 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan Zhao
A Unified Replay-based Continuous Learning Framework for Spatio-Temporal Prediction on Streaming Data
Apr 23, 2024
The widespread deployment of wireless and mobile devices results in a proliferation of spatio-temporal data that is used in applications, e.g., traffic prediction, human mobility mining, and air quality prediction, where spatio-temporal prediction is often essential to enable safety, predictability, or reliability. Many recent proposals that target deep learning for spatio-temporal prediction suffer from so-called catastrophic forgetting, where previously learned knowledge is entirely forgotten when new data arrives. Such proposals may experience deteriorating prediction performance when applied in settings where data streams into the system. To enable spatio-temporal prediction on streaming data, we propose a unified replay-based continuous learning framework. The framework includes a replay buffer of previously learned samples that are fused with training data using a spatio-temporal mixup mechanism in order to preserve historical knowledge effectively, thus avoiding catastrophic forgetting. To enable holistic representation preservation, the framework also integrates a general spatio-temporal autoencoder with a carefully designed spatio-temporal simple siamese (STSimSiam) network that aims to ensure prediction accuracy and avoid holistic feature loss by means of mutual information maximization. The framework further encompasses five spatio-temporal data augmentation methods to enhance the performance of STSimSiam. Extensive experiments on real data offer insight into the effectiveness of the proposed framework.
E2USD: Efficient-yet-effective Unsupervised State Detection for Multivariate Time Series
Mar 01, 2024We propose E2USD that enables efficient-yet-accurate unsupervised MTS state detection. E2USD exploits a Fast Fourier Transform-based Time Series Compressor (FFTCompress) and a Decomposed Dual-view Embedding Module (DDEM) that together encode input MTSs at low computational overhead. Additionally, we propose a False Negative Cancellation Contrastive Learning method (FNCCLearning) to counteract the effects of false negatives and to achieve more cluster-friendly embedding spaces. To reduce computational overhead further in streaming settings, we introduce Adaptive Threshold Detection (ADATD). Comprehensive experiments with six baselines and six datasets offer evidence that E2USD is capable of SOTA accuracy at significantly reduced computational overhead. Our code is available at https://github.com/AI4CTS/E2Usd.
LB-KBQA: Large-language-model and BERT based Knowledge-Based Question and Answering System
Feb 09, 2024Generative Artificial Intelligence (AI), because of its emergent abilities, has empowered various fields, one typical of which is large language models (LLMs). One of the typical application fields of Generative AI is large language models (LLMs), and the natural language understanding capability of LLM is dramatically improved when compared with conventional AI-based methods. The natural language understanding capability has always been a barrier to the intent recognition performance of the Knowledge-Based-Question-and-Answer (KBQA) system, which arises from linguistic diversity and the newly appeared intent. Conventional AI-based methods for intent recognition can be divided into semantic parsing-based and model-based approaches. However, both of the methods suffer from limited resources in intent recognition. To address this issue, we propose a novel KBQA system based on a Large Language Model(LLM) and BERT (LB-KBQA). With the help of generative AI, our proposed method could detect newly appeared intent and acquire new knowledge. In experiments on financial domain question answering, our model has demonstrated superior effectiveness.
Emotion-Aware Contrastive Adaptation Network for Source-Free Cross-Corpus Speech Emotion Recognition
Jan 23, 2024Cross-corpus speech emotion recognition (SER) aims to transfer emotional knowledge from a labeled source corpus to an unlabeled corpus. However, prior methods require access to source data during adaptation, which is unattainable in real-life scenarios due to data privacy protection concerns. This paper tackles a more practical task, namely source-free cross-corpus SER, where a pre-trained source model is adapted to the target domain without access to source data. To address the problem, we propose a novel method called emotion-aware contrastive adaptation network (ECAN). The core idea is to capture local neighborhood information between samples while considering the global class-level adaptation. Specifically, we propose a nearest neighbor contrastive learning to promote local emotion consistency among features of highly similar samples. Furthermore, relying solely on nearest neighborhoods may lead to ambiguous boundaries between clusters. Thus, we incorporate supervised contrastive learning to encourage greater separation between clusters representing different emotions, thereby facilitating improved class-level adaptation. Extensive experiments indicate that our proposed ECAN significantly outperforms state-of-the-art methods under the source-free cross-corpus SER setting on several speech emotion corpora.
Speech Swin-Transformer: Exploring a Hierarchical Transformer with Shifted Windows for Speech Emotion Recognition
Jan 19, 2024Swin-Transformer has demonstrated remarkable success in computer vision by leveraging its hierarchical feature representation based on Transformer. In speech signals, emotional information is distributed across different scales of speech features, e.\,g., word, phrase, and utterance. Drawing above inspiration, this paper presents a hierarchical speech Transformer with shifted windows to aggregate multi-scale emotion features for speech emotion recognition (SER), called Speech Swin-Transformer. Specifically, we first divide the speech spectrogram into segment-level patches in the time domain, composed of multiple frame patches. These segment-level patches are then encoded using a stack of Swin blocks, in which a local window Transformer is utilized to explore local inter-frame emotional information across frame patches of each segment patch. After that, we also design a shifted window Transformer to compensate for patch correlations near the boundaries of segment patches. Finally, we employ a patch merging operation to aggregate segment-level emotional features for hierarchical speech representation by expanding the receptive field of Transformer from frame-level to segment-level. Experimental results demonstrate that our proposed Speech Swin-Transformer outperforms the state-of-the-art methods.
Improving Speaker-independent Speech Emotion Recognition Using Dynamic Joint Distribution Adaptation
Jan 18, 2024In speaker-independent speech emotion recognition, the training and testing samples are collected from diverse speakers, leading to a multi-domain shift challenge across the feature distributions of data from different speakers. Consequently, when the trained model is confronted with data from new speakers, its performance tends to degrade. To address the issue, we propose a Dynamic Joint Distribution Adaptation (DJDA) method under the framework of multi-source domain adaptation. DJDA firstly utilizes joint distribution adaptation (JDA), involving marginal distribution adaptation (MDA) and conditional distribution adaptation (CDA), to more precisely measure the multi-domain distribution shifts caused by different speakers. This helps eliminate speaker bias in emotion features, allowing for learning discriminative and speaker-invariant speech emotion features from coarse-level to fine-level. Furthermore, we quantify the adaptation contributions of MDA and CDA within JDA by using a dynamic balance factor based on $\mathcal{A}$-Distance, promoting to effectively handle the unknown distributions encountered in data from new speakers. Experimental results demonstrate the superior performance of our DJDA as compared to other state-of-the-art (SOTA) methods.
Towards Domain-Specific Cross-Corpus Speech Emotion Recognition Approach
Dec 11, 2023Cross-corpus speech emotion recognition (SER) poses a challenge due to feature distribution mismatch, potentially degrading the performance of established SER methods. In this paper, we tackle this challenge by proposing a novel transfer subspace learning method called acoustic knowledgeguided transfer linear regression (AKTLR). Unlike existing approaches, which often overlook domain-specific knowledge related to SER and simply treat cross-corpus SER as a generic transfer learning task, our AKTLR method is built upon a well-designed acoustic knowledge-guided dual sparsity constraint mechanism. This mechanism emphasizes the potential of minimalistic acoustic parameter feature sets to alleviate classifier overadaptation, which is empirically validated acoustic knowledge in SER, enabling superior generalization in cross-corpus SER tasks compared to using large feature sets. Through this mechanism, we extend a simple transfer linear regression model to AKTLR. This extension harnesses its full capability to seek emotiondiscriminative and corpus-invariant features from established acoustic parameter feature sets used for describing speech signals across two scales: contributive acoustic parameter groups and constituent elements within each contributive group. Our proposed method is evaluated through extensive cross-corpus SER experiments on three widely-used speech emotion corpora: EmoDB, eNTERFACE, and CASIA. The results confirm the effectiveness and superior performance of our method, outperforming recent state-of-the-art transfer subspace learning and deep transfer learning-based cross-corpus SER methods. Furthermore, our work provides experimental evidence supporting the feasibility and superiority of incorporating domain-specific knowledge into the transfer learning model to address cross-corpus SER tasks.
Audio Prompt Tuning for Universal Sound Separation
Nov 30, 2023Universal sound separation (USS) is a task to separate arbitrary sounds from an audio mixture. Existing USS systems are capable of separating arbitrary sources, given a few examples of the target sources as queries. However, separating arbitrary sounds with a single system is challenging, and the robustness is not always guaranteed. In this work, we propose audio prompt tuning (APT), a simple yet effective approach to enhance existing USS systems. Specifically, APT improves the separation performance of specific sources through training a small number of prompt parameters with limited audio samples, while maintaining the generalization of the USS model by keeping its parameters frozen. We evaluate the proposed method on MUSDB18 and ESC-50 datasets. Compared with the baseline model, APT can improve the signal-to-distortion ratio performance by 0.67 dB and 2.06 dB using the full training set of two datasets. Moreover, APT with only 5 audio samples even outperforms the baseline systems utilizing full training data on the ESC-50 dataset, indicating the great potential of few-shot APT.
Layer-Adapted Implicit Distribution Alignment Networks for Cross-Corpus Speech Emotion Recognition
Oct 06, 2023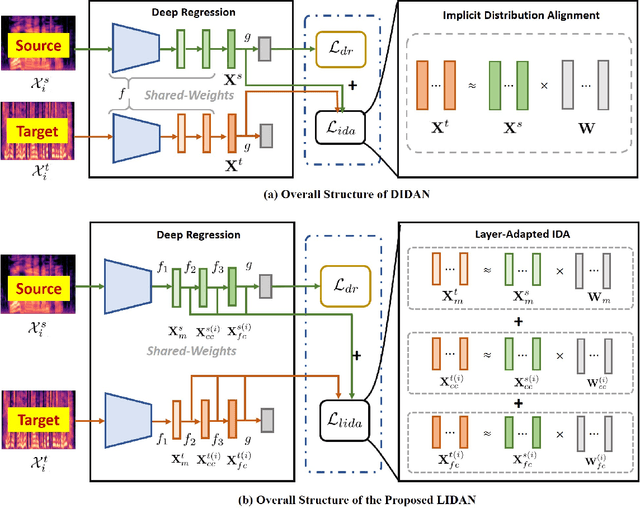
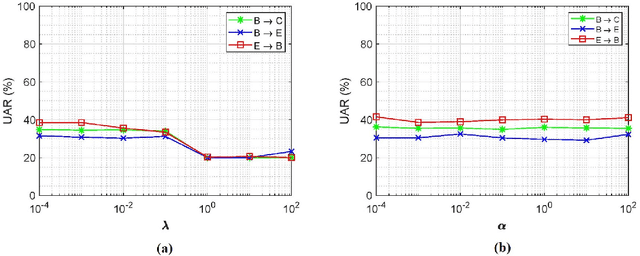

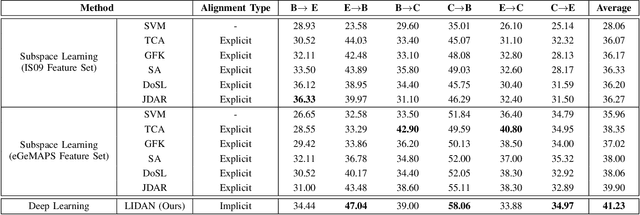
In this paper, we propose a new unsupervised domain adaptation (DA) method called layer-adapted implicit distribution alignment networks (LIDAN) to address the challenge of cross-corpus speech emotion recognition (SER). LIDAN extends our previous ICASSP work, deep implicit distribution alignment networks (DIDAN), whose key contribution lies in the introduction of a novel regularization term called implicit distribution alignment (IDA). This term allows DIDAN trained on source (training) speech samples to remain applicable to predicting emotion labels for target (testing) speech samples, regardless of corpus variance in cross-corpus SER. To further enhance this method, we extend IDA to layer-adapted IDA (LIDA), resulting in LIDAN. This layer-adpated extention consists of three modified IDA terms that consider emotion labels at different levels of granularity. These terms are strategically arranged within different fully connected layers in LIDAN, aligning with the increasing emotion-discriminative abilities with respect to the layer depth. This arrangement enables LIDAN to more effectively learn emotion-discriminative and corpus-invariant features for SER across various corpora compared to DIDAN. It is also worthy to mention that unlike most existing methods that rely on estimating statistical moments to describe pre-assumed explicit distributions, both IDA and LIDA take a different approach. They utilize an idea of target sample reconstruction to directly bridge the feature distribution gap without making assumptions about their distribution type. As a result, DIDAN and LIDAN can be viewed as implicit cross-corpus SER methods. To evaluate LIDAN, we conducted extensive cross-corpus SER experiments on EmoDB, eNTERFACE, and CASIA corpora. The experimental results demonstrate that LIDAN surpasses recent state-of-the-art explicit unsupervised DA methods in tackling cross-corpus SER tasks.
Leveraging SE(3) Equivariance for Learning 3D Geometric Shape Assembly
Sep 13, 2023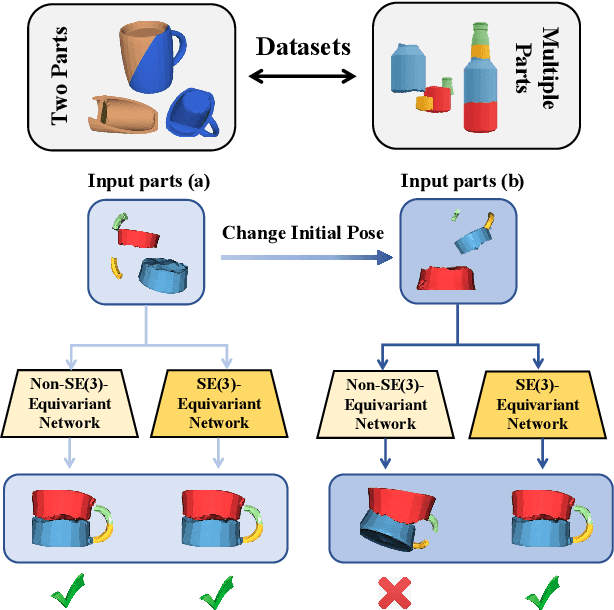
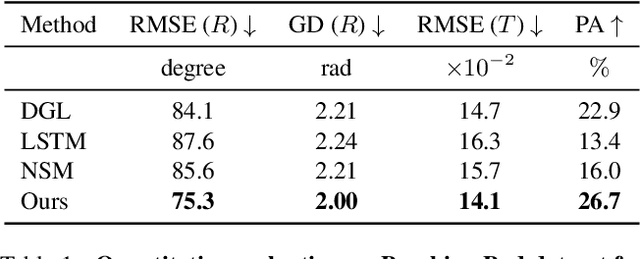
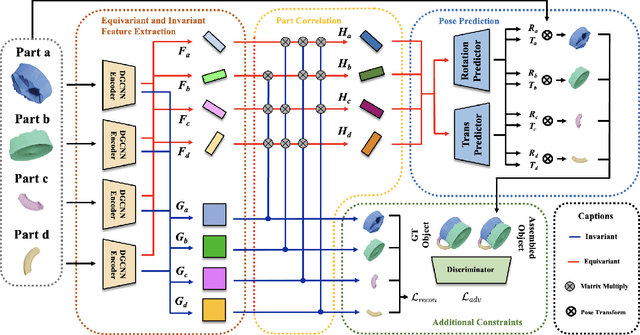
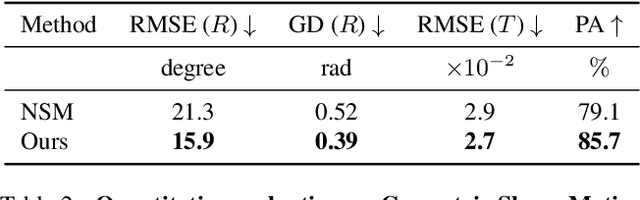
Shape assembly aims to reassemble parts (or fragments) into a complete object, which is a common task in our daily life. Different from the semantic part assembly (e.g., assembling a chair's semantic parts like legs into a whole chair), geometric part assembly (e.g., assembling bowl fragments into a complete bowl) is an emerging task in computer vision and robotics. Instead of semantic information, this task focuses on geometric information of parts. As the both geometric and pose space of fractured parts are exceptionally large, shape pose disentanglement of part representations is beneficial to geometric shape assembly. In our paper, we propose to leverage SE(3) equivariance for such shape pose disentanglement. Moreover, while previous works in vision and robotics only consider SE(3) equivariance for the representations of single objects, we move a step forward and propose leveraging SE(3) equivariance for representations considering multi-part correlations, which further boosts the performance of the multi-part assembly. Experiments demonstrate the significance of SE(3) equivariance and our proposed method for geometric shape assembly. Project page: https://crtie.github.io/SE-3-part-assembly/