 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYichi Zhang
Exploring the Transferability of Visual Prompting for Multimodal Large Language Models
Apr 17, 2024
Although Multimodal Large Language Models (MLLMs) have demonstrated promising versatile capabilities, their performance is still inferior to specialized models on downstream tasks, which makes adaptation necessary to enhance their utility. However, fine-tuning methods require independent training for every model, leading to huge computation and memory overheads. In this paper, we propose a novel setting where we aim to improve the performance of diverse MLLMs with a group of shared parameters optimized for a downstream task. To achieve this, we propose Transferable Visual Prompting (TVP), a simple and effective approach to generate visual prompts that can transfer to different models and improve their performance on downstream tasks after trained on only one model. We introduce two strategies to address the issue of cross-model feature corruption of existing visual prompting methods and enhance the transferability of the learned prompts, including 1) Feature Consistency Alignment: which imposes constraints to the prompted feature changes to maintain task-agnostic knowledge; 2) Task Semantics Enrichment: which encourages the prompted images to contain richer task-specific semantics with language guidance. We validate the effectiveness of TVP through extensive experiments with 6 modern MLLMs on a wide variety of tasks ranging from object recognition and counting to multimodal reasoning and hallucination correction.
MyGO: Discrete Modality Information as Fine-Grained Tokens for Multi-modal Knowledge Graph Completion
Apr 15, 2024Multi-modal knowledge graphs (MMKG) store structured world knowledge containing rich multi-modal descriptive information. To overcome their inherent incompleteness, multi-modal knowledge graph completion (MMKGC) aims to discover unobserved knowledge from given MMKGs, leveraging both structural information from the triples and multi-modal information of the entities. Existing MMKGC methods usually extract multi-modal features with pre-trained models and employ a fusion module to integrate multi-modal features with triple prediction. However, this often results in a coarse handling of multi-modal data, overlooking the nuanced, fine-grained semantic details and their interactions. To tackle this shortfall, we introduce a novel framework MyGO to process, fuse, and augment the fine-grained modality information from MMKGs. MyGO tokenizes multi-modal raw data as fine-grained discrete tokens and learns entity representations with a cross-modal entity encoder. To further augment the multi-modal representations, MyGO incorporates fine-grained contrastive learning to highlight the specificity of the entity representations. Experiments on standard MMKGC benchmarks reveal that our method surpasses 20 of the latest models, underlining its superior performance. Code and data are available at https://github.com/zjukg/MyGO
Autonomous Evaluation and Refinement of Digital Agents
Apr 10, 2024We show that domain-general automatic evaluators can significantly improve the performance of agents for web navigation and device control. We experiment with multiple evaluation models that trade off between inference cost, modularity of design, and accuracy. We validate the performance of these models in several popular benchmarks for digital agents, finding between 74.4 and 92.9% agreement with oracle evaluation metrics. Finally, we use these evaluators to improve the performance of existing agents via fine-tuning and inference-time guidance. Without any additional supervision, we improve state-of-the-art performance by 29% on the popular benchmark WebArena, and achieve a 75% relative improvement in a challenging domain transfer scenario.
Movable Antenna-Aided Hybrid Beamforming for Multi-User Communications
Apr 01, 2024In this correspondence, we propose a movable antenna (MA)-aided multi-user hybrid beamforming scheme with a sub-connected structure, where multiple movable sub-arrays can independently change their positions within different local regions. To maximize the system sum rate, we jointly optimize the digital beamformer, analog beamformer, and positions of subarrays, under the constraints of unit modulus, finite movable regions, and power budget. Due to the non-concave/non-convex objective function/constraints, as well as the highly coupled variables, the formulated problem is challenging to solve. By employing fractional programming, we develop an alternating optimization framework to solve the problem via a combination of Lagrange multipliers, penalty method, and gradient descent. Numerical results reveal that the proposed MA-aided hybrid beamforming scheme significantly improves the sum rate compared to its fixed-position antenna (FPA) counterpart. Moreover, with sufficiently large movable regions, the proposed scheme with sub-connected MA arrays even outperforms the fully-connected FPA array.
Evaluating the Factuality of Large Language Models using Large-Scale Knowledge Graphs
Apr 01, 2024The advent of Large Language Models (LLMs) has significantly transformed the AI landscape, enhancing machine learning and AI capabilities. Factuality issue is a critical concern for LLMs, as they may generate factually incorrect responses. In this paper, we propose GraphEval to evaluate an LLM's performance using a substantially large test dataset. Specifically, the test dataset is retrieved from a large knowledge graph with more than 10 million facts without expensive human efforts. Unlike conventional methods that evaluate LLMs based on generated responses, GraphEval streamlines the evaluation process by creating a judge model to estimate the correctness of the answers given by the LLM. Our experiments demonstrate that the judge model's factuality assessment aligns closely with the correctness of the LLM's generated outputs, while also substantially reducing evaluation costs. Besides, our findings offer valuable insights into LLM performance across different metrics and highlight the potential for future improvements in ensuring the factual integrity of LLM outputs. The code is publicly available at https://github.com/xz-liu/GraphEval.
Theoretical Bound-Guided Hierarchical VAE for Neural Image Codecs
Mar 27, 2024Recent studies reveal a significant theoretical link between variational autoencoders (VAEs) and rate-distortion theory, notably in utilizing VAEs to estimate the theoretical upper bound of the information rate-distortion function of images. Such estimated theoretical bounds substantially exceed the performance of existing neural image codecs (NICs). To narrow this gap, we propose a theoretical bound-guided hierarchical VAE (BG-VAE) for NIC. The proposed BG-VAE leverages the theoretical bound to guide the NIC model towards enhanced performance. We implement the BG-VAE using Hierarchical VAEs and demonstrate its effectiveness through extensive experiments. Along with advanced neural network blocks, we provide a versatile, variable-rate NIC that outperforms existing methods when considering both rate-distortion performance and computational complexity. The code is available at BG-VAE.
MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?
Mar 21, 2024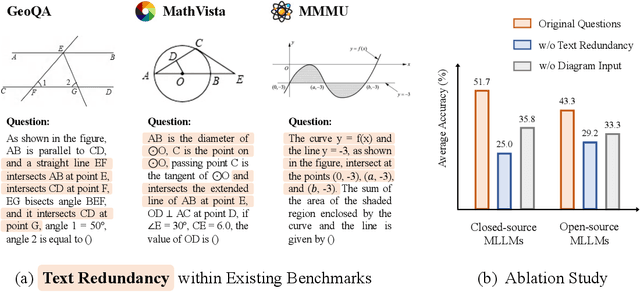

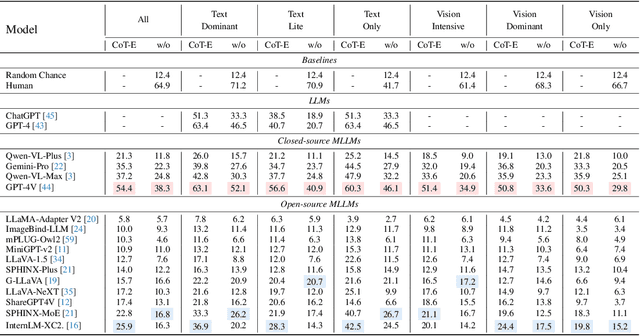
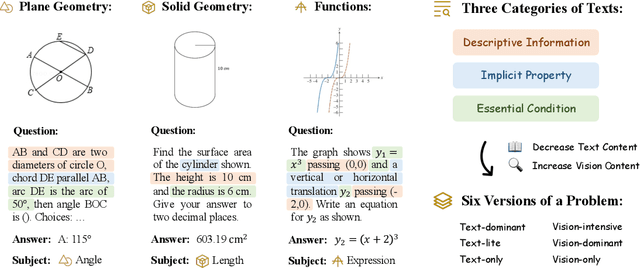
The remarkable progress of Multi-modal Large Language Models (MLLMs) has garnered unparalleled attention, due to their superior performance in visual contexts. However, their capabilities in visual math problem-solving remain insufficiently evaluated and understood. We investigate current benchmarks to incorporate excessive visual content within textual questions, which potentially assist MLLMs in deducing answers without truly interpreting the input diagrams. To this end, we introduce MathVerse, an all-around visual math benchmark designed for an equitable and in-depth evaluation of MLLMs. We meticulously collect 2,612 high-quality, multi-subject math problems with diagrams from publicly available sources. Each problem is then transformed by human annotators into six distinct versions, each offering varying degrees of information content in multi-modality, contributing to 15K test samples in total. This approach allows MathVerse to comprehensively assess whether and how much MLLMs can truly understand the visual diagrams for mathematical reasoning. In addition, we propose a Chain-of-Thought (CoT) evaluation strategy for a fine-grained assessment of the output answers. Rather than naively judging True or False, we employ GPT-4(V) to adaptively extract crucial reasoning steps, and then score each step with detailed error analysis, which can reveal the intermediate CoT reasoning quality by MLLMs. We hope the MathVerse benchmark may provide unique insights to guide the future development of MLLMs. Project page: https://mathverse-cuhk.github.io
The Power of Noise: Toward a Unified Multi-modal Knowledge Graph Representation Framework
Mar 20, 2024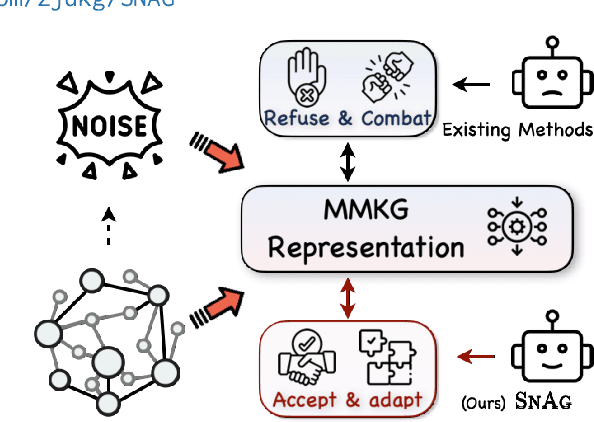
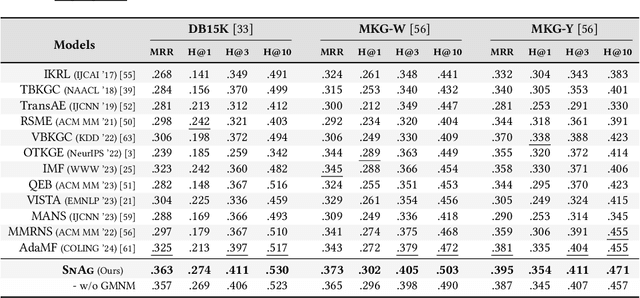
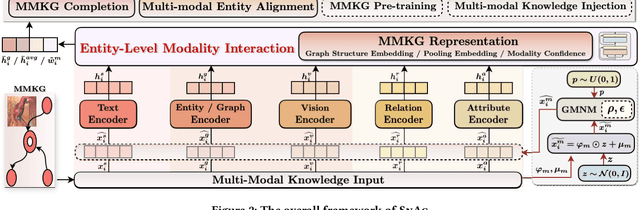
The advancement of Multi-modal Pre-training highlights the necessity for a robust Multi-Modal Knowledge Graph (MMKG) representation learning framework. This framework is crucial for integrating structured knowledge into multi-modal Large Language Models (LLMs) at scale, aiming to alleviate issues like knowledge misconceptions and multi-modal hallucinations. In this work, to evaluate models' ability to accurately embed entities within MMKGs, we focus on two widely researched tasks: Multi-modal Knowledge Graph Completion (MKGC) and Multi-modal Entity Alignment (MMEA). Building on this foundation, we propose a novel SNAG method that utilizes a Transformer-based architecture equipped with modality-level noise masking for the robust integration of multi-modal entity features in KGs. By incorporating specific training objectives for both MKGC and MMEA, our approach achieves SOTA performance across a total of ten datasets (three for MKGC and seven for MEMA), demonstrating its robustness and versatility. Besides, SNAG can not only function as a standalone model but also enhance other existing methods, providing stable performance improvements. Our code and data are available at: https://github.com/zjukg/SNAG.
D-Net: Dynamic Large Kernel with Dynamic Feature Fusion for Volumetric Medical Image Segmentation
Mar 15, 2024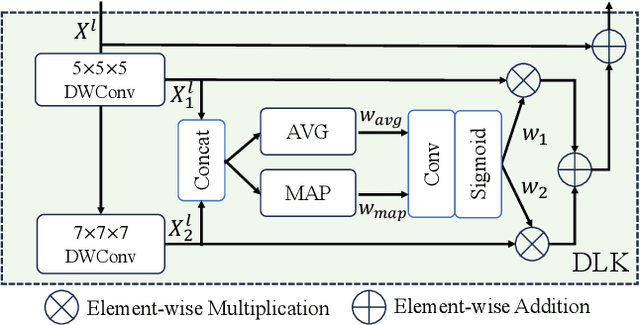
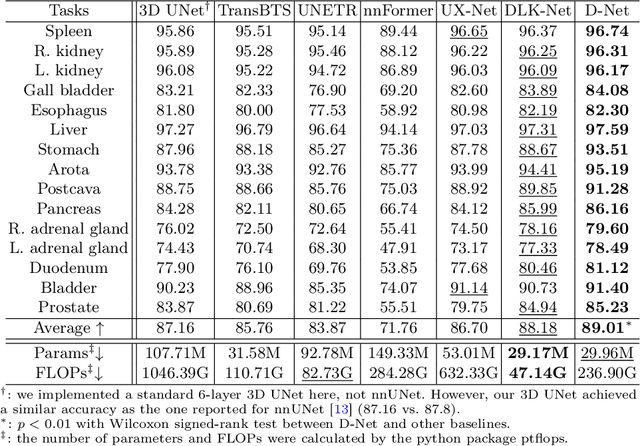
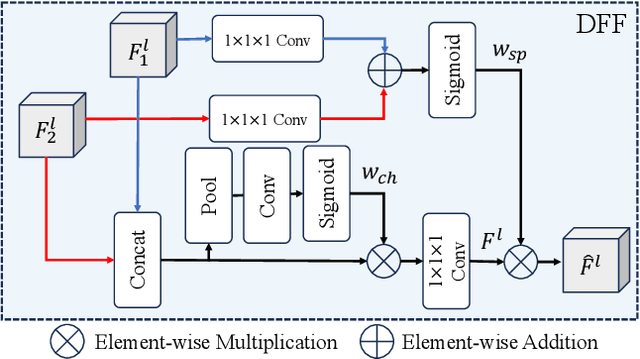
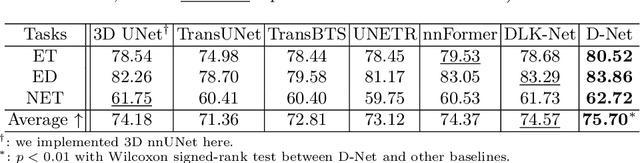
Hierarchical transformers have achieved significant success in medical image segmentation due to their large receptive field and capabilities of effectively leveraging global long-range contextual information. Convolutional neural networks (CNNs) can also deliver a large receptive field by using large kernels, enabling them to achieve competitive performance with fewer model parameters. However, CNNs incorporated with large convolutional kernels remain constrained in adaptively capturing multi-scale features from organs with large variations in shape and size due to the employment of fixed-sized kernels. Additionally, they are unable to utilize global contextual information efficiently. To address these limitations, we propose Dynamic Large Kernel (DLK) and Dynamic Feature Fusion (DFF) modules. The DLK module employs multiple large kernels with varying kernel sizes and dilation rates to capture multi-scale features. Subsequently, a dynamic selection mechanism is utilized to adaptively highlight the most important spatial features based on global information. Additionally, the DFF module is proposed to adaptively fuse multi-scale local feature maps based on their global information. We integrate DLK and DFF in a hierarchical transformer architecture to develop a novel architecture, termed D-Net. D-Net is able to effectively utilize a multi-scale large receptive field and adaptively harness global contextual information. Extensive experimental results demonstrate that D-Net outperforms other state-of-the-art models in the two volumetric segmentation tasks, including abdominal multi-organ segmentation and multi-modality brain tumor segmentation. Our code is available at https://github.com/sotiraslab/DLK.