 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiahao Wang
OneActor: Consistent Character Generation via Cluster-Conditioned Guidance
Apr 16, 2024
Text-to-image diffusion models benefit artists with high-quality image generation. Yet its stochastic nature prevent artists from creating consistent images of the same character. Existing methods try to tackle this challenge and generate consistent content in various ways. However, they either depend on external data or require expensive tuning of the diffusion model. For this issue, we argue that a lightweight but intricate guidance is enough to function. Aiming at this, we lead the way to formalize the objective of consistent generation, derive a clustering-based score function and propose a novel paradigm, OneActor. We design a cluster-conditioned model which incorporates posterior samples to guide the denoising trajectories towards the target cluster. To overcome the overfitting challenge shared by one-shot tuning pipelines, we devise auxiliary components to simultaneously augment the tuning and regulate the inference. This technique is later verified to significantly enhance the content diversity of generated images. Comprehensive experiments show that our method outperforms a variety of baselines with satisfactory character consistency, superior prompt conformity as well as high image quality. And our method is at least 4 times faster than tuning-based baselines. Furthermore, to our best knowledge, we first prove that the semantic space has the same interpolation property as the latent space dose. This property can serve as another promising tool for fine generation control.
Adapting LLaMA Decoder to Vision Transformer
Apr 13, 2024This work examines whether decoder-only Transformers such as LLaMA, which were originally designed for large language models (LLMs), can be adapted to the computer vision field. We first "LLaMAfy" a standard ViT step-by-step to align with LLaMA's architecture, and find that directly applying a casual mask to the self-attention brings an attention collapse issue, resulting in the failure to the network training. We suggest to reposition the class token behind the image tokens with a post-sequence class token technique to overcome this challenge, enabling causal self-attention to efficiently capture the entire image's information. Additionally, we develop a soft mask strategy that gradually introduces a casual mask to the self-attention at the onset of training to facilitate the optimization behavior. The tailored model, dubbed as image LLaMA (iLLaMA), is akin to LLaMA in architecture and enables direct supervised learning. Its causal self-attention boosts computational efficiency and learns complex representation by elevating attention map ranks. iLLaMA rivals the performance with its encoder-only counterparts, achieving 75.1% ImageNet top-1 accuracy with only 5.7M parameters. Scaling the model to ~310M and pre-training on ImageNet-21K further enhances the accuracy to 86.0%. Extensive experiments demonstrate iLLaMA's reliable properties: calibration, shape-texture bias, quantization compatibility, ADE20K segmentation and CIFAR transfer learning. We hope our study can kindle fresh views to visual model design in the wave of LLMs. Pre-trained models and codes are available here.
Rethinking Kullback-Leibler Divergence in Knowledge Distillation for Large Language Models
Apr 03, 2024Kullback-Leiber divergence has been widely used in Knowledge Distillation (KD) to compress Large Language Models (LLMs). Contrary to prior assertions that reverse Kullback-Leibler (RKL) divergence is mode-seeking and thus preferable over the mean-seeking forward Kullback-Leibler (FKL) divergence, this study empirically and theoretically demonstrates that neither mode-seeking nor mean-seeking properties manifest in KD for LLMs. Instead, RKL and FKL are found to share the same optimization objective and both converge after a sufficient number of epochs. However, due to practical constraints, LLMs are seldom trained for such an extensive number of epochs. Meanwhile, we further find that RKL focuses on the tail part of the distributions, while FKL focuses on the head part at the beginning epochs. Consequently, we propose a simple yet effective Adaptive Kullback-Leiber (AKL) divergence method, which adaptively allocates weights to combine FKL and RKL. Metric-based and GPT-4-based evaluations demonstrate that the proposed AKL outperforms the baselines across various tasks and improves the diversity and quality of generated responses.
Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
Mar 14, 2024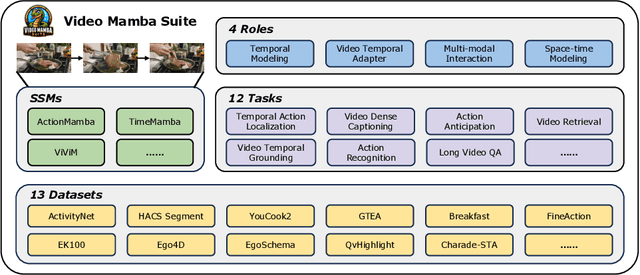

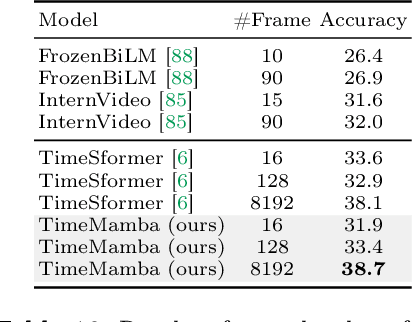
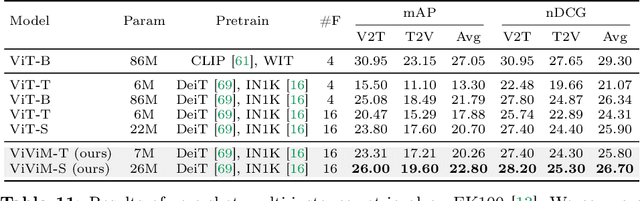
Understanding videos is one of the fundamental directions in computer vision research, with extensive efforts dedicated to exploring various architectures such as RNN, 3D CNN, and Transformers. The newly proposed architecture of state space model, e.g., Mamba, shows promising traits to extend its success in long sequence modeling to video modeling. To assess whether Mamba can be a viable alternative to Transformers in the video understanding domain, in this work, we conduct a comprehensive set of studies, probing different roles Mamba can play in modeling videos, while investigating diverse tasks where Mamba could exhibit superiority. We categorize Mamba into four roles for modeling videos, deriving a Video Mamba Suite composed of 14 models/modules, and evaluating them on 12 video understanding tasks. Our extensive experiments reveal the strong potential of Mamba on both video-only and video-language tasks while showing promising efficiency-performance trade-offs. We hope this work could provide valuable data points and insights for future research on video understanding. Code is public: https://github.com/OpenGVLab/video-mamba-suite.
Radiative Gaussian Splatting for Efficient X-ray Novel View Synthesis
Mar 07, 2024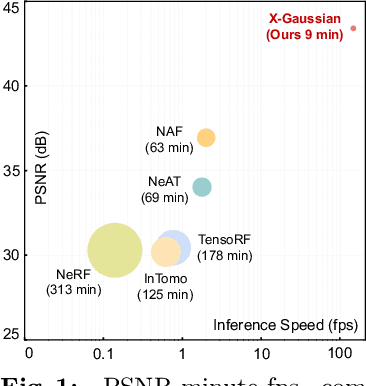
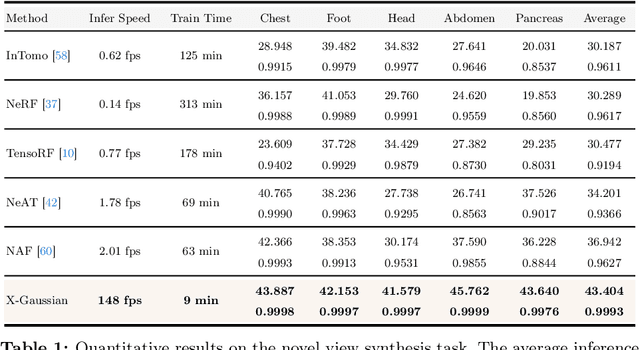

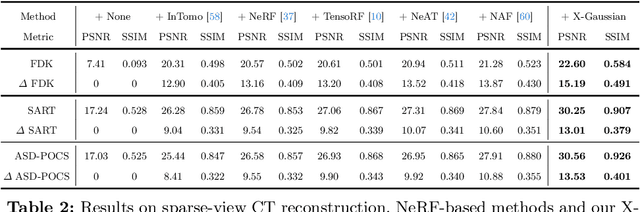
X-ray is widely applied for transmission imaging due to its stronger penetration than natural light. When rendering novel view X-ray projections, existing methods mainly based on NeRF suffer from long training time and slow inference speed. In this paper, we propose a 3D Gaussian splatting-based framework, namely X-Gaussian, for X-ray novel view synthesis. Firstly, we redesign a radiative Gaussian point cloud model inspired by the isotropic nature of X-ray imaging. Our model excludes the influence of view direction when learning to predict the radiation intensity of 3D points. Based on this model, we develop a Differentiable Radiative Rasterization (DRR) with CUDA implementation. Secondly, we customize an Angle-pose Cuboid Uniform Initialization (ACUI) strategy that directly uses the parameters of the X-ray scanner to compute the camera information and then uniformly samples point positions within a cuboid enclosing the scanned object. Experiments show that our X-Gaussian outperforms state-of-the-art methods by 6.5 dB while enjoying less than 15% training time and over 73x inference speed. The application on sparse-view CT reconstruction also reveals the practical values of our method. Code and models will be publicly available at https://github.com/caiyuanhao1998/X-Gaussian . A video demo of the training process visualization is at https://www.youtube.com/watch?v=gDVf_Ngeghg .
Poisson-Gamma Dynamical Systems with Non-Stationary Transition Dynamics
Feb 26, 2024Bayesian methodologies for handling count-valued time series have gained prominence due to their ability to infer interpretable latent structures and to estimate uncertainties, and thus are especially suitable for dealing with noisy and incomplete count data. Among these Bayesian models, Poisson-Gamma Dynamical Systems (PGDSs) are proven to be effective in capturing the evolving dynamics underlying observed count sequences. However, the state-of-the-art PGDS still falls short in capturing the time-varying transition dynamics that are commonly observed in real-world count time series. To mitigate this limitation, a non-stationary PGDS is proposed to allow the underlying transition matrices to evolve over time, and the evolving transition matrices are modeled by sophisticatedly-designed Dirichlet Markov chains. Leveraging Dirichlet-Multinomial-Beta data augmentation techniques, a fully-conjugate and efficient Gibbs sampler is developed to perform posterior simulation. Experiments show that, in comparison with related models, the proposed non-stationary PGDS achieves improved predictive performance due to its capacity to learn non-stationary dependency structure captured by the time-evolving transition matrices.
LLMs as Bridges: Reformulating Grounded Multimodal Named Entity Recognition
Feb 17, 2024Grounded Multimodal Named Entity Recognition (GMNER) is a nascent multimodal task that aims to identify named entities, entity types and their corresponding visual regions. GMNER task exhibits two challenging properties: 1) The weak correlation between image-text pairs in social media results in a significant portion of named entities being ungroundable. 2) There exists a distinction between coarse-grained referring expressions commonly used in similar tasks (e.g., phrase localization, referring expression comprehension) and fine-grained named entities. In this paper, we propose RiVEG, a unified framework that reformulates GMNER into a joint MNER-VE-VG task by leveraging large language models (LLMs) as a connecting bridge. This reformulation brings two benefits: 1) It maintains the optimal MNER performance and eliminates the need for employing object detection methods to pre-extract regional features, thereby naturally addressing two major limitations of existing GMNER methods. 2) The introduction of entity expansion expression and Visual Entailment (VE) Module unifies Visual Grounding (VG) and Entity Grounding (EG). It enables RiVEG to effortlessly inherit the Visual Entailment and Visual Grounding capabilities of any current or prospective multimodal pretraining models. Extensive experiments demonstrate that RiVEG outperforms state-of-the-art methods on the existing GMNER dataset and achieves absolute leads of 10.65%, 6.21%, and 8.83% in all three subtasks.
Less is more: Ensemble Learning for Retinal Disease Recognition Under Limited Resources
Feb 15, 2024Retinal optical coherence tomography (OCT) images provide crucial insights into the health of the posterior ocular segment. Therefore, the advancement of automated image analysis methods is imperative to equip clinicians and researchers with quantitative data, thereby facilitating informed decision-making. The application of deep learning (DL)-based approaches has gained extensive traction for executing these analysis tasks, demonstrating remarkable performance compared to labor-intensive manual analyses. However, the acquisition of Retinal OCT images often presents challenges stemming from privacy concerns and the resource-intensive labeling procedures, which contradicts the prevailing notion that DL models necessitate substantial data volumes for achieving superior performance. Moreover, limitations in available computational resources constrain the progress of high-performance medical artificial intelligence, particularly in less developed regions and countries. This paper introduces a novel ensemble learning mechanism designed for recognizing retinal diseases under limited resources (e.g., data, computation). The mechanism leverages insights from multiple pre-trained models, facilitating the transfer and adaptation of their knowledge to Retinal OCT images. This approach establishes a robust model even when confronted with limited labeled data, eliminating the need for an extensive array of parameters, as required in learning from scratch. Comprehensive experimentation on real-world datasets demonstrates that the proposed approach can achieve superior performance in recognizing Retinal OCT images, even when dealing with exceedingly restricted labeled datasets. Furthermore, this method obviates the necessity of learning extensive-scale parameters, making it well-suited for deployment in low-resource scenarios.
A Survey on Data Selection for LLM Instruction Tuning
Feb 04, 2024Instruction tuning is a vital step of training large language models (LLM), so how to enhance the effect of instruction tuning has received increased attention. Existing works indicate that the quality of the dataset is more crucial than the quantity during instruction tuning of LLM. Therefore, recently a lot of studies focus on exploring the methods of selecting high-quality subset from instruction datasets, aiming to reduce training costs and enhance the instruction-following capabilities of LLMs. This paper presents a comprehensive survey on data selection for LLM instruction tuning. Firstly, we introduce the wildly used instruction datasets. Then, we propose a new taxonomy of the data selection methods and provide a detailed introduction of recent advances,and the evaluation strategies and results of data selection methods are also elaborated in detail. Finally, we emphasize the open challenges and present new frontiers of this task.
LLaMA Pro: Progressive LLaMA with Block Expansion
Jan 04, 2024Humans generally acquire new skills without compromising the old; however, the opposite holds for Large Language Models (LLMs), e.g., from LLaMA to CodeLLaMA. To this end, we propose a new post-pretraining method for LLMs with an expansion of Transformer blocks. We tune the expanded blocks using only new corpus, efficiently and effectively improving the model's knowledge without catastrophic forgetting. In this paper, we experiment on the corpus of code and math, yielding LLaMA Pro-8.3B, a versatile foundation model initialized from LLaMA2-7B, excelling in general tasks, programming, and mathematics. LLaMA Pro and its instruction-following counterpart (LLaMA Pro-Instruct) achieve advanced performance among various benchmarks, demonstrating superiority over existing open models in the LLaMA family and the immense potential of reasoning and addressing diverse tasks as an intelligent agent. Our findings provide valuable insights into integrating natural and programming languages, laying a solid foundation for developing advanced language agents that operate effectively in various environments.