 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNiko Suenderhauf
Human-in-the-Loop Segmentation of Multi-species Coral Imagery
Apr 16, 2024
Broad-scale marine surveys performed by underwater vehicles significantly increase the availability of coral reef imagery, however it is costly and time-consuming for domain experts to label images. Point label propagation is an approach used to leverage existing image data labeled with sparse point labels. The resulting augmented ground truth generated is then used to train a semantic segmentation model. Here, we first demonstrate that recent advances in foundation models enable generation of multi-species coral augmented ground truth masks using denoised DINOv2 features and K-Nearest Neighbors (KNN), without the need for any pre-training or custom-designed algorithms. For extremely sparsely labeled images, we propose a labeling regime based on human-in-the-loop principles, resulting in significant improvement in annotation efficiency: If only 5 point labels per image are available, our proposed human-in-the-loop approach improves on the state-of-the-art by 17.3% for pixel accuracy and 22.6% for mIoU; and by 10.6% and 19.1% when 10 point labels per image are available. Even if the human-in-the-loop labeling regime is not used, the denoised DINOv2 features with a KNN outperforms the prior state-of-the-art by 3.5% for pixel accuracy and 5.7% for mIoU (5 grid points). We also provide a detailed analysis of how point labeling style and the quantity of points per image affects the point label propagation quality and provide general recommendations on maximizing point label efficiency.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023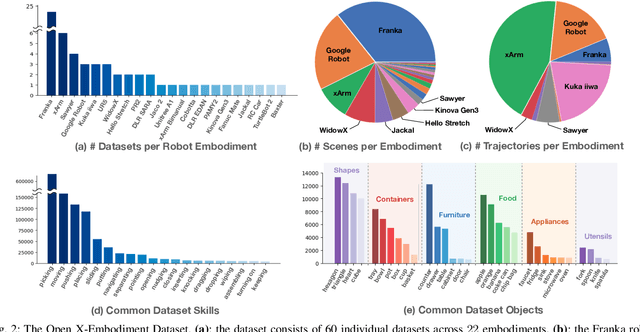
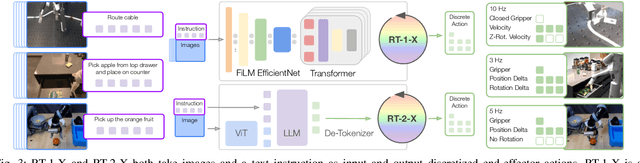
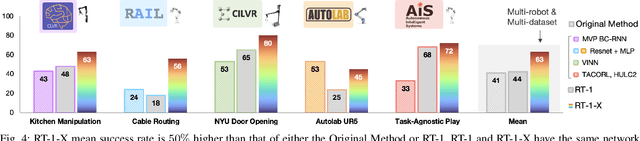

Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Task Planning
Jul 12, 2023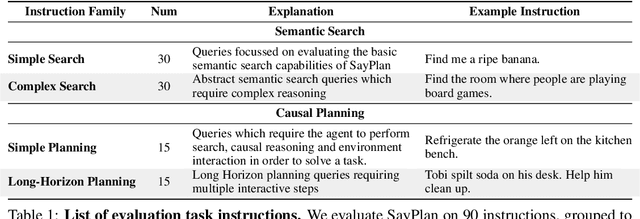
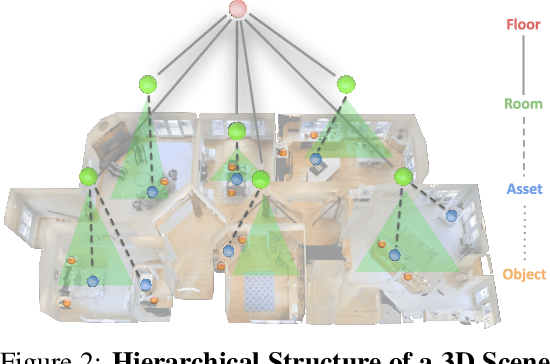
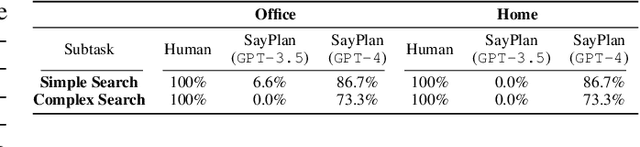
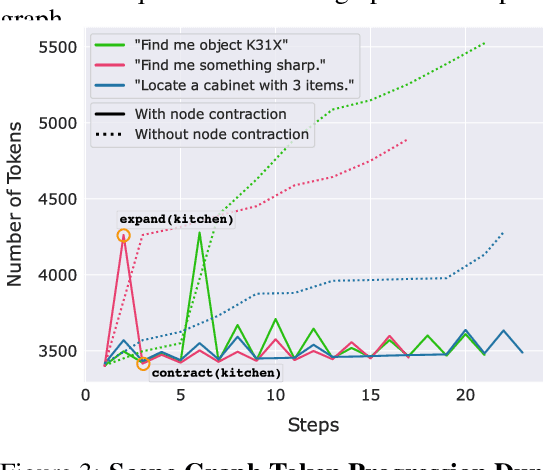
Large language models (LLMs) have demonstrated impressive results in developing generalist planning agents for diverse tasks. However, grounding these plans in expansive, multi-floor, and multi-room environments presents a significant challenge for robotics. We introduce SayPlan, a scalable approach to LLM-based, large-scale task planning for robotics using 3D scene graph (3DSG) representations. To ensure the scalability of our approach, we: (1) exploit the hierarchical nature of 3DSGs to allow LLMs to conduct a semantic search for task-relevant subgraphs from a smaller, collapsed representation of the full graph; (2) reduce the planning horizon for the LLM by integrating a classical path planner and (3) introduce an iterative replanning pipeline that refines the initial plan using feedback from a scene graph simulator, correcting infeasible actions and avoiding planning failures. We evaluate our approach on two large-scale environments spanning up to 3 floors, 36 rooms and 140 objects, and show that our approach is capable of grounding large-scale, long-horizon task plans from abstract, and natural language instruction for a mobile manipulator robot to execute.
The Need for Inherently Privacy-Preserving Vision in Trustworthy Autonomous Systems
Mar 29, 2023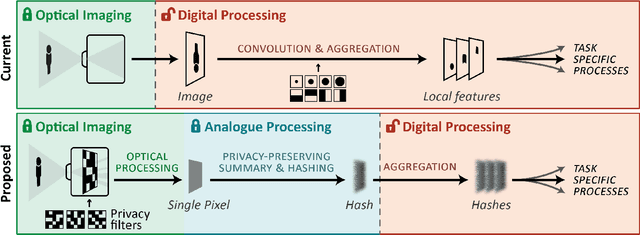
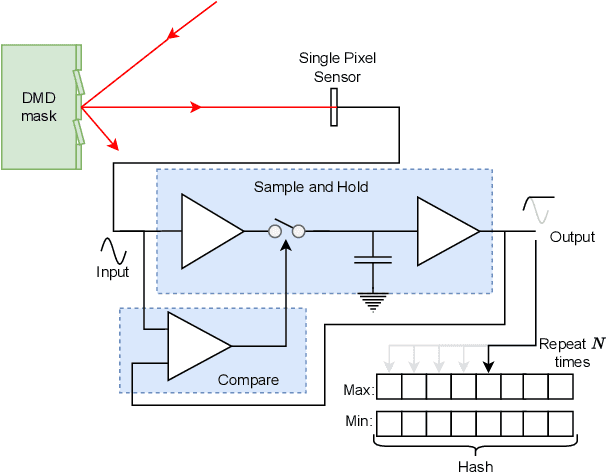
Vision is a popular and effective sensor for robotics from which we can derive rich information about the environment: the geometry and semantics of the scene, as well as the age, gender, identity, activity and even emotional state of humans within that scene. This raises important questions about the reach, lifespan, and potential misuse of this information. This paper is a call to action to consider privacy in the context of robotic vision. We propose a specific form privacy preservation in which no images are captured or could be reconstructed by an attacker even with full remote access. We present a set of principles by which such systems can be designed, and through a case study in localisation demonstrate in simulation a specific implementation that delivers an important robotic capability in an inherently privacy-preserving manner. This is a first step, and we hope to inspire future works that expand the range of applications open to sighted robotic systems.
Critic Guided Segmentation of Rewarding Objects in First-Person Views
Jul 20, 2021
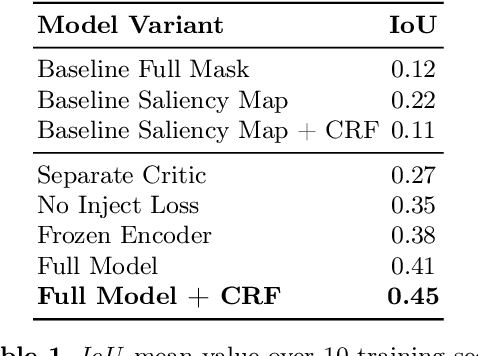

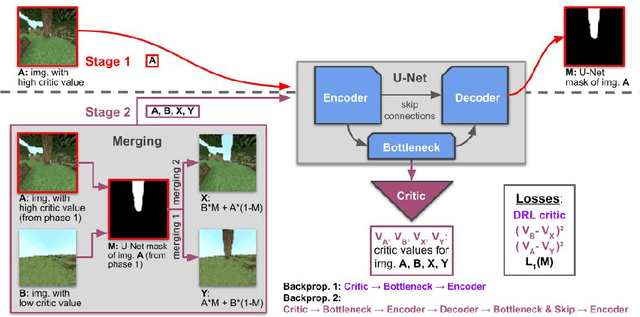
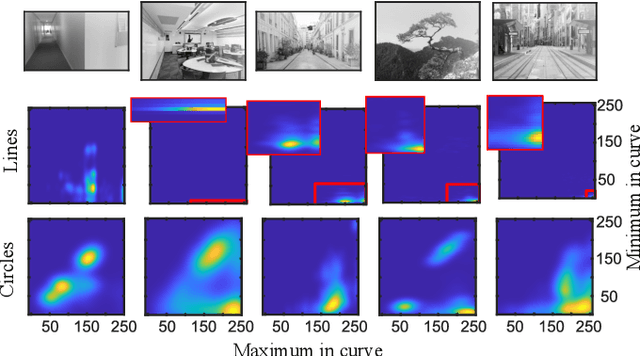
This work discusses a learning approach to mask rewarding objects in images using sparse reward signals from an imitation learning dataset. For that, we train an Hourglass network using only feedback from a critic model. The Hourglass network learns to produce a mask to decrease the critic's score of a high score image and increase the critic's score of a low score image by swapping the masked areas between these two images. We trained the model on an imitation learning dataset from the NeurIPS 2020 MineRL Competition Track, where our model learned to mask rewarding objects in a complex interactive 3D environment with a sparse reward signal. This approach was part of the 1st place winning solution in this competition. Video demonstration and code: https://rebrand.ly/critic-guided-segmentation
Look No Deeper: Recognizing Places from Opposing Viewpoints under Varying Scene Appearance using Single-View Depth Estimation
Feb 20, 2019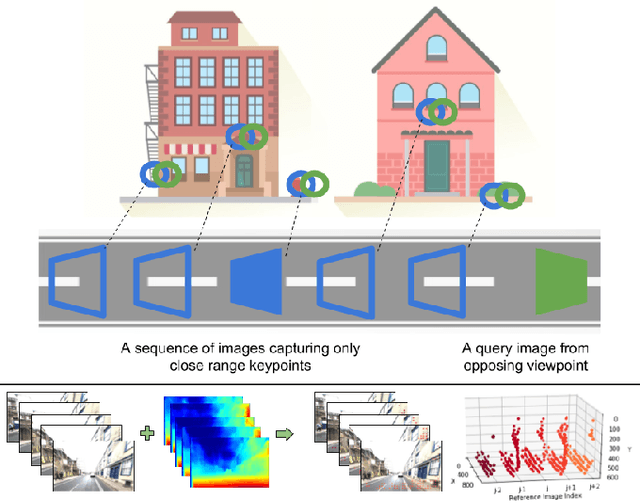
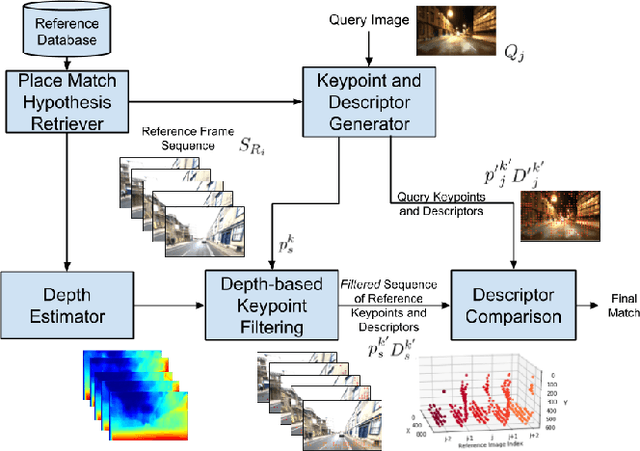

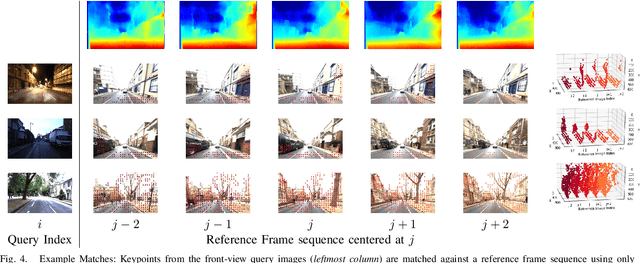
Visual place recognition (VPR) - the act of recognizing a familiar visual place - becomes difficult when there is extreme environmental appearance change or viewpoint change. Particularly challenging is the scenario where both phenomena occur simultaneously, such as when returning for the first time along a road at night that was previously traversed during the day in the opposite direction. While such problems can be solved with panoramic sensors, humans solve this problem regularly with limited field of view vision and without needing to constantly turn around. In this paper, we present a new depth- and temporal-aware visual place recognition system that solves the opposing viewpoint, extreme appearance-change visual place recognition problem. Our system performs sequence-to-single matching by extracting depth-filtered keypoints using a state-of-the-art depth estimation pipeline, constructing a keypoint sequence over multiple frames from the reference dataset, and comparing those keypoints to those in a single query image. We evaluate the system on a challenging benchmark dataset and show that it consistently outperforms state-of-the-art techniques. We also develop a range of diagnostic simulation experiments that characterize the contribution of depth-filtered keypoint sequences with respect to key domain parameters including degree of appearance change and camera motion.
Structure Aware SLAM using Quadrics and Planes
Nov 02, 2018
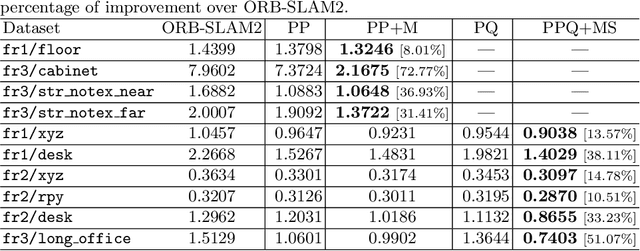

Simultaneous Localization And Mapping (SLAM) is a fundamental problem in mobile robotics. While point-based SLAM methods provide accurate camera localization, the generated maps lack semantic information. On the other hand, state of the art object detection methods provide rich information about entities present in the scene from a single image. This work marries the two and proposes a method for representing generic objects as quadrics which allows object detections to be seamlessly integrated in a SLAM framework. For scene coverage, additional dominant planar structures are modeled as infinite planes. Experiments show that the proposed points-planes-quadrics representation can easily incorporate Manhattan and object affordance constraints, greatly improving camera localization and leading to semantically meaningful maps. The performance of our SLAM system is demonstrated in https://youtu.be/dR-rB9keF8M .
LoST? Appearance-Invariant Place Recognition for Opposite Viewpoints using Visual Semantics
May 26, 2018
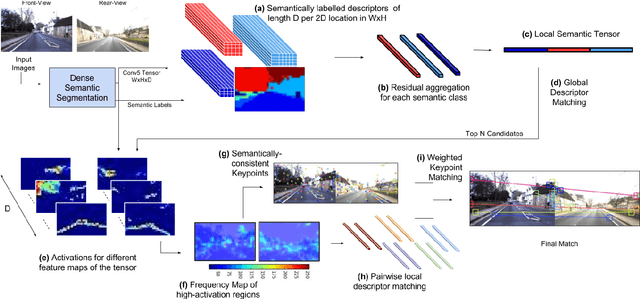
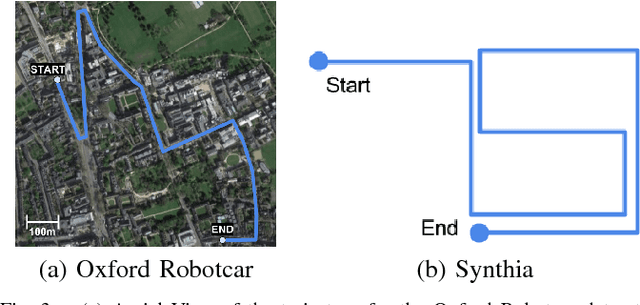
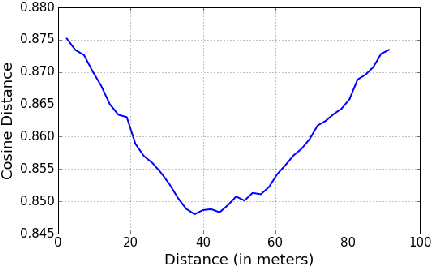
Human visual scene understanding is so remarkable that we are able to recognize a revisited place when entering it from the opposite direction it was first visited, even in the presence of extreme variations in appearance. This capability is especially apparent during driving: a human driver can recognize where they are when travelling in the reverse direction along a route for the first time, without having to turn back and look. The difficulty of this problem exceeds any addressed in past appearance- and viewpoint-invariant visual place recognition (VPR) research, in part because large parts of the scene are not commonly observable from opposite directions. Consequently, as shown in this paper, the precision-recall performance of current state-of-the-art viewpoint- and appearance-invariant VPR techniques is orders of magnitude below what would be usable in a closed-loop system. Current engineered solutions predominantly rely on panoramic camera or LIDAR sensing setups; an eminently suitable engineering solution but one that is clearly very different to how humans navigate, which also has implications for how naturally humans could interact and communicate with the navigation system. In this paper we develop a suite of novel semantic- and appearance-based techniques to enable for the first time high performance place recognition in this challenging scenario. We first propose a novel Local Semantic Tensor (LoST) descriptor of images using the convolutional feature maps from a state-of-the-art dense semantic segmentation network. Then, to verify the spatial semantic arrangement of the top matching candidates, we develop a novel approach for mining semantically-salient keypoint correspondences.
Don't Look Back: Robustifying Place Categorization for Viewpoint- and Condition-Invariant Place Recognition
Jan 16, 2018

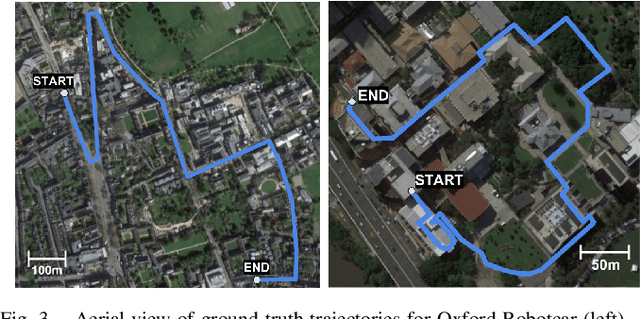

When a human drives a car along a road for the first time, they later recognize where they are on the return journey typically without needing to look in their rear-view mirror or turn around to look back, despite significant viewpoint and appearance change. Such navigation capabilities are typically attributed to our semantic visual understanding of the environment [1] beyond geometry to recognizing the types of places we are passing through such as "passing a shop on the left" or "moving through a forested area". Humans are in effect using place categorization [2] to perform specific place recognition even when the viewpoint is 180 degrees reversed. Recent advances in deep neural networks have enabled high-performance semantic understanding of visual places and scenes, opening up the possibility of emulating what humans do. In this work, we develop a novel methodology for using the semantics-aware higher-order layers of deep neural networks for recognizing specific places from within a reference database. To further improve the robustness to appearance change, we develop a descriptor normalization scheme that builds on the success of normalization schemes for pure appearance-based techniques such as SeqSLAM [3]. Using two different datasets - one road-based, one pedestrian-based, we evaluate the performance of the system in performing place recognition on reverse traversals of a route with a limited field of view camera and no turn-back-and-look behaviours, and compare to existing state-of-the-art techniques and vanilla off-the-shelf features. The results demonstrate significant improvements over the existing state of the art, especially for extreme perceptual challenges that involve both great viewpoint change and environmental appearance change. We also provide experimental analyses of the contributions of the various system components.
One-Shot Reinforcement Learning for Robot Navigation with Interactive Replay
Nov 29, 2017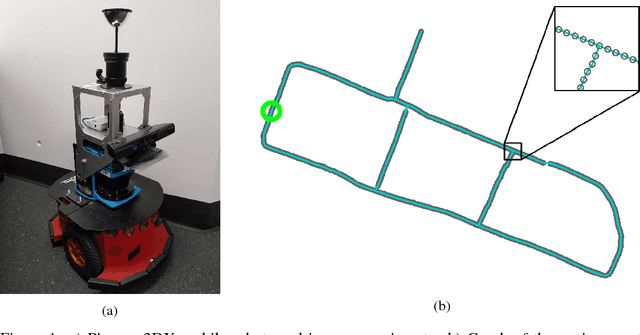
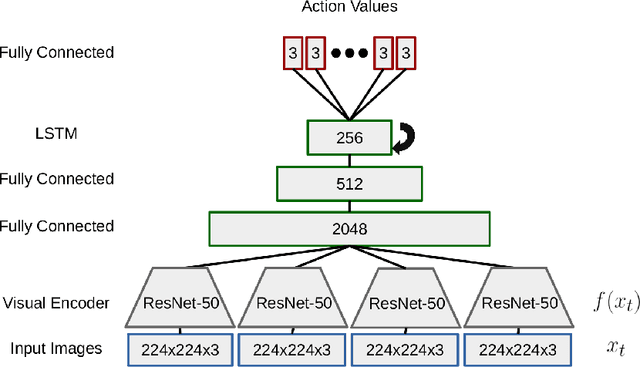

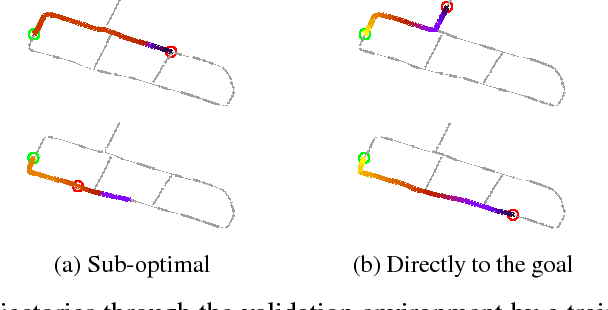
Recently, model-free reinforcement learning algorithms have been shown to solve challenging problems by learning from extensive interaction with the environment. A significant issue with transferring this success to the robotics domain is that interaction with the real world is costly, but training on limited experience is prone to overfitting. We present a method for learning to navigate, to a fixed goal and in a known environment, on a mobile robot. The robot leverages an interactive world model built from a single traversal of the environment, a pre-trained visual feature encoder, and stochastic environmental augmentation, to demonstrate successful zero-shot transfer under real-world environmental variations without fine-tuning.
* NIPS Workshop on Acting and Interacting in the Real World: Challenges in Robot Learning