 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiang Xiao
DriveWorld: 4D Pre-trained Scene Understanding via World Models for Autonomous Driving
May 07, 2024
Vision-centric autonomous driving has recently raised wide attention due to its lower cost. Pre-training is essential for extracting a universal representation. However, current vision-centric pre-training typically relies on either 2D or 3D pre-text tasks, overlooking the temporal characteristics of autonomous driving as a 4D scene understanding task. In this paper, we address this challenge by introducing a world model-based autonomous driving 4D representation learning framework, dubbed \emph{DriveWorld}, which is capable of pre-training from multi-camera driving videos in a spatio-temporal fashion. Specifically, we propose a Memory State-Space Model for spatio-temporal modelling, which consists of a Dynamic Memory Bank module for learning temporal-aware latent dynamics to predict future changes and a Static Scene Propagation module for learning spatial-aware latent statics to offer comprehensive scene contexts. We additionally introduce a Task Prompt to decouple task-aware features for various downstream tasks. The experiments demonstrate that DriveWorld delivers promising results on various autonomous driving tasks. When pre-trained with the OpenScene dataset, DriveWorld achieves a 7.5% increase in mAP for 3D object detection, a 3.0% increase in IoU for online mapping, a 5.0% increase in AMOTA for multi-object tracking, a 0.1m decrease in minADE for motion forecasting, a 3.0% increase in IoU for occupancy prediction, and a 0.34m reduction in average L2 error for planning.
Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond
May 06, 2024General world models represent a crucial pathway toward achieving Artificial General Intelligence (AGI), serving as the cornerstone for various applications ranging from virtual environments to decision-making systems. Recently, the emergence of the Sora model has attained significant attention due to its remarkable simulation capabilities, which exhibits an incipient comprehension of physical laws. In this survey, we embark on a comprehensive exploration of the latest advancements in world models. Our analysis navigates through the forefront of generative methodologies in video generation, where world models stand as pivotal constructs facilitating the synthesis of highly realistic visual content. Additionally, we scrutinize the burgeoning field of autonomous-driving world models, meticulously delineating their indispensable role in reshaping transportation and urban mobility. Furthermore, we delve into the intricacies inherent in world models deployed within autonomous agents, shedding light on their profound significance in enabling intelligent interactions within dynamic environmental contexts. At last, we examine challenges and limitations of world models, and discuss their potential future directions. We hope this survey can serve as a foundational reference for the research community and inspire continued innovation. This survey will be regularly updated at: https://github.com/GigaAI-research/General-World-Models-Survey.
CoSD: Collaborative Stance Detection with Contrastive Heterogeneous Topic Graph Learning
Apr 26, 2024Stance detection seeks to identify the viewpoints of individuals either in favor or against a given target or a controversial topic. Current advanced neural models for stance detection typically employ fully parametric softmax classifiers. However, these methods suffer from several limitations, including lack of explainability, insensitivity to the latent data structure, and unimodality, which greatly restrict their performance and applications. To address these challenges, we present a novel collaborative stance detection framework called (CoSD) which leverages contrastive heterogeneous topic graph learning to learn topic-aware semantics and collaborative signals among texts, topics, and stance labels for enhancing stance detection. During training, we construct a heterogeneous graph to structurally organize texts and stances through implicit topics via employing latent Dirichlet allocation. We then perform contrastive graph learning to learn heterogeneous node representations, aggregating informative multi-hop collaborative signals via an elaborate Collaboration Propagation Aggregation (CPA) module. During inference, we introduce a hybrid similarity scoring module to enable the comprehensive incorporation of topic-aware semantics and collaborative signals for stance detection. Extensive experiments on two benchmark datasets demonstrate the state-of-the-art detection performance of CoSD, verifying the effectiveness and explainability of our collaborative framework.
ArgMed-Agents: Explainable Clinical Decision Reasoning with Large Language Models via Argumentation Schemes
Mar 10, 2024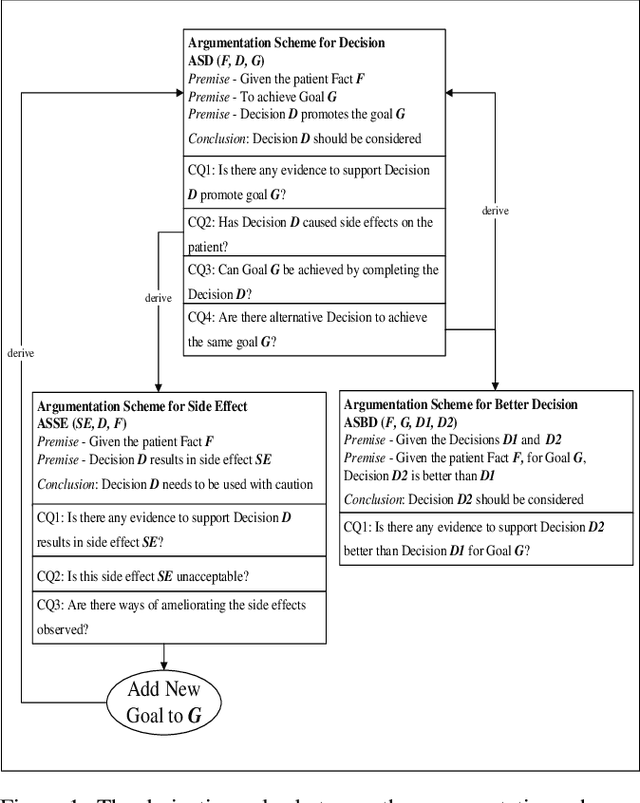
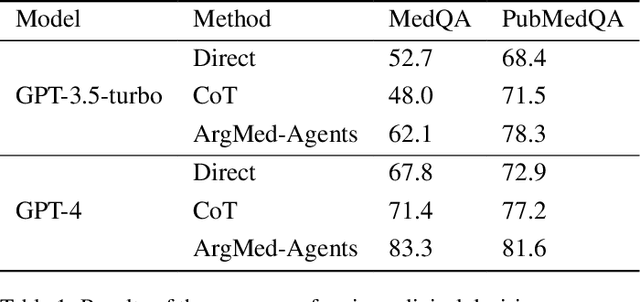

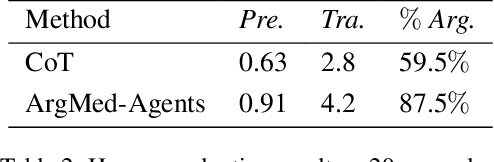
There are two main barriers to using large language models (LLMs) in clinical reasoning. Firstly, while LLMs exhibit significant promise in Natural Language Processing (NLP) tasks, their performance in complex reasoning and planning falls short of expectations. Secondly, LLMs use uninterpretable methods to make clinical decisions that are fundamentally different from the clinician's cognitive processes. This leads to user distrust. In this paper, we present a multi-agent framework called ArgMed-Agents, which aims to enable LLM-based agents to make explainable clinical decision reasoning through interaction. ArgMed-Agents performs self-argumentation iterations via Argumentation Scheme for Clinical Decision (a reasoning mechanism for modeling cognitive processes in clinical reasoning), and then constructs the argumentation process as a directed graph representing conflicting relationships. Ultimately, Reasoner(a symbolic solver) identify a series of rational and coherent arguments to support decision. ArgMed-Agents enables LLMs to mimic the process of clinical argumentative reasoning by generating explanations of reasoning in a self-directed manner. The setup experiments show that ArgMed-Agents not only improves accuracy in complex clinical decision reasoning problems compared to other prompt methods, but more importantly, it provides users with decision explanations that increase their confidence.
MSynFD: Multi-hop Syntax aware Fake News Detection
Feb 18, 2024The proliferation of social media platforms has fueled the rapid dissemination of fake news, posing threats to our real-life society. Existing methods use multimodal data or contextual information to enhance the detection of fake news by analyzing news content and/or its social context. However, these methods often overlook essential textual news content (articles) and heavily rely on sequential modeling and global attention to extract semantic information. These existing methods fail to handle the complex, subtle twists in news articles, such as syntax-semantics mismatches and prior biases, leading to lower performance and potential failure when modalities or social context are missing. To bridge these significant gaps, we propose a novel multi-hop syntax aware fake news detection (MSynFD) method, which incorporates complementary syntax information to deal with subtle twists in fake news. Specifically, we introduce a syntactical dependency graph and design a multi-hop subgraph aggregation mechanism to capture multi-hop syntax. It extends the effect of word perception, leading to effective noise filtering and adjacent relation enhancement. Subsequently, a sequential relative position-aware Transformer is designed to capture the sequential information, together with an elaborate keyword debiasing module to mitigate the prior bias. Extensive experimental results on two public benchmark datasets verify the effectiveness and superior performance of our proposed MSynFD over state-of-the-art detection models.
A Conditional Denoising Diffusion Probabilistic Model for Point Cloud Upsampling
Dec 03, 2023Point cloud upsampling (PCU) enriches the representation of raw point clouds, significantly improving the performance in downstream tasks such as classification and reconstruction. Most of the existing point cloud upsampling methods focus on sparse point cloud feature extraction and upsampling module design. In a different way, we dive deeper into directly modelling the gradient of data distribution from dense point clouds. In this paper, we proposed a conditional denoising diffusion probability model (DDPM) for point cloud upsampling, called PUDM. Specifically, PUDM treats the sparse point cloud as a condition, and iteratively learns the transformation relationship between the dense point cloud and the noise. Simultaneously, PUDM aligns with a dual mapping paradigm to further improve the discernment of point features. In this context, PUDM enables learning complex geometry details in the ground truth through the dominant features, while avoiding an additional upsampling module design. Furthermore, to generate high-quality arbitrary-scale point clouds during inference, PUDM exploits the prior knowledge of the scale between sparse point clouds and dense point clouds during training by parameterizing a rate factor. Moreover, PUDM exhibits strong noise robustness in experimental results. In the quantitative and qualitative evaluations on PU1K and PUGAN, PUDM significantly outperformed existing methods in terms of Chamfer Distance (CD) and Hausdorff Distance (HD), achieving state of the art (SOTA) performance.
Adversarial Purification of Information Masking
Nov 26, 2023Adversarial attacks meticulously generate minuscule, imperceptible perturbations to images to deceive neural networks. Counteracting these, adversarial purification methods seek to transform adversarial input samples into clean output images to defend against adversarial attacks. Nonetheless, extent generative models fail to effectively eliminate adversarial perturbations, yielding less-than-ideal purification results. We emphasize the potential threat of residual adversarial perturbations to target models, quantitatively establishing a relationship between perturbation scale and attack capability. Notably, the residual perturbations on the purified image primarily stem from the same-position patch and similar patches of the adversarial sample. We propose a novel adversarial purification approach named Information Mask Purification (IMPure), aims to extensively eliminate adversarial perturbations. To obtain an adversarial sample, we first mask part of the patches information, then reconstruct the patches to resist adversarial perturbations from the patches. We reconstruct all patches in parallel to obtain a cohesive image. Then, in order to protect the purified samples against potential similar regional perturbations, we simulate this risk by randomly mixing the purified samples with the input samples before inputting them into the feature extraction network. Finally, we establish a combined constraint of pixel loss and perceptual loss to augment the model's reconstruction adaptability. Extensive experiments on the ImageNet dataset with three classifier models demonstrate that our approach achieves state-of-the-art results against nine adversarial attack methods. Implementation code and pre-trained weights can be accessed at \textcolor{blue}{https://github.com/NoWindButRain/IMPure}.
A Spectral Diffusion Prior for Hyperspectral Image Super-Resolution
Nov 15, 2023Fusion-based hyperspectral image (HSI) super-resolution aims to produce a high-spatial-resolution HSI by fusing a low-spatial-resolution HSI and a high-spatial-resolution multispectral image. Such a HSI super-resolution process can be modeled as an inverse problem, where the prior knowledge is essential for obtaining the desired solution. Motivated by the success of diffusion models, we propose a novel spectral diffusion prior for fusion-based HSI super-resolution. Specifically, we first investigate the spectrum generation problem and design a spectral diffusion model to model the spectral data distribution. Then, in the framework of maximum a posteriori, we keep the transition information between every two neighboring states during the reverse generative process, and thereby embed the knowledge of trained spectral diffusion model into the fusion problem in the form of a regularization term. At last, we treat each generation step of the final optimization problem as its subproblem, and employ the Adam to solve these subproblems in a reverse sequence. Experimental results conducted on both synthetic and real datasets demonstrate the effectiveness of the proposed approach. The code of the proposed approach will be available on https://github.com/liuofficial/SDP.
UniWorld: Autonomous Driving Pre-training via World Models
Aug 14, 2023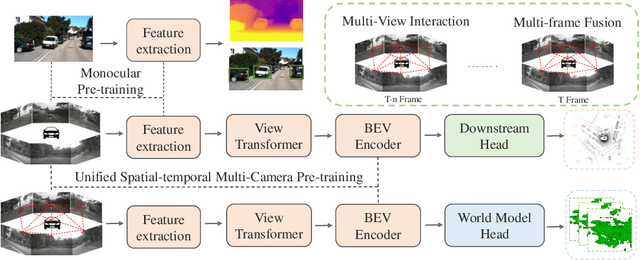

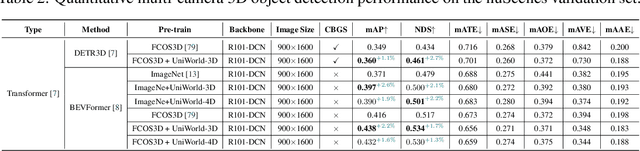
In this paper, we draw inspiration from Alberto Elfes' pioneering work in 1989, where he introduced the concept of the occupancy grid as World Models for robots. We imbue the robot with a spatial-temporal world model, termed UniWorld, to perceive its surroundings and predict the future behavior of other participants. UniWorld involves initially predicting 4D geometric occupancy as the World Models for foundational stage and subsequently fine-tuning on downstream tasks. UniWorld can estimate missing information concerning the world state and predict plausible future states of the world. Besides, UniWorld's pre-training process is label-free, enabling the utilization of massive amounts of image-LiDAR pairs to build a Foundational Model.The proposed unified pre-training framework demonstrates promising results in key tasks such as motion prediction, multi-camera 3D object detection, and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, UniWorld shows a significant improvement of about 1.5% in IoU for motion prediction, 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. By adopting our unified pre-training method, a 25% reduction in 3D training annotation costs can be achieved, offering significant practical value for the implementation of real-world autonomous driving. Codes are publicly available at https://github.com/chaytonmin/UniWorld.
Contrastive Label Disambiguation for Self-Supervised Terrain Traversability Learning in Off-Road Environments
Jul 06, 2023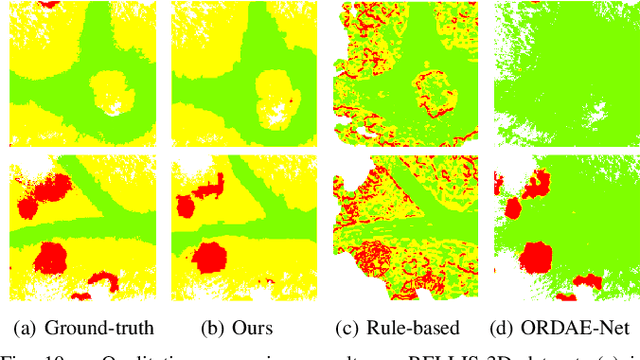

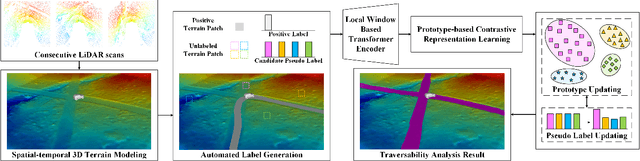
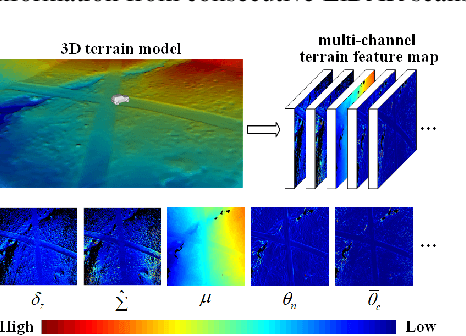
Discriminating the traversability of terrains is a crucial task for autonomous driving in off-road environments. However, it is challenging due to the diverse, ambiguous, and platform-specific nature of off-road traversability. In this paper, we propose a novel self-supervised terrain traversability learning framework, utilizing a contrastive label disambiguation mechanism. Firstly, weakly labeled training samples with pseudo labels are automatically generated by projecting actual driving experiences onto the terrain models constructed in real time. Subsequently, a prototype-based contrastive representation learning method is designed to learn distinguishable embeddings, facilitating the self-supervised updating of those pseudo labels. As the iterative interaction between representation learning and pseudo label updating, the ambiguities in those pseudo labels are gradually eliminated, enabling the learning of platform-specific and task-specific traversability without any human-provided annotations. Experimental results on the RELLIS-3D dataset and our Gobi Desert driving dataset demonstrate the effectiveness of the proposed method.