 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBotian Shi
Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond
May 06, 2024
General world models represent a crucial pathway toward achieving Artificial General Intelligence (AGI), serving as the cornerstone for various applications ranging from virtual environments to decision-making systems. Recently, the emergence of the Sora model has attained significant attention due to its remarkable simulation capabilities, which exhibits an incipient comprehension of physical laws. In this survey, we embark on a comprehensive exploration of the latest advancements in world models. Our analysis navigates through the forefront of generative methodologies in video generation, where world models stand as pivotal constructs facilitating the synthesis of highly realistic visual content. Additionally, we scrutinize the burgeoning field of autonomous-driving world models, meticulously delineating their indispensable role in reshaping transportation and urban mobility. Furthermore, we delve into the intricacies inherent in world models deployed within autonomous agents, shedding light on their profound significance in enabling intelligent interactions within dynamic environmental contexts. At last, we examine challenges and limitations of world models, and discuss their potential future directions. We hope this survey can serve as a foundational reference for the research community and inspire continued innovation. This survey will be regularly updated at: https://github.com/GigaAI-research/General-World-Models-Survey.
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Apr 29, 2024In this report, we introduce InternVL 1.5, an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding. We introduce three simple improvements: (1) Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model -- InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs. (2) Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448$\times$448 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input. (3) High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks. We evaluate InternVL 1.5 through a series of benchmarks and comparative studies. Compared to both open-source and proprietary models, InternVL 1.5 shows competitive performance, achieving state-of-the-art results in 8 of 18 benchmarks. Code has been released at https://github.com/OpenGVLab/InternVL.
UniMERNet: A Universal Network for Real-World Mathematical Expression Recognition
Apr 23, 2024This paper presents the UniMER dataset to provide the first study on Mathematical Expression Recognition (MER) towards complex real-world scenarios. The UniMER dataset consists of a large-scale training set UniMER-1M offering an unprecedented scale and diversity with one million training instances and a meticulously designed test set UniMER-Test that reflects a diverse range of formula distributions prevalent in real-world scenarios. Therefore, the UniMER dataset enables the training of a robust and high-accuracy MER model and comprehensive evaluation of model performance. Moreover, we introduce the Universal Mathematical Expression Recognition Network (UniMERNet), an innovative framework designed to enhance MER in practical scenarios. UniMERNet incorporates a Length-Aware Module to process formulas of varied lengths efficiently, thereby enabling the model to handle complex mathematical expressions with greater accuracy. In addition, UniMERNet employs our UniMER-1M data and image augmentation techniques to improve the model's robustness under different noise conditions. Our extensive experiments demonstrate that UniMERNet outperforms existing MER models, setting a new benchmark in various scenarios and ensuring superior recognition quality in real-world applications. The dataset and model are available at https://github.com/opendatalab/UniMERNet.
ChartX & ChartVLM: A Versatile Benchmark and Foundation Model for Complicated Chart Reasoning
Feb 19, 2024Recently, many versatile Multi-modal Large Language Models (MLLMs) have emerged continuously. However, their capacity to query information depicted in visual charts and engage in reasoning based on the queried contents remains under-explored. In this paper, to comprehensively and rigorously benchmark the ability of the off-the-shelf MLLMs in the chart domain, we construct ChartX, a multi-modal evaluation set covering 18 chart types, 7 chart tasks, 22 disciplinary topics, and high-quality chart data. Besides, we develop ChartVLM to offer a new perspective on handling multi-modal tasks that strongly depend on interpretable patterns, such as reasoning tasks in the field of charts or geometric images. We evaluate the chart-related ability of mainstream MLLMs and our ChartVLM on the proposed ChartX evaluation set. Extensive experiments demonstrate that ChartVLM surpasses both versatile and chart-related large models, achieving results comparable to GPT-4V. We believe that our study can pave the way for further exploration in creating a more comprehensive chart evaluation set and developing more interpretable multi-modal models. Both ChartX and ChartVLM are available at: https://github.com/UniModal4Reasoning/ChartVLM
OASim: an Open and Adaptive Simulator based on Neural Rendering for Autonomous Driving
Feb 06, 2024With deep learning and computer vision technology development, autonomous driving provides new solutions to improve traffic safety and efficiency. The importance of building high-quality datasets is self-evident, especially with the rise of end-to-end autonomous driving algorithms in recent years. Data plays a core role in the algorithm closed-loop system. However, collecting real-world data is expensive, time-consuming, and unsafe. With the development of implicit rendering technology and in-depth research on using generative models to produce data at scale, we propose OASim, an open and adaptive simulator and autonomous driving data generator based on implicit neural rendering. It has the following characteristics: (1) High-quality scene reconstruction through neural implicit surface reconstruction technology. (2) Trajectory editing of the ego vehicle and participating vehicles. (3) Rich vehicle model library that can be freely selected and inserted into the scene. (4) Rich sensors model library where you can select specified sensors to generate data. (5) A highly customizable data generation system can generate data according to user needs. We demonstrate the high quality and fidelity of the generated data through perception performance evaluation on the Carla simulator and real-world data acquisition. Code is available at https://github.com/PJLab-ADG/OASim.
LimSim++: A Closed-Loop Platform for Deploying Multimodal LLMs in Autonomous Driving
Feb 02, 2024The emergence of Multimodal Large Language Models ((M)LLMs) has ushered in new avenues in artificial intelligence, particularly for autonomous driving by offering enhanced understanding and reasoning capabilities. This paper introduces LimSim++, an extended version of LimSim designed for the application of (M)LLMs in autonomous driving. Acknowledging the limitations of existing simulation platforms, LimSim++ addresses the need for a long-term closed-loop infrastructure supporting continuous learning and improved generalization in autonomous driving. The platform offers extended-duration, multi-scenario simulations, providing crucial information for (M)LLM-driven vehicles. Users can engage in prompt engineering, model evaluation, and framework enhancement, making LimSim++ a versatile tool for research and practice. This paper additionally introduces a baseline (M)LLM-driven framework, systematically validated through quantitative experiments across diverse scenarios. The open-source resources of LimSim++ are available at: https://pjlab-adg.github.io/limsim_plus/.
Realistic Rainy Weather Simulation for LiDARs in CARLA Simulator
Dec 20, 2023Employing data augmentation methods to enhance perception performance in adverse weather has attracted considerable attention recently. Most of the LiDAR augmentation methods post-process the existing dataset by physics-based models or machine-learning methods. However, due to the limited environmental annotations and the fixed vehicle trajectories in the existing dataset, it is challenging to edit the scene and expand the diversity of traffic flow and scenario. To this end, we propose a simulator-based physical modeling approach to augment LiDAR data in rainy weather in order to improve the perception performance of LiDAR in this scenario. We complete the modeling task of the rainy weather in the CARLA simulator and establish a pipeline for LiDAR data collection. In particular, we pay special attention to the spray and splash rolled up by the wheels of surrounding vehicles in rain and complete the simulation of this special scenario through the Spray Emitter method we developed. In addition, we examine the influence of different weather conditions on the intensity of the LiDAR echo, develop a prediction network for the intensity of the LiDAR echo, and complete the simulation of 4-feat LiDAR point cloud data. In the experiment, we observe that the model augmented by the synthetic data improves the object detection task's performance in the rainy sequence of the Waymo Open Dataset. Both the code and the dataset will be made publicly available at https://github.com/PJLab-ADG/PCSim#rainypcsim.
Towards Knowledge-driven Autonomous Driving
Dec 12, 2023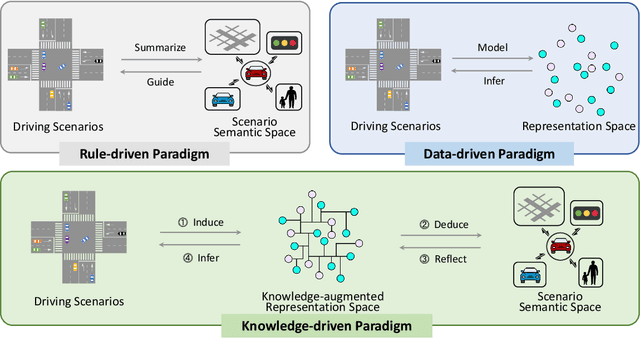
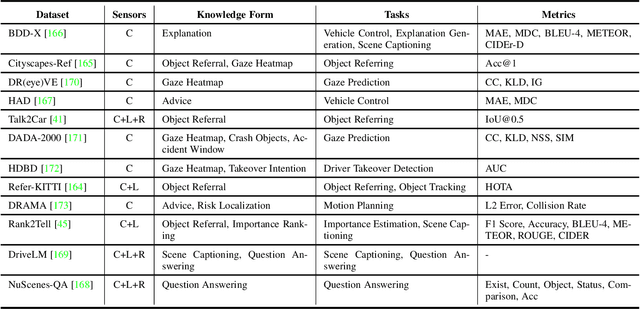
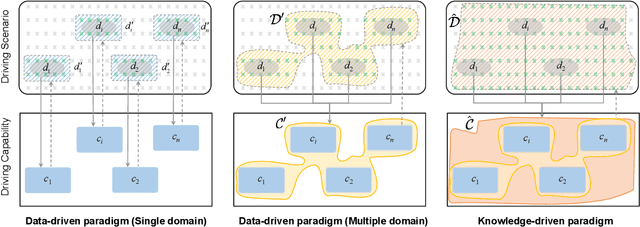
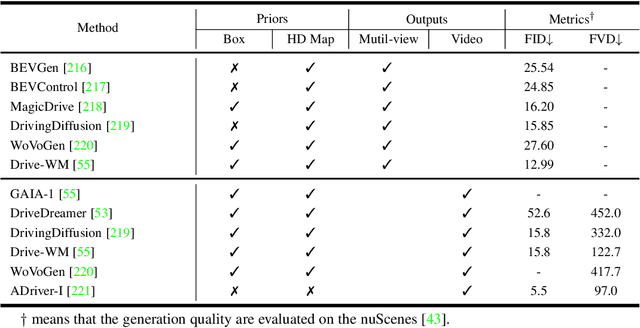
This paper explores the emerging knowledge-driven autonomous driving technologies. Our investigation highlights the limitations of current autonomous driving systems, in particular their sensitivity to data bias, difficulty in handling long-tail scenarios, and lack of interpretability. Conversely, knowledge-driven methods with the abilities of cognition, generalization and life-long learning emerge as a promising way to overcome these challenges. This paper delves into the essence of knowledge-driven autonomous driving and examines its core components: dataset \& benchmark, environment, and driver agent. By leveraging large language models, world models, neural rendering, and other advanced artificial intelligence techniques, these components collectively contribute to a more holistic, adaptive, and intelligent autonomous driving system. The paper systematically organizes and reviews previous research efforts in this area, and provides insights and guidance for future research and practical applications of autonomous driving. We will continually share the latest updates on cutting-edge developments in knowledge-driven autonomous driving along with the relevant valuable open-source resources at: \url{https://github.com/PJLab-ADG/awesome-knowledge-driven-AD}.
On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving
Nov 28, 2023



The pursuit of autonomous driving technology hinges on the sophisticated integration of perception, decision-making, and control systems. Traditional approaches, both data-driven and rule-based, have been hindered by their inability to grasp the nuance of complex driving environments and the intentions of other road users. This has been a significant bottleneck, particularly in the development of common sense reasoning and nuanced scene understanding necessary for safe and reliable autonomous driving. The advent of Visual Language Models (VLM) represents a novel frontier in realizing fully autonomous vehicle driving. This report provides an exhaustive evaluation of the latest state-of-the-art VLM, GPT-4V(ision), and its application in autonomous driving scenarios. We explore the model's abilities to understand and reason about driving scenes, make decisions, and ultimately act in the capacity of a driver. Our comprehensive tests span from basic scene recognition to complex causal reasoning and real-time decision-making under varying conditions. Our findings reveal that GPT-4V demonstrates superior performance in scene understanding and causal reasoning compared to existing autonomous systems. It showcases the potential to handle out-of-distribution scenarios, recognize intentions, and make informed decisions in real driving contexts. However, challenges remain, particularly in direction discernment, traffic light recognition, vision grounding, and spatial reasoning tasks. These limitations underscore the need for further research and development. Project is now available on GitHub for interested parties to access and utilize: \url{https://github.com/PJLab-ADG/GPT4V-AD-Exploration}
SceneDM: Scene-level Multi-agent Trajectory Generation with Consistent Diffusion Models
Nov 27, 2023Realistic scene-level multi-agent motion simulations are crucial for developing and evaluating self-driving algorithms. However, most existing works focus on generating trajectories for a certain single agent type, and typically ignore the consistency of generated trajectories. In this paper, we propose a novel framework based on diffusion models, called SceneDM, to generate joint and consistent future motions of all the agents, including vehicles, bicycles, pedestrians, etc., in a scene. To enhance the consistency of the generated trajectories, we resort to a new Transformer-based network to effectively handle agent-agent interactions in the inverse process of motion diffusion. In consideration of the smoothness of agent trajectories, we further design a simple yet effective consistent diffusion approach, to improve the model in exploiting short-term temporal dependencies. Furthermore, a scene-level scoring function is attached to evaluate the safety and road-adherence of the generated agent's motions and help filter out unrealistic simulations. Finally, SceneDM achieves state-of-the-art results on the Waymo Sim Agents Benchmark. Project webpage is available at https://alperen-hub.github.io/SceneDM.