 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingbing Guo
MyGO: Discrete Modality Information as Fine-Grained Tokens for Multi-modal Knowledge Graph Completion
Apr 15, 2024
Multi-modal knowledge graphs (MMKG) store structured world knowledge containing rich multi-modal descriptive information. To overcome their inherent incompleteness, multi-modal knowledge graph completion (MMKGC) aims to discover unobserved knowledge from given MMKGs, leveraging both structural information from the triples and multi-modal information of the entities. Existing MMKGC methods usually extract multi-modal features with pre-trained models and employ a fusion module to integrate multi-modal features with triple prediction. However, this often results in a coarse handling of multi-modal data, overlooking the nuanced, fine-grained semantic details and their interactions. To tackle this shortfall, we introduce a novel framework MyGO to process, fuse, and augment the fine-grained modality information from MMKGs. MyGO tokenizes multi-modal raw data as fine-grained discrete tokens and learns entity representations with a cross-modal entity encoder. To further augment the multi-modal representations, MyGO incorporates fine-grained contrastive learning to highlight the specificity of the entity representations. Experiments on standard MMKGC benchmarks reveal that our method surpasses 20 of the latest models, underlining its superior performance. Code and data are available at https://github.com/zjukg/MyGO
The Power of Noise: Toward a Unified Multi-modal Knowledge Graph Representation Framework
Mar 20, 2024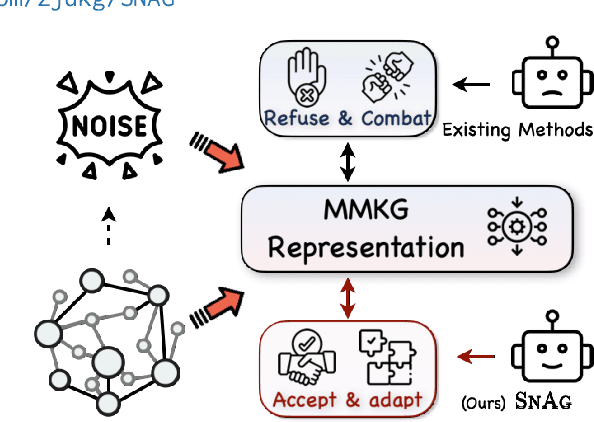
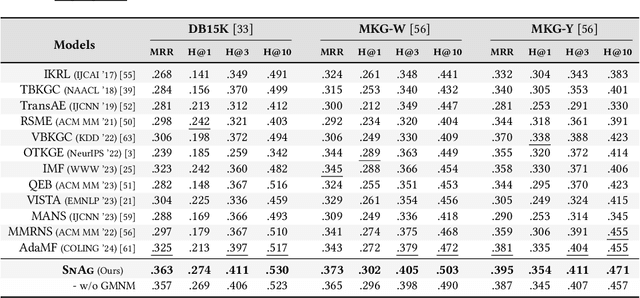
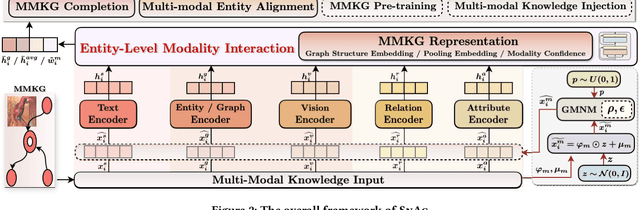
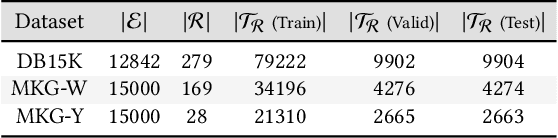
The advancement of Multi-modal Pre-training highlights the necessity for a robust Multi-Modal Knowledge Graph (MMKG) representation learning framework. This framework is crucial for integrating structured knowledge into multi-modal Large Language Models (LLMs) at scale, aiming to alleviate issues like knowledge misconceptions and multi-modal hallucinations. In this work, to evaluate models' ability to accurately embed entities within MMKGs, we focus on two widely researched tasks: Multi-modal Knowledge Graph Completion (MKGC) and Multi-modal Entity Alignment (MMEA). Building on this foundation, we propose a novel SNAG method that utilizes a Transformer-based architecture equipped with modality-level noise masking for the robust integration of multi-modal entity features in KGs. By incorporating specific training objectives for both MKGC and MMEA, our approach achieves SOTA performance across a total of ten datasets (three for MKGC and seven for MEMA), demonstrating its robustness and versatility. Besides, SNAG can not only function as a standalone model but also enhance other existing methods, providing stable performance improvements. Our code and data are available at: https://github.com/zjukg/SNAG.
Knowledge Graphs Meet Multi-Modal Learning: A Comprehensive Survey
Feb 26, 2024



Knowledge Graphs (KGs) play a pivotal role in advancing various AI applications, with the semantic web community's exploration into multi-modal dimensions unlocking new avenues for innovation. In this survey, we carefully review over 300 articles, focusing on KG-aware research in two principal aspects: KG-driven Multi-Modal (KG4MM) learning, where KGs support multi-modal tasks, and Multi-Modal Knowledge Graph (MM4KG), which extends KG studies into the MMKG realm. We begin by defining KGs and MMKGs, then explore their construction progress. Our review includes two primary task categories: KG-aware multi-modal learning tasks, such as Image Classification and Visual Question Answering, and intrinsic MMKG tasks like Multi-modal Knowledge Graph Completion and Entity Alignment, highlighting specific research trajectories. For most of these tasks, we provide definitions, evaluation benchmarks, and additionally outline essential insights for conducting relevant research. Finally, we discuss current challenges and identify emerging trends, such as progress in Large Language Modeling and Multi-modal Pre-training strategies. This survey aims to serve as a comprehensive reference for researchers already involved in or considering delving into KG and multi-modal learning research, offering insights into the evolving landscape of MMKG research and supporting future work.
ASGEA: Exploiting Logic Rules from Align-Subgraphs for Entity Alignment
Feb 16, 2024Entity alignment (EA) aims to identify entities across different knowledge graphs that represent the same real-world objects. Recent embedding-based EA methods have achieved state-of-the-art performance in EA yet faced interpretability challenges as they purely rely on the embedding distance and neglect the logic rules behind a pair of aligned entities. In this paper, we propose the Align-Subgraph Entity Alignment (ASGEA) framework to exploit logic rules from Align-Subgraphs. ASGEA uses anchor links as bridges to construct Align-Subgraphs and spreads along the paths across KGs, which distinguishes it from the embedding-based methods. Furthermore, we design an interpretable Path-based Graph Neural Network, ASGNN, to effectively identify and integrate the logic rules across KGs. We also introduce a node-level multi-modal attention mechanism coupled with multi-modal enriched anchors to augment the Align-Subgraph. Our experimental results demonstrate the superior performance of ASGEA over the existing embedding-based methods in both EA and Multi-Modal EA (MMEA) tasks. Our code will be available soon.
Universal Multi-modal Entity Alignment via Iteratively Fusing Modality Similarity Paths
Oct 13, 2023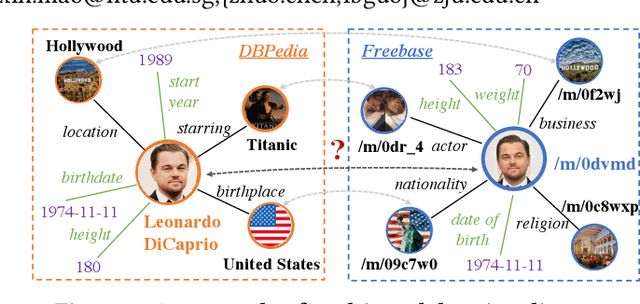
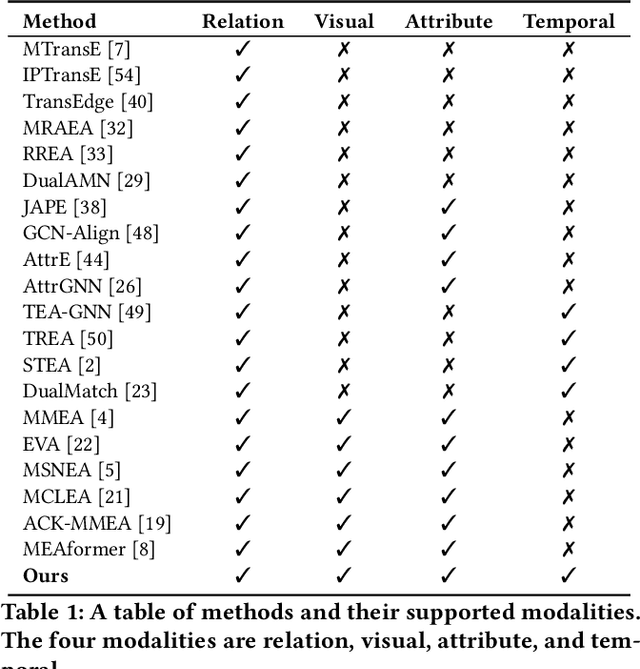

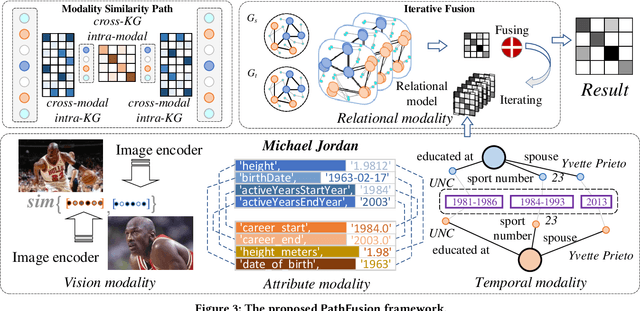
The objective of Entity Alignment (EA) is to identify equivalent entity pairs from multiple Knowledge Graphs (KGs) and create a more comprehensive and unified KG. The majority of EA methods have primarily focused on the structural modality of KGs, lacking exploration of multi-modal information. A few multi-modal EA methods have made good attempts in this field. Still, they have two shortcomings: (1) inconsistent and inefficient modality modeling that designs complex and distinct models for each modality; (2) ineffective modality fusion due to the heterogeneous nature of modalities in EA. To tackle these challenges, we propose PathFusion, consisting of two main components: (1) MSP, a unified modeling approach that simplifies the alignment process by constructing paths connecting entities and modality nodes to represent multiple modalities; (2) IRF, an iterative fusion method that effectively combines information from different modalities using the path as an information carrier. Experimental results on real-world datasets demonstrate the superiority of PathFusion over state-of-the-art methods, with 22.4%-28.9% absolute improvement on Hits@1, and 0.194-0.245 absolute improvement on MRR.
Rethinking Uncertainly Missing and Ambiguous Visual Modality in Multi-Modal Entity Alignment
Aug 01, 2023



As a crucial extension of entity alignment (EA), multi-modal entity alignment (MMEA) aims to identify identical entities across disparate knowledge graphs (KGs) by exploiting associated visual information. However, existing MMEA approaches primarily concentrate on the fusion paradigm of multi-modal entity features, while neglecting the challenges presented by the pervasive phenomenon of missing and intrinsic ambiguity of visual images. In this paper, we present a further analysis of visual modality incompleteness, benchmarking latest MMEA models on our proposed dataset MMEA-UMVM, where the types of alignment KGs covering bilingual and monolingual, with standard (non-iterative) and iterative training paradigms to evaluate the model performance. Our research indicates that, in the face of modality incompleteness, models succumb to overfitting the modality noise, and exhibit performance oscillations or declines at high rates of missing modality. This proves that the inclusion of additional multi-modal data can sometimes adversely affect EA. To address these challenges, we introduce UMAEA , a robust multi-modal entity alignment approach designed to tackle uncertainly missing and ambiguous visual modalities. It consistently achieves SOTA performance across all 97 benchmark splits, significantly surpassing existing baselines with limited parameters and time consumption, while effectively alleviating the identified limitations of other models. Our code and benchmark data are available at https://github.com/zjukg/UMAEA.
Revisit and Outstrip Entity Alignment: A Perspective of Generative Models
May 24, 2023



Recent embedding-based methods have achieved great successes on exploiting entity alignment from knowledge graph (KG) embeddings of multiple modals. In this paper, we study embedding-based entity alignment (EEA) from a perspective of generative models. We show that EEA is a special problem where the main objective is analogous to that in a typical generative model, based on which we theoretically prove the effectiveness of the recently developed generative adversarial network (GAN)-based EEA methods. We then reveal that their incomplete objective limits the capacity on both entity alignment and entity synthesis (i.e., generating new entities). We mitigate this problem by introducing a generative EEA (abbr., GEEA) framework with the proposed mutual variational autoencoder (M-VAE) as the generative model. M-VAE can convert an entity from one KG to another and generate new entities from random noise vectors. We demonstrate the power of GEEA with theoretical analysis and empirical experiments on both entity alignment and entity synthesis tasks.
Newton-Cotes Graph Neural Networks: On the Time Evolution of Dynamic Systems
May 24, 2023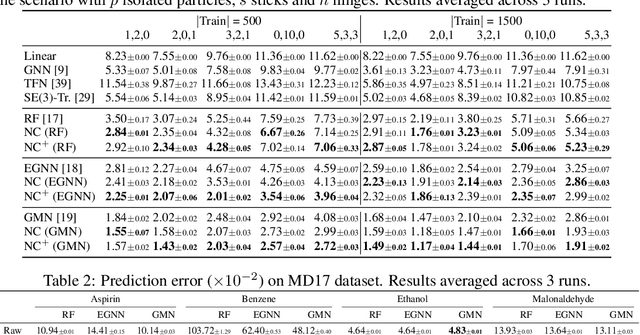
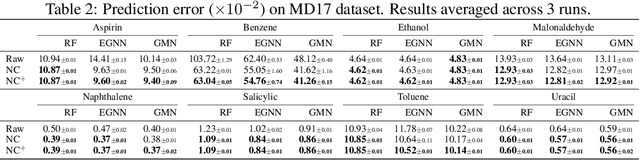
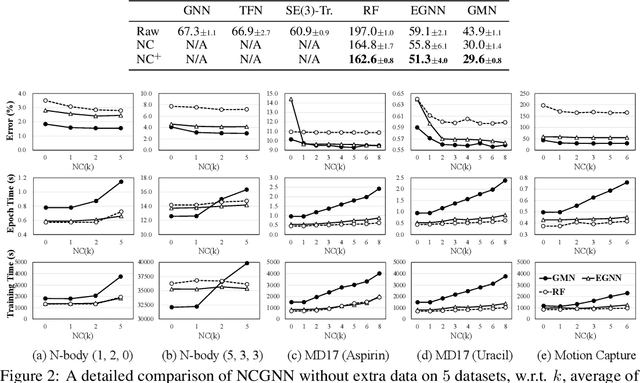
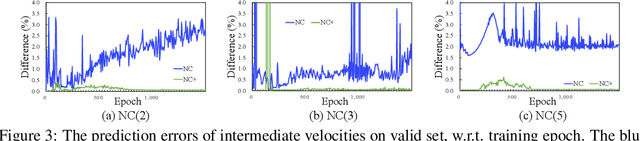
Reasoning system dynamics is one of the most important analytical approaches for many scientific studies. With the initial state of a system as input, the recent graph neural networks (GNNs)-based methods are capable of predicting the future state distant in time with high accuracy. Although these methods have diverse designs in modeling the coordinates and interacting forces of the system, we show that they actually share a common paradigm that learns the integration of the velocity over the interval between the initial and terminal coordinates. However, their integrand is constant w.r.t. time. Inspired by this observation, we propose a new approach to predict the integration based on several velocity estimations with Newton-Cotes formulas and prove its effectiveness theoretically. Extensive experiments on several benchmarks empirically demonstrate consistent and significant improvement compared with the state-of-the-art methods.
MEAformer: Multi-modal Entity Alignment Transformer for Meta Modality Hybrid
Dec 29, 2022



As an important variant of entity alignment (EA), multi-modal entity alignment (MMEA) aims to discover identical entities across different knowledge graphs (KGs) with multiple modalities like images. However, current MMEA algorithms all adopt KG-level modality fusion strategies but ignore modality differences among individual entities, hurting the robustness to potential noise involved in modalities (e.g., unidentifiable images and relations). In this paper we present MEAformer, a multi-modal entity alignment transformer approach for meta modality hybrid, to dynamically predict the mutual correlation coefficients among modalities for instance-level feature fusion. A modal-aware hard entity replay strategy is also proposed for addressing vague entity details. Extensive experimental results show that our model not only achieves SOTA performance on multiple training scenarios including supervised, unsupervised, iterative, and low resource, but also has limited parameters, optimistic speed, and good interpretability. Our code will be available soon.
Deep Reinforcement Learning for Entity Alignment
Mar 07, 2022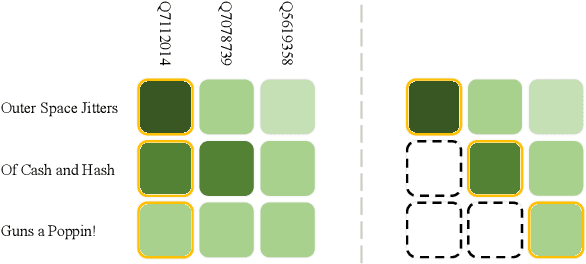



Embedding-based methods have attracted increasing attention in recent entity alignment (EA) studies. Although great promise they can offer, there are still several limitations. The most notable is that they identify the aligned entities based on cosine similarity, ignoring the semantics underlying the embeddings themselves. Furthermore, these methods are shortsighted, heuristically selecting the closest entity as the target and allowing multiple entities to match the same candidate. To address these limitations, we model entity alignment as a sequential decision-making task, in which an agent sequentially decides whether two entities are matched or mismatched based on their representation vectors. The proposed reinforcement learning (RL)-based entity alignment framework can be flexibly adapted to most embedding-based EA methods. The experimental results demonstrate that it consistently advances the performance of several state-of-the-art methods, with a maximum improvement of 31.1% on Hits@1.