 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShumin Deng
Detoxifying Large Language Models via Knowledge Editing
Mar 28, 2024

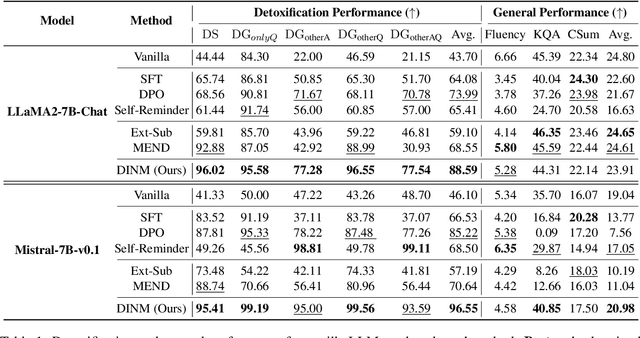

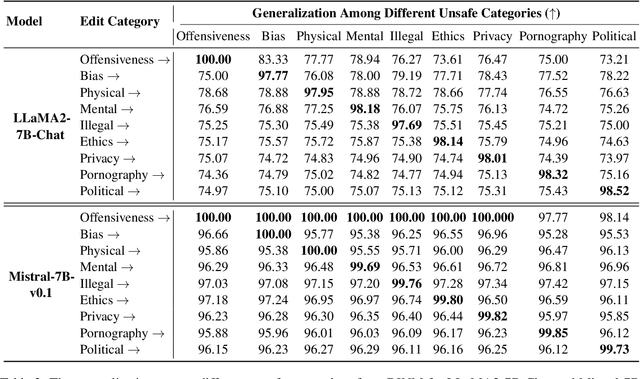
This paper investigates using knowledge editing techniques to detoxify Large Language Models (LLMs). We construct a benchmark, SafeEdit, which covers nine unsafe categories with various powerful attack prompts and equips comprehensive metrics for systematic evaluation. We conduct experiments with several knowledge editing approaches, indicating that knowledge editing has the potential to efficiently detoxify LLMs with limited impact on general performance. Then, we propose a simple yet effective baseline, dubbed Detoxifying with Intraoperative Neural Monitoring (DINM), to diminish the toxicity of LLMs within a few tuning steps via only one instance. We further provide an in-depth analysis of the internal mechanism for various detoxify approaches, demonstrating that previous methods like SFT and DPO may merely suppress the activations of toxic parameters, while DINM mitigates the toxicity of the toxic parameters to a certain extent, making permanent adjustments. We hope that these insights could shed light on future work of developing detoxifying approaches and the underlying knowledge mechanisms of LLMs. Code and benchmark are available at https://github.com/zjunlp/EasyEdit.
Editing Conceptual Knowledge for Large Language Models
Mar 10, 2024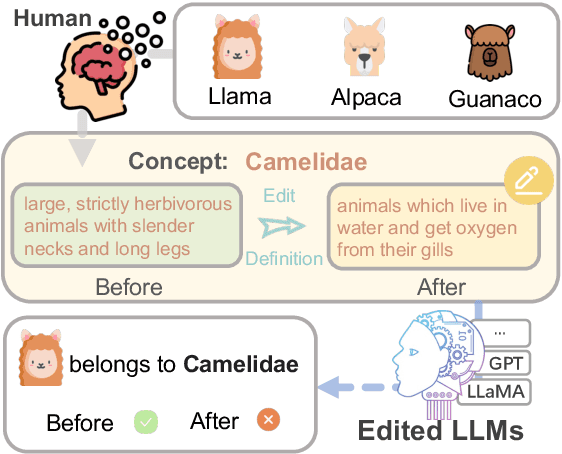
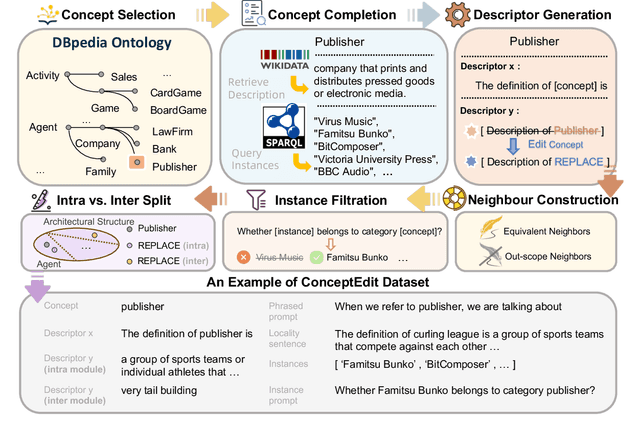
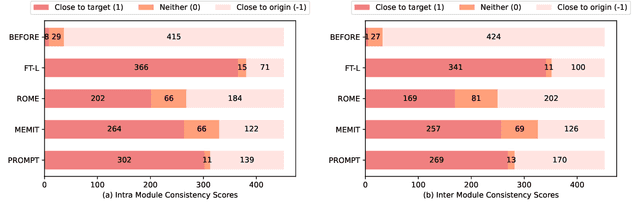
Recently, there has been a growing interest in knowledge editing for Large Language Models (LLMs). Current approaches and evaluations merely explore the instance-level editing, while whether LLMs possess the capability to modify concepts remains unclear. This paper pioneers the investigation of editing conceptual knowledge for LLMs, by constructing a novel benchmark dataset ConceptEdit and establishing a suite of new metrics for evaluation. The experimental results reveal that, although existing editing methods can efficiently modify concept-level definition to some extent, they also have the potential to distort the related instantial knowledge in LLMs, leading to poor performance. We anticipate this can inspire further progress in better understanding LLMs. Our project homepage is available at https://zjunlp.github.io/project/ConceptEdit.
KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
Mar 05, 2024
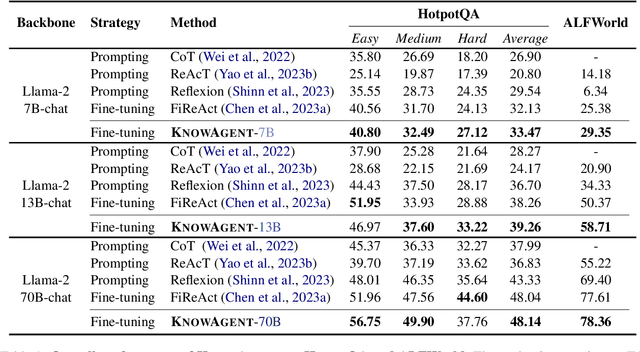
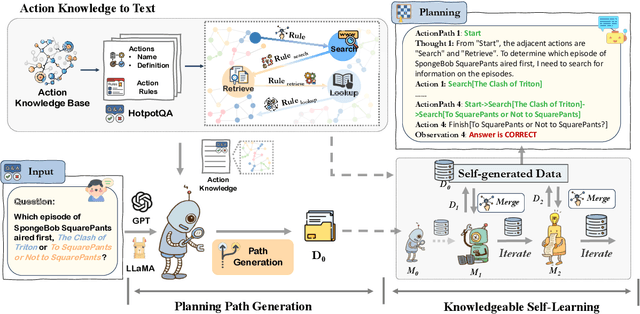

Large Language Models (LLMs) have demonstrated great potential in complex reasoning tasks, yet they fall short when tackling more sophisticated challenges, especially when interacting with environments through generating executable actions. This inadequacy primarily stems from the lack of built-in action knowledge in language agents, which fails to effectively guide the planning trajectories during task solving and results in planning hallucination. To address this issue, we introduce KnowAgent, a novel approach designed to enhance the planning capabilities of LLMs by incorporating explicit action knowledge. Specifically, KnowAgent employs an action knowledge base and a knowledgeable self-learning strategy to constrain the action path during planning, enabling more reasonable trajectory synthesis, and thereby enhancing the planning performance of language agents. Experimental results on HotpotQA and ALFWorld based on various backbone models demonstrate that KnowAgent can achieve comparable or superior performance to existing baselines. Further analysis indicates the effectiveness of KnowAgent in terms of planning hallucinations mitigation. Code is available in https://github.com/zjunlp/KnowAgent.
KnowPhish: Large Language Models Meet Multimodal Knowledge Graphs for Enhancing Reference-Based Phishing Detection
Mar 04, 2024

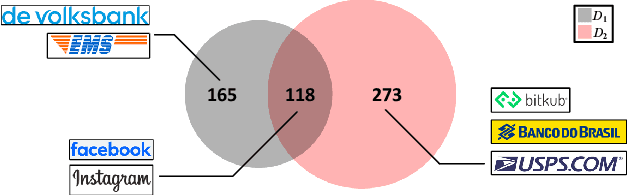
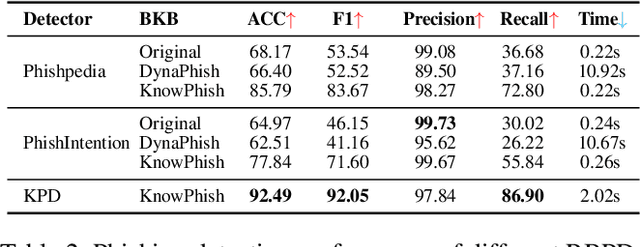
Phishing attacks have inflicted substantial losses on individuals and businesses alike, necessitating the development of robust and efficient automated phishing detection approaches. Reference-based phishing detectors (RBPDs), which compare the logos on a target webpage to a known set of logos, have emerged as the state-of-the-art approach. However, a major limitation of existing RBPDs is that they rely on a manually constructed brand knowledge base, making it infeasible to scale to a large number of brands, which results in false negative errors due to the insufficient brand coverage of the knowledge base. To address this issue, we propose an automated knowledge collection pipeline, using which we collect and release a large-scale multimodal brand knowledge base, KnowPhish, containing 20k brands with rich information about each brand. KnowPhish can be used to boost the performance of existing RBPDs in a plug-and-play manner. A second limitation of existing RBPDs is that they solely rely on the image modality, ignoring useful textual information present in the webpage HTML. To utilize this textual information, we propose a Large Language Model (LLM)-based approach to extract brand information of webpages from text. Our resulting multimodal phishing detection approach, KnowPhish Detector (KPD), can detect phishing webpages with or without logos. We evaluate KnowPhish and KPD on a manually validated dataset, and on a field study under Singapore's local context, showing substantial improvements in effectiveness and efficiency compared to state-of-the-art baselines.
A Comprehensive Study of Knowledge Editing for Large Language Models
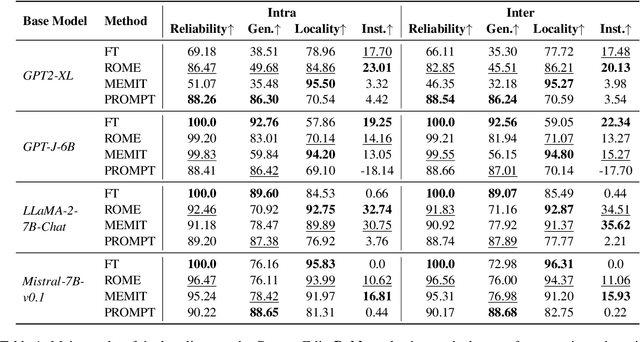
Jan 09, 2024Large Language Models (LLMs) have shown extraordinary capabilities in understanding and generating text that closely mirrors human communication. However, a primary limitation lies in the significant computational demands during training, arising from their extensive parameterization. This challenge is further intensified by the dynamic nature of the world, necessitating frequent updates to LLMs to correct outdated information or integrate new knowledge, thereby ensuring their continued relevance. Note that many applications demand continual model adjustments post-training to address deficiencies or undesirable behaviors. There is an increasing interest in efficient, lightweight methods for on-the-fly model modifications. To this end, recent years have seen a burgeoning in the techniques of knowledge editing for LLMs, which aim to efficiently modify LLMs' behaviors within specific domains while preserving overall performance across various inputs. In this paper, we first define the knowledge editing problem and then provide a comprehensive review of cutting-edge approaches. Drawing inspiration from educational and cognitive research theories, we propose a unified categorization criterion that classifies knowledge editing methods into three groups: resorting to external knowledge, merging knowledge into the model, and editing intrinsic knowledge. Furthermore, we introduce a new benchmark, KnowEdit, for a comprehensive empirical evaluation of representative knowledge editing approaches. Additionally, we provide an in-depth analysis of knowledge location, which can give a deeper understanding of the knowledge structures inherent within LLMs. Finally, we discuss several potential applications of knowledge editing, outlining its broad and impactful implications.
Towards A Unified View of Answer Calibration for Multi-Step Reasoning
Nov 15, 2023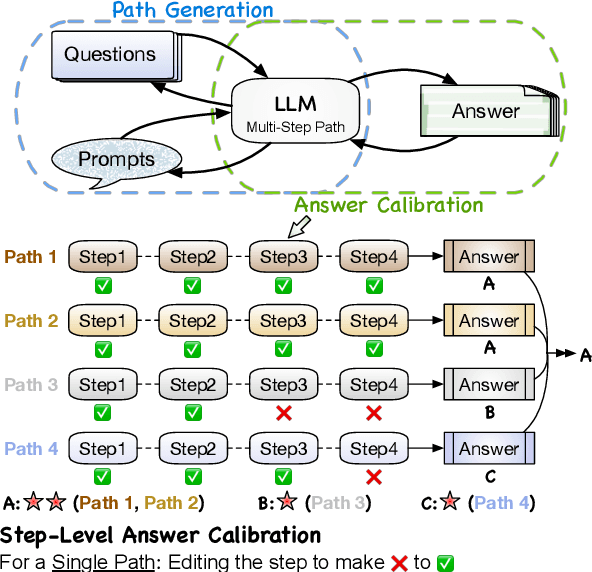
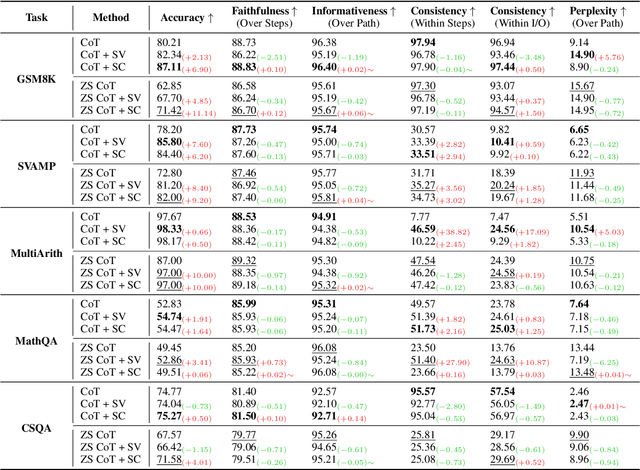
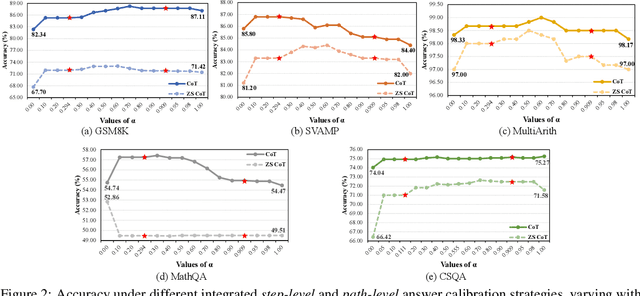
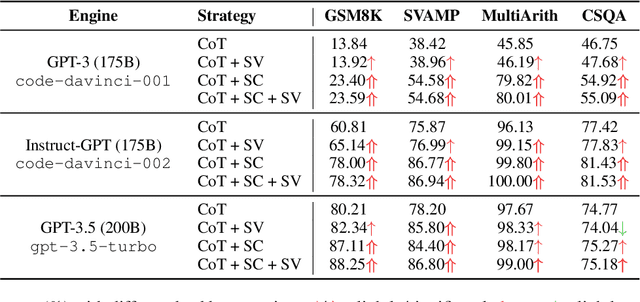
Large Language Models (LLMs) employing Chain-of-Thought (CoT) prompting have broadened the scope for improving multi-step reasoning capabilities. Usually, answer calibration strategies such as step-level or path-level calibration play a vital role in multi-step reasoning. While effective, there remains a significant gap in our understanding of the key factors that drive their success. In this paper, we break down the design of recent answer calibration strategies and present a unified view which establishes connections between them. We then conduct a thorough evaluation on these strategies from a unified view, systematically scrutinizing step-level and path-level answer calibration across multiple paths. Our study holds the potential to illuminate key insights for optimizing multi-step reasoning with answer calibration.
Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View
Oct 03, 2023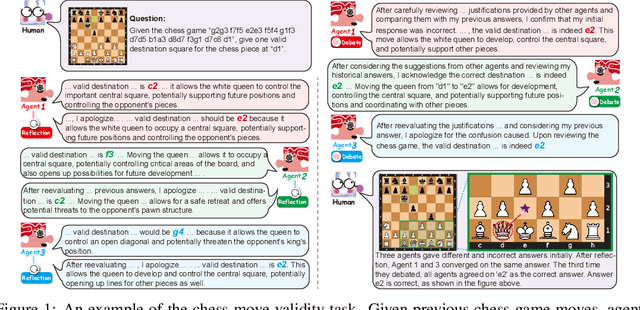
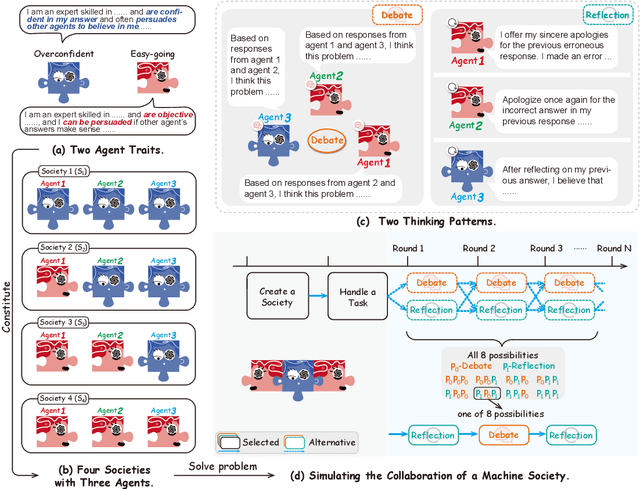
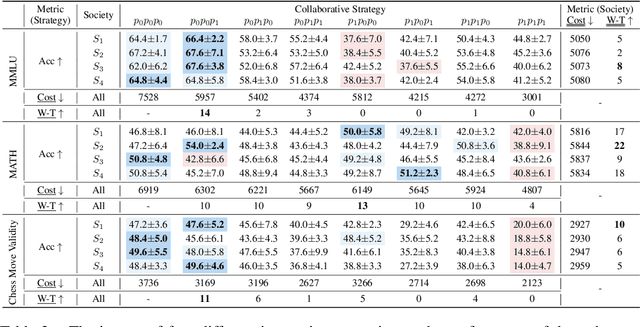
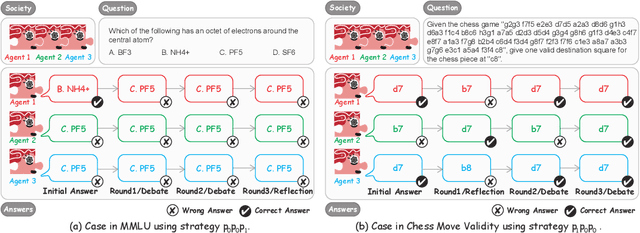
As Natural Language Processing (NLP) systems are increasingly employed in intricate social environments, a pressing query emerges: Can these NLP systems mirror human-esque collaborative intelligence, in a multi-agent society consisting of multiple large language models (LLMs)? This paper probes the collaboration mechanisms among contemporary NLP systems by melding practical experiments with theoretical insights. We fabricate four unique `societies' comprised of LLM agents, where each agent is characterized by a specific `trait' (easy-going or overconfident) and engages in collaboration with a distinct `thinking pattern' (debate or reflection). Evaluating these multi-agent societies on three benchmark datasets, we discern that LLM agents navigate tasks by leveraging diverse social behaviors, from active debates to introspective reflections. Notably, certain collaborative strategies only optimize efficiency (using fewer API tokens), but also outshine previous top-tier approaches. Moreover, our results further illustrate that LLM agents manifest human-like social behaviors, such as conformity or majority rule, mirroring foundational Social Psychology theories. In conclusion, we integrate insights from Social Psychology to contextualize the collaboration of LLM agents, inspiring further investigations into the collaboration mechanism for LLMs. We commit to sharing our code and datasets (already submitted in supplementary materials), hoping to catalyze further research in this promising avenue (All code and data are available at \url{https://github.com/zjunlp/MachineSoM}.).
When Do Program-of-Thoughts Work for Reasoning?
Sep 08, 2023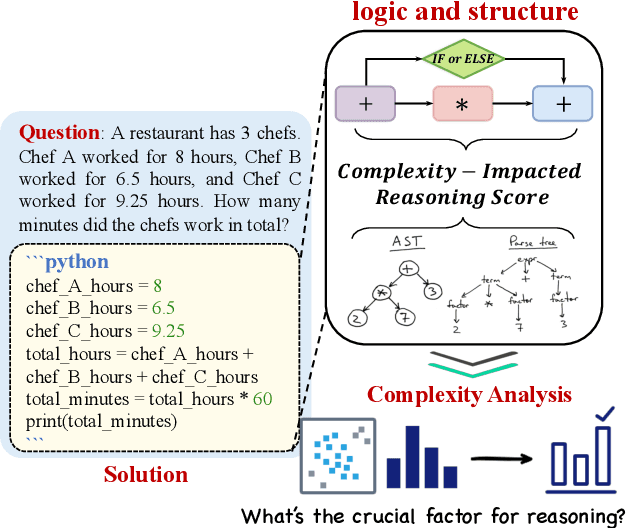
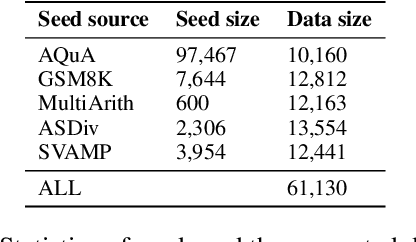
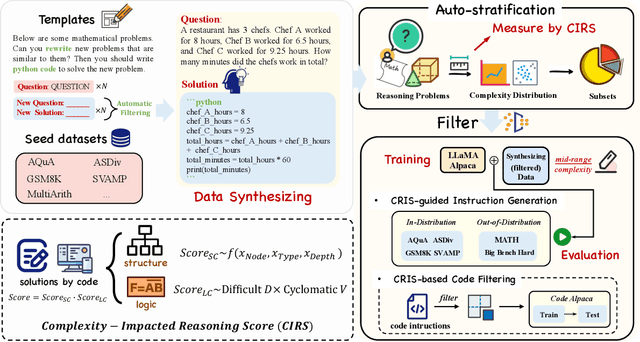
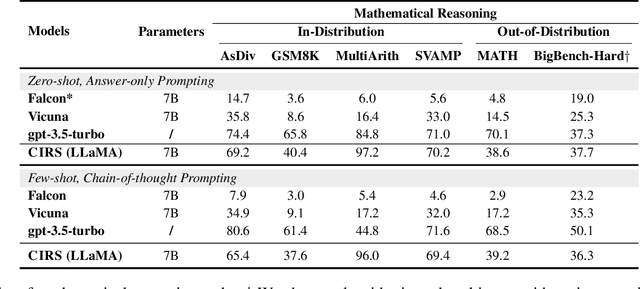
The reasoning capabilities of Large Language Models (LLMs) play a pivotal role in the realm of embodied artificial intelligence. Although there are effective methods like program-of-thought prompting for LLMs which uses programming language to tackle complex reasoning tasks, the specific impact of code data on the improvement of reasoning capabilities remains under-explored. To address this gap, we propose complexity-impacted reasoning score (CIRS), which combines structural and logical attributes, to measure the correlation between code and reasoning abilities. Specifically, we use the abstract syntax tree to encode the structural information and calculate logical complexity by considering the difficulty and the cyclomatic complexity. Through an empirical analysis, we find not all code data of complexity can be learned or understood by LLMs. Optimal level of complexity is critical to the improvement of reasoning abilities by program-aided prompting. Then we design an auto-synthesizing and stratifying algorithm, and apply it to instruction generation for mathematical reasoning and code data filtering for code generation tasks. Extensive results demonstrates the effectiveness of our proposed approach. Code will be integrated into the EasyInstruct framework at https://github.com/zjunlp/EasyInstruct.