 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianfeng He
Exploring the Deceptive Power of LLM-Generated Fake News: A Study of Real-World Detection Challenges
Apr 08, 2024

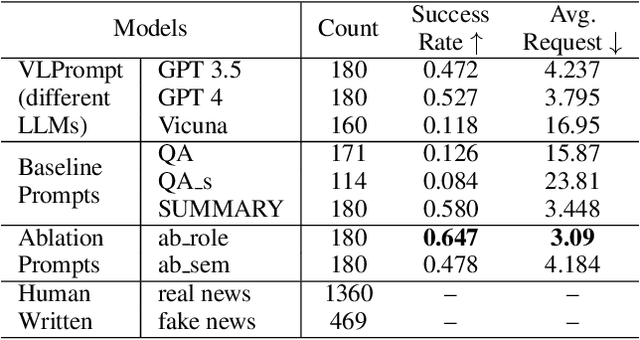
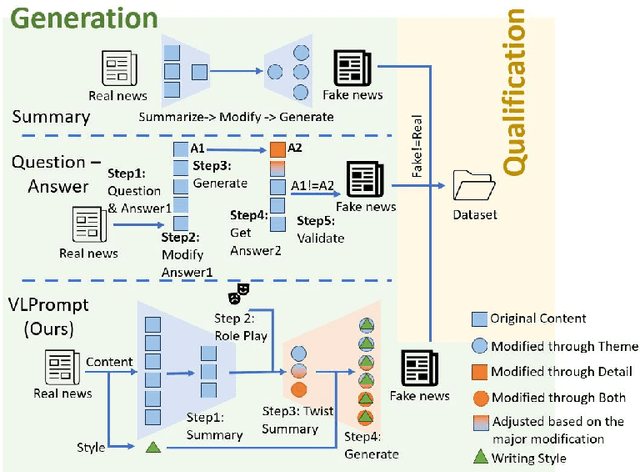
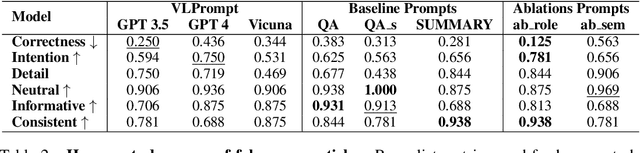
Recent advancements in Large Language Models (LLMs) have enabled the creation of fake news, particularly in complex fields like healthcare. Studies highlight the gap in the deceptive power of LLM-generated fake news with and without human assistance, yet the potential of prompting techniques has not been fully explored. Thus, this work aims to determine whether prompting strategies can effectively narrow this gap. Current LLM-based fake news attacks require human intervention for information gathering and often miss details and fail to maintain context consistency. Therefore, to better understand threat tactics, we propose a strong fake news attack method called conditional Variational-autoencoder-Like Prompt (VLPrompt). Unlike current methods, VLPrompt eliminates the need for additional data collection while maintaining contextual coherence and preserving the intricacies of the original text. To propel future research on detecting VLPrompt attacks, we created a new dataset named VLPrompt fake news (VLPFN) containing real and fake texts. Our experiments, including various detection methods and novel human study metrics, were conducted to assess their performance on our dataset, yielding numerous findings.
Semi-Supervised Dialogue Abstractive Summarization via High-Quality Pseudolabel Selection
Mar 06, 2024

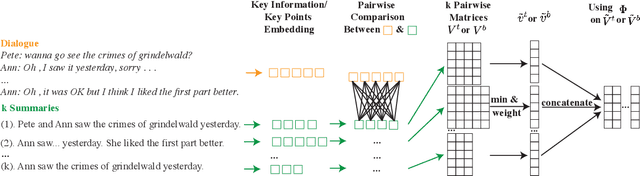

Semi-supervised dialogue summarization (SSDS) leverages model-generated summaries to reduce reliance on human-labeled data and improve the performance of summarization models. While addressing label noise, previous works on semi-supervised learning primarily focus on natural language understanding tasks, assuming each sample has a unique label. However, these methods are not directly applicable to SSDS, as it is a generative task, and each dialogue can be summarized in different ways. In this work, we propose a novel scoring approach, SiCF, which encapsulates three primary dimensions of summarization model quality: Semantic invariance (indicative of model confidence), Coverage (factual recall), and Faithfulness (factual precision). Using the SiCF score, we select unlabeled dialogues with high-quality generated summaries to train summarization models. Comprehensive experiments on three public datasets demonstrate the effectiveness of SiCF scores in uncertainty estimation and semi-supervised learning for dialogue summarization tasks. Our code is available at \url{https://github.com/amazon-science/summarization-sicf-score}.
Don't Go To Extremes: Revealing the Excessive Sensitivity and Calibration Limitations of LLMs in Implicit Hate Speech Detection
Feb 26, 2024The fairness and trustworthiness of Large Language Models (LLMs) are receiving increasing attention. Implicit hate speech, which employs indirect language to convey hateful intentions, occupies a significant portion of practice. However, the extent to which LLMs effectively address this issue remains insufficiently examined. This paper delves into the capability of LLMs to detect implicit hate speech (Classification Task) and express confidence in their responses (Calibration Task). Our evaluation meticulously considers various prompt patterns and mainstream uncertainty estimation methods. Our findings highlight that LLMs exhibit two extremes: (1) LLMs display excessive sensitivity towards groups or topics that may cause fairness issues, resulting in misclassifying benign statements as hate speech. (2) LLMs' confidence scores for each method excessively concentrate on a fixed range, remaining unchanged regardless of the dataset's complexity. Consequently, the calibration performance is heavily reliant on primary classification accuracy. These discoveries unveil new limitations of LLMs, underscoring the need for caution when optimizing models to ensure they do not veer towards extremes. This serves as a reminder to carefully consider sensitivity and confidence in the pursuit of model fairness.
Can LLM find the green circle? Investigation and Human-guided tool manipulation for compositional generalization
Dec 12, 2023
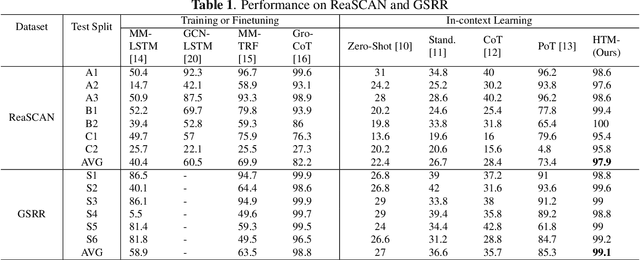
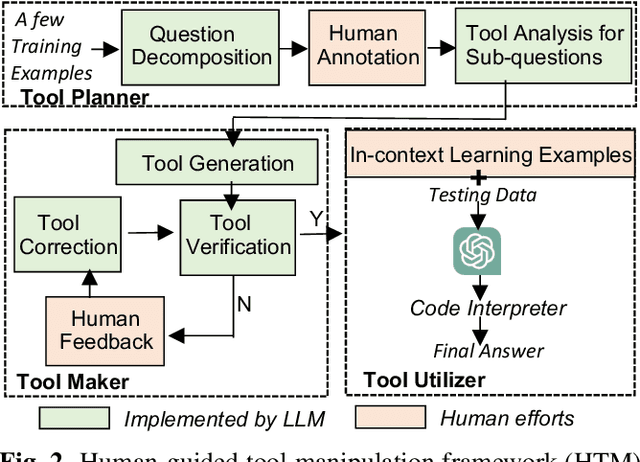

The meaning of complex phrases in natural language is composed of their individual components. The task of compositional generalization evaluates a model's ability to understand new combinations of components. Previous studies trained smaller, task-specific models, which exhibited poor generalization. While large language models (LLMs) exhibit impressive generalization abilities on many tasks through in-context learning (ICL), their potential for compositional generalization remains unexplored. In this paper, we first empirically investigate prevailing ICL methods in compositional generalization. We find that they struggle with complex compositional questions due to cumulative errors in long reasoning steps and intricate logic required for tool-making. Consequently, we propose a human-guided tool manipulation framework (HTM) that generates tools for sub-questions and integrates multiple tools. Our method enhances the effectiveness of tool creation and usage with minimal human effort. Experiments show that our method achieves state-of-the-art performance on two compositional generalization benchmarks and outperforms existing methods on the most challenging test split by 70%.
Uncertainty Estimation on Sequential Labeling via Uncertainty Transmission
Nov 15, 2023Sequential labeling is a task predicting labels for each token in a sequence, such as Named Entity Recognition (NER). NER tasks aim to extract entities and predict their labels given a text, which is important in information extraction. Although previous works have shown great progress in improving NER performance, uncertainty estimation on NER (UE-NER) is still underexplored but essential. This work focuses on UE-NER, which aims to estimate uncertainty scores for the NER predictions. Previous uncertainty estimation models often overlook two unique characteristics of NER: the connection between entities (i.e., one entity embedding is learned based on the other ones) and wrong span cases in the entity extraction subtask. Therefore, we propose a Sequential Labeling Posterior Network (SLPN) to estimate uncertainty scores for the extracted entities, considering uncertainty transmitted from other tokens. Moreover, we have defined an evaluation strategy to address the specificity of wrong-span cases. Our SLPN has achieved significant improvements on two datasets, such as a 5.54-point improvement in AUPR on the MIT-Restaurant dataset.
EC-Depth: Exploring the consistency of self-supervised monocular depth estimation under challenging scenes
Oct 12, 2023Self-supervised monocular depth estimation holds significant importance in the fields of autonomous driving and robotics. However, existing methods are typically designed to train and test on clear and pristine datasets, overlooking the impact of various adverse conditions prevalent in real-world scenarios. As a result, it is commonly observed that most self-supervised monocular depth estimation methods struggle to perform adequately under challenging conditions. To address this issue, we present EC-Depth, a novel self-supervised two-stage training framework to achieve a robust depth estimation, starting from the foundation of depth prediction consistency under different perturbations. Leveraging the proposed perturbation-invariant depth consistency constraint module and the consistency-based pseudo-label selection module, our model attains accurate and consistent depth predictions in both standard and challenging scenarios. Extensive experiments substantiate the effectiveness of the proposed method. Moreover, our method surpasses existing state-of-the-art methods on KITTI, KITTI-C and DrivingStereo benchmarks, demonstrating its potential for enhancing the reliability of self-supervised monocular depth estimation models in real-world applications.
Self-Correlation and Cross-Correlation Learning for Few-Shot Remote Sensing Image Semantic Segmentation
Sep 15, 2023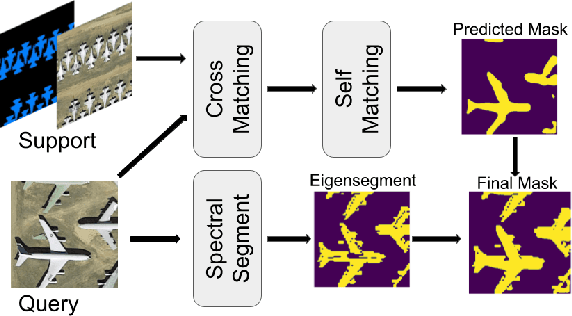

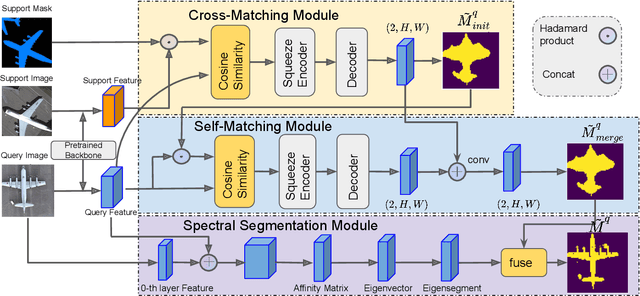

Remote sensing image semantic segmentation is an important problem for remote sensing image interpretation. Although remarkable progress has been achieved, existing deep neural network methods suffer from the reliance on massive training data. Few-shot remote sensing semantic segmentation aims at learning to segment target objects from a query image using only a few annotated support images of the target class. Most existing few-shot learning methods stem primarily from their sole focus on extracting information from support images, thereby failing to effectively address the large variance in appearance and scales of geographic objects. To tackle these challenges, we propose a Self-Correlation and Cross-Correlation Learning Network for the few-shot remote sensing image semantic segmentation. Our model enhances the generalization by considering both self-correlation and cross-correlation between support and query images to make segmentation predictions. To further explore the self-correlation with the query image, we propose to adopt a classical spectral method to produce a class-agnostic segmentation mask based on the basic visual information of the image. Extensive experiments on two remote sensing image datasets demonstrate the effectiveness and superiority of our model in few-shot remote sensing image semantic segmentation. Code and models will be accessed at https://github.com/linhanwang/SCCNet.
TART: Improved Few-shot Text Classification Using Task-Adaptive Reference Transformation
Jun 03, 2023

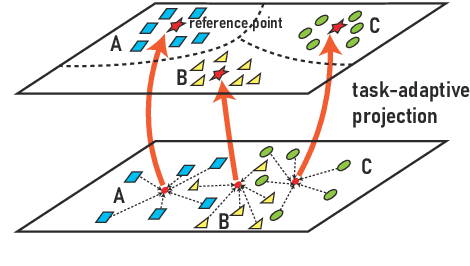
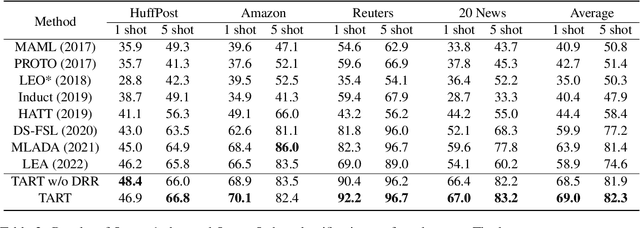
Meta-learning has emerged as a trending technique to tackle few-shot text classification and achieve state-of-the-art performance. However, the performance of existing approaches heavily depends on the inter-class variance of the support set. As a result, it can perform well on tasks when the semantics of sampled classes are distinct while failing to differentiate classes with similar semantics. In this paper, we propose a novel Task-Adaptive Reference Transformation (TART) network, aiming to enhance the generalization by transforming the class prototypes to per-class fixed reference points in task-adaptive metric spaces. To further maximize divergence between transformed prototypes in task-adaptive metric spaces, TART introduces a discriminative reference regularization among transformed prototypes. Extensive experiments are conducted on four benchmark datasets and our method demonstrates clear superiority over the state-of-the-art models in all the datasets. In particular, our model surpasses the state-of-the-art method by 7.4% and 5.4% in 1-shot and 5-shot classification on the 20 Newsgroups dataset, respectively.
Zero-Shot End-to-End Spoken Language Understanding via Cross-Modal Selective Self-Training
May 22, 2023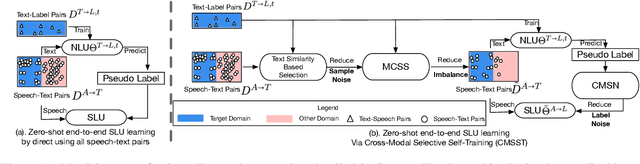
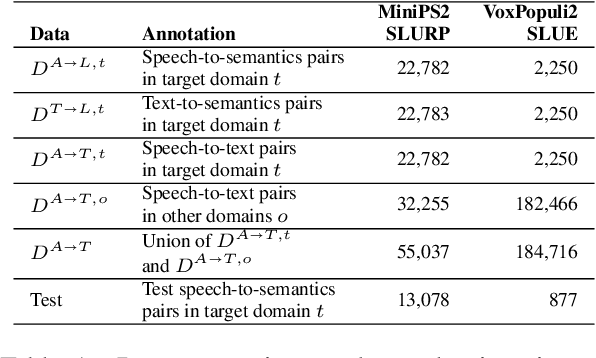
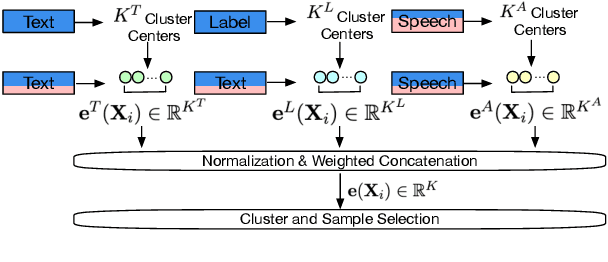
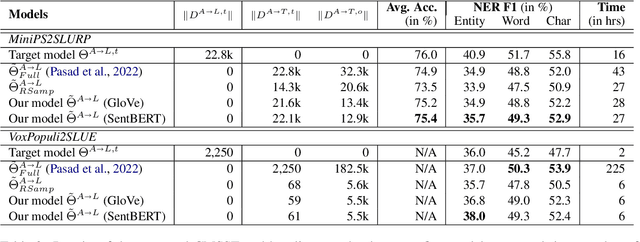
End-to-end (E2E) spoken language understanding (SLU) is constrained by the cost of collecting speech-semantics pairs, especially when label domains change. Hence, we explore \textit{zero-shot} E2E SLU, which learns E2E SLU without speech-semantics pairs, instead using only speech-text and text-semantics pairs. Previous work achieved zero-shot by pseudolabeling all speech-text transcripts with a natural language understanding (NLU) model learned on text-semantics corpora. However, this method requires the domains of speech-text and text-semantics to match, which often mismatch due to separate collections. Furthermore, using the entire speech-text corpus from any domains leads to \textit{imbalance} and \textit{noise} issues. To address these, we propose \textit{cross-modal selective self-training} (CMSST). CMSST tackles imbalance by clustering in a joint space of the three modalities (speech, text, and semantics) and handles label noise with a selection network. We also introduce two benchmarks for zero-shot E2E SLU, covering matched and found speech (mismatched) settings. Experiments show that CMSST improves performance in both two settings, with significantly reduced sample sizes and training time.
SE-ORNet: Self-Ensembling Orientation-aware Network for Unsupervised Point Cloud Shape Correspondence
Apr 10, 2023
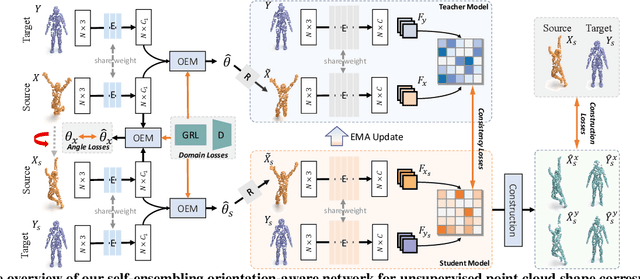
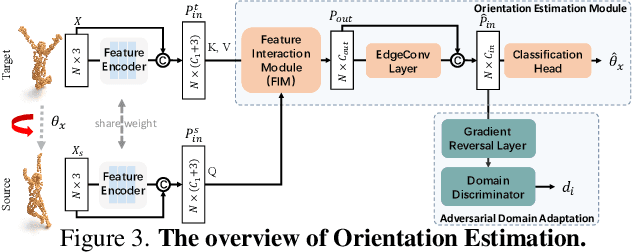
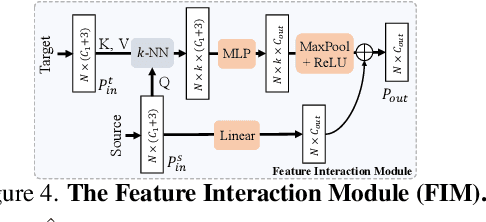
Unsupervised point cloud shape correspondence aims to obtain dense point-to-point correspondences between point clouds without manually annotated pairs. However, humans and some animals have bilateral symmetry and various orientations, which lead to severe mispredictions of symmetrical parts. Besides, point cloud noise disrupts consistent representations for point cloud and thus degrades the shape correspondence accuracy. To address the above issues, we propose a Self-Ensembling ORientation-aware Network termed SE-ORNet. The key of our approach is to exploit an orientation estimation module with a domain adaptive discriminator to align the orientations of point cloud pairs, which significantly alleviates the mispredictions of symmetrical parts. Additionally, we design a selfensembling framework for unsupervised point cloud shape correspondence. In this framework, the disturbances of point cloud noise are overcome by perturbing the inputs of the student and teacher networks with different data augmentations and constraining the consistency of predictions. Extensive experiments on both human and animal datasets show that our SE-ORNet can surpass state-of-the-art unsupervised point cloud shape correspondence methods.