 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTong Lu
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Apr 29, 2024
In this report, we introduce InternVL 1.5, an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding. We introduce three simple improvements: (1) Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model -- InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs. (2) Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448$\times$448 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input. (3) High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks. We evaluate InternVL 1.5 through a series of benchmarks and comparative studies. Compared to both open-source and proprietary models, InternVL 1.5 shows competitive performance, achieving state-of-the-art results in 8 of 18 benchmarks. Code has been released at https://github.com/OpenGVLab/InternVL.
Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
Mar 14, 2024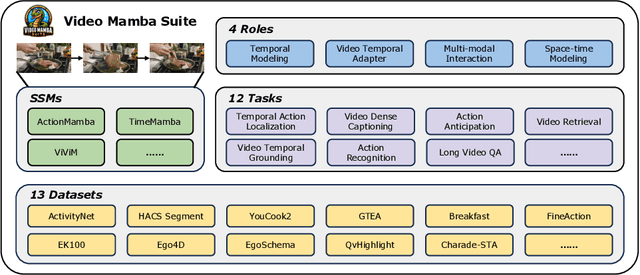

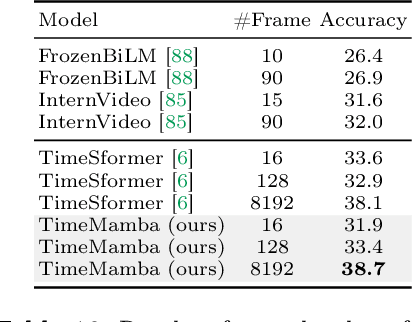
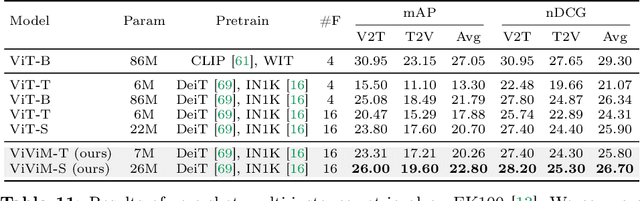
Understanding videos is one of the fundamental directions in computer vision research, with extensive efforts dedicated to exploring various architectures such as RNN, 3D CNN, and Transformers. The newly proposed architecture of state space model, e.g., Mamba, shows promising traits to extend its success in long sequence modeling to video modeling. To assess whether Mamba can be a viable alternative to Transformers in the video understanding domain, in this work, we conduct a comprehensive set of studies, probing different roles Mamba can play in modeling videos, while investigating diverse tasks where Mamba could exhibit superiority. We categorize Mamba into four roles for modeling videos, deriving a Video Mamba Suite composed of 14 models/modules, and evaluating them on 12 video understanding tasks. Our extensive experiments reveal the strong potential of Mamba on both video-only and video-language tasks while showing promising efficiency-performance trade-offs. We hope this work could provide valuable data points and insights for future research on video understanding. Code is public: https://github.com/OpenGVLab/video-mamba-suite.
Vision-RWKV: Efficient and Scalable Visual Perception with RWKV-Like Architectures
Mar 07, 2024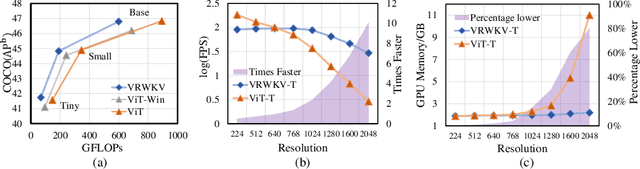

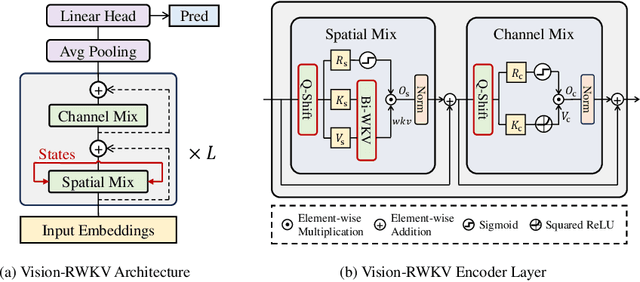
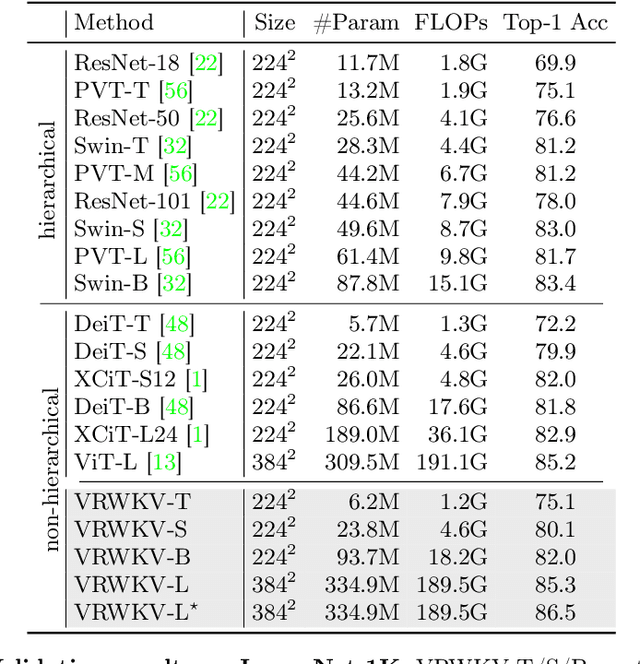
Transformers have revolutionized computer vision and natural language processing, but their high computational complexity limits their application in high-resolution image processing and long-context analysis. This paper introduces Vision-RWKV (VRWKV), a model adapted from the RWKV model used in the NLP field with necessary modifications for vision tasks. Similar to the Vision Transformer (ViT), our model is designed to efficiently handle sparse inputs and demonstrate robust global processing capabilities, while also scaling up effectively, accommodating both large-scale parameters and extensive datasets. Its distinctive advantage lies in its reduced spatial aggregation complexity, which renders it exceptionally adept at processing high-resolution images seamlessly, eliminating the necessity for windowing operations. Our evaluations demonstrate that VRWKV surpasses ViT's performance in image classification and has significantly faster speeds and lower memory usage processing high-resolution inputs. In dense prediction tasks, it outperforms window-based models, maintaining comparable speeds. These results highlight VRWKV's potential as a more efficient alternative for visual perception tasks. Code is released at \url{https://github.com/OpenGVLab/Vision-RWKV}.
PromptRR: Diffusion Models as Prompt Generators for Single Image Reflection Removal
Feb 04, 2024Existing single image reflection removal (SIRR) methods using deep learning tend to miss key low-frequency (LF) and high-frequency (HF) differences in images, affecting their effectiveness in removing reflections. To address this problem, this paper proposes a novel prompt-guided reflection removal (PromptRR) framework that uses frequency information as new visual prompts for better reflection performance. Specifically, the proposed framework decouples the reflection removal process into the prompt generation and subsequent prompt-guided restoration. For the prompt generation, we first propose a prompt pre-training strategy to train a frequency prompt encoder that encodes the ground-truth image into LF and HF prompts. Then, we adopt diffusion models (DMs) as prompt generators to generate the LF and HF prompts estimated by the pre-trained frequency prompt encoder. For the prompt-guided restoration, we integrate specially generated prompts into the PromptFormer network, employing a novel Transformer-based prompt block to effectively steer the model toward enhanced reflection removal. The results on commonly used benchmarks show that our method outperforms state-of-the-art approaches. The codes and models are available at https://github.com/TaoWangzj/PromptRR.
MM-Interleaved: Interleaved Image-Text Generative Modeling via Multi-modal Feature Synchronizer
Jan 18, 2024Developing generative models for interleaved image-text data has both research and practical value. It requires models to understand the interleaved sequences and subsequently generate images and text. However, existing attempts are limited by the issue that the fixed number of visual tokens cannot efficiently capture image details, which is particularly problematic in the multi-image scenarios. To address this, this paper presents MM-Interleaved, an end-to-end generative model for interleaved image-text data. It introduces a multi-scale and multi-image feature synchronizer module, allowing direct access to fine-grained image features in the previous context during the generation process. MM-Interleaved is end-to-end pre-trained on both paired and interleaved image-text corpora. It is further enhanced through a supervised fine-tuning phase, wherein the model improves its ability to follow complex multi-modal instructions. Experiments demonstrate the versatility of MM-Interleaved in recognizing visual details following multi-modal instructions and generating consistent images following both textual and visual conditions. Code and models are available at \url{https://github.com/OpenGVLab/MM-Interleaved}.
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Jan 15, 2024The exponential growth of large language models (LLMs) has opened up numerous possibilities for multimodal AGI systems. However, the progress in vision and vision-language foundation models, which are also critical elements of multi-modal AGI, has not kept pace with LLMs. In this work, we design a large-scale vision-language foundation model (InternVL), which scales up the vision foundation model to 6 billion parameters and progressively aligns it with the LLM, using web-scale image-text data from various sources. This model can be broadly applied to and achieve state-of-the-art performance on 32 generic visual-linguistic benchmarks including visual perception tasks such as image-level or pixel-level recognition, vision-language tasks such as zero-shot image/video classification, zero-shot image/video-text retrieval, and link with LLMs to create multi-modal dialogue systems. It has powerful visual capabilities and can be a good alternative to the ViT-22B. We hope that our research could contribute to the development of multi-modal large models. Code and models are available at https://github.com/OpenGVLab/InternVL.
Efficient Deformable ConvNets: Rethinking Dynamic and Sparse Operator for Vision Applications
Jan 11, 2024We introduce Deformable Convolution v4 (DCNv4), a highly efficient and effective operator designed for a broad spectrum of vision applications. DCNv4 addresses the limitations of its predecessor, DCNv3, with two key enhancements: 1. removing softmax normalization in spatial aggregation to enhance its dynamic property and expressive power and 2. optimizing memory access to minimize redundant operations for speedup. These improvements result in a significantly faster convergence compared to DCNv3 and a substantial increase in processing speed, with DCNv4 achieving more than three times the forward speed. DCNv4 demonstrates exceptional performance across various tasks, including image classification, instance and semantic segmentation, and notably, image generation. When integrated into generative models like U-Net in the latent diffusion model, DCNv4 outperforms its baseline, underscoring its possibility to enhance generative models. In practical applications, replacing DCNv3 with DCNv4 in the InternImage model to create FlashInternImage results in up to 80% speed increase and further performance improvement without further modifications. The advancements in speed and efficiency of DCNv4, combined with its robust performance across diverse vision tasks, show its potential as a foundational building block for future vision models.
CRA-PCN: Point Cloud Completion with Intra- and Inter-level Cross-Resolution Transformers
Jan 03, 2024Point cloud completion is an indispensable task for recovering complete point clouds due to incompleteness caused by occlusion, limited sensor resolution, etc. The family of coarse-to-fine generation architectures has recently exhibited great success in point cloud completion and gradually became mainstream. In this work, we unveil one of the key ingredients behind these methods: meticulously devised feature extraction operations with explicit cross-resolution aggregation. We present Cross-Resolution Transformer that efficiently performs cross-resolution aggregation with local attention mechanisms. With the help of our recursive designs, the proposed operation can capture more scales of features than common aggregation operations, which is beneficial for capturing fine geometric characteristics. While prior methodologies have ventured into various manifestations of inter-level cross-resolution aggregation, the effectiveness of intra-level one and their combination has not been analyzed. With unified designs, Cross-Resolution Transformer can perform intra- or inter-level cross-resolution aggregation by switching inputs. We integrate two forms of Cross-Resolution Transformers into one up-sampling block for point generation, and following the coarse-to-fine manner, we construct CRA-PCN to incrementally predict complete shapes with stacked up-sampling blocks. Extensive experiments demonstrate that our method outperforms state-of-the-art methods by a large margin on several widely used benchmarks. Codes are available at https://github.com/EasyRy/CRA-PCN.
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
Dec 05, 2023End-to-end autonomous driving recently emerged as a promising research direction to target autonomy from a full-stack perspective. Along this line, many of the latest works follow an open-loop evaluation setting on nuScenes to study the planning behavior. In this paper, we delve deeper into the problem by conducting thorough analyses and demystifying more devils in the details. We initially observed that the nuScenes dataset, characterized by relatively simple driving scenarios, leads to an under-utilization of perception information in end-to-end models incorporating ego status, such as the ego vehicle's velocity. These models tend to rely predominantly on the ego vehicle's status for future path planning. Beyond the limitations of the dataset, we also note that current metrics do not comprehensively assess the planning quality, leading to potentially biased conclusions drawn from existing benchmarks. To address this issue, we introduce a new metric to evaluate whether the predicted trajectories adhere to the road. We further propose a simple baseline able to achieve competitive results without relying on perception annotations. Given the current limitations on the benchmark and metrics, we suggest the community reassess relevant prevailing research and be cautious whether the continued pursuit of state-of-the-art would yield convincing and universal conclusions. Code and models are available at \url{https://github.com/NVlabs/BEV-Planner}
Deep Video Restoration for Under-Display Camera
Sep 09, 2023
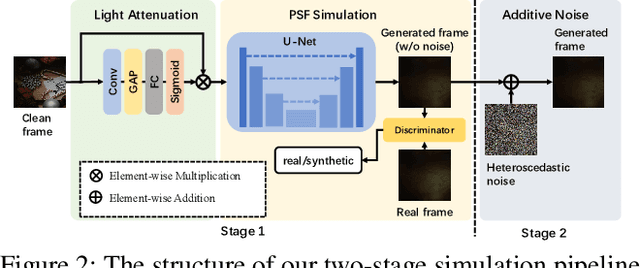
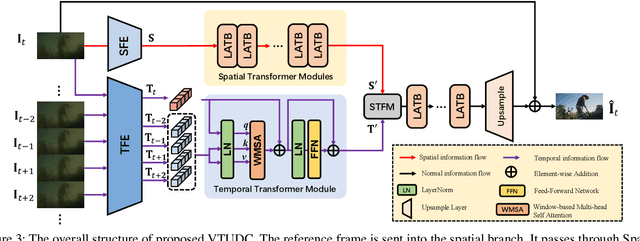
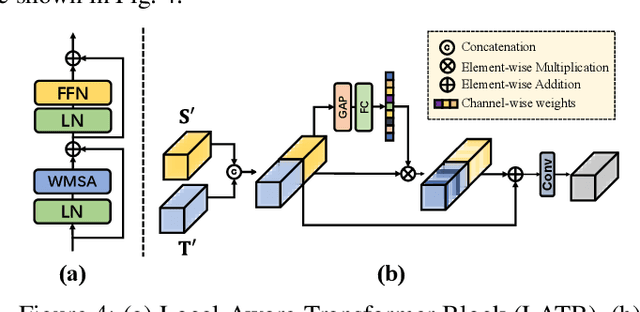
Images or videos captured by the Under-Display Camera (UDC) suffer from severe degradation, such as saturation degeneration and color shift. While restoration for UDC has been a critical task, existing works of UDC restoration focus only on images. UDC video restoration (UDC-VR) has not been explored in the community. In this work, we first propose a GAN-based generation pipeline to simulate the realistic UDC degradation process. With the pipeline, we build the first large-scale UDC video restoration dataset called PexelsUDC, which includes two subsets named PexelsUDC-T and PexelsUDC-P corresponding to different displays for UDC. Using the proposed dataset, we conduct extensive benchmark studies on existing video restoration methods and observe their limitations on the UDC-VR task. To this end, we propose a novel transformer-based baseline method that adaptively enhances degraded videos. The key components of the method are a spatial branch with local-aware transformers, a temporal branch embedded temporal transformers, and a spatial-temporal fusion module. These components drive the model to fully exploit spatial and temporal information for UDC-VR. Extensive experiments show that our method achieves state-of-the-art performance on PexelsUDC. The benchmark and the baseline method are expected to promote the progress of UDC-VR in the community, which will be made public.