 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJi Ma
ASPIRe: An Informative Trajectory Planner with Mutual Information Approximation for Target Search and Tracking
Mar 04, 2024
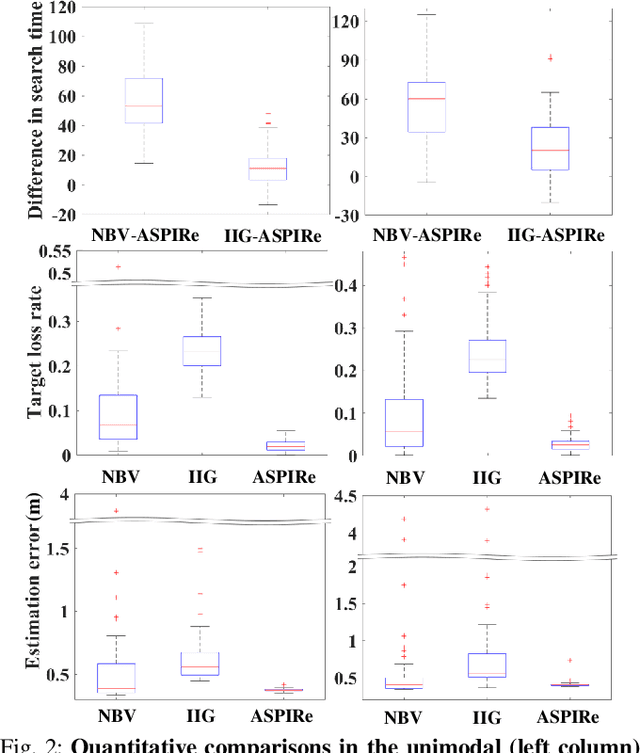
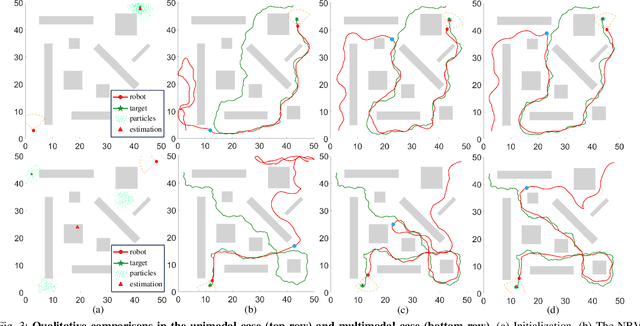
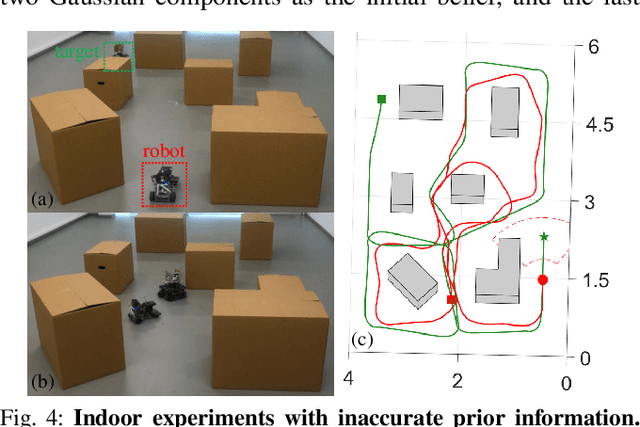
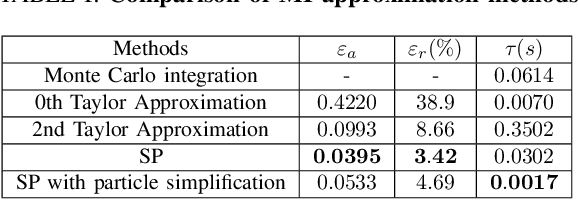
This paper proposes an informative trajectory planning approach, namely, \textit{adaptive particle filter tree with sigma point-based mutual information reward approximation} (ASPIRe), for mobile target search and tracking (SAT) in cluttered environments with limited sensing field of view. We develop a novel sigma point-based approximation to accurately estimate mutual information (MI) for general, non-Gaussian distributions utilizing particle representation of the belief state, while simultaneously maintaining high computational efficiency. Building upon the MI approximation, we develop the Adaptive Particle Filter Tree (APFT) approach with MI as the reward, which features belief state tree nodes for informative trajectory planning in continuous state and measurement spaces. An adaptive criterion is proposed in APFT to adjust the planning horizon based on the expected information gain. Simulations and physical experiments demonstrate that ASPIRe achieves real-time computation and outperforms benchmark methods in terms of both search efficiency and estimation accuracy.
DOZE: A Dataset for Open-Vocabulary Zero-Shot Object Navigation in Dynamic Environments
Feb 29, 2024Zero-Shot Object Navigation (ZSON) requires agents to autonomously locate and approach unseen objects in unfamiliar environments and has emerged as a particularly challenging task within the domain of Embodied AI. Existing datasets for developing ZSON algorithms lack consideration of dynamic obstacles, object attribute diversity, and scene texts, thus exhibiting noticeable discrepancy from real-world situations. To address these issues, we propose a Dataset for Open-Vocabulary Zero-Shot Object Navigation in Dynamic Environments (DOZE) that comprises ten high-fidelity 3D scenes with over 18k tasks, aiming to mimic complex, dynamic real-world scenarios. Specifically, DOZE scenes feature multiple moving humanoid obstacles, a wide array of open-vocabulary objects, diverse distinct-attribute objects, and valuable textual hints. Besides, different from existing datasets that only provide collision checking between the agent and static obstacles, we enhance DOZE by integrating capabilities for detecting collisions between the agent and moving obstacles. This novel functionality enables evaluation of the agents' collision avoidance abilities in dynamic environments. We test four representative ZSON methods on DOZE, revealing substantial room for improvement in existing approaches concerning navigation efficiency, safety, and object recognition accuracy. Our dataset could be found at https://DOZE-Dataset.github.io/.
VoroNav: Voronoi-based Zero-shot Object Navigation with Large Language Model
Jan 05, 2024In the realm of household robotics, the Zero-Shot Object Navigation (ZSON) task empowers agents to adeptly traverse unfamiliar environments and locate objects from novel categories without prior explicit training. This paper introduces VoroNav, a novel semantic exploration framework that proposes the Reduced Voronoi Graph to extract exploratory paths and planning nodes from a semantic map constructed in real time. By harnessing topological and semantic information, VoroNav designs text-based descriptions of paths and images that are readily interpretable by a large language model (LLM). Our approach presents a synergy of path and farsight descriptions to represent the environmental context, enabling the LLM to apply commonsense reasoning to ascertain the optimal waypoints for navigation. Extensive evaluation on the HM3D and HSSD datasets validates that VoroNav surpasses existing ZSON benchmarks in both success rates and exploration efficiency (+2.8% Success and +3.7% SPL on HM3D, +2.6% Success and +3.8% SPL on HSSD). Additionally introduced metrics that evaluate obstacle avoidance proficiency and perceptual efficiency further corroborate the enhancements achieved by our method in ZSON planning.
OpenMSD: Towards Multilingual Scientific Documents Similarity Measurement
Sep 19, 2023We develop and evaluate multilingual scientific documents similarity measurement models in this work. Such models can be used to find related works in different languages, which can help multilingual researchers find and explore papers more efficiently. We propose the first multilingual scientific documents dataset, Open-access Multilingual Scientific Documents (OpenMSD), which has 74M papers in 103 languages and 778M citation pairs. With OpenMSD, we pretrain science-specialized language models, and explore different strategies to derive "related" paper pairs to fine-tune the models, including using a mixture of citation, co-citation, and bibliographic-coupling pairs. To further improve the models' performance for non-English papers, we explore the use of generative language models to enrich the non-English papers with English summaries. This allows us to leverage the models' English capabilities to create better representations for non-English papers. Our best model significantly outperforms strong baselines by 7-16% (in mean average precision).
Probabilistic Visibility-Aware Trajectory Planning for Target Tracking in Cluttered Environments
Jun 10, 2023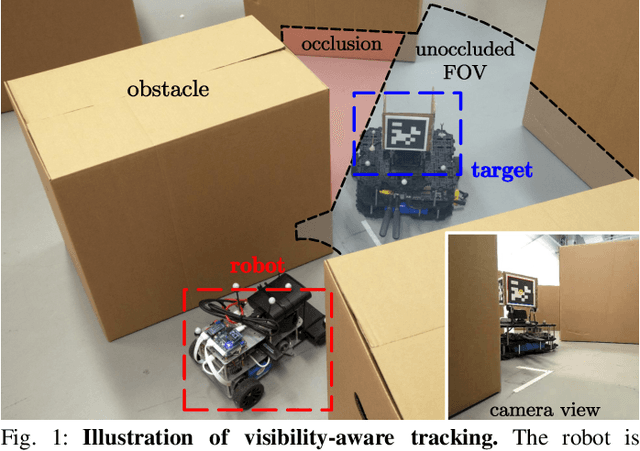
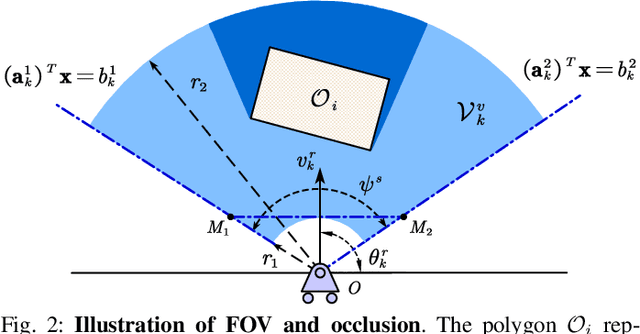
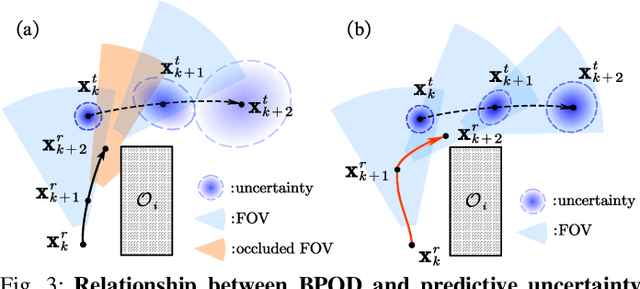
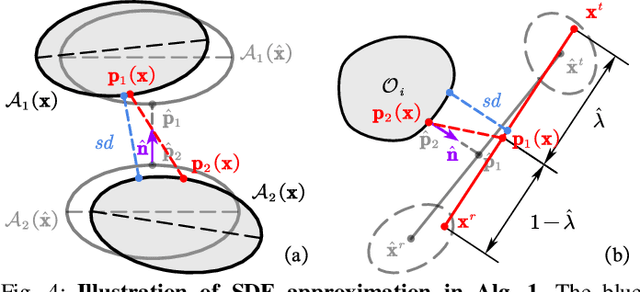
Target tracking with a mobile robot has numerous significant applications in both civilian and military. Practical challenges such as limited field-of-view, obstacle occlusion, and system uncertainty may all adversely affect tracking performance, yet few existing works can simultaneously tackle these limitations. To bridge the gap, we introduce the concept of belief-space probability of detection (BPOD) to measure the predictive visibility of the target under stochastic robot and target states. An Extended Kalman Filter variant incorporating BPOD is developed to predict target belief state under uncertain visibility within the planning horizon. Furthermore, we propose a computationally efficient algorithm to uniformly calculate both BPOD and the chance-constrained collision risk by utilizing linearized signed distance function (SDF), and then design a two-stage strategy for lightweight calculation of SDF in sequential convex programming. Building upon these treatments, we develop a real-time, non-myopic trajectory planner for visibility-aware and safe target tracking in the presence of system uncertainty. The effectiveness of the proposed approach is verified by both simulations and real-world experiments.
Learning List-Level Domain-Invariant Representations for Ranking
Dec 21, 2022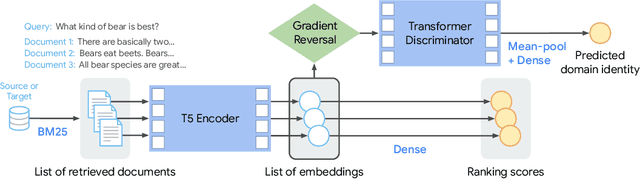
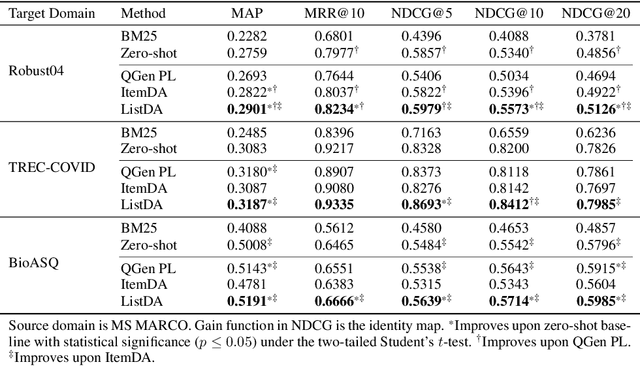
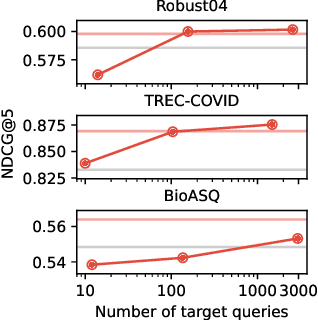
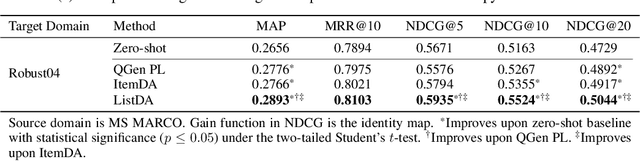
Domain adaptation aims to transfer the knowledge acquired by models trained on (data-rich) source domains to (low-resource) target domains, for which a popular method is invariant representation learning. While they have been studied extensively for classification and regression problems, how they apply to ranking problems, where the data and metrics have a list structure, is not well understood. Theoretically, we establish a domain adaptation generalization bound for ranking under listwise metrics such as MRR and NDCG. The bound suggests an adaptation method via learning list-level domain-invariant feature representations, whose benefits are empirically demonstrated by unsupervised domain adaptation experiments on real-world ranking tasks, including passage reranking. A key message is that for domain adaptation, the representations should be analyzed at the same level at which the metric is computed, as we show that learning invariant representations at the list level is most effective for adaptation on ranking problems.
HYRR: Hybrid Infused Reranking for Passage Retrieval
Dec 20, 2022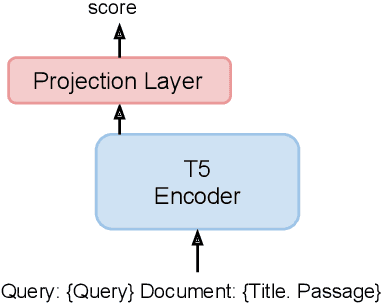
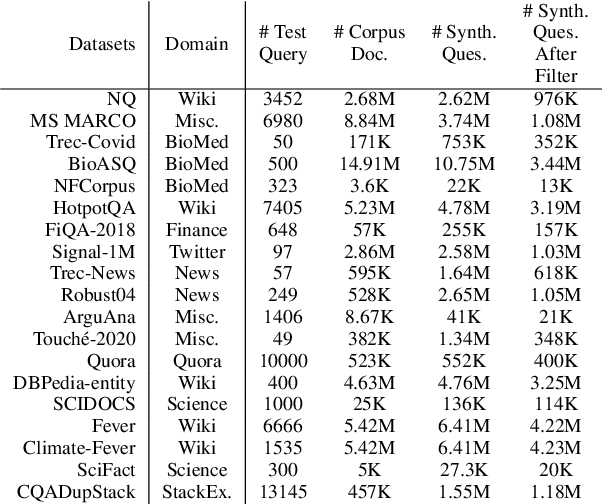
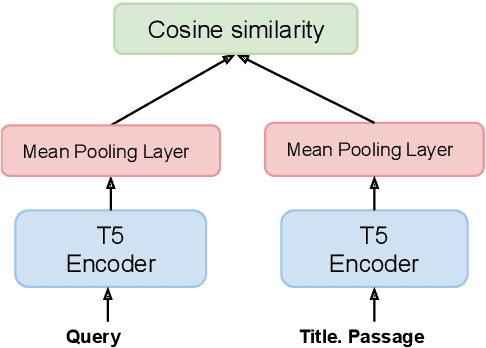
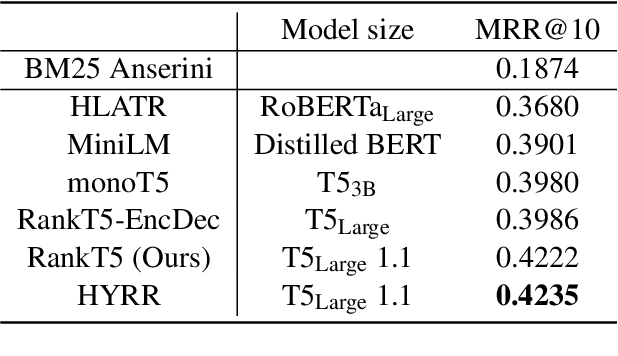
We present Hybrid Infused Reranking for Passages Retrieval (HYRR), a framework for training rerankers based on a hybrid of BM25 and neural retrieval models. Retrievers based on hybrid models have been shown to outperform both BM25 and neural models alone. Our approach exploits this improved performance when training a reranker, leading to a robust reranking model. The reranker, a cross-attention neural model, is shown to be robust to different first-stage retrieval systems, achieving better performance than rerankers simply trained upon the first-stage retrievers in the multi-stage systems. We present evaluations on a supervised passage retrieval task using MS MARCO and zero-shot retrieval tasks using BEIR. The empirical results show strong performance on both evaluations.
Attributed Question Answering: Evaluation and Modeling for Attributed Large Language Models
Dec 15, 2022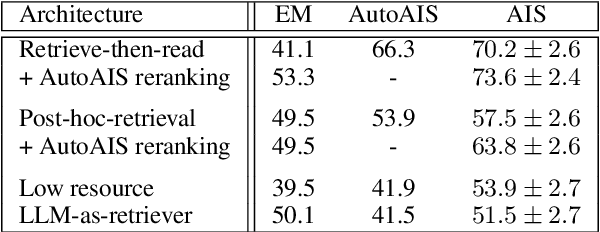

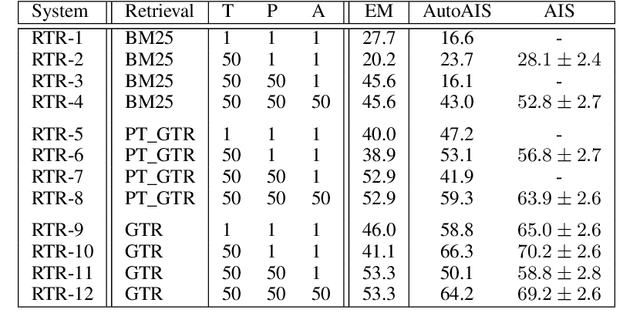
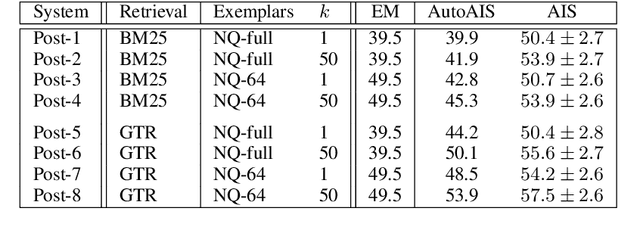
Large language models (LLMs) have shown impressive results across a variety of tasks while requiring little or no direct supervision. Further, there is mounting evidence that LLMs may have potential in information-seeking scenarios. We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in this setting. We propose and study Attributed QA as a key first step in the development of attributed LLMs. We develop a reproducable evaluation framework for the task, using human annotations as a gold standard and a correlated automatic metric that we show is suitable for development settings. We describe and benchmark a broad set of architectures for the task. Our contributions give some concrete answers to two key questions (How to measure attribution?, and How well do current state-of-the-art methods perform on attribution?), and give some hints as to how to address a third key question (How to build LLMs with attribution?).
QAmeleon: Multilingual QA with Only 5 Examples
Nov 15, 2022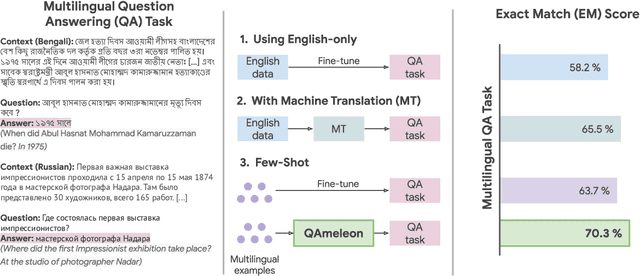
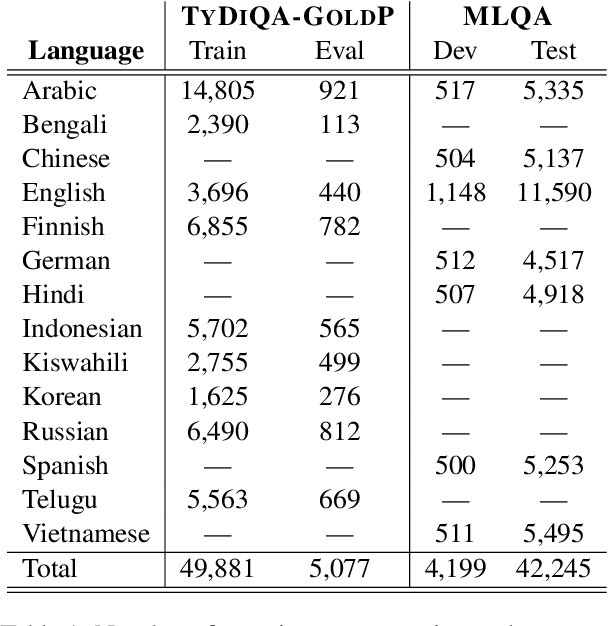
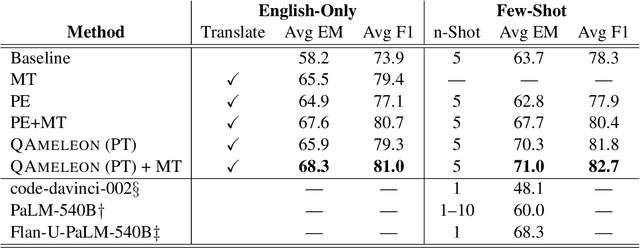
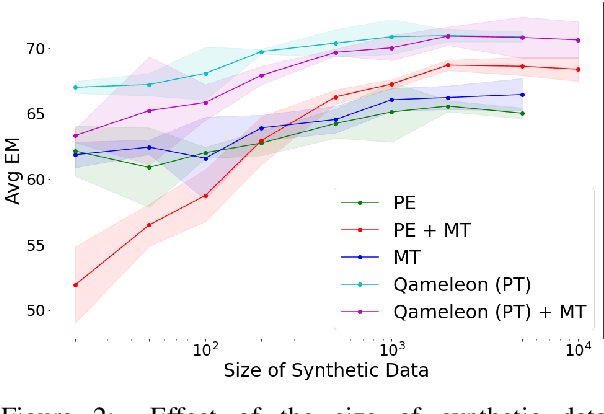
The availability of large, high-quality datasets has been one of the main drivers of recent progress in question answering (QA). Such annotated datasets however are difficult and costly to collect, and rarely exist in languages other than English, rendering QA technology inaccessible to underrepresented languages. An alternative to building large monolingual training datasets is to leverage pre-trained language models (PLMs) under a few-shot learning setting. Our approach, QAmeleon, uses a PLM to automatically generate multilingual data upon which QA models are trained, thus avoiding costly annotation. Prompt tuning the PLM for data synthesis with only five examples per language delivers accuracy superior to translation-based baselines, bridges nearly 60% of the gap between an English-only baseline and a fully supervised upper bound trained on almost 50,000 hand labeled examples, and always leads to substantial improvements compared to fine-tuning a QA model directly on labeled examples in low resource settings. Experiments on the TyDiQA-GoldP and MLQA benchmarks show that few-shot prompt tuning for data synthesis scales across languages and is a viable alternative to large-scale annotation.
RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
Oct 12, 2022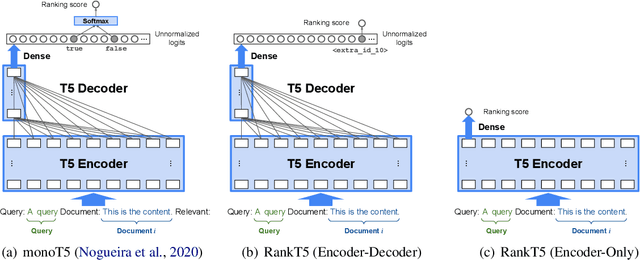

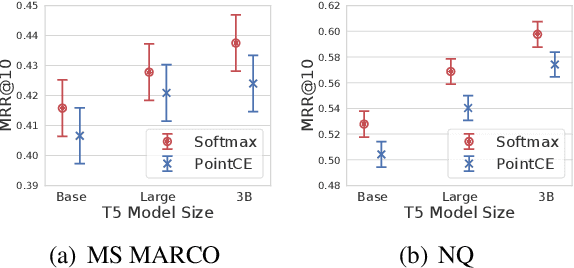
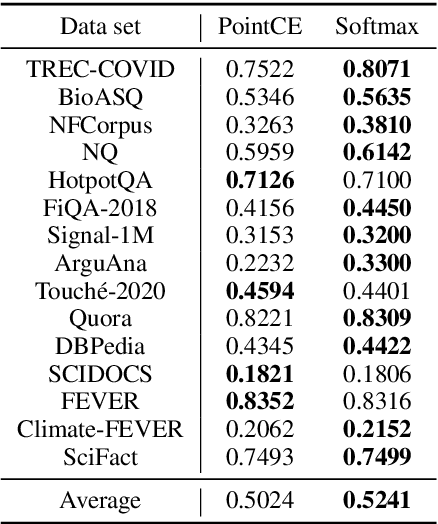
Recently, substantial progress has been made in text ranking based on pretrained language models such as BERT. However, there are limited studies on how to leverage more powerful sequence-to-sequence models such as T5. Existing attempts usually formulate text ranking as classification and rely on postprocessing to obtain a ranked list. In this paper, we propose RankT5 and study two T5-based ranking model structures, an encoder-decoder and an encoder-only one, so that they not only can directly output ranking scores for each query-document pair, but also can be fine-tuned with "pairwise" or "listwise" ranking losses to optimize ranking performances. Our experiments show that the proposed models with ranking losses can achieve substantial ranking performance gains on different public text ranking data sets. Moreover, when fine-tuned with listwise ranking losses, the ranking model appears to have better zero-shot ranking performance on out-of-domain data sets compared to the model fine-tuned with classification losses.