 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinbin Hu
How Do Recommendation Models Amplify Popularity Bias? An Analysis from the Spectral Perspective
Apr 18, 2024
Recommendation Systems (RS) are often plagued by popularity bias. Specifically,when recommendation models are trained on long-tailed datasets, they not only inherit this bias but often exacerbate it. This effect undermines both the precision and fairness of RS and catalyzes the so-called Matthew Effect. Despite the widely recognition of this issue, the fundamental causes remain largely elusive. In our research, we delve deeply into popularity bias amplification. Our comprehensive theoretical and empirical investigations lead to two core insights: 1) Item popularity is memorized in the principal singular vector of the score matrix predicted by the recommendation model; 2) The dimension collapse phenomenon amplifies the impact of principal singular vector on model predictions, intensifying the popularity bias. Based on these insights, we propose a novel method to mitigate this bias by imposing penalties on the magnitude of the principal singular value. Considering the heavy computational burden in directly evaluating the gradient of the principal singular value, we develop an efficient algorithm that harnesses the inherent properties of the singular vector. Extensive experiments across seven real-world datasets and three testing scenarios have been conducted to validate the superiority of our method.
MyGO: Discrete Modality Information as Fine-Grained Tokens for Multi-modal Knowledge Graph Completion
Apr 15, 2024Multi-modal knowledge graphs (MMKG) store structured world knowledge containing rich multi-modal descriptive information. To overcome their inherent incompleteness, multi-modal knowledge graph completion (MMKGC) aims to discover unobserved knowledge from given MMKGs, leveraging both structural information from the triples and multi-modal information of the entities. Existing MMKGC methods usually extract multi-modal features with pre-trained models and employ a fusion module to integrate multi-modal features with triple prediction. However, this often results in a coarse handling of multi-modal data, overlooking the nuanced, fine-grained semantic details and their interactions. To tackle this shortfall, we introduce a novel framework MyGO to process, fuse, and augment the fine-grained modality information from MMKGs. MyGO tokenizes multi-modal raw data as fine-grained discrete tokens and learns entity representations with a cross-modal entity encoder. To further augment the multi-modal representations, MyGO incorporates fine-grained contrastive learning to highlight the specificity of the entity representations. Experiments on standard MMKGC benchmarks reveal that our method surpasses 20 of the latest models, underlining its superior performance. Code and data are available at https://github.com/zjukg/MyGO
Can Small Language Models be Good Reasoners for Sequential Recommendation?
Mar 07, 2024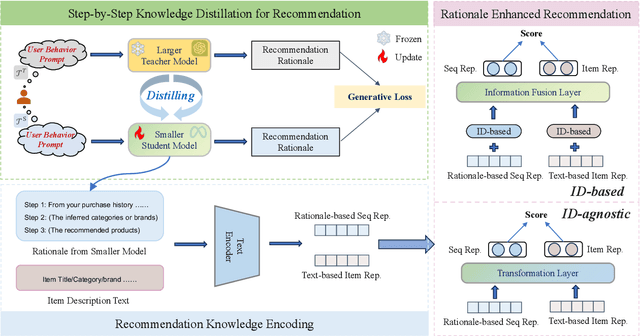
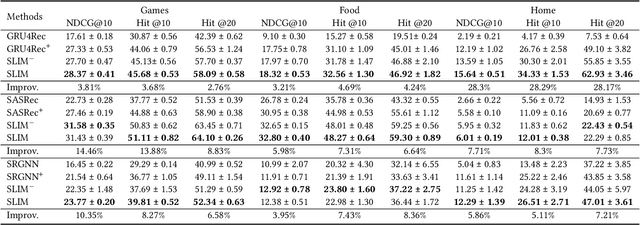


Large language models (LLMs) open up new horizons for sequential recommendations, owing to their remarkable language comprehension and generation capabilities. However, there are still numerous challenges that should be addressed to successfully implement sequential recommendations empowered by LLMs. Firstly, user behavior patterns are often complex, and relying solely on one-step reasoning from LLMs may lead to incorrect or task-irrelevant responses. Secondly, the prohibitively resource requirements of LLM (e.g., ChatGPT-175B) are overwhelmingly high and impractical for real sequential recommender systems. In this paper, we propose a novel Step-by-step knowLedge dIstillation fraMework for recommendation (SLIM), paving a promising path for sequential recommenders to enjoy the exceptional reasoning capabilities of LLMs in a "slim" (i.e., resource-efficient) manner. We introduce CoT prompting based on user behavior sequences for the larger teacher model. The rationales generated by the teacher model are then utilized as labels to distill the downstream smaller student model (e.g., LLaMA2-7B). In this way, the student model acquires the step-by-step reasoning capabilities in recommendation tasks. We encode the generated rationales from the student model into a dense vector, which empowers recommendation in both ID-based and ID-agnostic scenarios. Extensive experiments demonstrate the effectiveness of SLIM over state-of-the-art baselines, and further analysis showcasing its ability to generate meaningful recommendation reasoning at affordable costs.
Know Your Needs Better: Towards Structured Understanding of Marketer Demands with Analogical Reasoning Augmented LLMs
Jan 09, 2024In this paper, we explore a new way for user targeting, where non-expert marketers could select their target users solely given demands in natural language form. The key to this issue is how to transform natural languages into practical structured logical languages, i.e., the structured understanding of marketer demands. Considering the impressive natural language processing ability of large language models (LLMs), we try to leverage LLMs to solve this issue. Past research indicates that the reasoning ability of LLMs can be effectively enhanced through chain-of-thought (CoT) prompting. But existing methods still have some limitations: (1) Previous methods either use simple "Let's think step by step" spells or provide fixed examples in demonstrations without considering compatibility between prompts and questions, making LLMs ineffective in some complex reasoning tasks such as structured language transformation. (2) Previous methods are often implemented in closed-source models or excessively large models, which is not suitable in industrial practical scenarios. Based on these, we propose ARALLM (i.e., Analogical Reasoning Augmented Large Language Models) consisting of two modules: Analogical Reasoning based Prompting and Reasoning-Augmented Multi-Task Model Distillation.
Not All Negatives Are Worth Attending to: Meta-Bootstrapping Negative Sampling Framework for Link Prediction
Dec 12, 2023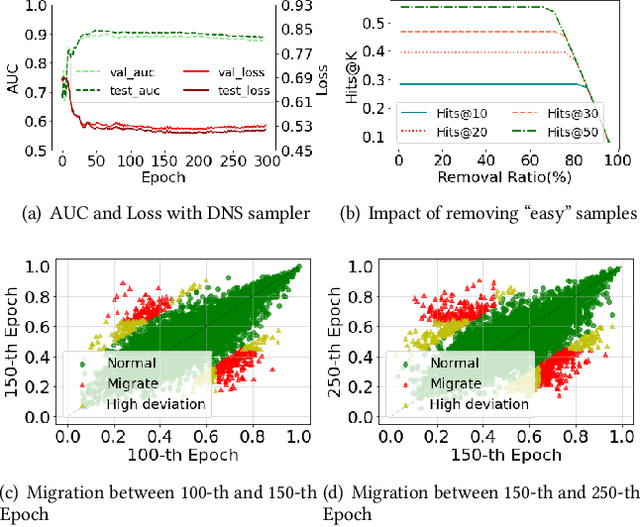
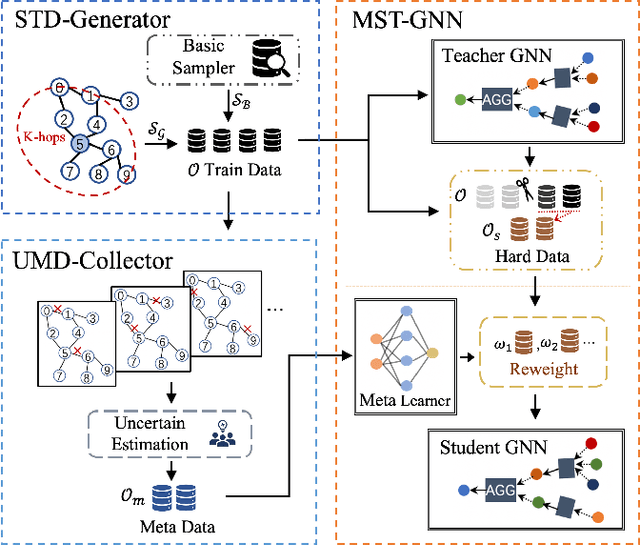
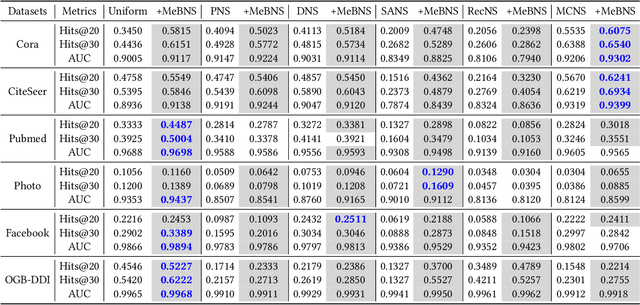
The rapid development of graph neural networks (GNNs) encourages the rising of link prediction, achieving promising performance with various applications. Unfortunately, through a comprehensive analysis, we surprisingly find that current link predictors with dynamic negative samplers (DNSs) suffer from the migration phenomenon between "easy" and "hard" samples, which goes against the preference of DNS of choosing "hard" negatives, thus severely hindering capability. Towards this end, we propose the MeBNS framework, serving as a general plugin that can potentially improve current negative sampling based link predictors. In particular, we elaborately devise a Meta-learning Supported Teacher-student GNN (MST-GNN) that is not only built upon teacher-student architecture for alleviating the migration between "easy" and "hard" samples but also equipped with a meta learning based sample re-weighting module for helping the student GNN distinguish "hard" samples in a fine-grained manner. To effectively guide the learning of MST-GNN, we prepare a Structure enhanced Training Data Generator (STD-Generator) and an Uncertainty based Meta Data Collector (UMD-Collector) for supporting the teacher and student GNN, respectively. Extensive experiments show that the MeBNS achieves remarkable performance across six link prediction benchmark datasets.
Making Large Language Models Better Knowledge Miners for Online Marketing with Progressive Prompting Augmentation
Dec 08, 2023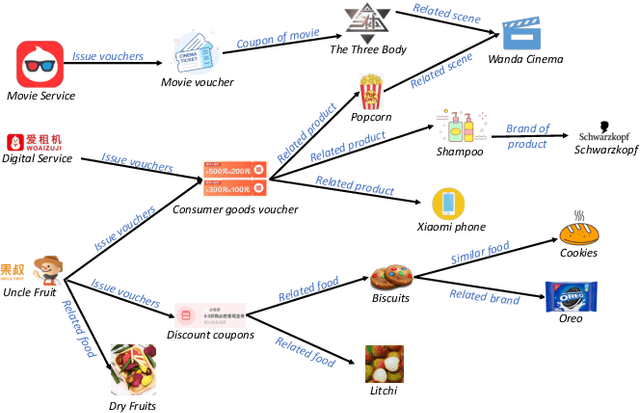
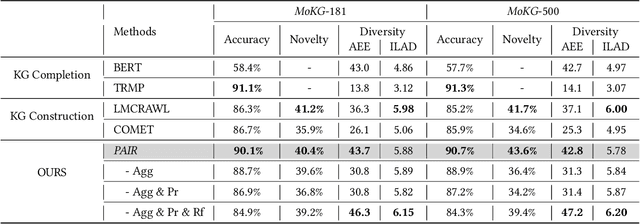
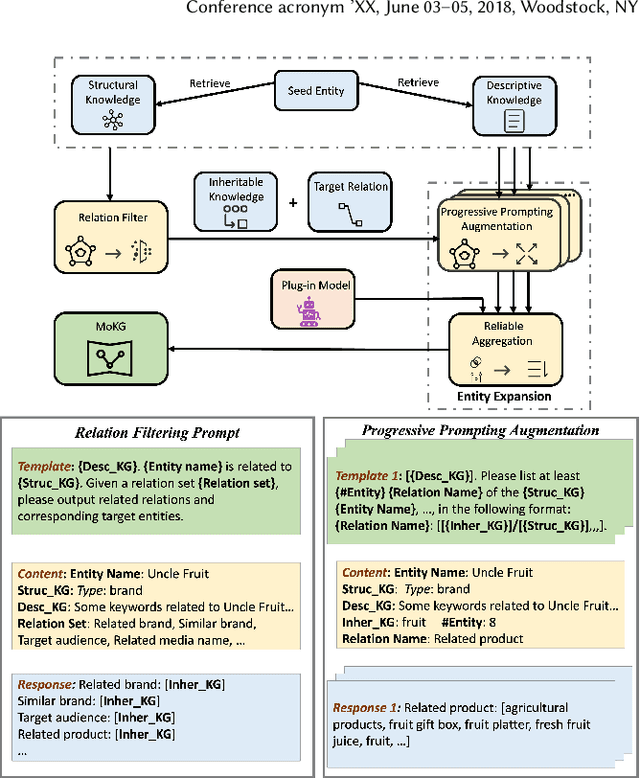
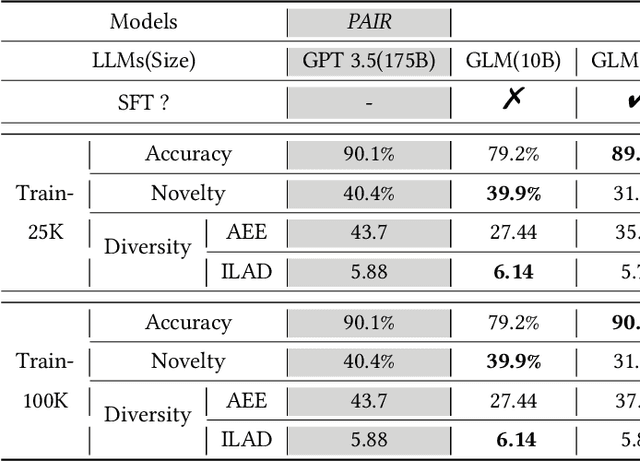
Nowadays, the rapid development of mobile economy has promoted the flourishing of online marketing campaigns, whose success greatly hinges on the efficient matching between user preferences and desired marketing campaigns where a well-established Marketing-oriented Knowledge Graph (dubbed as MoKG) could serve as the critical "bridge" for preference propagation. In this paper, we seek to carefully prompt a Large Language Model (LLM) with domain-level knowledge as a better marketing-oriented knowledge miner for marketing-oriented knowledge graph construction, which is however non-trivial, suffering from several inevitable issues in real-world marketing scenarios, i.e., uncontrollable relation generation of LLMs,insufficient prompting ability of a single prompt, the unaffordable deployment cost of LLMs. To this end, we propose PAIR, a novel Progressive prompting Augmented mIning fRamework for harvesting marketing-oriented knowledge graph with LLMs. In particular, we reduce the pure relation generation to an LLM based adaptive relation filtering process through the knowledge-empowered prompting technique. Next, we steer LLMs for entity expansion with progressive prompting augmentation,followed by a reliable aggregation with comprehensive consideration of both self-consistency and semantic relatedness. In terms of online serving, we specialize in a small and white-box PAIR (i.e.,LightPAIR),which is fine-tuned with a high-quality corpus provided by a strong teacher-LLM. Extensive experiments and practical applications in audience targeting verify the effectiveness of the proposed (Light)PAIR.
PEACE: Prototype lEarning Augmented transferable framework for Cross-domain rEcommendation
Dec 04, 2023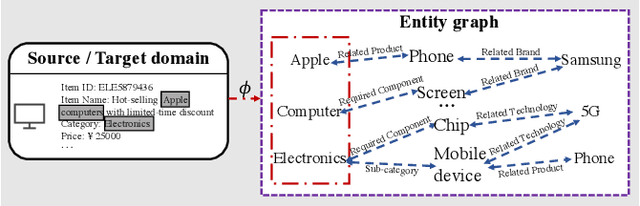
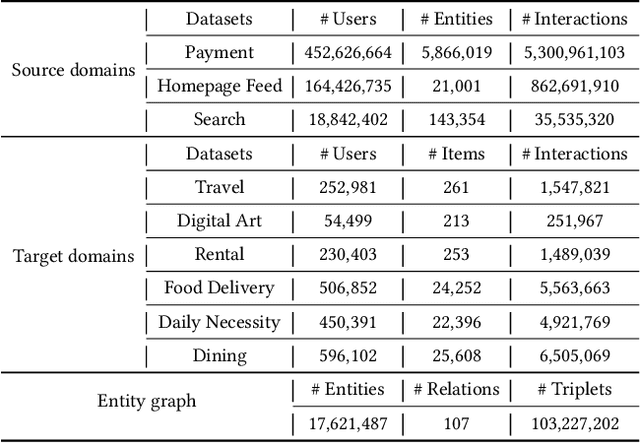
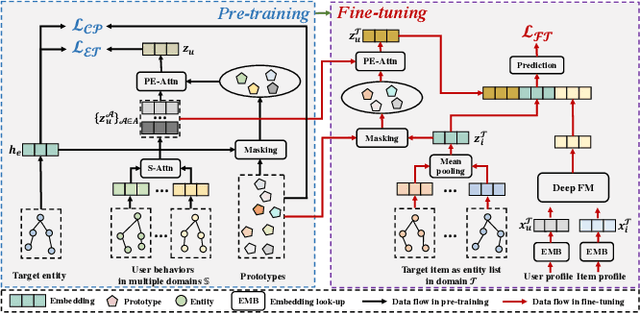
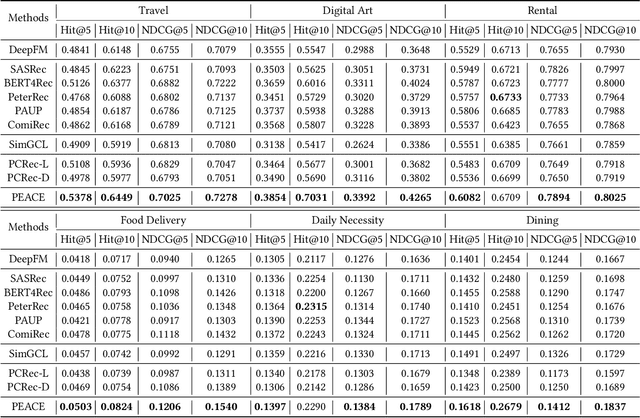
To help merchants/customers to provide/access a variety of services through miniapps, online service platforms have occupied a critical position in the effective content delivery, in which how to recommend items in the new domain launched by the service provider for customers has become more urgent. However, the non-negligible gap between the source and diversified target domains poses a considerable challenge to cross-domain recommendation systems, which often leads to performance bottlenecks in industrial settings. While entity graphs have the potential to serve as a bridge between domains, rudimentary utilization still fail to distill useful knowledge and even induce the negative transfer issue. To this end, we propose PEACE, a Prototype lEarning Augmented transferable framework for Cross-domain rEcommendation. For domain gap bridging, PEACE is built upon a multi-interest and entity-oriented pre-training architecture which could not only benefit the learning of generalized knowledge in a multi-granularity manner, but also help leverage more structural information in the entity graph. Then, we bring the prototype learning into the pre-training over source domains, so that representations of users and items are greatly improved by the contrastive prototype learning module and the prototype enhanced attention mechanism for adaptive knowledge utilization. To ease the pressure of online serving, PEACE is carefully deployed in a lightweight manner, and significant performance improvements are observed in both online and offline environments.
Which Matters Most in Making Fund Investment Decisions? A Multi-granularity Graph Disentangled Learning Framework
Nov 23, 2023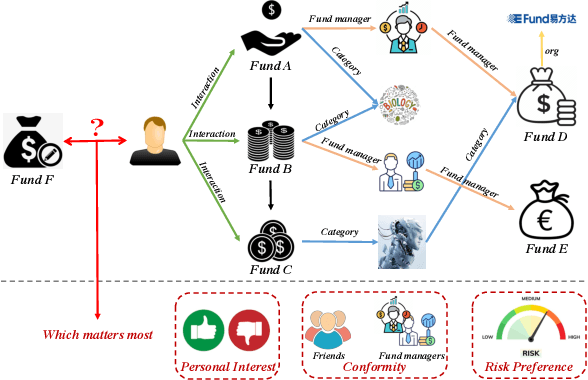
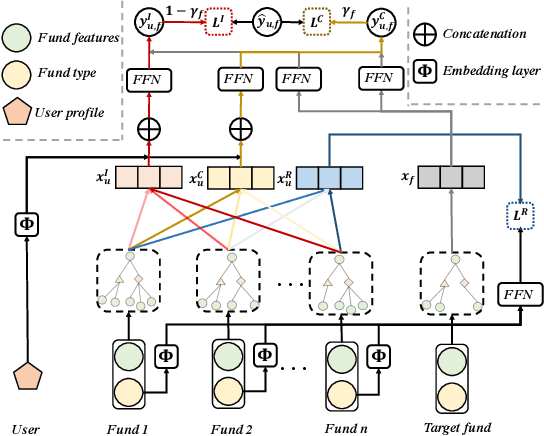

In this paper, we highlight that both conformity and risk preference matter in making fund investment decisions beyond personal interest and seek to jointly characterize these aspects in a disentangled manner. Consequently, we develop a novel M ulti-granularity Graph Disentangled Learning framework named MGDL to effectively perform intelligent matching of fund investment products. Benefiting from the well-established fund graph and the attention module, multi-granularity user representations are derived from historical behaviors to separately express personal interest, conformity and risk preference in a fine-grained way. To attain stronger disentangled representations with specific semantics, MGDL explicitly involve two self-supervised signals, i.e., fund type based contrasts and fund popularity. Extensive experiments in offline and online environments verify the effectiveness of MGDL.
Think-in-Memory: Recalling and Post-thinking Enable LLMs with Long-Term Memory
Nov 15, 2023Memory-augmented Large Language Models (LLMs) have demonstrated remarkable performance in long-term human-machine interactions, which basically relies on iterative recalling and reasoning of history to generate high-quality responses. However, such repeated recall-reason steps easily produce biased thoughts, \textit{i.e.}, inconsistent reasoning results when recalling the same history for different questions. On the contrary, humans can keep thoughts in the memory and recall them without repeated reasoning. Motivated by this human capability, we propose a novel memory mechanism called TiM (Think-in-Memory) that enables LLMs to maintain an evolved memory for storing historical thoughts along the conversation stream. The TiM framework consists of two crucial stages: (1) before generating a response, a LLM agent recalls relevant thoughts from memory, and (2) after generating a response, the LLM agent post-thinks and incorporates both historical and new thoughts to update the memory. Thus, TiM can eliminate the issue of repeated reasoning by saving the post-thinking thoughts as the history. Besides, we formulate the basic principles to organize the thoughts in memory based on the well-established operations, (\textit{i.e.}, insert, forget, and merge operations), allowing for dynamic updates and evolution of the thoughts. Furthermore, we introduce Locality-Sensitive Hashing into TiM to achieve efficient retrieval for the long-term conversations. We conduct qualitative and quantitative experiments on real-world and simulated dialogues covering a wide range of topics, demonstrating that equipping existing LLMs with TiM significantly enhances their performance in generating responses for long-term interactions.
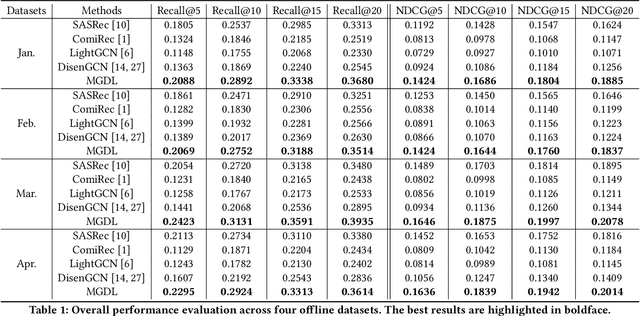
InferTurbo: A Scalable System for Boosting Full-graph Inference of Graph Neural Network over Huge Graphs
Jul 01, 2023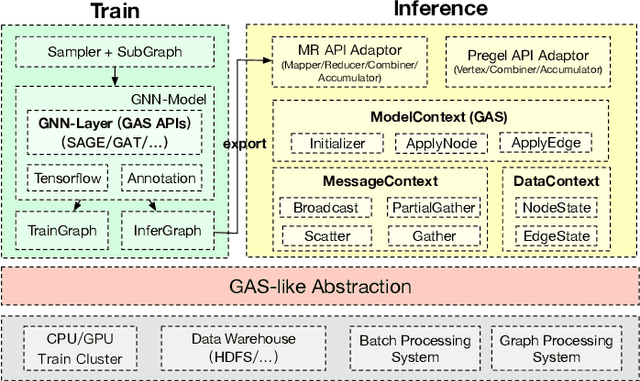
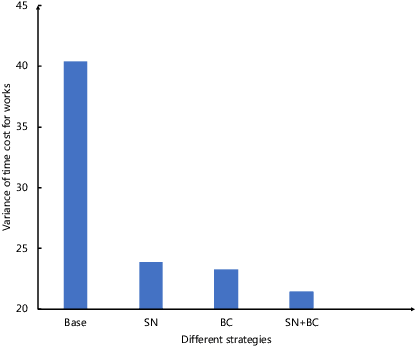
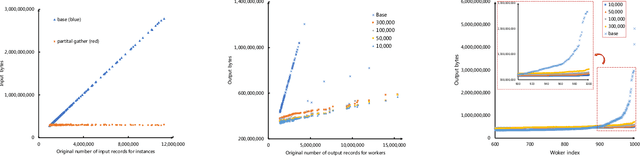

GNN inference is a non-trivial task, especially in industrial scenarios with giant graphs, given three main challenges, i.e., scalability tailored for full-graph inference on huge graphs, inconsistency caused by stochastic acceleration strategies (e.g., sampling), and the serious redundant computation issue. To address the above challenges, we propose a scalable system named InferTurbo to boost the GNN inference tasks in industrial scenarios. Inspired by the philosophy of ``think-like-a-vertex", a GAS-like (Gather-Apply-Scatter) schema is proposed to describe the computation paradigm and data flow of GNN inference. The computation of GNNs is expressed in an iteration manner, in which a vertex would gather messages via in-edges and update its state information by forwarding an associated layer of GNNs with those messages and then send the updated information to other vertexes via out-edges. Following the schema, the proposed InferTurbo can be built with alternative backends (e.g., batch processing system or graph computing system). Moreover, InferTurbo introduces several strategies like shadow-nodes and partial-gather to handle nodes with large degrees for better load balancing. With InferTurbo, GNN inference can be hierarchically conducted over the full graph without sampling and redundant computation. Experimental results demonstrate that our system is robust and efficient for inference tasks over graphs containing some hub nodes with many adjacent edges. Meanwhile, the system gains a remarkable performance compared with the traditional inference pipeline, and it can finish a GNN inference task over a graph with tens of billions of nodes and hundreds of billions of edges within 2 hours.