 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYixuan Wang
KAN: Kolmogorov-Arnold Networks
May 02, 2024
Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes ("neurons"), KANs have learnable activation functions on edges ("weights"). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.
LM-Combiner: A Contextual Rewriting Model for Chinese Grammatical Error Correction
Mar 26, 2024

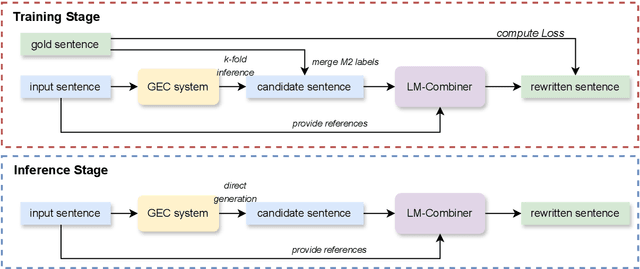
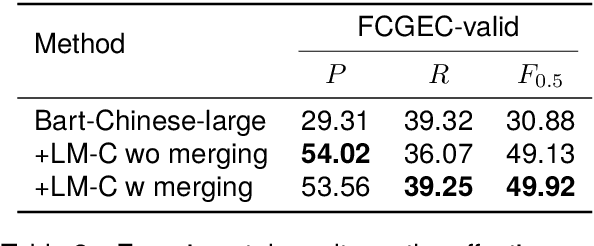
Over-correction is a critical problem in Chinese grammatical error correction (CGEC) task. Recent work using model ensemble methods based on voting can effectively mitigate over-correction and improve the precision of the GEC system. However, these methods still require the output of several GEC systems and inevitably lead to reduced error recall. In this light, we propose the LM-Combiner, a rewriting model that can directly modify the over-correction of GEC system outputs without a model ensemble. Specifically, we train the model on an over-correction dataset constructed through the proposed K-fold cross inference method, which allows it to directly generate filtered sentences by combining the original and the over-corrected text. In the inference stage, we directly take the original sentences and the output results of other systems as input and then obtain the filtered sentences through LM-Combiner. Experiments on the FCGEC dataset show that our proposed method effectively alleviates the over-correction of the original system (+18.2 Precision) while ensuring the error recall remains unchanged. Besides, we find that LM-Combiner still has a good rewriting performance even with small parameters and few training data, and thus can cost-effectively mitigate the over-correction of black-box GEC systems (e.g., ChatGPT).
Progress and Opportunities of Foundation Models in Bioinformatics
Feb 06, 2024Bioinformatics has witnessed a paradigm shift with the increasing integration of artificial intelligence (AI), particularly through the adoption of foundation models (FMs). These AI techniques have rapidly advanced, addressing historical challenges in bioinformatics such as the scarcity of annotated data and the presence of data noise. FMs are particularly adept at handling large-scale, unlabeled data, a common scenario in biological contexts due to the time-consuming and costly nature of experimentally determining labeled data. This characteristic has allowed FMs to excel and achieve notable results in various downstream validation tasks, demonstrating their ability to represent diverse biological entities effectively. Undoubtedly, FMs have ushered in a new era in computational biology, especially in the realm of deep learning. The primary goal of this survey is to conduct a systematic investigation and summary of FMs in bioinformatics, tracing their evolution, current research status, and the methodologies employed. Central to our focus is the application of FMs to specific biological problems, aiming to guide the research community in choosing appropriate FMs for their research needs. We delve into the specifics of the problem at hand including sequence analysis, structure prediction, function annotation, and multimodal integration, comparing the structures and advancements against traditional methods. Furthermore, the review analyses challenges and limitations faced by FMs in biology, such as data noise, model explainability, and potential biases. Finally, we outline potential development paths and strategies for FMs in future biological research, setting the stage for continued innovation and application in this rapidly evolving field. This comprehensive review serves not only as an academic resource but also as a roadmap for future explorations and applications of FMs in biology.
Boosting Long-Delayed Reinforcement Learning with Auxiliary Short-Delayed Task
Feb 05, 2024Reinforcement learning is challenging in delayed scenarios, a common real-world situation where observations and interactions occur with delays. State-of-the-art (SOTA) state-augmentation techniques either suffer from the state-space explosion along with the delayed steps, or performance degeneration in stochastic environments. To address these challenges, our novel Auxiliary-Delayed Reinforcement Learning (AD-RL) leverages an auxiliary short-delayed task to accelerate the learning on a long-delayed task without compromising the performance in stochastic environments. Specifically, AD-RL learns the value function in the short-delayed task and then employs it with the bootstrapping and policy improvement techniques in the long-delayed task. We theoretically show that this can greatly reduce the sample complexity compared to directly learning on the original long-delayed task. On deterministic and stochastic benchmarks, our method remarkably outperforms the SOTAs in both sample efficiency and policy performance.
S$^{2}$-DMs:Skip-Step Diffusion Models
Jan 03, 2024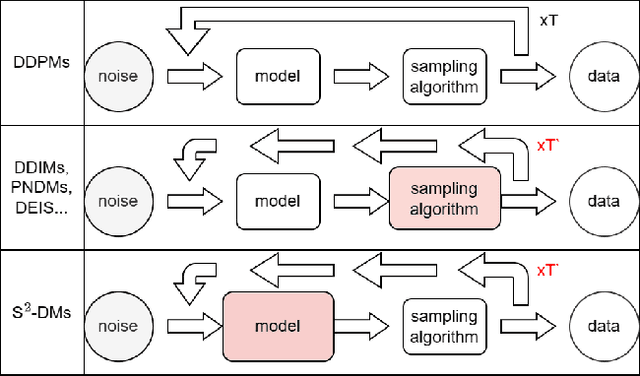

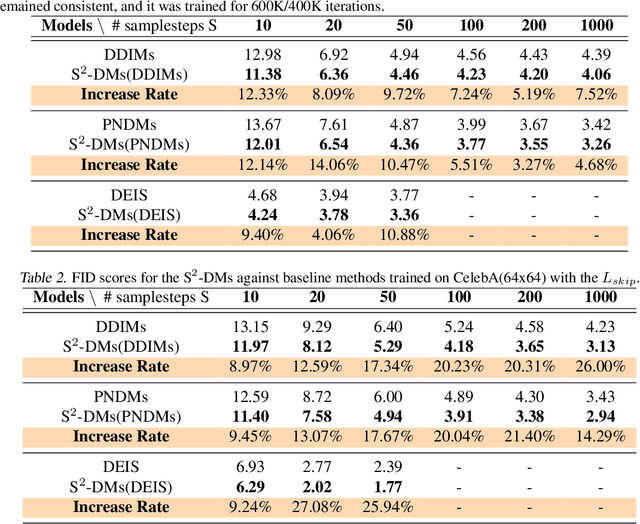
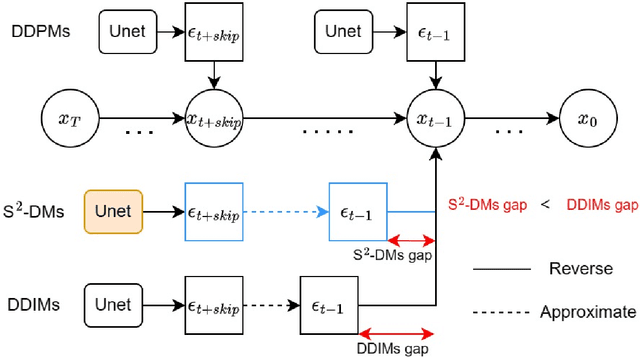
Diffusion models have emerged as powerful generative tools, rivaling GANs in sample quality and mirroring the likelihood scores of autoregressive models. A subset of these models, exemplified by DDIMs, exhibit an inherent asymmetry: they are trained over $T$ steps but only sample from a subset of $T$ during generation. This selective sampling approach, though optimized for speed, inadvertently misses out on vital information from the unsampled steps, leading to potential compromises in sample quality. To address this issue, we present the S$^{2}$-DMs, which is a new training method by using an innovative $L_{skip}$, meticulously designed to reintegrate the information omitted during the selective sampling phase. The benefits of this approach are manifold: it notably enhances sample quality, is exceptionally simple to implement, requires minimal code modifications, and is flexible enough to be compatible with various sampling algorithms. On the CIFAR10 dataset, models trained using our algorithm showed an improvement of 3.27% to 14.06% over models trained with traditional methods across various sampling algorithms (DDIMs, PNDMs, DEIS) and different numbers of sampling steps (10, 20, ..., 1000). On the CELEBA dataset, the improvement ranged from 8.97% to 27.08%. Access to the code and additional resources is provided in the github.
Single-Cell RNA-seq Synthesis with Latent Diffusion Model
Dec 21, 2023The single-cell RNA sequencing (scRNA-seq) technology enables researchers to study complex biological systems and diseases with high resolution. The central challenge is synthesizing enough scRNA-seq samples; insufficient samples can impede downstream analysis and reproducibility. While various methods have been attempted in past research, the resulting scRNA-seq samples were often of poor quality or limited in terms of useful specific cell subpopulations. To address these issues, we propose a novel method called Single-Cell Latent Diffusion (SCLD) based on the Diffusion Model. This method is capable of synthesizing large-scale, high-quality scRNA-seq samples, including both 'holistic' or targeted specific cellular subpopulations within a unified framework. A pre-guidance mechanism is designed for synthesizing specific cellular subpopulations, while a post-guidance mechanism aims to enhance the quality of scRNA-seq samples. The SCLD can synthesize large-scale and high-quality scRNA-seq samples for various downstream tasks. Our experimental results demonstrate state-of-the-art performance in cell classification and data distribution distances when evaluated on two scRNA-seq benchmarks. Additionally, visualization experiments show the SCLD's capability in synthesizing specific cellular subpopulations.
Empowering Autonomous Driving with Large Language Models: A Safety Perspective
Nov 28, 2023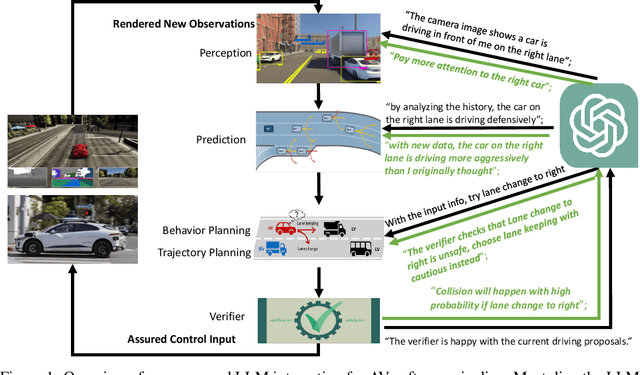
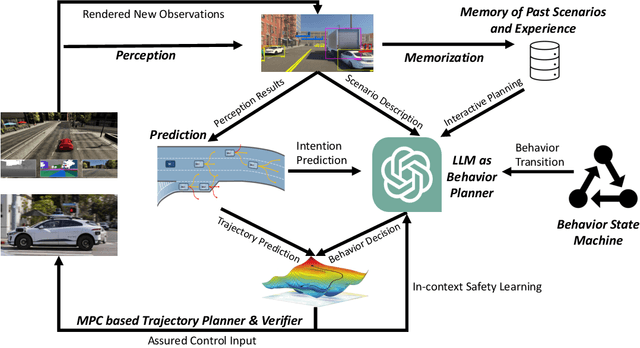

Autonomous Driving (AD) faces crucial hurdles for commercial launch, notably in the form of diminished public trust and safety concerns from long-tail unforeseen driving scenarios. This predicament is due to the limitation of deep neural networks in AD software, which struggle with interpretability and exhibit poor generalization capabilities in out-of-distribution and uncertain scenarios. To this end, this paper advocates for the integration of Large Language Models (LLMs) into the AD system, leveraging their robust common-sense knowledge, reasoning abilities, and human-interaction capabilities. The proposed approach deploys the LLM as an intelligent decision-maker in planning, incorporating safety verifiers for contextual safety learning to enhance overall AD performance and safety. We present results from two case studies that affirm the efficacy of our approach. We further discuss the potential integration of LLM for other AD software components including perception, prediction, and simulation. Despite the observed challenges in the case studies, the integration of LLMs is promising and beneficial for reinforcing both safety and performance in AD.
Multi-view learning for automatic classification of multi-wavelength auroral images
Nov 06, 2023Auroral classification plays a crucial role in polar research. However, current auroral classification studies are predominantly based on images taken at a single wavelength, typically 557.7 nm. Images obtained at other wavelengths have been comparatively overlooked, and the integration of information from multiple wavelengths remains an underexplored area. This limitation results in low classification rates for complex auroral patterns. Furthermore, these studies, whether employing traditional machine learning or deep learning approaches, have not achieved a satisfactory trade-off between accuracy and speed. To address these challenges, this paper proposes a lightweight auroral multi-wavelength fusion classification network, MLCNet, based on a multi-view approach. Firstly, we develop a lightweight feature extraction backbone, called LCTNet, to improve the classification rate and cope with the increasing amount of auroral observation data. Secondly, considering the existence of multi-scale spatial structures in auroras, we design a novel multi-scale reconstructed feature module named MSRM. Finally, to highlight the discriminative information between auroral classes, we propose a lightweight attention feature enhancement module called LAFE. The proposed method is validated using observational data from the Arctic Yellow River Station during 2003-2004. Experimental results demonstrate that the fusion of multi-wavelength information effectively improves the auroral classification performance. In particular, our approach achieves state-of-the-art classification accuracy compared to previous auroral classification studies, and superior results in terms of accuracy and computational efficiency compared to existing multi-view methods.
State-wise Safe Reinforcement Learning With Pixel Observations
Nov 03, 2023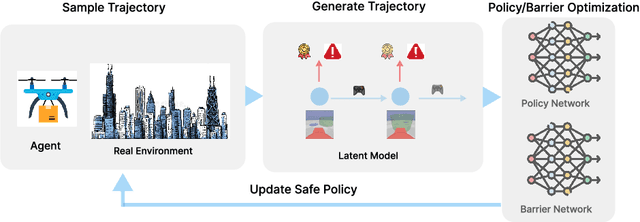
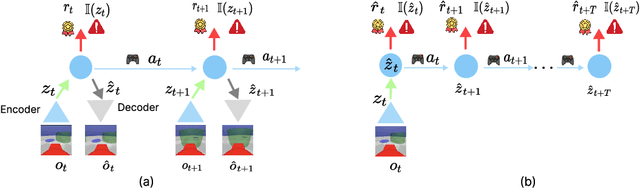

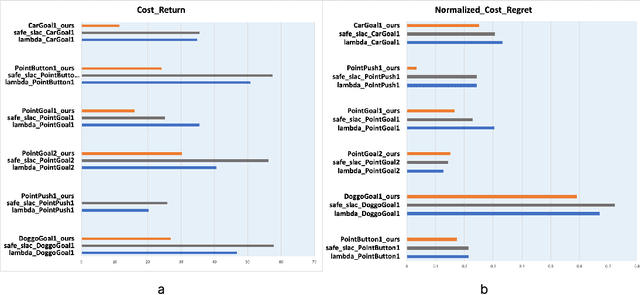
Reinforcement Learning(RL) in the context of safe exploration has long grappled with the challenges of the delicate balance between maximizing rewards and minimizing safety violations, the complexities arising from contact-rich or non-smooth environments, and high-dimensional pixel observations. Furthermore, incorporating state-wise safety constraints in the exploration and learning process, where the agent is prohibited from accessing unsafe regions without prior knowledge, adds an additional layer of complexity. In this paper, we propose a novel pixel-observation safe RL algorithm that efficiently encodes state-wise safety constraints with unknown hazard regions through the introduction of a latent barrier function learning mechanism. As a joint learning framework, our approach first involves constructing a latent dynamics model with low-dimensional latent spaces derived from pixel observations. Subsequently, we build and learn a latent barrier function on top of the latent dynamics and conduct policy optimization simultaneously, thereby improving both safety and the total expected return. Experimental evaluations on the safety-gym benchmark suite demonstrate that our proposed method significantly reduces safety violations throughout the training process and demonstrates faster safety convergence compared to existing methods while achieving competitive results in reward return.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023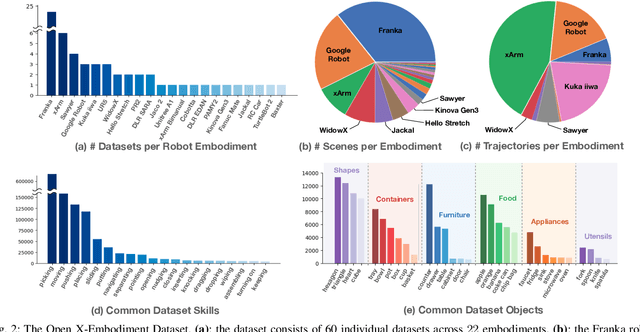
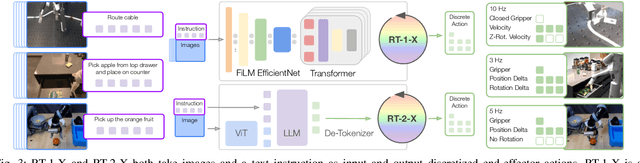
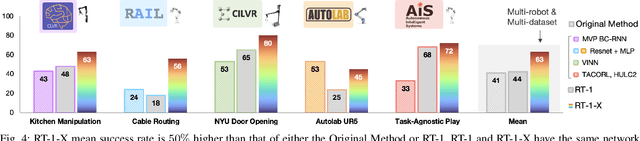

Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.