 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCong Wu
An Improved Graph Pooling Network for Skeleton-Based Action Recognition
Apr 25, 2024
Pooling is a crucial operation in computer vision, yet the unique structure of skeletons hinders the application of existing pooling strategies to skeleton graph modelling. In this paper, we propose an Improved Graph Pooling Network, referred to as IGPN. The main innovations include: Our method incorporates a region-awareness pooling strategy based on structural partitioning. The correlation matrix of the original feature is used to adaptively adjust the weight of information in different regions of the newly generated features, resulting in more flexible and effective processing. To prevent the irreversible loss of discriminative information, we propose a cross fusion module and an information supplement module to provide block-level and input-level information respectively. As a plug-and-play structure, the proposed operation can be seamlessly combined with existing GCN-based models. We conducted extensive evaluations on several challenging benchmarks, and the experimental results indicate the effectiveness of our proposed solutions. For example, in the cross-subject evaluation of the NTU-RGB+D 60 dataset, IGPN achieves a significant improvement in accuracy compared to the baseline while reducing Flops by nearly 70%; a heavier version has also been introduced to further boost accuracy.
CLAD: Robust Audio Deepfake Detection Against Manipulation Attacks with Contrastive Learning
Apr 24, 2024The increasing prevalence of audio deepfakes poses significant security threats, necessitating robust detection methods. While existing detection systems exhibit promise, their robustness against malicious audio manipulations remains underexplored. To bridge the gap, we undertake the first comprehensive study of the susceptibility of the most widely adopted audio deepfake detectors to manipulation attacks. Surprisingly, even manipulations like volume control can significantly bypass detection without affecting human perception. To address this, we propose CLAD (Contrastive Learning-based Audio deepfake Detector) to enhance the robustness against manipulation attacks. The key idea is to incorporate contrastive learning to minimize the variations introduced by manipulations, therefore enhancing detection robustness. Additionally, we incorporate a length loss, aiming to improve the detection accuracy by clustering real audios more closely in the feature space. We comprehensively evaluated the most widely adopted audio deepfake detection models and our proposed CLAD against various manipulation attacks. The detection models exhibited vulnerabilities, with FAR rising to 36.69%, 31.23%, and 51.28% under volume control, fading, and noise injection, respectively. CLAD enhanced robustness, reducing the FAR to 0.81% under noise injection and consistently maintaining an FAR below 1.63% across all tests. Our source code and documentation are available in the artifact repository (https://github.com/CLAD23/CLAD).
On the Effectiveness of Distillation in Mitigating Backdoors in Pre-trained Encoder
Mar 06, 2024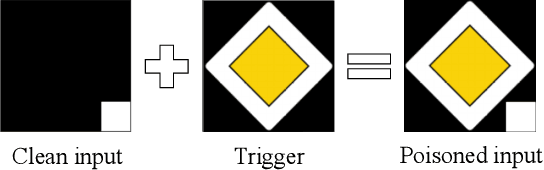
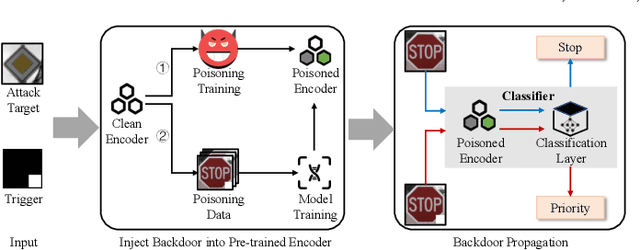
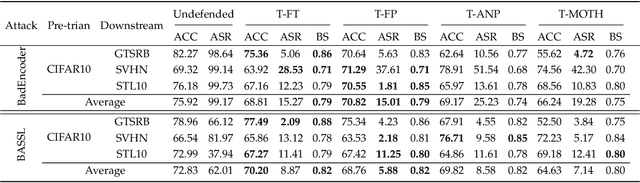
In this paper, we study a defense against poisoned encoders in SSL called distillation, which is a defense used in supervised learning originally. Distillation aims to distill knowledge from a given model (a.k.a the teacher net) and transfer it to another (a.k.a the student net). Now, we use it to distill benign knowledge from poisoned pre-trained encoders and transfer it to a new encoder, resulting in a clean pre-trained encoder. In particular, we conduct an empirical study on the effectiveness and performance of distillation against poisoned encoders. Using two state-of-the-art backdoor attacks against pre-trained image encoders and four commonly used image classification datasets, our experimental results show that distillation can reduce attack success rate from 80.87% to 27.51% while suffering a 6.35% loss in accuracy. Moreover, we investigate the impact of three core components of distillation on performance: teacher net, student net, and distillation loss. By comparing 4 different teacher nets, 3 student nets, and 6 distillation losses, we find that fine-tuned teacher nets, warm-up-training-based student nets, and attention-based distillation loss perform best, respectively.
SCD-Net: Spatiotemporal Clues Disentanglement Network for Self-supervised Skeleton-based Action Recognition
Sep 11, 2023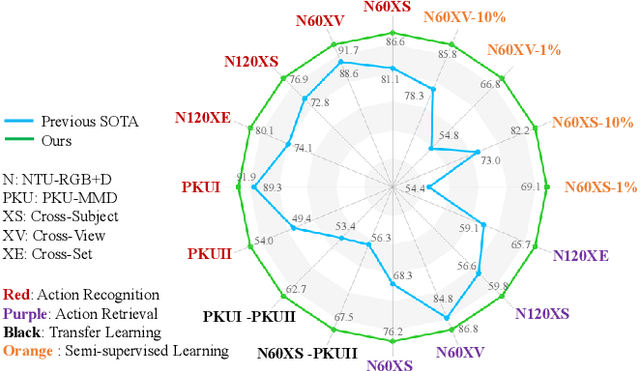
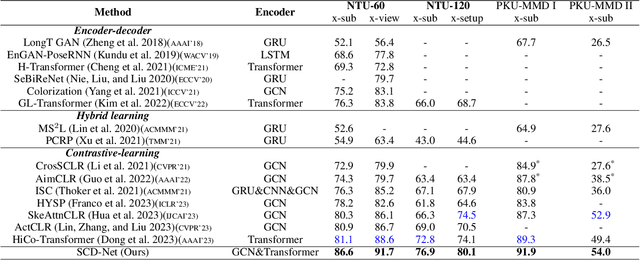
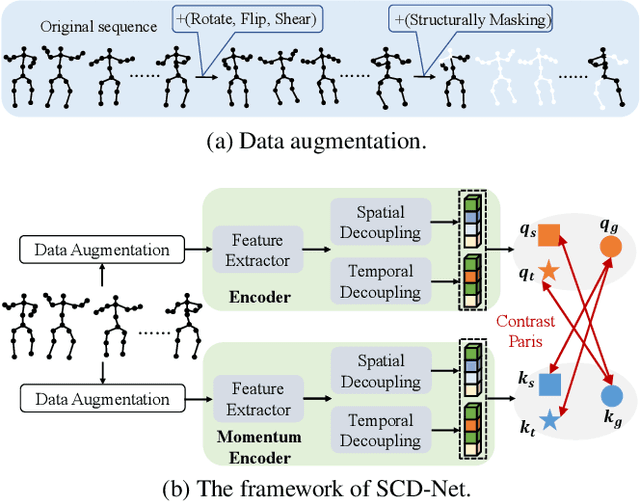
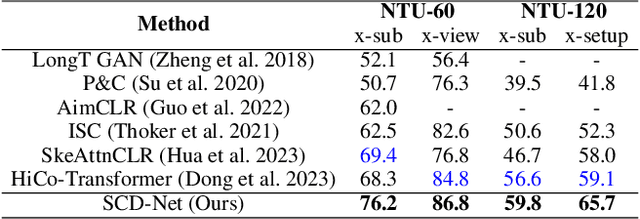
Contrastive learning has achieved great success in skeleton-based action recognition. However, most existing approaches encode the skeleton sequences as entangled spatiotemporal representations and confine the contrasts to the same level of representation. Instead, this paper introduces a novel contrastive learning framework, namely Spatiotemporal Clues Disentanglement Network (SCD-Net). Specifically, we integrate the decoupling module with a feature extractor to derive explicit clues from spatial and temporal domains respectively. As for the training of SCD-Net, with a constructed global anchor, we encourage the interaction between the anchor and extracted clues. Further, we propose a new masking strategy with structural constraints to strengthen the contextual associations, leveraging the latest development from masked image modelling into the proposed SCD-Net. We conduct extensive evaluations on the NTU-RGB+D (60&120) and PKU-MMD (I&II) datasets, covering various downstream tasks such as action recognition, action retrieval, transfer learning, and semi-supervised learning. The experimental results demonstrate the effectiveness of our method, which outperforms the existing state-of-the-art (SOTA) approaches significantly.
The Multi-Modal Video Reasoning and Analyzing Competition
Aug 18, 2021



In this paper, we introduce the Multi-Modal Video Reasoning and Analyzing Competition (MMVRAC) workshop in conjunction with ICCV 2021. This competition is composed of four different tracks, namely, video question answering, skeleton-based action recognition, fisheye video-based action recognition, and person re-identification, which are based on two datasets: SUTD-TrafficQA and UAV-Human. We summarize the top-performing methods submitted by the participants in this competition and show their results achieved in the competition.