 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBolin Zhang
A Survey on Data Selection for LLM Instruction Tuning
Feb 04, 2024
Instruction tuning is a vital step of training large language models (LLM), so how to enhance the effect of instruction tuning has received increased attention. Existing works indicate that the quality of the dataset is more crucial than the quantity during instruction tuning of LLM. Therefore, recently a lot of studies focus on exploring the methods of selecting high-quality subset from instruction datasets, aiming to reduce training costs and enhance the instruction-following capabilities of LLMs. This paper presents a comprehensive survey on data selection for LLM instruction tuning. Firstly, we introduce the wildly used instruction datasets. Then, we propose a new taxonomy of the data selection methods and provide a detailed introduction of recent advances,and the evaluation strategies and results of data selection methods are also elaborated in detail. Finally, we emphasize the open challenges and present new frontiers of this task.
HeroNet: A Hybrid Retrieval-Generation Network for Conversational Bots
Feb 08, 2023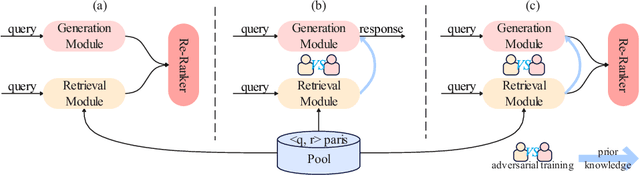

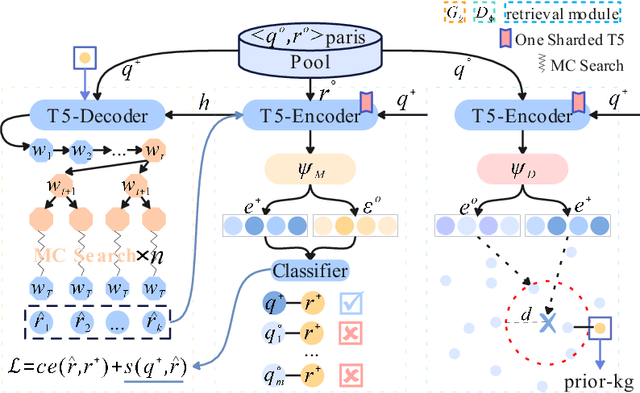
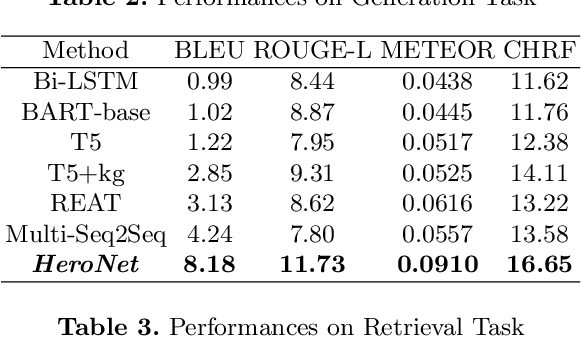
Using natural language, Conversational Bot offers unprecedented ways to many challenges in areas such as information searching, item recommendation, and question answering. Existing bots are usually developed through retrieval-based or generative-based approaches, yet both of them have their own advantages and disadvantages. To assemble this two approaches, we propose a hybrid retrieval-generation network (HeroNet) with the three-fold ideas: 1). To produce high-quality sentence representations, HeroNet performs multi-task learning on two subtasks: Similar Queries Discovery and Query-Response Matching. Specifically, the retrieval performance is improved while the model size is reduced by training two lightweight, task-specific adapter modules that share only one underlying T5-Encoder model. 2). By introducing adversarial training, HeroNet is able to solve both retrieval\&generation tasks simultaneously while maximizing performance of each other. 3). The retrieval results are used as prior knowledge to improve the generation performance while the generative result are scored by the discriminator and their scores are integrated into the generator's cross-entropy loss function. The experimental results on a open dataset demonstrate the effectiveness of the HeroNet and our code is available at https://github.com/TempHero/HeroNet.git
Requirements Elicitation in Cognitive Service for Recommendation
Mar 29, 2022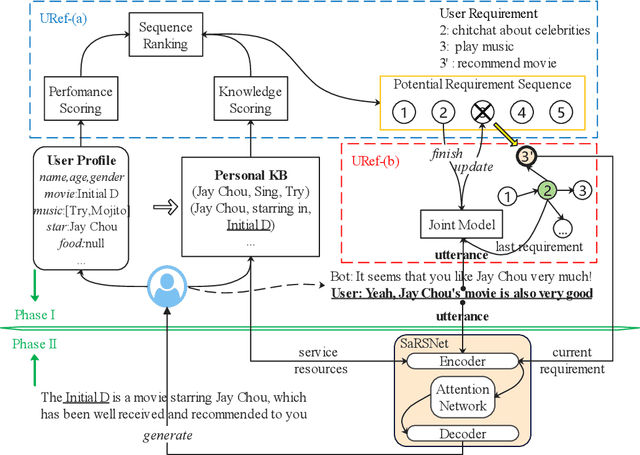

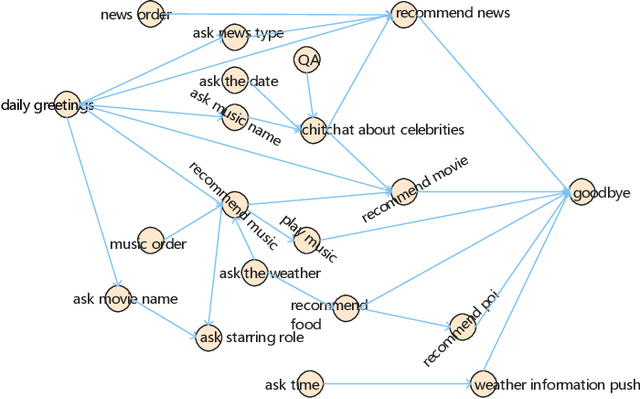
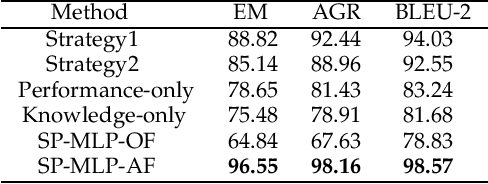
Nowadays, cognitive service provides more interactive way to understand users' requirements via human-machine conversation. In other words, it has to capture users' requirements from their utterance and respond them with the relevant and suitable service resources. To this end, two phases must be applied: I.Sequence planning and Real-time detection of user requirement, II.Service resource selection and Response generation. The existing works ignore the potential connection between these two phases. To model their connection, Two-Phase Requirement Elicitation Method is proposed. For the phase I, this paper proposes a user requirement elicitation framework (URef) to plan a potential requirement sequence grounded on user profile and personal knowledge base before the conversation. In addition, it can also predict user's true requirement and judge whether the requirement is completed based on the user's utterance during the conversation. For the phase II, this paper proposes a response generation model based on attention, SaRSNet. It can select the appropriate resource (i.e. knowledge triple) in line with the requirement predicted by URef, and then generates a suitable response for recommendation. The experimental results on the open dataset \emph{DuRecDial} have been significantly improved compared to the baseline, which proves the effectiveness of the proposed methods.