 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQingnan Fan
FreeDiff: Progressive Frequency Truncation for Image Editing with Diffusion Models
Apr 18, 2024
Precise image editing with text-to-image models has attracted increasing interest due to their remarkable generative capabilities and user-friendly nature. However, such attempts face the pivotal challenge of misalignment between the intended precise editing target regions and the broader area impacted by the guidance in practice. Despite excellent methods leveraging attention mechanisms that have been developed to refine the editing guidance, these approaches necessitate modifications through complex network architecture and are limited to specific editing tasks. In this work, we re-examine the diffusion process and misalignment problem from a frequency perspective, revealing that, due to the power law of natural images and the decaying noise schedule, the denoising network primarily recovers low-frequency image components during the earlier timesteps and thus brings excessive low-frequency signals for editing. Leveraging this insight, we introduce a novel fine-tuning free approach that employs progressive $\textbf{Fre}$qu$\textbf{e}$ncy truncation to refine the guidance of $\textbf{Diff}$usion models for universal editing tasks ($\textbf{FreeDiff}$). Our method achieves comparable results with state-of-the-art methods across a variety of editing tasks and on a diverse set of images, highlighting its potential as a versatile tool in image editing applications.
Tuning-Free Adaptive Style Incorporation for Structure-Consistent Text-Driven Style Transfer
Apr 10, 2024In this work, we target the task of text-driven style transfer in the context of text-to-image (T2I) diffusion models. The main challenge is consistent structure preservation while enabling effective style transfer effects. The past approaches in this field directly concatenate the content and style prompts for a prompt-level style injection, leading to unavoidable structure distortions. In this work, we propose a novel solution to the text-driven style transfer task, namely, Adaptive Style Incorporation~(ASI), to achieve fine-grained feature-level style incorporation. It consists of the Siamese Cross-Attention~(SiCA) to decouple the single-track cross-attention to a dual-track structure to obtain separate content and style features, and the Adaptive Content-Style Blending (AdaBlending) module to couple the content and style information from a structure-consistent manner. Experimentally, our method exhibits much better performance in both structure preservation and stylized effects.
InstructBrush: Learning Attention-based Instruction Optimization for Image Editing
Mar 27, 2024In recent years, instruction-based image editing methods have garnered significant attention in image editing. However, despite encompassing a wide range of editing priors, these methods are helpless when handling editing tasks that are challenging to accurately describe through language. We propose InstructBrush, an inversion method for instruction-based image editing methods to bridge this gap. It extracts editing effects from exemplar image pairs as editing instructions, which are further applied for image editing. Two key techniques are introduced into InstructBrush, Attention-based Instruction Optimization and Transformation-oriented Instruction Initialization, to address the limitations of the previous method in terms of inversion effects and instruction generalization. To explore the ability of instruction inversion methods to guide image editing in open scenarios, we establish a TransformationOriented Paired Benchmark (TOP-Bench), which contains a rich set of scenes and editing types. The creation of this benchmark paves the way for further exploration of instruction inversion. Quantitatively and qualitatively, our approach achieves superior performance in editing and is more semantically consistent with the target editing effects.
C$\cdot$ASE: Learning Conditional Adversarial Skill Embeddings for Physics-based Characters
Sep 20, 2023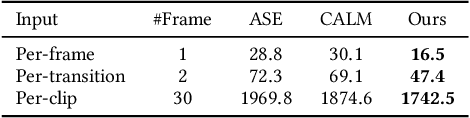
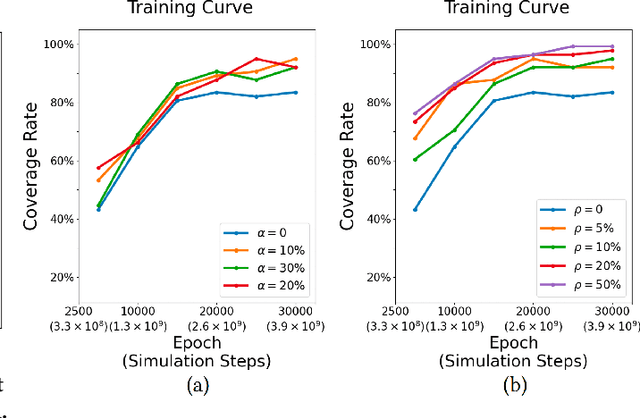

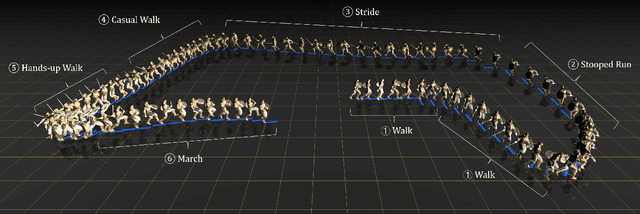
We present C$\cdot$ASE, an efficient and effective framework that learns conditional Adversarial Skill Embeddings for physics-based characters. Our physically simulated character can learn a diverse repertoire of skills while providing controllability in the form of direct manipulation of the skills to be performed. C$\cdot$ASE divides the heterogeneous skill motions into distinct subsets containing homogeneous samples for training a low-level conditional model to learn conditional behavior distribution. The skill-conditioned imitation learning naturally offers explicit control over the character's skills after training. The training course incorporates the focal skill sampling, skeletal residual forces, and element-wise feature masking to balance diverse skills of varying complexities, mitigate dynamics mismatch to master agile motions and capture more general behavior characteristics, respectively. Once trained, the conditional model can produce highly diverse and realistic skills, outperforming state-of-the-art models, and can be repurposed in various downstream tasks. In particular, the explicit skill control handle allows a high-level policy or user to direct the character with desired skill specifications, which we demonstrate is advantageous for interactive character animation.
3D-Aware Object Goal Navigation via Simultaneous Exploration and Identification
Dec 01, 2022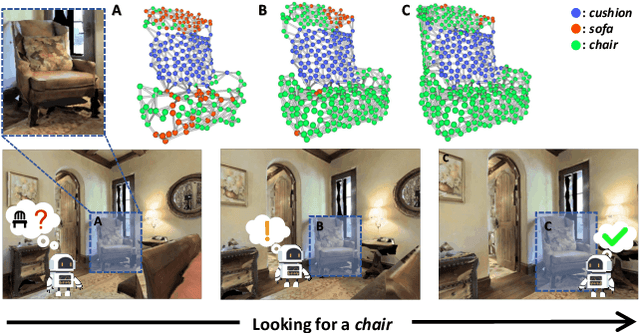
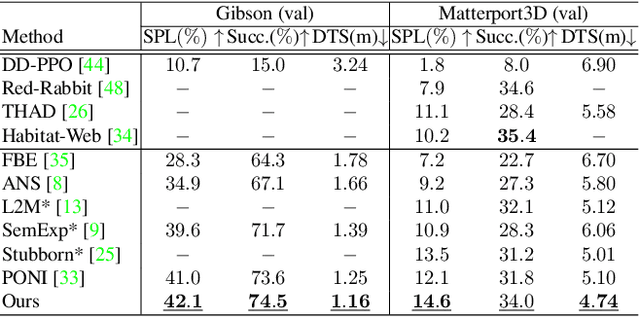
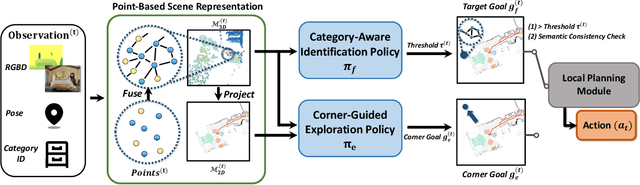
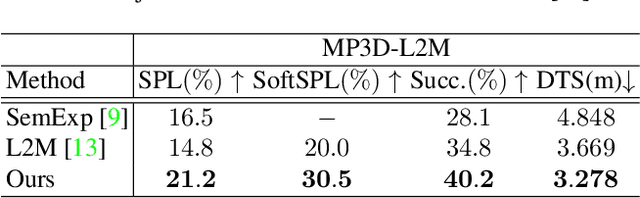
Object goal navigation (ObjectNav) in unseen environments is a fundamental task for Embodied AI. Agents in existing works learn ObjectNav policies based on 2D maps, scene graphs, or image sequences. Considering this task happens in 3D space, a 3D-aware agent can advance its ObjectNav capability via learning from fine-grained spatial information. However, leveraging 3D scene representation can be prohibitively unpractical for policy learning in this floor-level task, due to low sample efficiency and expensive computational cost. In this work, we propose a framework for the challenging 3D-aware ObjectNav based on two straightforward sub-policies. The two sub-polices, namely corner-guided exploration policy and category-aware identification policy, simultaneously perform by utilizing online fused 3D points as observation. Through extensive experiments, we show that this framework can dramatically improve the performance in ObjectNav through learning from 3D scene representation. Our framework achieves the best performance among all modular-based methods on the Matterport3D and Gibson datasets, while requiring (up to 30x) less computational cost for training.
DualAfford: Learning Collaborative Visual Affordance for Dual-gripper Object Manipulation
Jul 05, 2022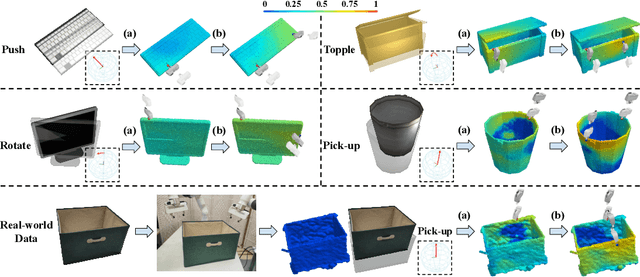
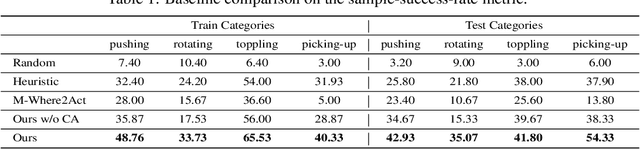
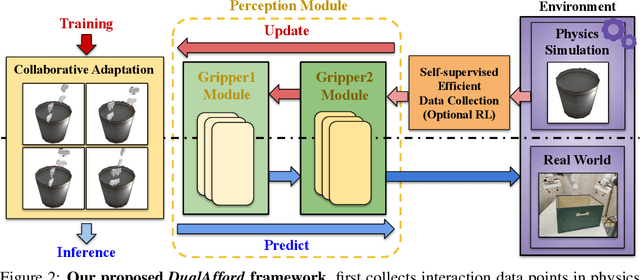

It is essential yet challenging for future home-assistant robots to understand and manipulate diverse 3D objects in daily human environments. Towards building scalable systems that can perform diverse manipulation tasks over various 3D shapes, recent works have advocated and demonstrated promising results learning visual actionable affordance, which labels every point over the input 3D geometry with an action likelihood of accomplishing the downstream task (e.g., pushing or picking-up). However, these works only studied single-gripper manipulation tasks, yet many real-world tasks require two hands to achieve collaboratively. In this work, we propose a novel learning framework, DualAfford, to learn collaborative affordance for dual-gripper manipulation tasks. The core design of the approach is to reduce the quadratic problem for two grippers into two disentangled yet interconnected subtasks for efficient learning. Using the large-scale PartNet-Mobility and ShapeNet datasets, we set up four benchmark tasks for dual-gripper manipulation. Experiments prove the effectiveness and superiority of our method over three baselines. Additional results and videos can be found at https://hyperplane-lab.github.io/DualAfford .
Multi-Robot Active Mapping via Neural Bipartite Graph Matching
Apr 01, 2022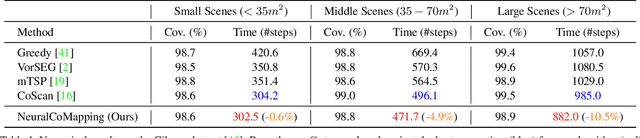
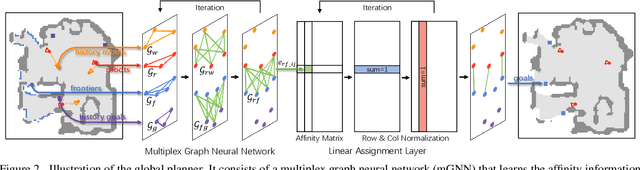
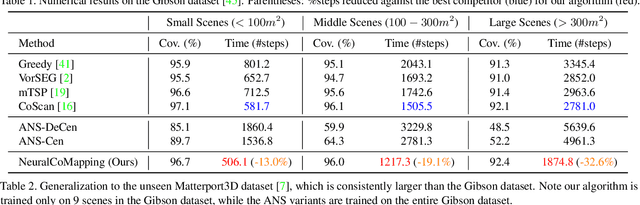
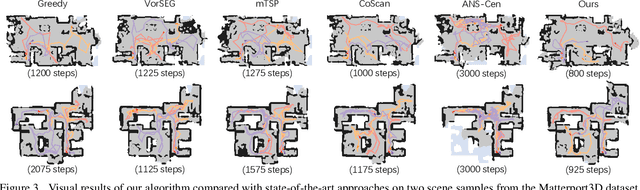
We study the problem of multi-robot active mapping, which aims for complete scene map construction in minimum time steps. The key to this problem lies in the goal position estimation to enable more efficient robot movements. Previous approaches either choose the frontier as the goal position via a myopic solution that hinders the time efficiency, or maximize the long-term value via reinforcement learning to directly regress the goal position, but does not guarantee the complete map construction. In this paper, we propose a novel algorithm, namely NeuralCoMapping, which takes advantage of both approaches. We reduce the problem to bipartite graph matching, which establishes the node correspondences between two graphs, denoting robots and frontiers. We introduce a multiplex graph neural network (mGNN) that learns the neural distance to fill the affinity matrix for more effective graph matching. We optimize the mGNN with a differentiable linear assignment layer by maximizing the long-term values that favor time efficiency and map completeness via reinforcement learning. We compare our algorithm with several state-of-the-art multi-robot active mapping approaches and adapted reinforcement-learning baselines. Experimental results demonstrate the superior performance and exceptional generalization ability of our algorithm on various indoor scenes and unseen number of robots, when only trained with 9 indoor scenes.
RoboAssembly: Learning Generalizable Furniture Assembly Policy in a Novel Multi-robot Contact-rich Simulation Environment
Dec 19, 2021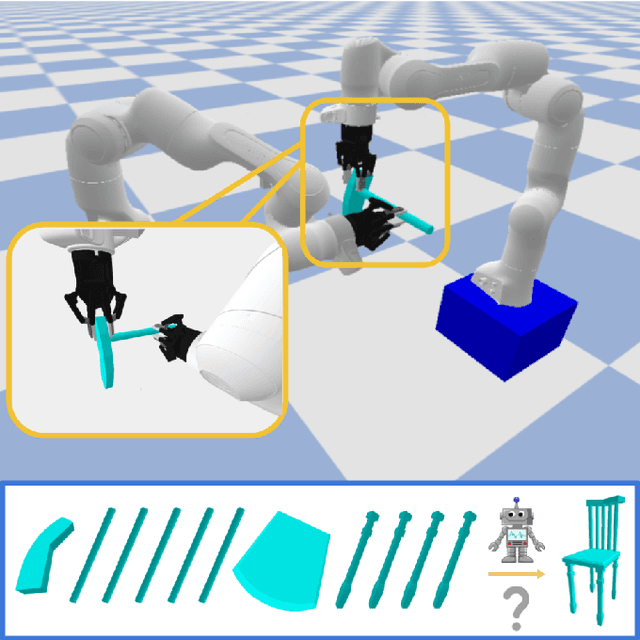
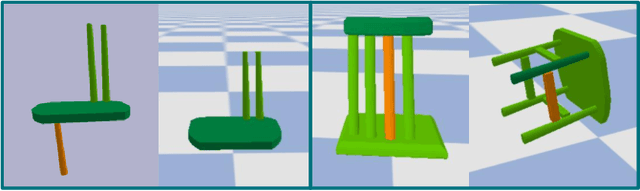
Part assembly is a typical but challenging task in robotics, where robots assemble a set of individual parts into a complete shape. In this paper, we develop a robotic assembly simulation environment for furniture assembly. We formulate the part assembly task as a concrete reinforcement learning problem and propose a pipeline for robots to learn to assemble a diverse set of chairs. Experiments show that when testing with unseen chairs, our approach achieves a success rate of 74.5% under the object-centric setting and 50.0% under the full setting. We adopt an RRT-Connect algorithm as the baseline, which only achieves a success rate of 18.8% after a significantly longer computation time. Supplemental materials and videos are available on our project webpage.
AdaAfford: Learning to Adapt Manipulation Affordance for 3D Articulated Objects via Few-shot Interactions
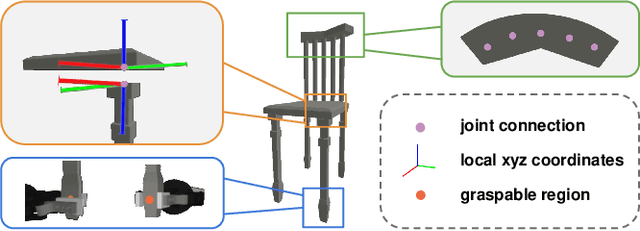
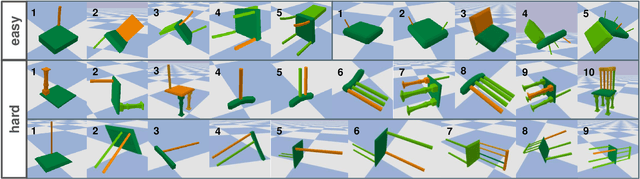
Dec 01, 2021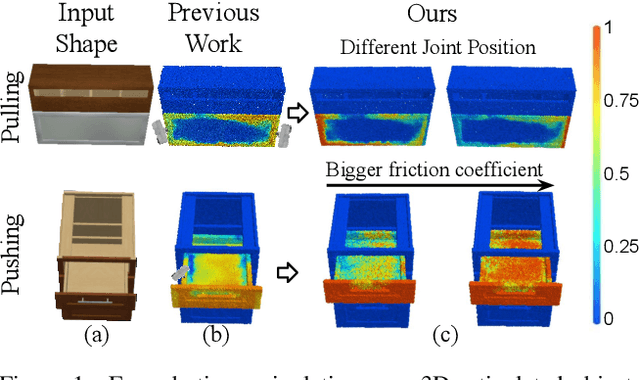
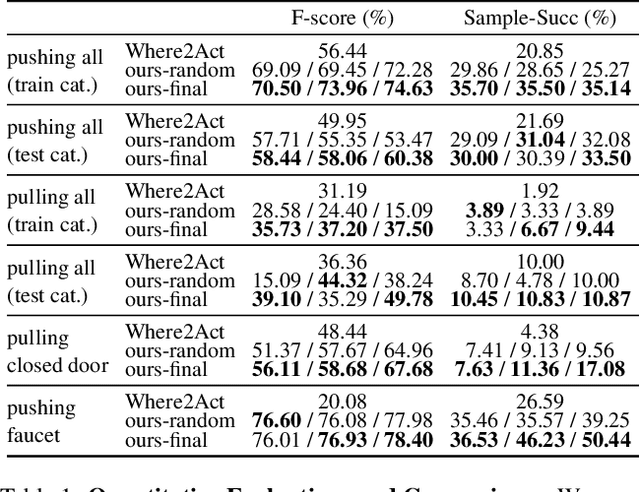
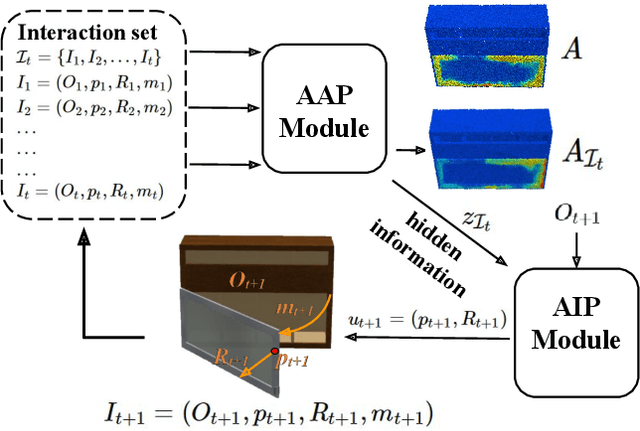
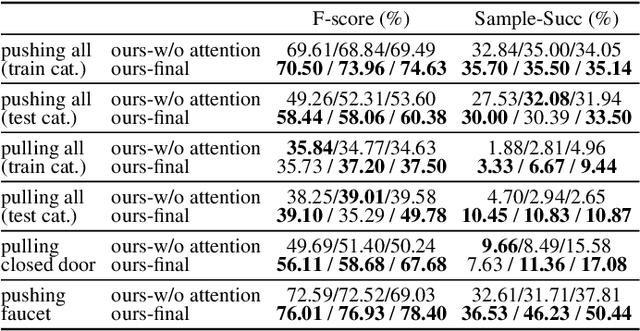
Perceiving and interacting with 3D articulated objects, such as cabinets, doors, and faucets, pose particular challenges for future home-assistant robots performing daily tasks in human environments. Besides parsing the articulated parts and joint parameters, researchers recently advocate learning manipulation affordance over the input shape geometry which is more task-aware and geometrically fine-grained. However, taking only passive observations as inputs, these methods ignore many hidden but important kinematic constraints (e.g., joint location and limits) and dynamic factors (e.g., joint friction and restitution), therefore losing significant accuracy for test cases with such uncertainties. In this paper, we propose a novel framework, named AdaAfford, that learns to perform very few test-time interactions for quickly adapting the affordance priors to more accurate instance-specific posteriors. We conduct large-scale experiments using the PartNet-Mobility dataset and prove that our system performs better than baselines.
ADeLA: Automatic Dense Labeling with Attention for Viewpoint Adaptation in Semantic Segmentation
Jul 29, 2021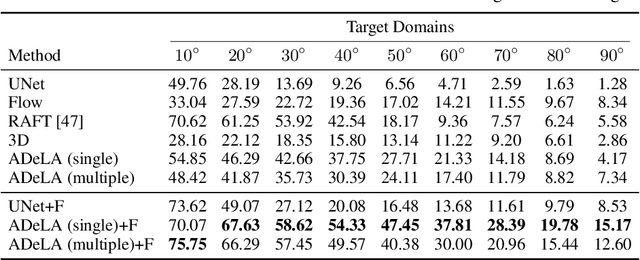

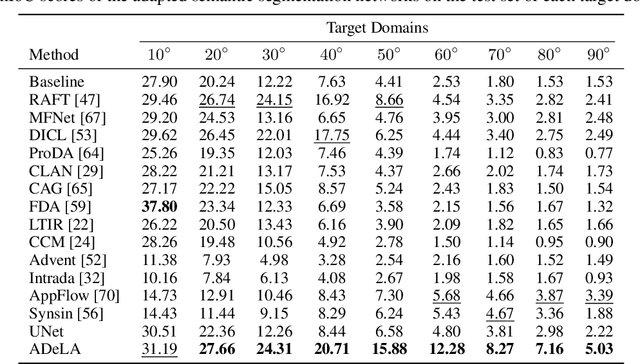

We describe an unsupervised domain adaptation method for image content shift caused by viewpoint changes for a semantic segmentation task. Most existing methods perform domain alignment in a shared space and assume that the mapping from the aligned space to the output is transferable. However, the novel content induced by viewpoint changes may nullify such a space for effective alignments, thus resulting in negative adaptation. Our method works without aligning any statistics of the images between the two domains. Instead, it utilizes a view transformation network trained only on color images to hallucinate the semantic images for the target. Despite the lack of supervision, the view transformation network can still generalize to semantic images thanks to the inductive bias introduced by the attention mechanism. Furthermore, to resolve ambiguities in converting the semantic images to semantic labels, we treat the view transformation network as a functional representation of an unknown mapping implied by the color images and propose functional label hallucination to generate pseudo-labels in the target domain. Our method surpasses baselines built on state-of-the-art correspondence estimation and view synthesis methods. Moreover, it outperforms the state-of-the-art unsupervised domain adaptation methods that utilize self-training and adversarial domain alignment. Our code and dataset will be made publicly available.