 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoshui Huang
3DBench: A Scalable 3D Benchmark and Instruction-Tuning Dataset
Apr 23, 2024
Evaluating the performance of Multi-modal Large Language Models (MLLMs), integrating both point cloud and language, presents significant challenges. The lack of a comprehensive assessment hampers determining whether these models truly represent advancements, thereby impeding further progress in the field. Current evaluations heavily rely on classification and caption tasks, falling short in providing a thorough assessment of MLLMs. A pressing need exists for a more sophisticated evaluation method capable of thoroughly analyzing the spatial understanding and expressive capabilities of these models. To address these issues, we introduce a scalable 3D benchmark, accompanied by a large-scale instruction-tuning dataset known as 3DBench, providing an extensible platform for a comprehensive evaluation of MLLMs. Specifically, we establish the benchmark that spans a wide range of spatial and semantic scales, from object-level to scene-level, addressing both perception and planning tasks. Furthermore, we present a rigorous pipeline for automatically constructing scalable 3D instruction-tuning datasets, covering 10 diverse multi-modal tasks with more than 0.23 million QA pairs generated in total. Thorough experiments evaluating trending MLLMs, comparisons against existing datasets, and variations of training protocols demonstrate the superiority of 3DBench, offering valuable insights into current limitations and potential research directions.
Taming Stable Diffusion for Text to 360° Panorama Image Generation
Apr 11, 2024Generative models, e.g., Stable Diffusion, have enabled the creation of photorealistic images from text prompts. Yet, the generation of 360-degree panorama images from text remains a challenge, particularly due to the dearth of paired text-panorama data and the domain gap between panorama and perspective images. In this paper, we introduce a novel dual-branch diffusion model named PanFusion to generate a 360-degree image from a text prompt. We leverage the stable diffusion model as one branch to provide prior knowledge in natural image generation and register it to another panorama branch for holistic image generation. We propose a unique cross-attention mechanism with projection awareness to minimize distortion during the collaborative denoising process. Our experiments validate that PanFusion surpasses existing methods and, thanks to its dual-branch structure, can integrate additional constraints like room layout for customized panorama outputs. Code is available at https://chengzhag.github.io/publication/panfusion.
GVGEN: Text-to-3D Generation with Volumetric Representation
Mar 19, 2024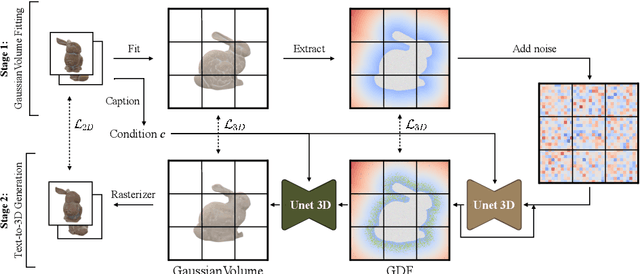
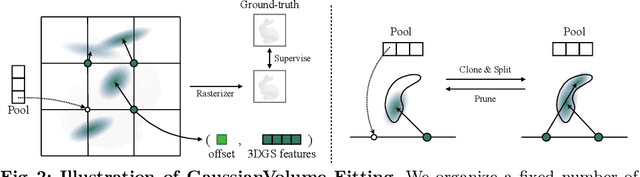


In recent years, 3D Gaussian splatting has emerged as a powerful technique for 3D reconstruction and generation, known for its fast and high-quality rendering capabilities. To address these shortcomings, this paper introduces a novel diffusion-based framework, GVGEN, designed to efficiently generate 3D Gaussian representations from text input. We propose two innovative techniques:(1) Structured Volumetric Representation. We first arrange disorganized 3D Gaussian points as a structured form GaussianVolume. This transformation allows the capture of intricate texture details within a volume composed of a fixed number of Gaussians. To better optimize the representation of these details, we propose a unique pruning and densifying method named the Candidate Pool Strategy, enhancing detail fidelity through selective optimization. (2) Coarse-to-fine Generation Pipeline. To simplify the generation of GaussianVolume and empower the model to generate instances with detailed 3D geometry, we propose a coarse-to-fine pipeline. It initially constructs a basic geometric structure, followed by the prediction of complete Gaussian attributes. Our framework, GVGEN, demonstrates superior performance in qualitative and quantitative assessments compared to existing 3D generation methods. Simultaneously, it maintains a fast generation speed ($\sim$7 seconds), effectively striking a balance between quality and efficiency.
THOR: Text to Human-Object Interaction Diffusion via Relation Intervention
Mar 17, 2024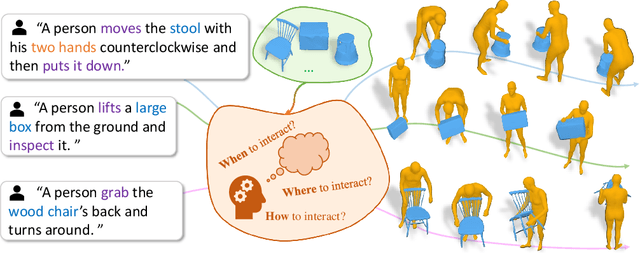
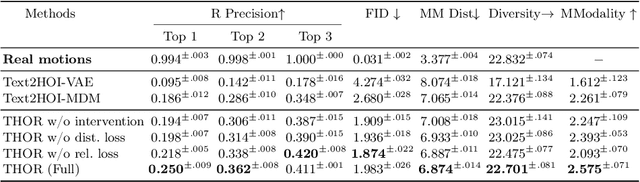
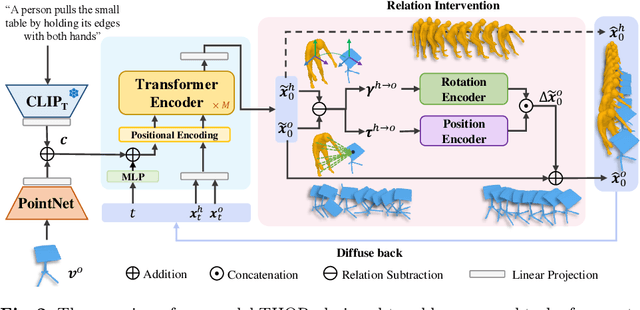

This paper addresses new methodologies to deal with the challenging task of generating dynamic Human-Object Interactions from textual descriptions (Text2HOI). While most existing works assume interactions with limited body parts or static objects, our task involves addressing the variation in human motion, the diversity of object shapes, and the semantic vagueness of object motion simultaneously. To tackle this, we propose a novel Text-guided Human-Object Interaction diffusion model with Relation Intervention (THOR). THOR is a cohesive diffusion model equipped with a relation intervention mechanism. In each diffusion step, we initiate text-guided human and object motion and then leverage human-object relations to intervene in object motion. This intervention enhances the spatial-temporal relations between humans and objects, with human-centric interaction representation providing additional guidance for synthesizing consistent motion from text. To achieve more reasonable and realistic results, interaction losses is introduced at different levels of motion granularity. Moreover, we construct Text-BEHAVE, a Text2HOI dataset that seamlessly integrates textual descriptions with the currently largest publicly available 3D HOI dataset. Both quantitative and qualitative experiments demonstrate the effectiveness of our proposed model.
NeRF-Det++: Incorporating Semantic Cues and Perspective-aware Depth Supervision for Indoor Multi-View 3D Detection
Feb 22, 2024NeRF-Det has achieved impressive performance in indoor multi-view 3D detection by innovatively utilizing NeRF to enhance representation learning. Despite its notable performance, we uncover three decisive shortcomings in its current design, including semantic ambiguity, inappropriate sampling, and insufficient utilization of depth supervision. To combat the aforementioned problems, we present three corresponding solutions: 1) Semantic Enhancement. We project the freely available 3D segmentation annotations onto the 2D plane and leverage the corresponding 2D semantic maps as the supervision signal, significantly enhancing the semantic awareness of multi-view detectors. 2) Perspective-aware Sampling. Instead of employing the uniform sampling strategy, we put forward the perspective-aware sampling policy that samples densely near the camera while sparsely in the distance, more effectively collecting the valuable geometric clues. 3)Ordinal Residual Depth Supervision. As opposed to directly regressing the depth values that are difficult to optimize, we divide the depth range of each scene into a fixed number of ordinal bins and reformulate the depth prediction as the combination of the classification of depth bins as well as the regression of the residual depth values, thereby benefiting the depth learning process. The resulting algorithm, NeRF-Det++, has exhibited appealing performance in the ScanNetV2 and ARKITScenes datasets. Notably, in ScanNetV2, NeRF-Det++ outperforms the competitive NeRF-Det by +1.9% in mAP@0.25 and +3.5% in mAP@0.50$. The code will be publicly at https://github.com/mrsempress/NeRF-Detplusplus.
A Comprehensive Survey on 3D Content Generation
Feb 02, 2024Recent years have witnessed remarkable advances in artificial intelligence generated content(AIGC), with diverse input modalities, e.g., text, image, video, audio and 3D. The 3D is the most close visual modality to real-world 3D environment and carries enormous knowledge. The 3D content generation shows both academic and practical values while also presenting formidable technical challenges. This review aims to consolidate developments within the burgeoning domain of 3D content generation. Specifically, a new taxonomy is proposed that categorizes existing approaches into three types: 3D native generative methods, 2D prior-based 3D generative methods, and hybrid 3D generative methods. The survey covers approximately 60 papers spanning the major techniques. Besides, we discuss limitations of current 3D content generation techniques, and point out open challenges as well as promising directions for future work. Accompanied with this survey, we have established a project website where the resources on 3D content generation research are provided. The project page is available at https://github.com/hitcslj/Awesome-AIGC-3D.
3DAxiesPrompts: Unleashing the 3D Spatial Task Capabilities of GPT-4V
Dec 15, 2023
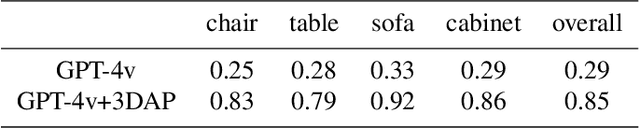
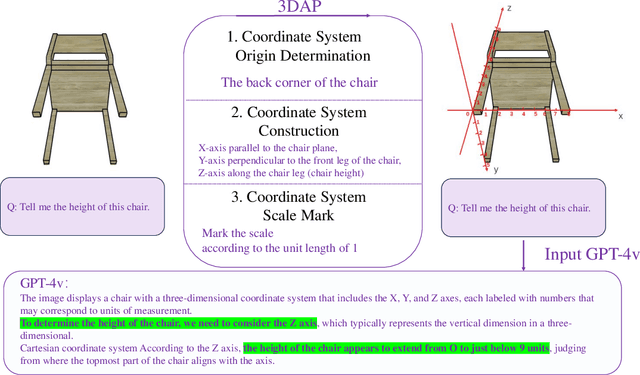

In this work, we present a new visual prompting method called 3DAxiesPrompts (3DAP) to unleash the capabilities of GPT-4V in performing 3D spatial tasks. Our investigation reveals that while GPT-4V exhibits proficiency in discerning the position and interrelations of 2D entities through current visual prompting techniques, its abilities in handling 3D spatial tasks have yet to be explored. In our approach, we create a 3D coordinate system tailored to 3D imagery, complete with annotated scale information. By presenting images infused with the 3DAP visual prompt as inputs, we empower GPT-4V to ascertain the spatial positioning information of the given 3D target image with a high degree of precision. Through experiments, We identified three tasks that could be stably completed using the 3DAP method, namely, 2D to 3D Point Reconstruction, 2D to 3D point matching, and 3D Object Detection. We perform experiments on our proposed dataset 3DAP-Data, the results from these experiments validate the efficacy of 3DAP-enhanced GPT-4V inputs, marking a significant stride in 3D spatial task execution.
UniDream: Unifying Diffusion Priors for Relightable Text-to-3D Generation
Dec 14, 2023Recent advancements in text-to-3D generation technology have significantly advanced the conversion of textual descriptions into imaginative well-geometrical and finely textured 3D objects. Despite these developments, a prevalent limitation arises from the use of RGB data in diffusion or reconstruction models, which often results in models with inherent lighting and shadows effects that detract from their realism, thereby limiting their usability in applications that demand accurate relighting capabilities. To bridge this gap, we present UniDream, a text-to-3D generation framework by incorporating unified diffusion priors. Our approach consists of three main components: (1) a dual-phase training process to get albedo-normal aligned multi-view diffusion and reconstruction models, (2) a progressive generation procedure for geometry and albedo-textures based on Score Distillation Sample (SDS) using the trained reconstruction and diffusion models, and (3) an innovative application of SDS for finalizing PBR generation while keeping a fixed albedo based on Stable Diffusion model. Extensive evaluations demonstrate that UniDream surpasses existing methods in generating 3D objects with clearer albedo textures, smoother surfaces, enhanced realism, and superior relighting capabilities.
PCRDiffusion: Diffusion Probabilistic Models for Point Cloud Registration
Dec 11, 2023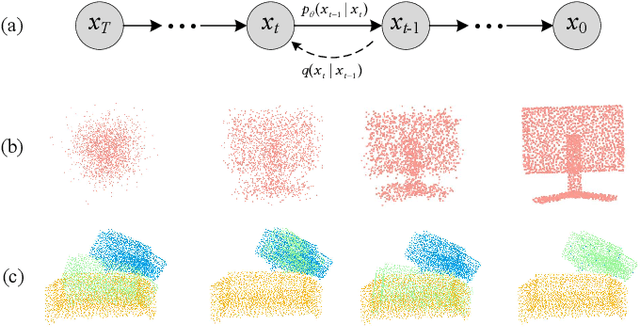
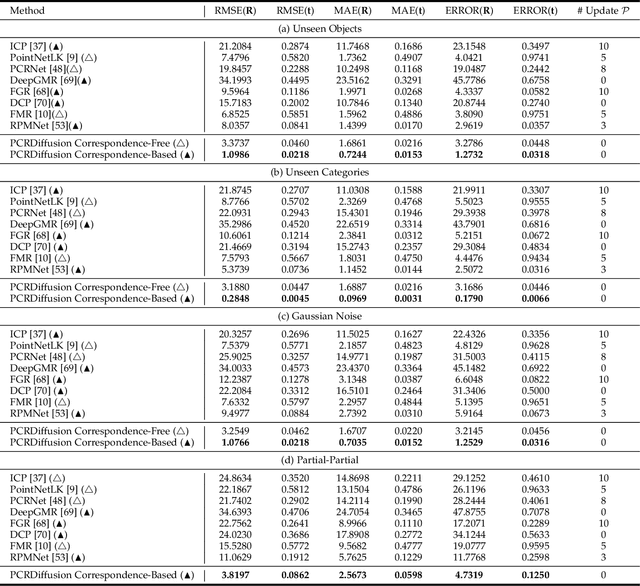
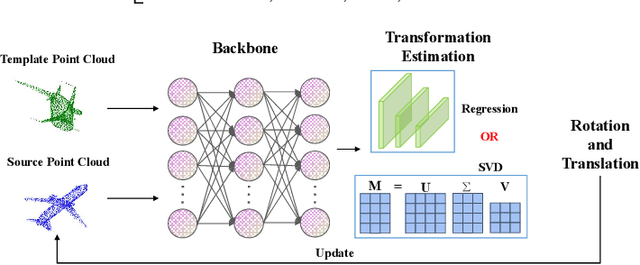
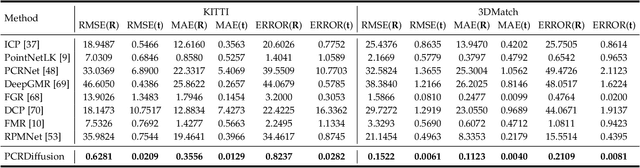
We propose a new framework that formulates point cloud registration as a denoising diffusion process from noisy transformation to object transformation. During training stage, object transformation diffuses from ground-truth transformation to random distribution, and the model learns to reverse this noising process. In sampling stage, the model refines randomly generated transformation to the output result in a progressive way. We derive the variational bound in closed form for training and provide implementations of the model. Our work provides the following crucial findings: (i) In contrast to most existing methods, our framework, Diffusion Probabilistic Models for Point Cloud Registration (PCRDiffusion) does not require repeatedly update source point cloud to refine the predicted transformation. (ii) Point cloud registration, one of the representative discriminative tasks, can be solved by a generative way and the unified probabilistic formulation. Finally, we discuss and provide an outlook on the application of diffusion model in different scenarios for point cloud registration. Experimental results demonstrate that our model achieves competitive performance in point cloud registration. In correspondence-free and correspondence-based scenarios, PCRDifussion can both achieve exceeding 50\% performance improvements.
Zero-Shot Point Cloud Registration
Dec 08, 2023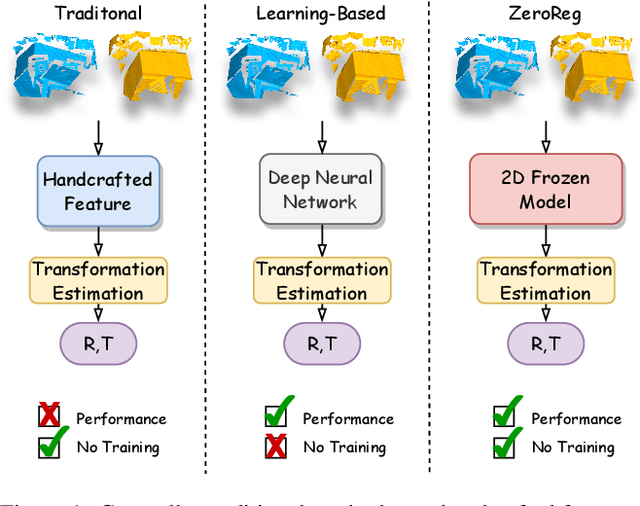
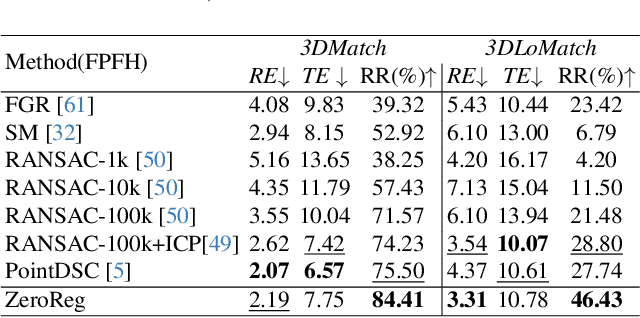
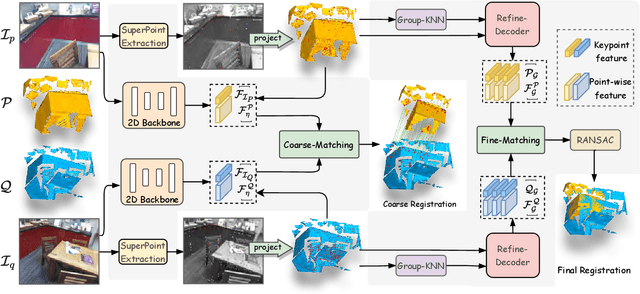
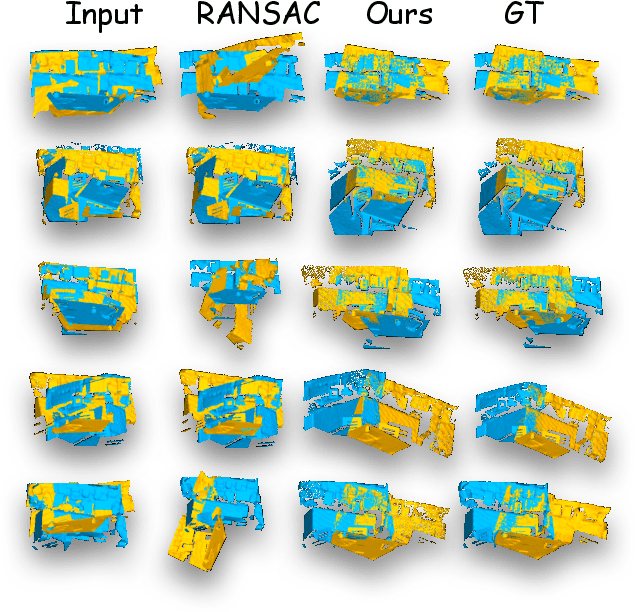
Learning-based point cloud registration approaches have significantly outperformed their traditional counterparts. However, they typically require extensive training on specific datasets. In this paper, we propose , the first zero-shot point cloud registration approach that eliminates the need for training on point cloud datasets. The cornerstone of ZeroReg is the novel transfer of image features from keypoints to the point cloud, enriched by aggregating information from 3D geometric neighborhoods. Specifically, we extract keypoints and features from 2D image pairs using a frozen pretrained 2D backbone. These features are then projected in 3D, and patches are constructed by searching for neighboring points. We integrate the geometric and visual features of each point using our novel parameter-free geometric decoder. Subsequently, the task of determining correspondences between point clouds is formulated as an optimal transport problem. Extensive evaluations of ZeroReg demonstrate its competitive performance against both traditional and learning-based methods. On benchmarks such as 3DMatch, 3DLoMatch, and ScanNet, ZeroReg achieves impressive Recall Ratios (RR) of over 84%, 46%, and 75%, respectively.