 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianyang Xu
Revisiting RGBT Tracking Benchmarks from the Perspective of Modality Validity: A New Benchmark, Problem, and Method
Apr 30, 2024
RGBT tracking draws increasing attention due to its robustness in multi-modality warranting (MMW) scenarios, such as nighttime and bad weather, where relying on a single sensing modality fails to ensure stable tracking results. However, the existing benchmarks predominantly consist of videos collected in common scenarios where both RGB and thermal infrared (TIR) information are of sufficient quality. This makes the data unrepresentative of severe imaging conditions, leading to tracking failures in MMW scenarios. To bridge this gap, we present a new benchmark, MV-RGBT, captured specifically in MMW scenarios. In contrast with the existing datasets, MV-RGBT comprises more object categories and scenes, providing a diverse and challenging benchmark. Furthermore, for severe imaging conditions of MMW scenarios, a new problem is posed, namely \textit{when to fuse}, to stimulate the development of fusion strategies for such data. We propose a new method based on a mixture of experts, namely MoETrack, as a baseline fusion strategy. In MoETrack, each expert generates independent tracking results along with the corresponding confidence score, which is used to control the fusion process. Extensive experimental results demonstrate the significant potential of MV-RGBT in advancing RGBT tracking and elicit the conclusion that fusion is not always beneficial, especially in MMW scenarios. Significantly, the proposed MoETrack method achieves new state-of-the-art results not only on MV-RGBT, but also on standard benchmarks, such as RGBT234, LasHeR, and the short-term split of VTUAV (VTUAV-ST). More information of MV-RGBT and the source code of MoETrack will be released at https://github.com/Zhangyong-Tang/MoETrack.
An Improved Graph Pooling Network for Skeleton-Based Action Recognition
Apr 25, 2024Pooling is a crucial operation in computer vision, yet the unique structure of skeletons hinders the application of existing pooling strategies to skeleton graph modelling. In this paper, we propose an Improved Graph Pooling Network, referred to as IGPN. The main innovations include: Our method incorporates a region-awareness pooling strategy based on structural partitioning. The correlation matrix of the original feature is used to adaptively adjust the weight of information in different regions of the newly generated features, resulting in more flexible and effective processing. To prevent the irreversible loss of discriminative information, we propose a cross fusion module and an information supplement module to provide block-level and input-level information respectively. As a plug-and-play structure, the proposed operation can be seamlessly combined with existing GCN-based models. We conducted extensive evaluations on several challenging benchmarks, and the experimental results indicate the effectiveness of our proposed solutions. For example, in the cross-subject evaluation of the NTU-RGB+D 60 dataset, IGPN achieves a significant improvement in accuracy compared to the baseline while reducing Flops by nearly 70%; a heavier version has also been introduced to further boost accuracy.
Evaluating the Factuality of Large Language Models using Large-Scale Knowledge Graphs
Apr 01, 2024The advent of Large Language Models (LLMs) has significantly transformed the AI landscape, enhancing machine learning and AI capabilities. Factuality issue is a critical concern for LLMs, as they may generate factually incorrect responses. In this paper, we propose GraphEval to evaluate an LLM's performance using a substantially large test dataset. Specifically, the test dataset is retrieved from a large knowledge graph with more than 10 million facts without expensive human efforts. Unlike conventional methods that evaluate LLMs based on generated responses, GraphEval streamlines the evaluation process by creating a judge model to estimate the correctness of the answers given by the LLM. Our experiments demonstrate that the judge model's factuality assessment aligns closely with the correctness of the LLM's generated outputs, while also substantially reducing evaluation costs. Besides, our findings offer valuable insights into LLM performance across different metrics and highlight the potential for future improvements in ensuring the factual integrity of LLM outputs. The code is publicly available at https://github.com/xz-liu/GraphEval.
BusReF: Infrared-Visible images registration and fusion focus on reconstructible area using one set of features
Dec 30, 2023In a scenario where multi-modal cameras are operating together, the problem of working with non-aligned images cannot be avoided. Yet, existing image fusion algorithms rely heavily on strictly registered input image pairs to produce more precise fusion results, as a way to improve the performance of downstream high-level vision tasks. In order to relax this assumption, one can attempt to register images first. However, the existing methods for registering multiple modalities have limitations, such as complex structures and reliance on significant semantic information. This paper aims to address the problem of image registration and fusion in a single framework, called BusRef. We focus on Infrared-Visible image registration and fusion task (IVRF). In this framework, the input unaligned image pairs will pass through three stages: Coarse registration, Fine registration and Fusion. It will be shown that the unified approach enables more robust IVRF. We also propose a novel training and evaluation strategy, involving the use of masks to reduce the influence of non-reconstructible regions on the loss functions, which greatly improves the accuracy and robustness of the fusion task. Last but not least, a gradient-aware fusion network is designed to preserve the complementary information. The advanced performance of this algorithm is demonstrated by
TextFusion: Unveiling the Power of Textual Semantics for Controllable Image Fusion
Dec 21, 2023Advanced image fusion methods are devoted to generating the fusion results by aggregating the complementary information conveyed by the source images. However, the difference in the source-specific manifestation of the imaged scene content makes it difficult to design a robust and controllable fusion process. We argue that this issue can be alleviated with the help of higher-level semantics, conveyed by the text modality, which should enable us to generate fused images for different purposes, such as visualisation and downstream tasks, in a controllable way. This is achieved by exploiting a vision-and-language model to build a coarse-to-fine association mechanism between the text and image signals. With the guidance of the association maps, an affine fusion unit is embedded in the transformer network to fuse the text and vision modalities at the feature level. As another ingredient of this work, we propose the use of textual attention to adapt image quality assessment to the fusion task. To facilitate the implementation of the proposed text-guided fusion paradigm, and its adoption by the wider research community, we release a text-annotated image fusion dataset IVT. Extensive experiments demonstrate that our approach (TextFusion) consistently outperforms traditional appearance-based fusion methods. Our code and dataset will be publicly available on the project homepage.
SCD-Net: Spatiotemporal Clues Disentanglement Network for Self-supervised Skeleton-based Action Recognition
Sep 11, 2023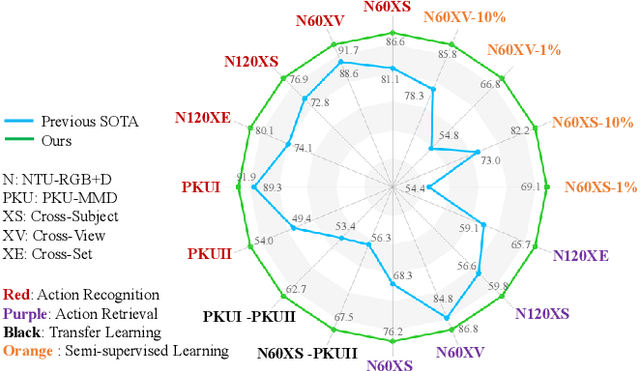
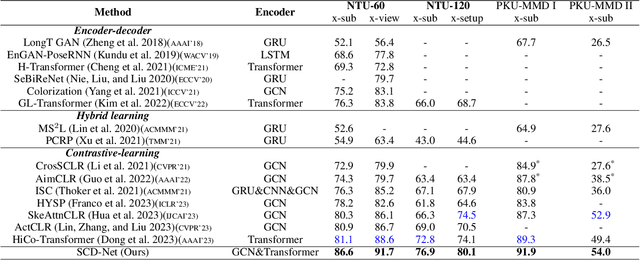
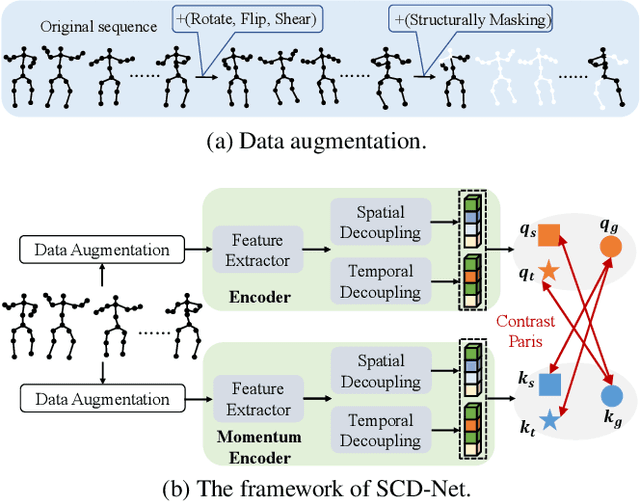
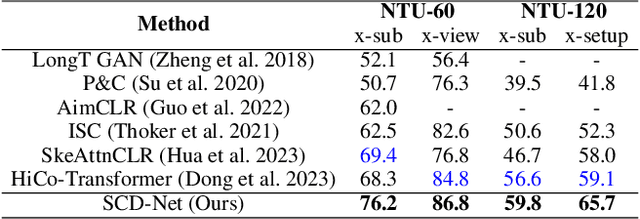
Contrastive learning has achieved great success in skeleton-based action recognition. However, most existing approaches encode the skeleton sequences as entangled spatiotemporal representations and confine the contrasts to the same level of representation. Instead, this paper introduces a novel contrastive learning framework, namely Spatiotemporal Clues Disentanglement Network (SCD-Net). Specifically, we integrate the decoupling module with a feature extractor to derive explicit clues from spatial and temporal domains respectively. As for the training of SCD-Net, with a constructed global anchor, we encourage the interaction between the anchor and extracted clues. Further, we propose a new masking strategy with structural constraints to strengthen the contextual associations, leveraging the latest development from masked image modelling into the proposed SCD-Net. We conduct extensive evaluations on the NTU-RGB+D (60&120) and PKU-MMD (I&II) datasets, covering various downstream tasks such as action recognition, action retrieval, transfer learning, and semi-supervised learning. The experimental results demonstrate the effectiveness of our method, which outperforms the existing state-of-the-art (SOTA) approaches significantly.
Generative-based Fusion Mechanism for Multi-Modal Tracking
Sep 07, 2023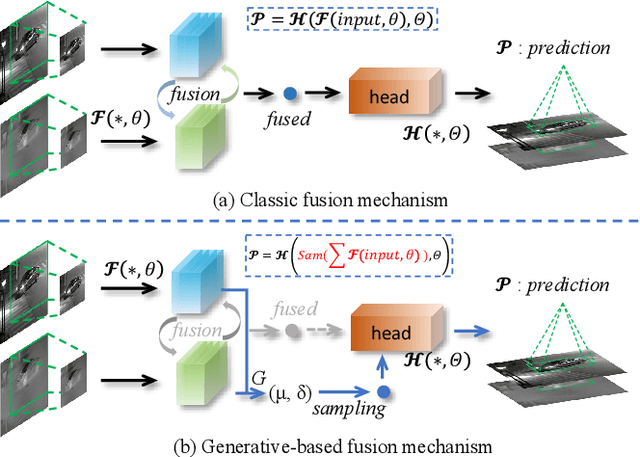

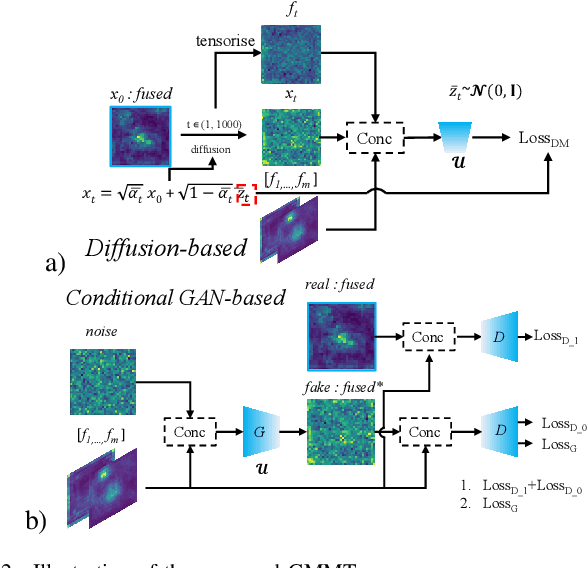

Generative models (GMs) have received increasing research interest for their remarkable capacity to achieve comprehensive understanding. However, their potential application in the domain of multi-modal tracking has remained relatively unexplored. In this context, we seek to uncover the potential of harnessing generative techniques to address the critical challenge, information fusion, in multi-modal tracking. In this paper, we delve into two prominent GM techniques, namely, Conditional Generative Adversarial Networks (CGANs) and Diffusion Models (DMs). Different from the standard fusion process where the features from each modality are directly fed into the fusion block, we condition these multi-modal features with random noise in the GM framework, effectively transforming the original training samples into harder instances. This design excels at extracting discriminative clues from the features, enhancing the ultimate tracking performance. To quantitatively gauge the effectiveness of our approach, we conduct extensive experiments across two multi-modal tracking tasks, three baseline methods, and three challenging benchmarks. The experimental results demonstrate that the proposed generative-based fusion mechanism achieves state-of-the-art performance, setting new records on LasHeR and RGBD1K.
Evidential Detection and Tracking Collaboration: New Problem, Benchmark and Algorithm for Robust Anti-UAV System
Jul 04, 2023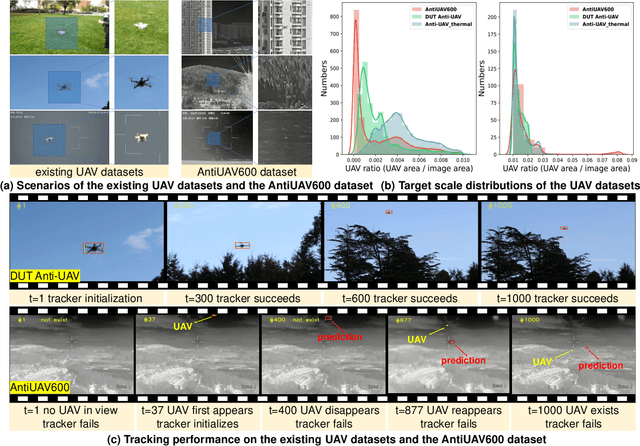
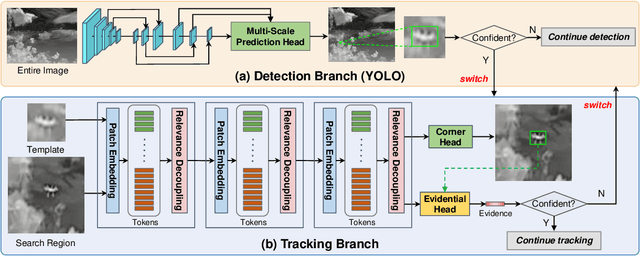
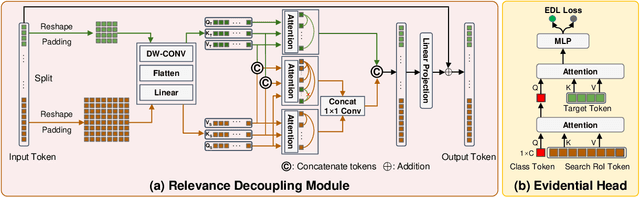
Unmanned Aerial Vehicles (UAVs) have been widely used in many areas, including transportation, surveillance, and military. However, their potential for safety and privacy violations is an increasing issue and highly limits their broader applications, underscoring the critical importance of UAV perception and defense (anti-UAV). Still, previous works have simplified such an anti-UAV task as a tracking problem, where the prior information of UAVs is always provided; such a scheme fails in real-world anti-UAV tasks (i.e. complex scenes, indeterminate-appear and -reappear UAVs, and real-time UAV surveillance). In this paper, we first formulate a new and practical anti-UAV problem featuring the UAVs perception in complex scenes without prior UAVs information. To benchmark such a challenging task, we propose the largest UAV dataset dubbed AntiUAV600 and a new evaluation metric. The AntiUAV600 comprises 600 video sequences of challenging scenes with random, fast, and small-scale UAVs, with over 723K thermal infrared frames densely annotated with bounding boxes. Finally, we develop a novel anti-UAV approach via an evidential collaboration of global UAVs detection and local UAVs tracking, which effectively tackles the proposed problem and can serve as a strong baseline for future research. Extensive experiments show our method outperforms SOTA approaches and validate the ability of AntiUAV600 to enhance UAV perception performance due to its large scale and complexity. Our dataset, pretrained models, and source codes will be released publically.
Mixture-of-Domain-Adapters: Decoupling and Injecting Domain Knowledge to Pre-trained Language Models Memories
Jun 08, 2023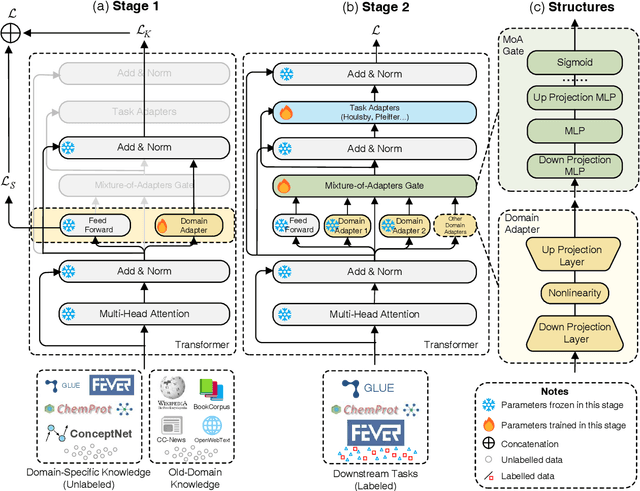

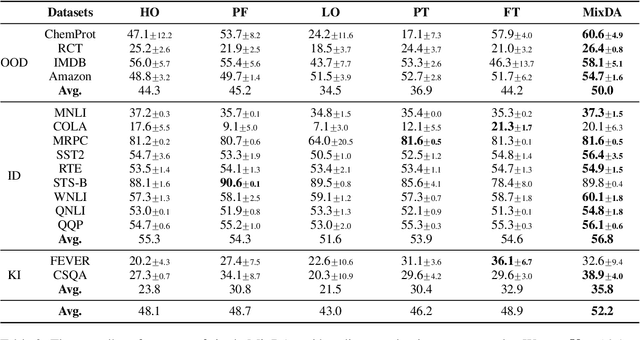

Pre-trained language models (PLMs) demonstrate excellent abilities to understand texts in the generic domain while struggling in a specific domain. Although continued pre-training on a large domain-specific corpus is effective, it is costly to tune all the parameters on the domain. In this paper, we investigate whether we can adapt PLMs both effectively and efficiently by only tuning a few parameters. Specifically, we decouple the feed-forward networks (FFNs) of the Transformer architecture into two parts: the original pre-trained FFNs to maintain the old-domain knowledge and our novel domain-specific adapters to inject domain-specific knowledge in parallel. Then we adopt a mixture-of-adapters gate to fuse the knowledge from different domain adapters dynamically. Our proposed Mixture-of-Domain-Adapters (MixDA) employs a two-stage adapter-tuning strategy that leverages both unlabeled data and labeled data to help the domain adaptation: i) domain-specific adapter on unlabeled data; followed by ii) the task-specific adapter on labeled data. MixDA can be seamlessly plugged into the pretraining-finetuning paradigm and our experiments demonstrate that MixDA achieves superior performance on in-domain tasks (GLUE), out-of-domain tasks (ChemProt, RCT, IMDB, Amazon), and knowledge-intensive tasks (KILT). Further analyses demonstrate the reliability, scalability, and efficiency of our method. The code is available at https://github.com/Amano-Aki/Mixture-of-Domain-Adapters.
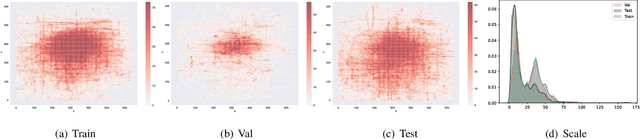
The 3rd Anti-UAV Workshop & Challenge: Methods and Results
May 12, 2023

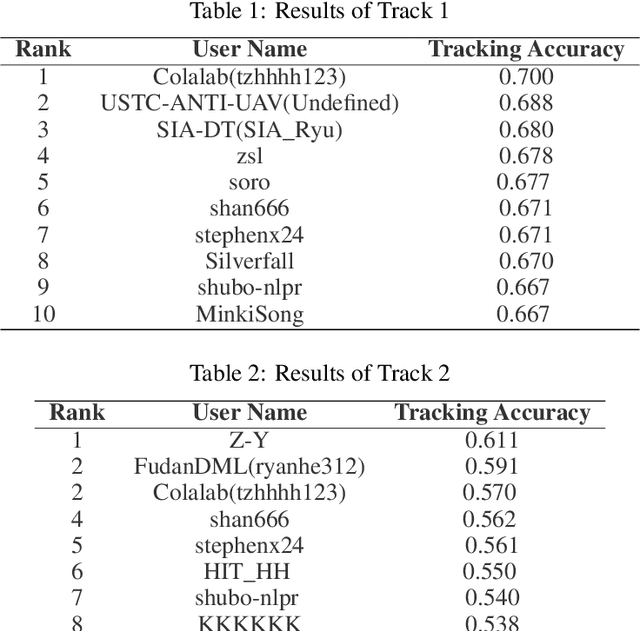
The 3rd Anti-UAV Workshop & Challenge aims to encourage research in developing novel and accurate methods for multi-scale object tracking. The Anti-UAV dataset used for the Anti-UAV Challenge has been publicly released. There are two main differences between this year's competition and the previous two. First, we have expanded the existing dataset, and for the first time, released a training set so that participants can focus on improving their models. Second, we set up two tracks for the first time, i.e., Anti-UAV Tracking and Anti-UAV Detection & Tracking. Around 76 participating teams from the globe competed in the 3rd Anti-UAV Challenge. In this paper, we provide a brief summary of the 3rd Anti-UAV Workshop & Challenge including brief introductions to the top three methods in each track. The submission leaderboard will be reopened for researchers that are interested in the Anti-UAV challenge. The benchmark dataset and other information can be found at: https://anti-uav.github.io/.