 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinbo Gao
Foundation Model assisted Weakly Supervised LiDAR Semantic Segmentation
Apr 19, 2024
Current point cloud semantic segmentation has achieved great advances when given sufficient labels. However, the dense annotation of LiDAR point clouds remains prohibitively expensive and time-consuming, unable to keep up with the continuously growing volume of data. In this paper, we propose annotating images with scattered points, followed by utilizing SAM (a Foundation model) to generate semantic segmentation labels for the images. Finally, by mapping the segmentation labels of the images to the LiDAR space using the intrinsic and extrinsic parameters of the camera and LiDAR, we obtain labels for point cloud semantic segmentation, and release Scatter-KITTI and Scatter-nuScenes, which are the first works to utilize image segmentation-based SAM for weakly supervised point cloud semantic segmentation. Furthermore, to mitigate the influence of erroneous pseudo labels obtained from sparse annotations on point cloud features, we propose a multi-modal weakly supervised network for LiDAR semantic segmentation, called MM-ScatterNet. This network combines features from both point cloud and image modalities, enhancing the representation learning of point clouds by introducing consistency constraints between multi-modal features and point cloud features. On the SemanticKITTI dataset, we achieve 66\% of fully supervised performance using only 0.02% of annotated data, and on the NuScenes dataset, we achieve 95% of fully supervised performance using only 0.1% labeled points.
Meta Invariance Defense Towards Generalizable Robustness to Unknown Adversarial Attacks
Apr 04, 2024Despite providing high-performance solutions for computer vision tasks, the deep neural network (DNN) model has been proved to be extremely vulnerable to adversarial attacks. Current defense mainly focuses on the known attacks, but the adversarial robustness to the unknown attacks is seriously overlooked. Besides, commonly used adaptive learning and fine-tuning technique is unsuitable for adversarial defense since it is essentially a zero-shot problem when deployed. Thus, to tackle this challenge, we propose an attack-agnostic defense method named Meta Invariance Defense (MID). Specifically, various combinations of adversarial attacks are randomly sampled from a manually constructed Attacker Pool to constitute different defense tasks against unknown attacks, in which a student encoder is supervised by multi-consistency distillation to learn the attack-invariant features via a meta principle. The proposed MID has two merits: 1) Full distillation from pixel-, feature- and prediction-level between benign and adversarial samples facilitates the discovery of attack-invariance. 2) The model simultaneously achieves robustness to the imperceptible adversarial perturbations in high-level image classification and attack-suppression in low-level robust image regeneration. Theoretical and empirical studies on numerous benchmarks such as ImageNet verify the generalizable robustness and superiority of MID under various attacks.
InstructBrush: Learning Attention-based Instruction Optimization for Image Editing
Mar 27, 2024In recent years, instruction-based image editing methods have garnered significant attention in image editing. However, despite encompassing a wide range of editing priors, these methods are helpless when handling editing tasks that are challenging to accurately describe through language. We propose InstructBrush, an inversion method for instruction-based image editing methods to bridge this gap. It extracts editing effects from exemplar image pairs as editing instructions, which are further applied for image editing. Two key techniques are introduced into InstructBrush, Attention-based Instruction Optimization and Transformation-oriented Instruction Initialization, to address the limitations of the previous method in terms of inversion effects and instruction generalization. To explore the ability of instruction inversion methods to guide image editing in open scenarios, we establish a TransformationOriented Paired Benchmark (TOP-Bench), which contains a rich set of scenes and editing types. The creation of this benchmark paves the way for further exploration of instruction inversion. Quantitatively and qualitatively, our approach achieves superior performance in editing and is more semantically consistent with the target editing effects.
An Open-World, Diverse, Cross-Spatial-Temporal Benchmark for Dynamic Wild Person Re-Identification
Mar 22, 2024Person re-identification (ReID) has made great strides thanks to the data-driven deep learning techniques. However, the existing benchmark datasets lack diversity, and models trained on these data cannot generalize well to dynamic wild scenarios. To meet the goal of improving the explicit generalization of ReID models, we develop a new Open-World, Diverse, Cross-Spatial-Temporal dataset named OWD with several distinct features. 1) Diverse collection scenes: multiple independent open-world and highly dynamic collecting scenes, including streets, intersections, shopping malls, etc. 2) Diverse lighting variations: long time spans from daytime to nighttime with abundant illumination changes. 3) Diverse person status: multiple camera networks in all seasons with normal/adverse weather conditions and diverse pedestrian appearances (e.g., clothes, personal belongings, poses, etc.). 4) Protected privacy: invisible faces for privacy critical applications. To improve the implicit generalization of ReID, we further propose a Latent Domain Expansion (LDE) method to develop the potential of source data, which decouples discriminative identity-relevant and trustworthy domain-relevant features and implicitly enforces domain-randomized identity feature space expansion with richer domain diversity to facilitate domain invariant representations. Our comprehensive evaluations with most benchmark datasets in the community are crucial for progress, although this work is far from the grand goal toward open-world and dynamic wild applications.
Semi-Supervised Learning for Anomaly Traffic Detection via Bidirectional Normalizing Flows
Mar 13, 2024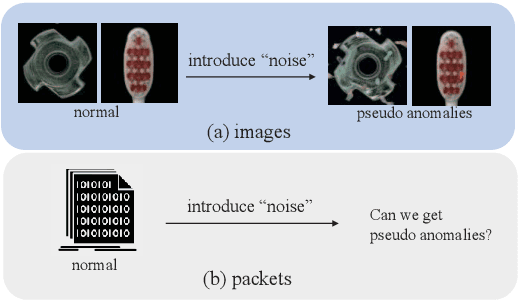
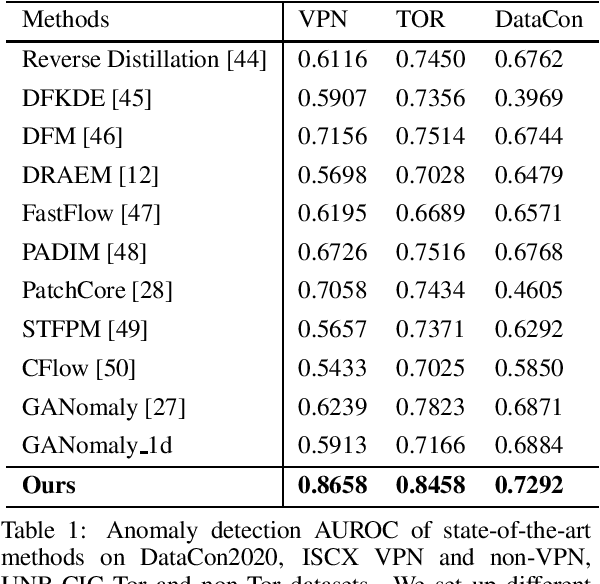
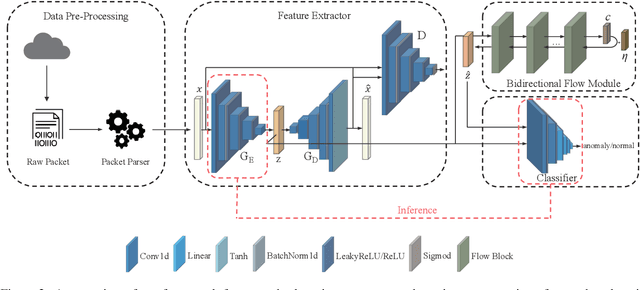
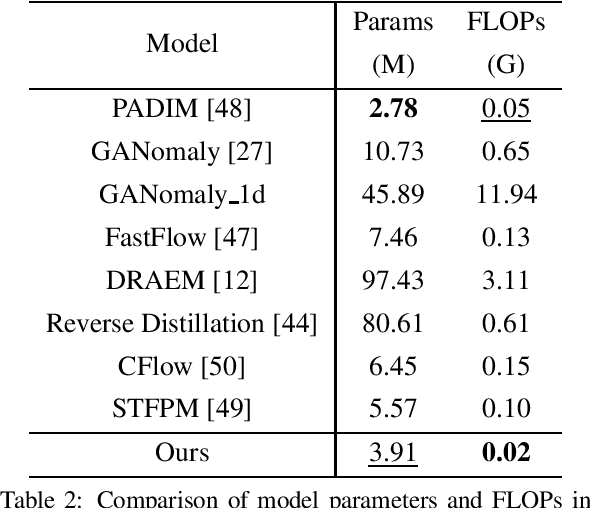
With the rapid development of the Internet, various types of anomaly traffic are threatening network security. We consider the problem of anomaly network traffic detection and propose a three-stage anomaly detection framework using only normal traffic. Our framework can generate pseudo anomaly samples without prior knowledge of anomalies to achieve the detection of anomaly data. Firstly, we employ a reconstruction method to learn the deep representation of normal samples. Secondly, these representations are normalized to a standard normal distribution using a bidirectional flow module. To simulate anomaly samples, we add noises to the normalized representations which are then passed through the generation direction of the bidirectional flow module. Finally, a simple classifier is trained to differentiate the normal samples and pseudo anomaly samples in the latent space. During inference, our framework requires only two modules to detect anomalous samples, leading to a considerable reduction in model size. According to the experiments, our method achieves the state of-the-art results on the common benchmarking datasets of anomaly network traffic detection. The code is given in the https://github.com/ZxuanDang/ATD-via-Flows.git
DAMSDet: Dynamic Adaptive Multispectral Detection Transformer with Competitive Query Selection and Adaptive Feature Fusion
Mar 07, 2024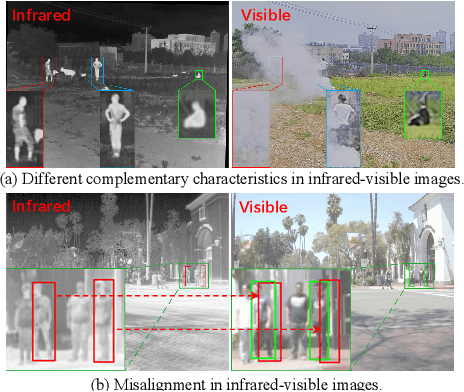
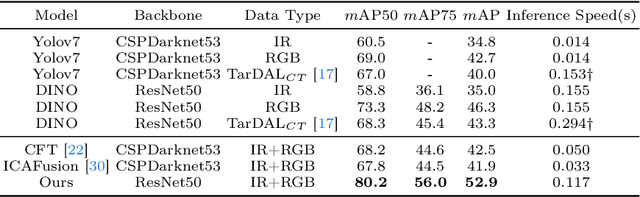

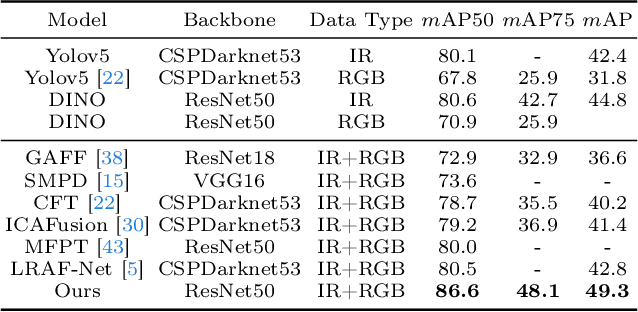
Infrared-visible object detection aims to achieve robust even full-day object detection by fusing the complementary information of infrared and visible images. However, highly dynamically variable complementary characteristics and commonly existing modality misalignment make the fusion of complementary information difficult. In this paper, we propose a Dynamic Adaptive Multispectral Detection Transformer (DAMSDet) to simultaneously address these two challenges. Specifically, we propose a Modality Competitive Query Selection strategy to provide useful prior information. This strategy can dynamically select basic salient modality feature representation for each object. To effectively mine the complementary information and adapt to misalignment situations, we propose a Multispectral Deformable Cross-attention module to adaptively sample and aggregate multi-semantic level features of infrared and visible images for each object. In addition, we further adopt the cascade structure of DETR to better mine complementary information. Experiments on four public datasets of different scenes demonstrate significant improvements compared to other state-of-the-art methods. The code will be released at https://github.com/gjj45/DAMSDet.
Are Dense Labels Always Necessary for 3D Object Detection from Point Cloud?
Mar 05, 2024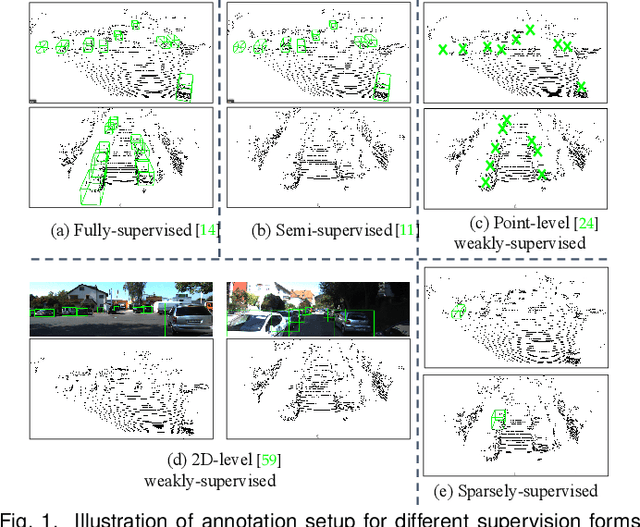
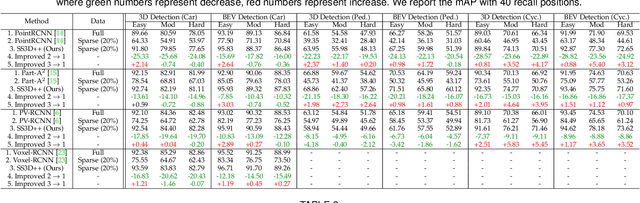
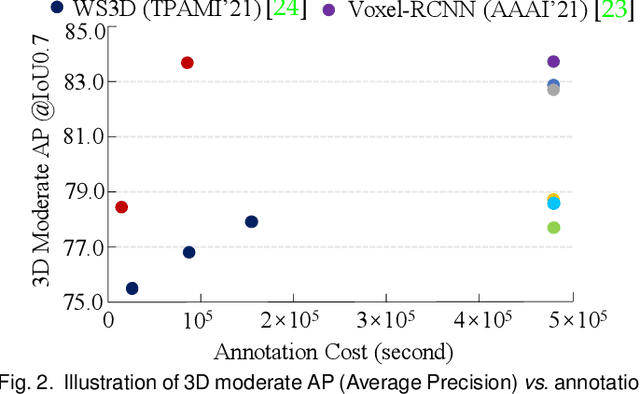

Current state-of-the-art (SOTA) 3D object detection methods often require a large amount of 3D bounding box annotations for training. However, collecting such large-scale densely-supervised datasets is notoriously costly. To reduce the cumbersome data annotation process, we propose a novel sparsely-annotated framework, in which we just annotate one 3D object per scene. Such a sparse annotation strategy could significantly reduce the heavy annotation burden, while inexact and incomplete sparse supervision may severely deteriorate the detection performance. To address this issue, we develop the SS3D++ method that alternatively improves 3D detector training and confident fully-annotated scene generation in a unified learning scheme. Using sparse annotations as seeds, we progressively generate confident fully-annotated scenes based on designing a missing-annotated instance mining module and reliable background mining module. Our proposed method produces competitive results when compared with SOTA weakly-supervised methods using the same or even more annotation costs. Besides, compared with SOTA fully-supervised methods, we achieve on-par or even better performance on the KITTI dataset with about 5x less annotation cost, and 90% of their performance on the Waymo dataset with about 15x less annotation cost. The additional unlabeled training scenes could further boost the performance. The code will be available at https://github.com/gaocq/SS3D2.
Diffusion Model Based Visual Compensation Guidance and Visual Difference Analysis for No-Reference Image Quality Assessment
Feb 22, 2024Existing free-energy guided No-Reference Image Quality Assessment (NR-IQA) methods still suffer from finding a balance between learning feature information at the pixel level of the image and capturing high-level feature information and the efficient utilization of the obtained high-level feature information remains a challenge. As a novel class of state-of-the-art (SOTA) generative model, the diffusion model exhibits the capability to model intricate relationships, enabling a comprehensive understanding of images and possessing a better learning of both high-level and low-level visual features. In view of these, we pioneer the exploration of the diffusion model into the domain of NR-IQA. Firstly, we devise a new diffusion restoration network that leverages the produced enhanced image and noise-containing images, incorporating nonlinear features obtained during the denoising process of the diffusion model, as high-level visual information. Secondly, two visual evaluation branches are designed to comprehensively analyze the obtained high-level feature information. These include the visual compensation guidance branch, grounded in the transformer architecture and noise embedding strategy, and the visual difference analysis branch, built on the ResNet architecture and the residual transposed attention block. Extensive experiments are conducted on seven public NR-IQA datasets, and the results demonstrate that the proposed model outperforms SOTA methods for NR-IQA.
Exploring Homogeneous and Heterogeneous Consistent Label Associations for Unsupervised Visible-Infrared Person ReID
Feb 04, 2024Unsupervised visible-infrared person re-identification (USL-VI-ReID) aims to retrieve pedestrian images of the same identity from different modalities without annotations. While prior work focuses on establishing cross-modality pseudo-label associations to bridge the modality-gap, they ignore maintaining the instance-level homogeneous and heterogeneous consistency in pseudo-label space, resulting in coarse associations. In response, we introduce a Modality-Unified Label Transfer (MULT) module that simultaneously accounts for both homogeneous and heterogeneous fine-grained instance-level structures, yielding high-quality cross-modality label associations. It models both homogeneous and heterogeneous affinities, leveraging them to define the inconsistency for the pseudo-labels and then minimize it, leading to pseudo-labels that maintain alignment across modalities and consistency within intra-modality structures. Additionally, a straightforward plug-and-play Online Cross-memory Label Refinement (OCLR) module is proposed to further mitigate the impact of noisy pseudo-labels while simultaneously aligning different modalities, coupled with a Modality-Invariant Representation Learning (MIRL) framework. Experiments demonstrate that our proposed method outperforms existing USL-VI-ReID methods, highlighting the superiority of our MULT in comparison to other cross-modality association methods. The code will be available.
Jailbreaking Attack against Multimodal Large Language Model
Feb 04, 2024This paper focuses on jailbreaking attacks against multi-modal large language models (MLLMs), seeking to elicit MLLMs to generate objectionable responses to harmful user queries. A maximum likelihood-based algorithm is proposed to find an \emph{image Jailbreaking Prompt} (imgJP), enabling jailbreaks against MLLMs across multiple unseen prompts and images (i.e., data-universal property). Our approach exhibits strong model-transferability, as the generated imgJP can be transferred to jailbreak various models, including MiniGPT-v2, LLaVA, InstructBLIP, and mPLUG-Owl2, in a black-box manner. Moreover, we reveal a connection between MLLM-jailbreaks and LLM-jailbreaks. As a result, we introduce a construction-based method to harness our approach for LLM-jailbreaks, demonstrating greater efficiency than current state-of-the-art methods. The code is available here. \textbf{Warning: some content generated by language models may be offensive to some readers.}