 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHang Su
Omniview-Tuning: Boosting Viewpoint Invariance of Vision-Language Pre-training Models
Apr 18, 2024
Vision-Language Pre-training (VLP) models like CLIP have achieved remarkable success in computer vision and particularly demonstrated superior robustness to distribution shifts of 2D images. However, their robustness under 3D viewpoint variations is still limited, which can hinder the development for real-world applications. This paper successfully addresses this concern while keeping VLPs' original performance by breaking through two primary obstacles: 1) the scarcity of training data and 2) the suboptimal fine-tuning paradigms. To combat data scarcity, we build the Multi-View Caption (MVCap) dataset -- a comprehensive collection of over four million multi-view image-text pairs across more than 100K objects, providing more potential for VLP models to develop generalizable viewpoint-invariant representations. To address the limitations of existing paradigms in performance trade-offs and training efficiency, we design a novel fine-tuning framework named Omniview-Tuning (OVT). Specifically, OVT introduces a Cross-Viewpoint Alignment objective through a minimax-like optimization strategy, which effectively aligns representations of identical objects from diverse viewpoints without causing overfitting. Additionally, OVT fine-tunes VLP models in a parameter-efficient manner, leading to minimal computational cost. Extensive experiments on various VLP models with different architectures validate that OVT significantly improves the models' resilience to viewpoint shifts and keeps the original performance, establishing a pioneering standard for boosting the viewpoint invariance of VLP models.
Exploring the Transferability of Visual Prompting for Multimodal Large Language Models
Apr 17, 2024Although Multimodal Large Language Models (MLLMs) have demonstrated promising versatile capabilities, their performance is still inferior to specialized models on downstream tasks, which makes adaptation necessary to enhance their utility. However, fine-tuning methods require independent training for every model, leading to huge computation and memory overheads. In this paper, we propose a novel setting where we aim to improve the performance of diverse MLLMs with a group of shared parameters optimized for a downstream task. To achieve this, we propose Transferable Visual Prompting (TVP), a simple and effective approach to generate visual prompts that can transfer to different models and improve their performance on downstream tasks after trained on only one model. We introduce two strategies to address the issue of cross-model feature corruption of existing visual prompting methods and enhance the transferability of the learned prompts, including 1) Feature Consistency Alignment: which imposes constraints to the prompted feature changes to maintain task-agnostic knowledge; 2) Task Semantics Enrichment: which encourages the prompted images to contain richer task-specific semantics with language guidance. We validate the effectiveness of TVP through extensive experiments with 6 modern MLLMs on a wide variety of tasks ranging from object recognition and counting to multimodal reasoning and hallucination correction.
FaceCat: Enhancing Face Recognition Security with a Unified Generative Model Framework
Apr 14, 2024Face anti-spoofing (FAS) and adversarial detection (FAD) have been regarded as critical technologies to ensure the safety of face recognition systems. As a consequence of their limited practicality and generalization, some existing methods aim to devise a framework capable of concurrently detecting both threats to address the challenge. Nevertheless, these methods still encounter challenges of insufficient generalization and suboptimal robustness, potentially owing to the inherent drawback of discriminative models. Motivated by the rich structural and detailed features of face generative models, we propose FaceCat which utilizes the face generative model as a pre-trained model to improve the performance of FAS and FAD. Specifically, FaceCat elaborately designs a hierarchical fusion mechanism to capture rich face semantic features of the generative model. These features then serve as a robust foundation for a lightweight head, designed to execute FAS and FAD tasks simultaneously. As relying solely on single-modality data often leads to suboptimal performance, we further propose a novel text-guided multi-modal alignment strategy that utilizes text prompts to enrich feature representation, thereby enhancing performance. For fair evaluations, we build a comprehensive protocol with a wide range of 28 attack types to benchmark the performance. Extensive experiments validate the effectiveness of FaceCat generalizes significantly better and obtains excellent robustness against input transformations.
An N-Point Linear Solver for Line and Motion Estimation with Event Cameras
Apr 01, 2024Event cameras respond primarily to edges--formed by strong gradients--and are thus particularly well-suited for line-based motion estimation. Recent work has shown that events generated by a single line each satisfy a polynomial constraint which describes a manifold in the space-time volume. Multiple such constraints can be solved simultaneously to recover the partial linear velocity and line parameters. In this work, we show that, with a suitable line parametrization, this system of constraints is actually linear in the unknowns, which allows us to design a novel linear solver. Unlike existing solvers, our linear solver (i) is fast and numerically stable since it does not rely on expensive root finding, (ii) can solve both minimal and overdetermined systems with more than 5 events, and (iii) admits the characterization of all degenerate cases and multiple solutions. The found line parameters are singularity-free and have a fixed scale, which eliminates the need for auxiliary constraints typically encountered in previous work. To recover the full linear camera velocity we fuse observations from multiple lines with a novel velocity averaging scheme that relies on a geometrically-motivated residual, and thus solves the problem more efficiently than previous schemes which minimize an algebraic residual. Extensive experiments in synthetic and real-world settings demonstrate that our method surpasses the previous work in numerical stability, and operates over 600 times faster.
Embodied Active Defense: Leveraging Recurrent Feedback to Counter Adversarial Patches
Mar 31, 2024The vulnerability of deep neural networks to adversarial patches has motivated numerous defense strategies for boosting model robustness. However, the prevailing defenses depend on single observation or pre-established adversary information to counter adversarial patches, often failing to be confronted with unseen or adaptive adversarial attacks and easily exhibiting unsatisfying performance in dynamic 3D environments. Inspired by active human perception and recurrent feedback mechanisms, we develop Embodied Active Defense (EAD), a proactive defensive strategy that actively contextualizes environmental information to address misaligned adversarial patches in 3D real-world settings. To achieve this, EAD develops two central recurrent sub-modules, i.e., a perception module and a policy module, to implement two critical functions of active vision. These models recurrently process a series of beliefs and observations, facilitating progressive refinement of their comprehension of the target object and enabling the development of strategic actions to counter adversarial patches in 3D environments. To optimize learning efficiency, we incorporate a differentiable approximation of environmental dynamics and deploy patches that are agnostic to the adversary strategies. Extensive experiments demonstrate that EAD substantially enhances robustness against a variety of patches within just a few steps through its action policy in safety-critical tasks (e.g., face recognition and object detection), without compromising standard accuracy. Furthermore, due to the attack-agnostic characteristic, EAD facilitates excellent generalization to unseen attacks, diminishing the averaged attack success rate by 95 percent across a range of unseen adversarial attacks.
CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
Mar 08, 2024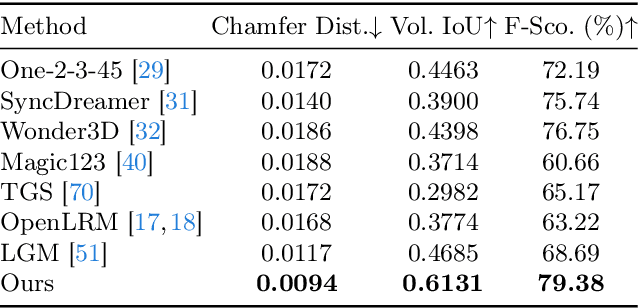
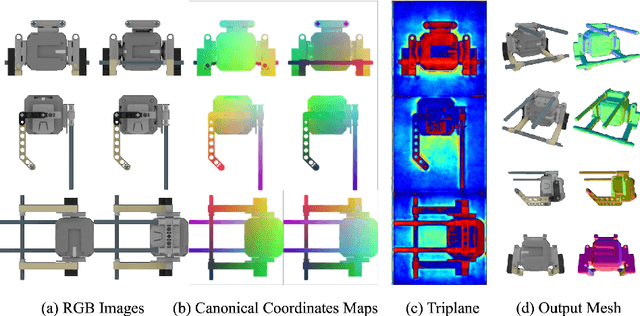
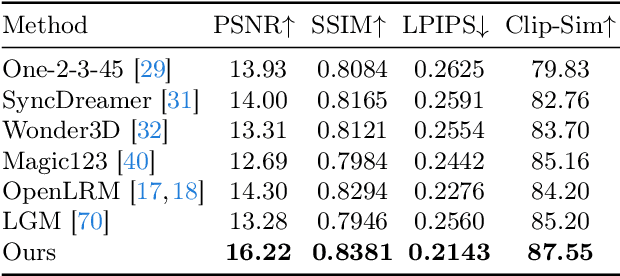
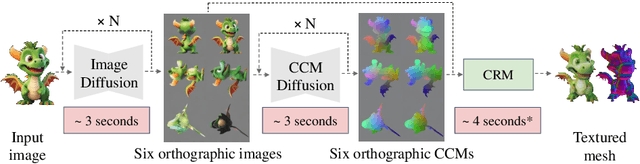
Feed-forward 3D generative models like the Large Reconstruction Model (LRM) have demonstrated exceptional generation speed. However, the transformer-based methods do not leverage the geometric priors of the triplane component in their architecture, often leading to sub-optimal quality given the limited size of 3D data and slow training. In this work, we present the Convolutional Reconstruction Model (CRM), a high-fidelity feed-forward single image-to-3D generative model. Recognizing the limitations posed by sparse 3D data, we highlight the necessity of integrating geometric priors into network design. CRM builds on the key observation that the visualization of triplane exhibits spatial correspondence of six orthographic images. First, it generates six orthographic view images from a single input image, then feeds these images into a convolutional U-Net, leveraging its strong pixel-level alignment capabilities and significant bandwidth to create a high-resolution triplane. CRM further employs Flexicubes as geometric representation, facilitating direct end-to-end optimization on textured meshes. Overall, our model delivers a high-fidelity textured mesh from an image in just 10 seconds, without any test-time optimization.
DPOT: Auto-Regressive Denoising Operator Transformer for Large-Scale PDE Pre-Training
Mar 08, 2024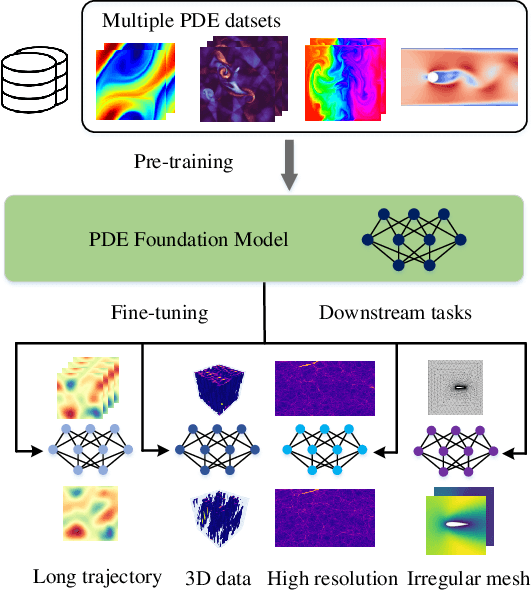
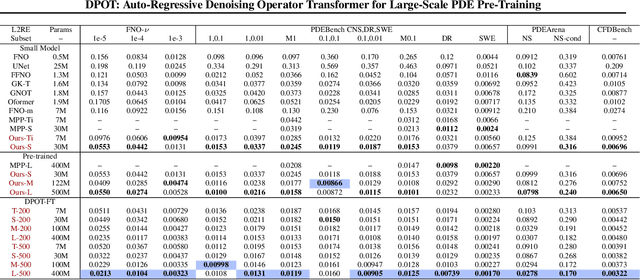
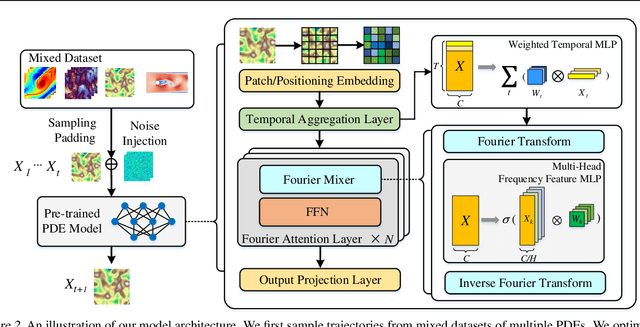
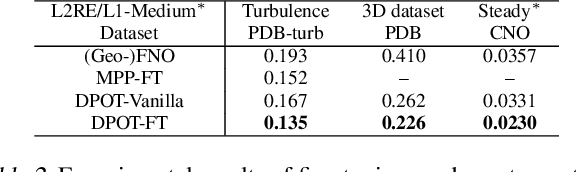
Pre-training has been investigated to improve the efficiency and performance of training neural operators in data-scarce settings. However, it is largely in its infancy due to the inherent complexity and diversity, such as long trajectories, multiple scales and varying dimensions of partial differential equations (PDEs) data. In this paper, we present a new auto-regressive denoising pre-training strategy, which allows for more stable and efficient pre-training on PDE data and generalizes to various downstream tasks. Moreover, by designing a flexible and scalable model architecture based on Fourier attention, we can easily scale up the model for large-scale pre-training. We train our PDE foundation model with up to 0.5B parameters on 10+ PDE datasets with more than 100k trajectories. Extensive experiments show that we achieve SOTA on these benchmarks and validate the strong generalizability of our model to significantly enhance performance on diverse downstream PDE tasks like 3D data. Code is available at \url{https://github.com/thu-ml/DPOT}.
Can Your Model Tell a Negation from an Implicature? Unravelling Challenges With Intent Encoders
Mar 07, 2024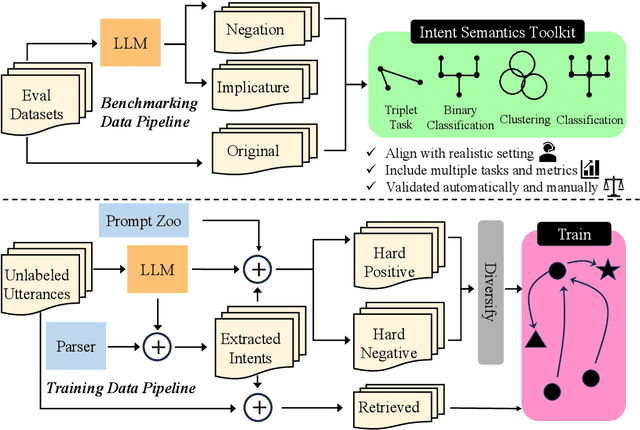

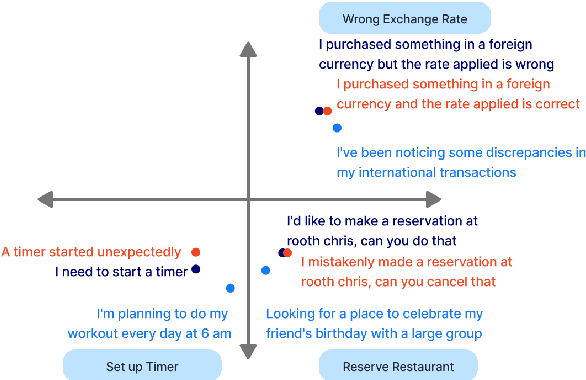

Conversational systems often rely on embedding models for intent classification and intent clustering tasks. The advent of Large Language Models (LLMs), which enable instructional embeddings allowing one to adjust semantics over the embedding space using prompts, are being viewed as a panacea for these downstream conversational tasks. However, traditional evaluation benchmarks rely solely on task metrics that don't particularly measure gaps related to semantic understanding. Thus, we propose an intent semantic toolkit that gives a more holistic view of intent embedding models by considering three tasks -- (1) intent classification, (2) intent clustering, and (3) a novel triplet task. The triplet task gauges the model's understanding of two semantic concepts paramount in real-world conversational systems -- negation and implicature. We observe that current embedding models fare poorly in semantic understanding of these concepts. To address this, we propose a pre-training approach to improve the embedding model by leveraging augmentation with data generated by an auto-regressive model and a contrastive loss term. Our approach improves the semantic understanding of the intent embedding model on the aforementioned linguistic dimensions while slightly effecting their performance on downstream task metrics.
Semi-Supervised Dialogue Abstractive Summarization via High-Quality Pseudolabel Selection
Mar 06, 2024

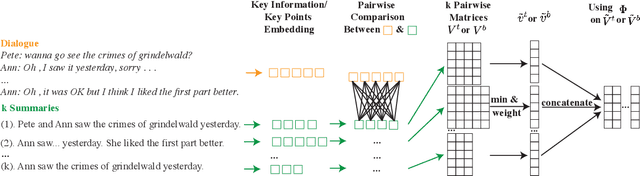

Semi-supervised dialogue summarization (SSDS) leverages model-generated summaries to reduce reliance on human-labeled data and improve the performance of summarization models. While addressing label noise, previous works on semi-supervised learning primarily focus on natural language understanding tasks, assuming each sample has a unique label. However, these methods are not directly applicable to SSDS, as it is a generative task, and each dialogue can be summarized in different ways. In this work, we propose a novel scoring approach, SiCF, which encapsulates three primary dimensions of summarization model quality: Semantic invariance (indicative of model confidence), Coverage (factual recall), and Faithfulness (factual precision). Using the SiCF score, we select unlabeled dialogues with high-quality generated summaries to train summarization models. Comprehensive experiments on three public datasets demonstrate the effectiveness of SiCF scores in uncertainty estimation and semi-supervised learning for dialogue summarization tasks. Our code is available at \url{https://github.com/amazon-science/summarization-sicf-score}.
MAGID: An Automated Pipeline for Generating Synthetic Multi-modal Datasets
Mar 05, 2024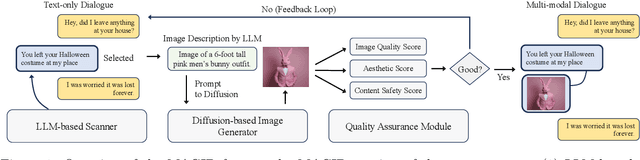
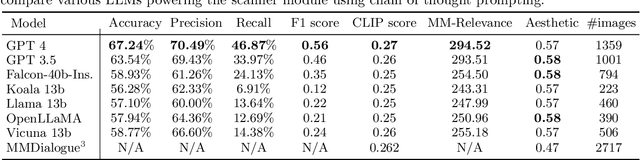

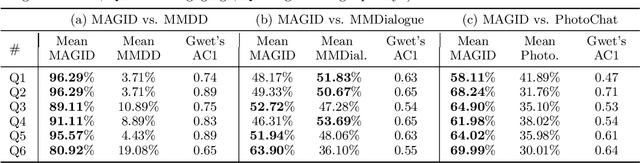
Development of multimodal interactive systems is hindered by the lack of rich, multimodal (text, images) conversational data, which is needed in large quantities for LLMs. Previous approaches augment textual dialogues with retrieved images, posing privacy, diversity, and quality constraints. In this work, we introduce \textbf{M}ultimodal \textbf{A}ugmented \textbf{G}enerative \textbf{I}mages \textbf{D}ialogues (MAGID), a framework to augment text-only dialogues with diverse and high-quality images. Subsequently, a diffusion model is applied to craft corresponding images, ensuring alignment with the identified text. Finally, MAGID incorporates an innovative feedback loop between an image description generation module (textual LLM) and image quality modules (addressing aesthetics, image-text matching, and safety), that work in tandem to generate high-quality and multi-modal dialogues. We compare MAGID to other SOTA baselines on three dialogue datasets, using automated and human evaluation. Our results show that MAGID is comparable to or better than baselines, with significant improvements in human evaluation, especially against retrieval baselines where the image database is small.