 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiqiang Zhang
HeMeNet: Heterogeneous Multichannel Equivariant Network for Protein Multitask Learning
Apr 02, 2024
Understanding and leveraging the 3D structures of proteins is central to a variety of biological and drug discovery tasks. While deep learning has been applied successfully for structure-based protein function prediction tasks, current methods usually employ distinct training for each task. However, each of the tasks is of small size, and such a single-task strategy hinders the models' performance and generalization ability. As some labeled 3D protein datasets are biologically related, combining multi-source datasets for larger-scale multi-task learning is one way to overcome this problem. In this paper, we propose a neural network model to address multiple tasks jointly upon the input of 3D protein structures. In particular, we first construct a standard structure-based multi-task benchmark called Protein-MT, consisting of 6 biologically relevant tasks, including affinity prediction and property prediction, integrated from 4 public datasets. Then, we develop a novel graph neural network for multi-task learning, dubbed Heterogeneous Multichannel Equivariant Network (HeMeNet), which is E(3) equivariant and able to capture heterogeneous relationships between different atoms. Besides, HeMeNet can achieve task-specific learning via the task-aware readout mechanism. Extensive evaluations on our benchmark verify the effectiveness of multi-task learning, and our model generally surpasses state-of-the-art models.
Continual Few-shot Event Detection via Hierarchical Augmentation Networks
Mar 26, 2024Traditional continual event detection relies on abundant labeled data for training, which is often impractical to obtain in real-world applications. In this paper, we introduce continual few-shot event detection (CFED), a more commonly encountered scenario when a substantial number of labeled samples are not accessible. The CFED task is challenging as it involves memorizing previous event types and learning new event types with few-shot samples. To mitigate these challenges, we propose a memory-based framework: Hierarchical Augmentation Networks (HANet). To memorize previous event types with limited memory, we incorporate prototypical augmentation into the memory set. For the issue of learning new event types in few-shot scenarios, we propose a contrastive augmentation module for token representations. Despite comparing with previous state-of-the-art methods, we also conduct comparisons with ChatGPT. Experiment results demonstrate that our method significantly outperforms all of these methods in multiple continual few-shot event detection tasks.
Towards Automatic Evaluation for LLMs' Clinical Capabilities: Metric, Data, and Algorithm
Mar 25, 2024Large language models (LLMs) are gaining increasing interests to improve clinical efficiency for medical diagnosis, owing to their unprecedented performance in modelling natural language. Ensuring the safe and reliable clinical applications, the evaluation of LLMs indeed becomes critical for better mitigating the potential risks, e.g., hallucinations. However, current evaluation methods heavily rely on labor-intensive human participation to achieve human-preferred judgements. To overcome this challenge, we propose an automatic evaluation paradigm tailored to assess the LLMs' capabilities in delivering clinical services, e.g., disease diagnosis and treatment. The evaluation paradigm contains three basic elements: metric, data, and algorithm. Specifically, inspired by professional clinical practice pathways, we formulate a LLM-specific clinical pathway (LCP) to define the clinical capabilities that a doctor agent should possess. Then, Standardized Patients (SPs) from the medical education are introduced as the guideline for collecting medical data for evaluation, which can well ensure the completeness of the evaluation procedure. Leveraging these steps, we develop a multi-agent framework to simulate the interactive environment between SPs and a doctor agent, which is equipped with a Retrieval-Augmented Evaluation (RAE) to determine whether the behaviors of a doctor agent are in accordance with LCP. The above paradigm can be extended to any similar clinical scenarios to automatically evaluate the LLMs' medical capabilities. Applying such paradigm, we construct an evaluation benchmark in the field of urology, including a LCP, a SPs dataset, and an automated RAE. Extensive experiments are conducted to demonstrate the effectiveness of the proposed approach, providing more insights for LLMs' safe and reliable deployments in clinical practice.
Graph Neural Network with Two Uplift Estimators for Label-Scarcity Individual Uplift Modeling
Mar 11, 2024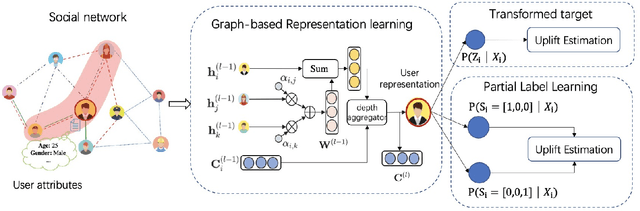

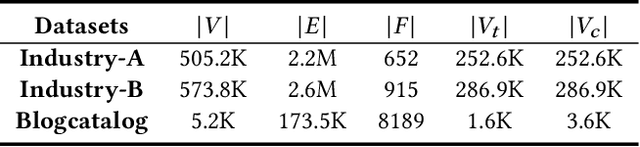

Uplift modeling aims to measure the incremental effect, which we call uplift, of a strategy or action on the users from randomized experiments or observational data. Most existing uplift methods only use individual data, which are usually not informative enough to capture the unobserved and complex hidden factors regarding the uplift. Furthermore, uplift modeling scenario usually has scarce labeled data, especially for the treatment group, which also poses a great challenge for model training. Considering that the neighbors' features and the social relationships are very informative to characterize a user's uplift, we propose a graph neural network-based framework with two uplift estimators, called GNUM, to learn from the social graph for uplift estimation. Specifically, we design the first estimator based on a class-transformed target. The estimator is general for all types of outcomes, and is able to comprehensively model the treatment and control group data together to approach the uplift. When the outcome is discrete, we further design the other uplift estimator based on our defined partial labels, which is able to utilize more labeled data from both the treatment and control groups, to further alleviate the label scarcity problem. Comprehensive experiments on a public dataset and two industrial datasets show a superior performance of our proposed framework over state-of-the-art methods under various evaluation metrics. The proposed algorithms have been deployed online to serve real-world uplift estimation scenarios.
Financial Default Prediction via Motif-preserving Graph Neural Network with Curriculum Learning
Mar 11, 2024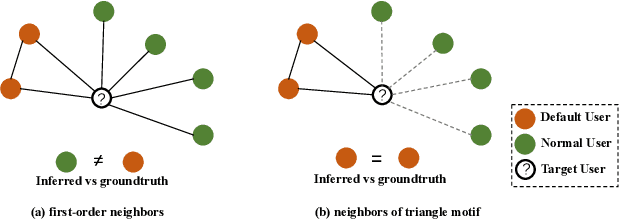
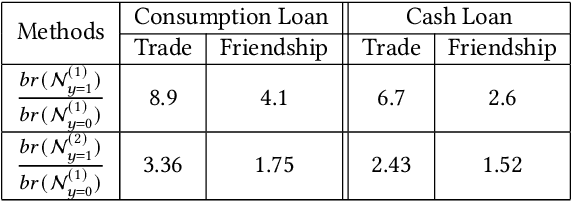
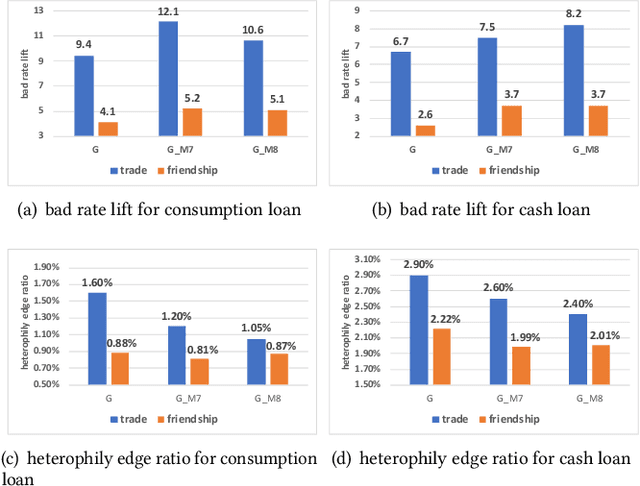
User financial default prediction plays a critical role in credit risk forecasting and management. It aims at predicting the probability that the user will fail to make the repayments in the future. Previous methods mainly extract a set of user individual features regarding his own profiles and behaviors and build a binary-classification model to make default predictions. However, these methods cannot get satisfied results, especially for users with limited information. Although recent efforts suggest that default prediction can be improved by social relations, they fail to capture the higher-order topology structure at the level of small subgraph patterns. In this paper, we fill in this gap by proposing a motif-preserving Graph Neural Network with curriculum learning (MotifGNN) to jointly learn the lower-order structures from the original graph and higherorder structures from multi-view motif-based graphs for financial default prediction. Specifically, to solve the problem of weak connectivity in motif-based graphs, we design the motif-based gating mechanism. It utilizes the information learned from the original graph with good connectivity to strengthen the learning of the higher-order structure. And considering that the motif patterns of different samples are highly unbalanced, we propose a curriculum learning mechanism on the whole learning process to more focus on the samples with uncommon motif distributions. Extensive experiments on one public dataset and two industrial datasets all demonstrate the effectiveness of our proposed method.
ChatUIE: Exploring Chat-based Unified Information Extraction using Large Language Models
Mar 08, 2024
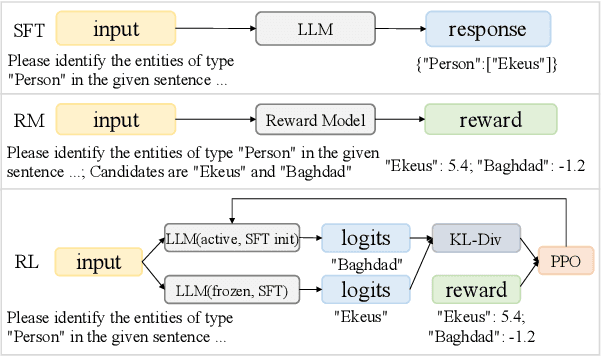
Recent advancements in large language models have shown impressive performance in general chat. However, their domain-specific capabilities, particularly in information extraction, have certain limitations. Extracting structured information from natural language that deviates from known schemas or instructions has proven challenging for previous prompt-based methods. This motivated us to explore domain-specific modeling in chat-based language models as a solution for extracting structured information from natural language. In this paper, we present ChatUIE, an innovative unified information extraction framework built upon ChatGLM. Simultaneously, reinforcement learning is employed to improve and align various tasks that involve confusing and limited samples. Furthermore, we integrate generation constraints to address the issue of generating elements that are not present in the input. Our experimental results demonstrate that ChatUIE can significantly improve the performance of information extraction with a slight decrease in chatting ability.
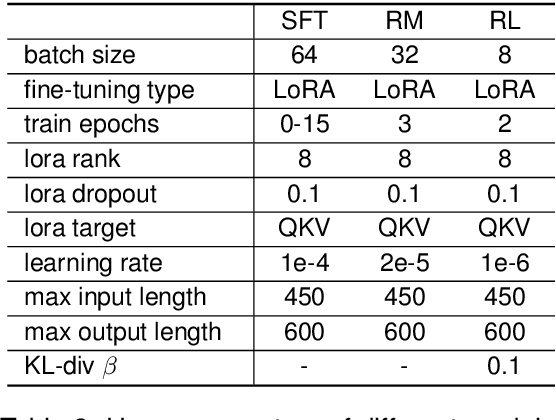
Can Small Language Models be Good Reasoners for Sequential Recommendation?
Mar 07, 2024
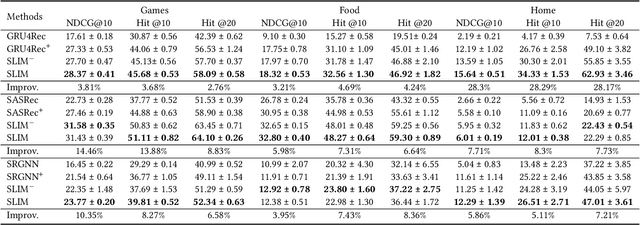


Large language models (LLMs) open up new horizons for sequential recommendations, owing to their remarkable language comprehension and generation capabilities. However, there are still numerous challenges that should be addressed to successfully implement sequential recommendations empowered by LLMs. Firstly, user behavior patterns are often complex, and relying solely on one-step reasoning from LLMs may lead to incorrect or task-irrelevant responses. Secondly, the prohibitively resource requirements of LLM (e.g., ChatGPT-175B) are overwhelmingly high and impractical for real sequential recommender systems. In this paper, we propose a novel Step-by-step knowLedge dIstillation fraMework for recommendation (SLIM), paving a promising path for sequential recommenders to enjoy the exceptional reasoning capabilities of LLMs in a "slim" (i.e., resource-efficient) manner. We introduce CoT prompting based on user behavior sequences for the larger teacher model. The rationales generated by the teacher model are then utilized as labels to distill the downstream smaller student model (e.g., LLaMA2-7B). In this way, the student model acquires the step-by-step reasoning capabilities in recommendation tasks. We encode the generated rationales from the student model into a dense vector, which empowers recommendation in both ID-based and ID-agnostic scenarios. Extensive experiments demonstrate the effectiveness of SLIM over state-of-the-art baselines, and further analysis showcasing its ability to generate meaningful recommendation reasoning at affordable costs.
Zero-Shot Cross-Lingual Document-Level Event Causality Identification with Heterogeneous Graph Contrastive Transfer Learning
Mar 05, 2024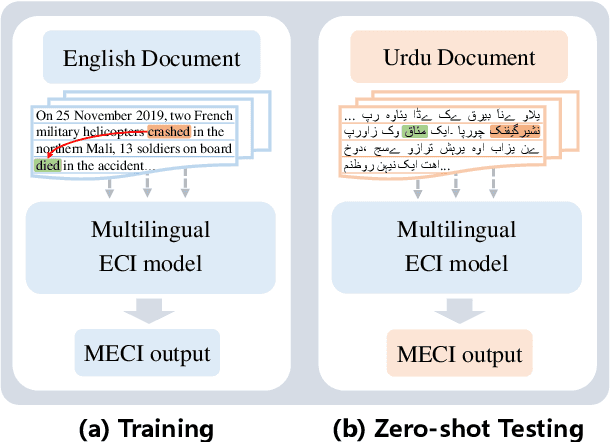
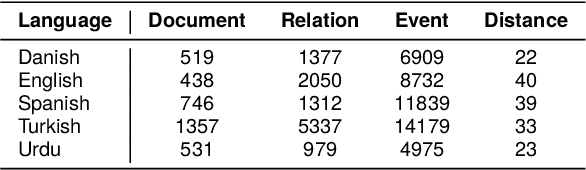

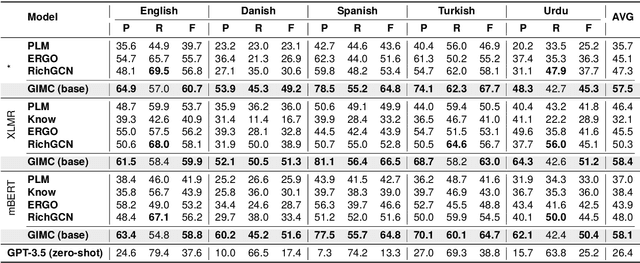
Event Causality Identification (ECI) refers to detect causal relations between events in texts. However, most existing studies focus on sentence-level ECI with high-resource language, leaving more challenging document-level ECI (DECI) with low-resource languages under-explored. In this paper, we propose a Heterogeneous Graph Interaction Model with Multi-granularity Contrastive Transfer Learning (GIMC) for zero-shot cross-lingual document-level ECI. Specifically, we introduce a heterogeneous graph interaction network to model the long-distance dependencies between events that are scattered over document. Then, to improve cross-lingual transferability of causal knowledge learned from source language, we propose a multi-granularity contrastive transfer learning module to align the causal representations across languages. Extensive experiments show our framework outperforms previous state-of-the-art model by 9.4% and 8.2% of average F1 score on monolingual and multilingual scenarios respectively. Notably, in multilingual scenario, our zero-shot framework even exceeds GPT-3.5 with few-shot learning by 24.3% in overall performance.
Non-autoregressive Generative Models for Reranking Recommendation
Feb 10, 2024In a multi-stage recommendation system, reranking plays a crucial role by modeling the intra-list correlations among items.The key challenge of reranking lies in the exploration of optimal sequences within the combinatorial space of permutations. Recent research proposes a generator-evaluator learning paradigm, where the generator generates multiple feasible sequences and the evaluator picks out the best sequence based on the estimated listwise score. Generator is of vital importance, and generative models are well-suited for the generator function. Current generative models employ an autoregressive strategy for sequence generation. However, deploying autoregressive models in real-time industrial systems is challenging. Hence, we propose a Non-AutoRegressive generative model for reranking Recommendation (NAR4Rec) designed to enhance efficiency and effectiveness. To address challenges related to sparse training samples and dynamic candidates impacting model convergence, we introduce a matching model. Considering the diverse nature of user feedback, we propose a sequence-level unlikelihood training objective to distinguish feasible from unfeasible sequences. Additionally, to overcome the lack of dependency modeling in non-autoregressive models regarding target items, we introduce contrastive decoding to capture correlations among these items. Extensive offline experiments on publicly available datasets validate the superior performance of our proposed approach compared to the existing state-of-the-art reranking methods. Furthermore, our method has been fully deployed in a popular video app Kuaishou with over 300 million daily active users, significantly enhancing online recommendation quality, and demonstrating the effectiveness and efficiency of our approach.
A Comprehensive Study of Knowledge Editing for Large Language Models
Jan 09, 2024Large Language Models (LLMs) have shown extraordinary capabilities in understanding and generating text that closely mirrors human communication. However, a primary limitation lies in the significant computational demands during training, arising from their extensive parameterization. This challenge is further intensified by the dynamic nature of the world, necessitating frequent updates to LLMs to correct outdated information or integrate new knowledge, thereby ensuring their continued relevance. Note that many applications demand continual model adjustments post-training to address deficiencies or undesirable behaviors. There is an increasing interest in efficient, lightweight methods for on-the-fly model modifications. To this end, recent years have seen a burgeoning in the techniques of knowledge editing for LLMs, which aim to efficiently modify LLMs' behaviors within specific domains while preserving overall performance across various inputs. In this paper, we first define the knowledge editing problem and then provide a comprehensive review of cutting-edge approaches. Drawing inspiration from educational and cognitive research theories, we propose a unified categorization criterion that classifies knowledge editing methods into three groups: resorting to external knowledge, merging knowledge into the model, and editing intrinsic knowledge. Furthermore, we introduce a new benchmark, KnowEdit, for a comprehensive empirical evaluation of representative knowledge editing approaches. Additionally, we provide an in-depth analysis of knowledge location, which can give a deeper understanding of the knowledge structures inherent within LLMs. Finally, we discuss several potential applications of knowledge editing, outlining its broad and impactful implications.