 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaoguo Gong
Enhancing Hyperspectral Images via Diffusion Model and Group-Autoencoder Super-resolution Network
Feb 27, 2024
Existing hyperspectral image (HSI) super-resolution (SR) methods struggle to effectively capture the complex spectral-spatial relationships and low-level details, while diffusion models represent a promising generative model known for their exceptional performance in modeling complex relations and learning high and low-level visual features. The direct application of diffusion models to HSI SR is hampered by challenges such as difficulties in model convergence and protracted inference time. In this work, we introduce a novel Group-Autoencoder (GAE) framework that synergistically combines with the diffusion model to construct a highly effective HSI SR model (DMGASR). Our proposed GAE framework encodes high-dimensional HSI data into low-dimensional latent space where the diffusion model works, thereby alleviating the difficulty of training the diffusion model while maintaining band correlation and considerably reducing inference time. Experimental results on both natural and remote sensing hyperspectral datasets demonstrate that the proposed method is superior to other state-of-the-art methods both visually and metrically.
Diffusion Model Based Visual Compensation Guidance and Visual Difference Analysis for No-Reference Image Quality Assessment
Feb 22, 2024Existing free-energy guided No-Reference Image Quality Assessment (NR-IQA) methods still suffer from finding a balance between learning feature information at the pixel level of the image and capturing high-level feature information and the efficient utilization of the obtained high-level feature information remains a challenge. As a novel class of state-of-the-art (SOTA) generative model, the diffusion model exhibits the capability to model intricate relationships, enabling a comprehensive understanding of images and possessing a better learning of both high-level and low-level visual features. In view of these, we pioneer the exploration of the diffusion model into the domain of NR-IQA. Firstly, we devise a new diffusion restoration network that leverages the produced enhanced image and noise-containing images, incorporating nonlinear features obtained during the denoising process of the diffusion model, as high-level visual information. Secondly, two visual evaluation branches are designed to comprehensively analyze the obtained high-level feature information. These include the visual compensation guidance branch, grounded in the transformer architecture and noise embedding strategy, and the visual difference analysis branch, built on the ResNet architecture and the residual transposed attention block. Extensive experiments are conducted on seven public NR-IQA datasets, and the results demonstrate that the proposed model outperforms SOTA methods for NR-IQA.
Neural Gaussian Similarity Modeling for Differential Graph Structure Learning
Dec 15, 2023Graph Structure Learning (GSL) has demonstrated considerable potential in the analysis of graph-unknown non-Euclidean data across a wide range of domains. However, constructing an end-to-end graph structure learning model poses a challenge due to the impediment of gradient flow caused by the nearest neighbor sampling strategy. In this paper, we construct a differential graph structure learning model by replacing the non-differentiable nearest neighbor sampling with a differentiable sampling using the reparameterization trick. Under this framework, we argue that the act of sampling \mbox{nearest} neighbors may not invariably be essential, particularly in instances where node features exhibit a significant degree of similarity. To alleviate this issue, the bell-shaped Gaussian Similarity (GauSim) modeling is proposed to sample non-nearest neighbors. To adaptively model the similarity, we further propose Neural Gaussian Similarity (NeuralGauSim) with learnable parameters featuring flexible sampling behaviors. In addition, we develop a scalable method by transferring the large-scale graph to the transition graph to significantly reduce the complexity. Experimental results demonstrate the effectiveness of the proposed methods.
M3SOT: Multi-frame, Multi-field, Multi-space 3D Single Object Tracking
Dec 11, 20233D Single Object Tracking (SOT) stands a forefront task of computer vision, proving essential for applications like autonomous driving. Sparse and occluded data in scene point clouds introduce variations in the appearance of tracked objects, adding complexity to the task. In this research, we unveil M3SOT, a novel 3D SOT framework, which synergizes multiple input frames (template sets), multiple receptive fields (continuous contexts), and multiple solution spaces (distinct tasks) in ONE model. Remarkably, M3SOT pioneers in modeling temporality, contexts, and tasks directly from point clouds, revisiting a perspective on the key factors influencing SOT. To this end, we design a transformer-based network centered on point cloud targets in the search area, aggregating diverse contextual representations and propagating target cues by employing historical frames. As M3SOT spans varied processing perspectives, we've streamlined the network-trimming its depth and optimizing its structure-to ensure a lightweight and efficient deployment for SOT applications. We posit that, backed by practical construction, M3SOT sidesteps the need for complex frameworks and auxiliary components to deliver sterling results. Extensive experiments on benchmarks such as KITTI, nuScenes, and Waymo Open Dataset demonstrate that M3SOT achieves state-of-the-art performance at 38 FPS. Our code and models are available at https://github.com/ywu0912/TeamCode.git.
* 12 pages, 10 figures, 10 tables, AAAI 2024
PCRDiffusion: Diffusion Probabilistic Models for Point Cloud Registration
Dec 11, 2023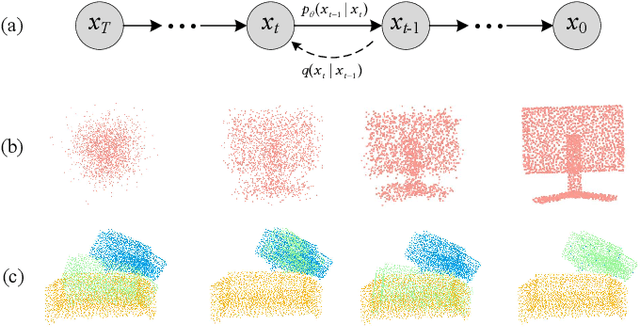
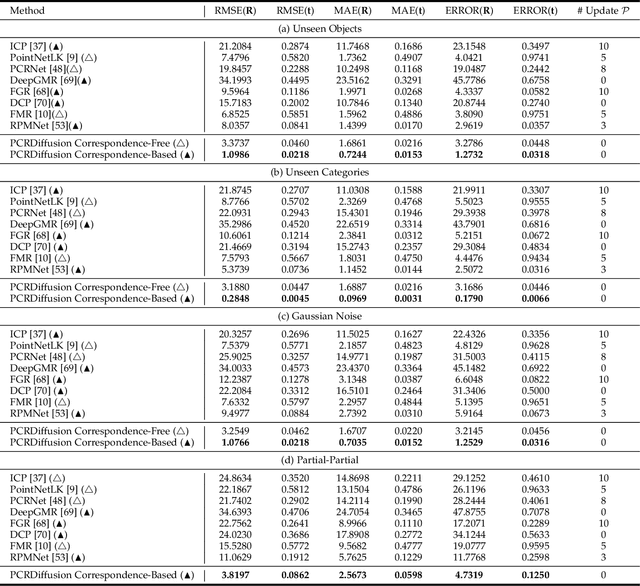
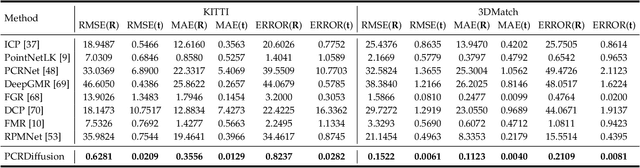
We propose a new framework that formulates point cloud registration as a denoising diffusion process from noisy transformation to object transformation. During training stage, object transformation diffuses from ground-truth transformation to random distribution, and the model learns to reverse this noising process. In sampling stage, the model refines randomly generated transformation to the output result in a progressive way. We derive the variational bound in closed form for training and provide implementations of the model. Our work provides the following crucial findings: (i) In contrast to most existing methods, our framework, Diffusion Probabilistic Models for Point Cloud Registration (PCRDiffusion) does not require repeatedly update source point cloud to refine the predicted transformation. (ii) Point cloud registration, one of the representative discriminative tasks, can be solved by a generative way and the unified probabilistic formulation. Finally, we discuss and provide an outlook on the application of diffusion model in different scenarios for point cloud registration. Experimental results demonstrate that our model achieves competitive performance in point cloud registration. In correspondence-free and correspondence-based scenarios, PCRDifussion can both achieve exceeding 50\% performance improvements.
One-Nearest Neighborhood Guides Inlier Estimation for Unsupervised Point Cloud Registration
Jul 26, 2023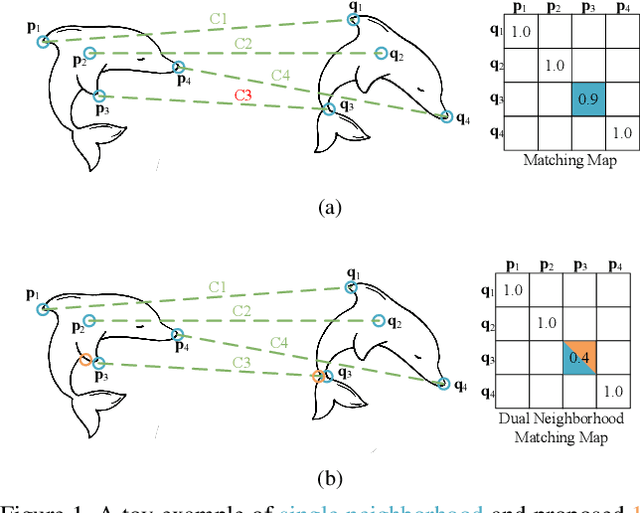

The precision of unsupervised point cloud registration methods is typically limited by the lack of reliable inlier estimation and self-supervised signal, especially in partially overlapping scenarios. In this paper, we propose an effective inlier estimation method for unsupervised point cloud registration by capturing geometric structure consistency between the source point cloud and its corresponding reference point cloud copy. Specifically, to obtain a high quality reference point cloud copy, an One-Nearest Neighborhood (1-NN) point cloud is generated by input point cloud. This facilitates matching map construction and allows for integrating dual neighborhood matching scores of 1-NN point cloud and input point cloud to improve matching confidence. Benefiting from the high quality reference copy, we argue that the neighborhood graph formed by inlier and its neighborhood should have consistency between source point cloud and its corresponding reference copy. Based on this observation, we construct transformation-invariant geometric structure representations and capture geometric structure consistency to score the inlier confidence for estimated correspondences between source point cloud and its reference copy. This strategy can simultaneously provide the reliable self-supervised signal for model optimization. Finally, we further calculate transformation estimation by the weighted SVD algorithm with the estimated correspondences and corresponding inlier confidence. We train the proposed model in an unsupervised manner, and extensive experiments on synthetic and real-world datasets illustrate the effectiveness of the proposed method.
Evolutionary Multitasking with Solution Space Cutting for Point Cloud Registration
Dec 12, 2022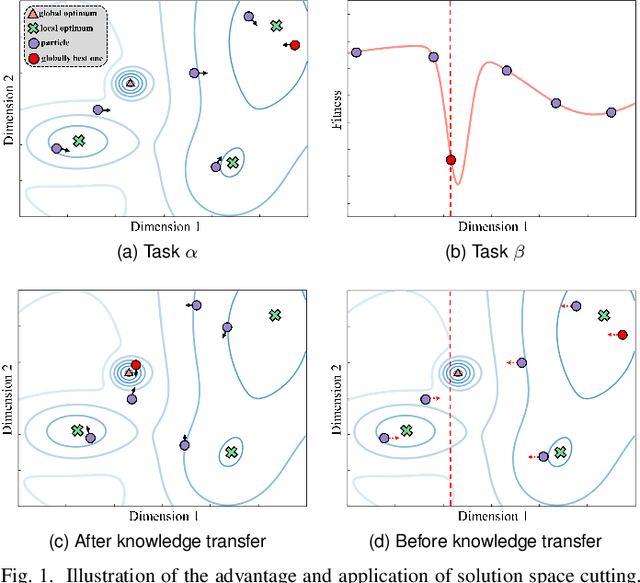
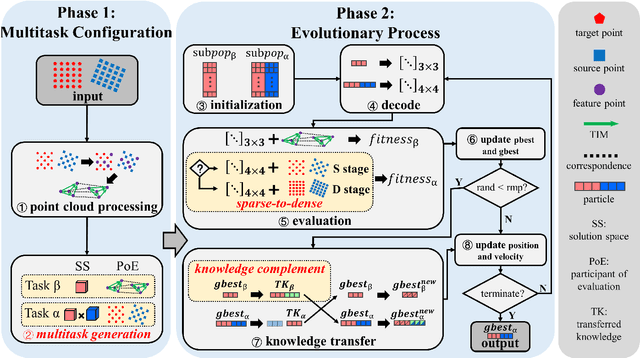
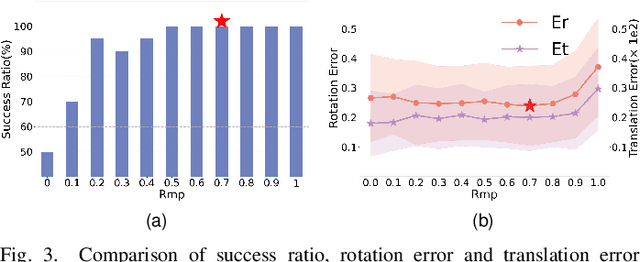
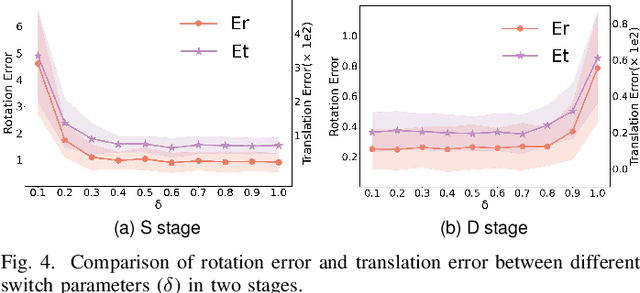
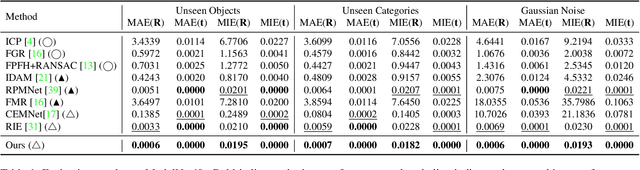
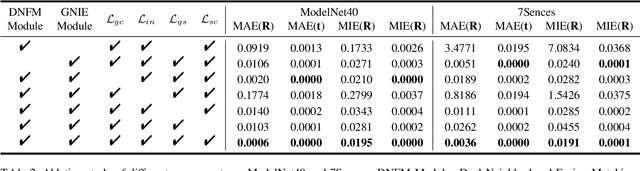
Point cloud registration (PCR) is a popular research topic in computer vision. Recently, the registration method in an evolutionary way has received continuous attention because of its robustness to the initial pose and flexibility in objective function design. However, most evolving registration methods cannot tackle the local optimum well and they have rarely investigated the success ratio, which implies the probability of not falling into local optima and is closely related to the practicality of the algorithm. Evolutionary multi-task optimization (EMTO) is a widely used paradigm, which can boost exploration capability through knowledge transfer among related tasks. Inspired by this concept, this study proposes a novel evolving registration algorithm via EMTO, where the multi-task configuration is based on the idea of solution space cutting. Concretely, one task searching in cut space assists another task with complex function landscape in escaping from local optima and enhancing successful registration ratio. To reduce unnecessary computational cost, a sparse-to-dense strategy is proposed. In addition, a novel fitness function robust to various overlap rates as well as a problem-specific metric of computational cost is introduced. Compared with 7 evolving registration approaches and 4 traditional registration approaches on the object-scale and scene-scale registration datasets, experimental results demonstrate that the proposed method has superior performances in terms of precision and tackling local optima.
Bayesian Layer Graph Convolutioanl Network for Hyperspetral Image Classification
Nov 14, 2022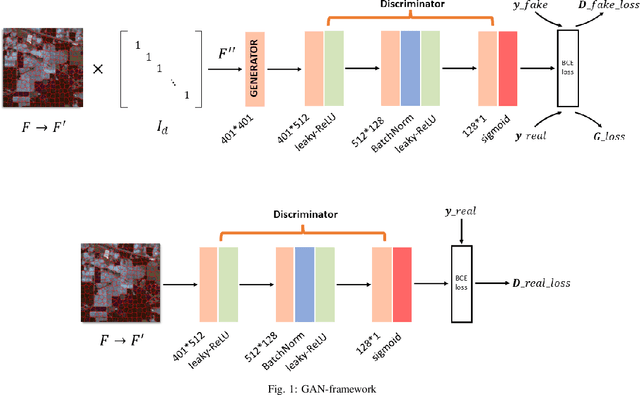
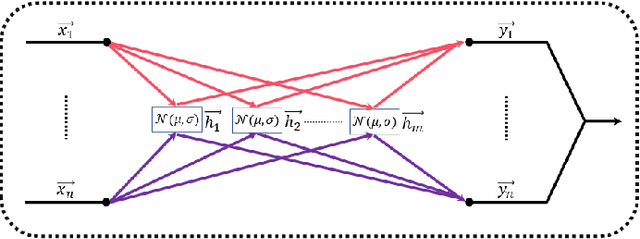
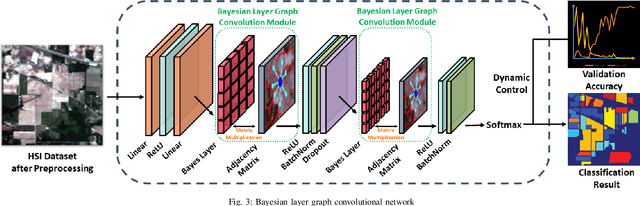

In recent years, research on hyperspectral image (HSI) classification has continuous progress on introducing deep network models, and recently the graph convolutional network (GCN) based models have shown impressive performance. However, these deep learning frameworks based on point estimation suffer from low generalization and inability to quantify the classification results uncertainty. On the other hand, simply applying the Bayesian Neural Network (BNN) based on distribution estimation to classify the HSI is unable to achieve high classification accuracy due to the large amount of parameters. In this paper, we design a Bayesian layer with Bayesian idea as an insertion layer into point estimation based neural networks, and propose a Bayesian Layer Graph Convolutional Network (BLGCN) model by combining graph convolution operations, which can effectively extract graph information and estimate the uncertainty of classification results. Moreover, a Generative Adversarial Network (GAN) is built to solve the sample imbalance problem of HSI dataset. Finally, we design a dynamic control training strategy based on the confidence interval of the classification results, which will terminate the training early when the confidence interval reaches the preseted threshold. The experimental results show that our model achieves a balance between high classification accuracy and strong generalization. In addition, it can quantifies the uncertainty of the classification results.
Towards Consistency and Complementarity: A Multiview Graph Information Bottleneck Approach
Oct 11, 2022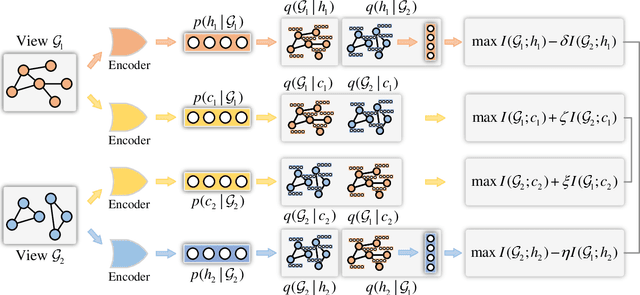
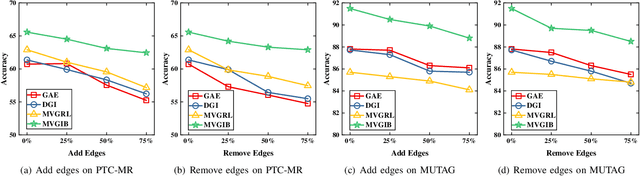
The empirical studies of Graph Neural Networks (GNNs) broadly take the original node feature and adjacency relationship as singleview input, ignoring the rich information of multiple graph views. To circumvent this issue, the multiview graph analysis framework has been developed to fuse graph information across views. How to model and integrate shared (i.e. consistency) and view-specific (i.e. complementarity) information is a key issue in multiview graph analysis. In this paper, we propose a novel Multiview Variational Graph Information Bottleneck (MVGIB) principle to maximize the agreement for common representations and the disagreement for view-specific representations. Under this principle, we formulate the common and view-specific information bottleneck objectives across multiviews by using constraints from mutual information. However, these objectives are hard to directly optimize since the mutual information is computationally intractable. To tackle this challenge, we derive variational lower and upper bounds of mutual information terms, and then instead optimize variational bounds to find the approximate solutions for the information objectives. Extensive experiments on graph benchmark datasets demonstrate the superior effectiveness of the proposed method.
Entropy Induced Pruning Framework for Convolutional Neural Networks
Aug 13, 2022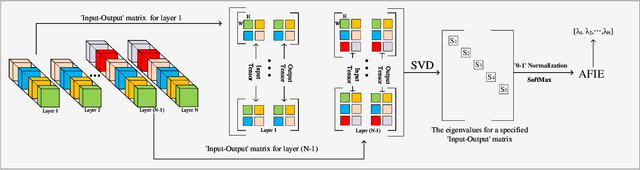
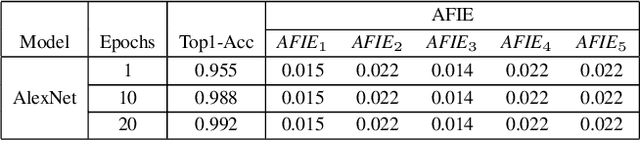


Structured pruning techniques have achieved great compression performance on convolutional neural networks for image classification task. However, the majority of existing methods are weight-oriented, and their pruning results may be unsatisfactory when the original model is trained poorly. That is, a fully-trained model is required to provide useful weight information. This may be time-consuming, and the pruning results are sensitive to the updating process of model parameters. In this paper, we propose a metric named Average Filter Information Entropy (AFIE) to measure the importance of each filter. It is calculated by three major steps, i.e., low-rank decomposition of the "input-output" matrix of each convolutional layer, normalization of the obtained eigenvalues, and calculation of filter importance based on information entropy. By leveraging the proposed AFIE, the proposed framework is able to yield a stable importance evaluation of each filter no matter whether the original model is trained fully. We implement our AFIE based on AlexNet, VGG-16, and ResNet-50, and test them on MNIST, CIFAR-10, and ImageNet, respectively. The experimental results are encouraging. We surprisingly observe that for our methods, even when the original model is only trained with one epoch, the importance evaluation of each filter keeps identical to the results when the model is fully-trained. This indicates that the proposed pruning strategy can perform effectively at the beginning stage of the training process for the original model.