 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDalin Zhang
E2USD: Efficient-yet-effective Unsupervised State Detection for Multivariate Time Series
Mar 01, 2024
We propose E2USD that enables efficient-yet-accurate unsupervised MTS state detection. E2USD exploits a Fast Fourier Transform-based Time Series Compressor (FFTCompress) and a Decomposed Dual-view Embedding Module (DDEM) that together encode input MTSs at low computational overhead. Additionally, we propose a False Negative Cancellation Contrastive Learning method (FNCCLearning) to counteract the effects of false negatives and to achieve more cluster-friendly embedding spaces. To reduce computational overhead further in streaming settings, we introduce Adaptive Threshold Detection (ADATD). Comprehensive experiments with six baselines and six datasets offer evidence that E2USD is capable of SOTA accuracy at significantly reduced computational overhead. Our code is available at https://github.com/AI4CTS/E2Usd.
TBDetector:Transformer-Based Detector for Advanced Persistent Threats with Provenance Graph
Apr 06, 2023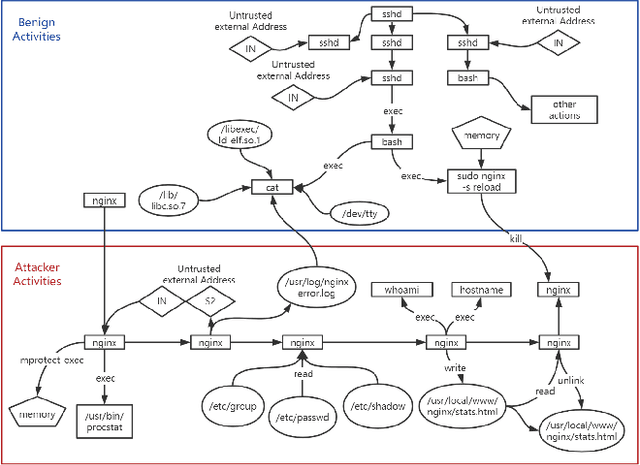
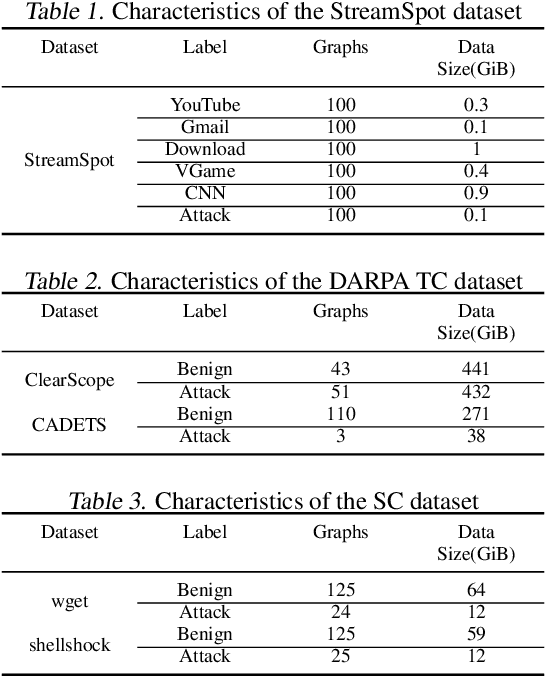

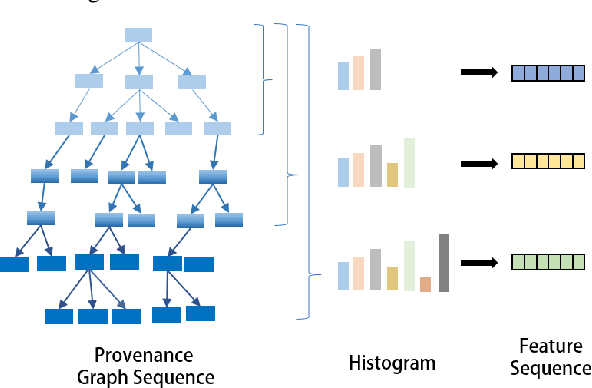
APT detection is difficult to detect due to the long-term latency, covert and slow multistage attack patterns of Advanced Persistent Threat (APT). To tackle these issues, we propose TBDetector, a transformer-based advanced persistent threat detection method for APT attack detection. Considering that provenance graphs provide rich historical information and have the powerful attacks historic correlation ability to identify anomalous activities, TBDetector employs provenance analysis for APT detection, which summarizes long-running system execution with space efficiency and utilizes transformer with self-attention based encoder-decoder to extract long-term contextual features of system states to detect slow-acting attacks. Furthermore, we further introduce anomaly scores to investigate the anomaly of different system states, where each state is calculated with an anomaly score corresponding to its similarity score and isolation score. To evaluate the effectiveness of the proposed method, we have conducted experiments on five public datasets, i.e., streamspot, cadets, shellshock, clearscope, and wget_baseline. Experimental results and comparisons with state-of-the-art methods have exhibited better performance of our proposed method.
LightCTS: A Lightweight Framework for Correlated Time Series Forecasting
Feb 27, 2023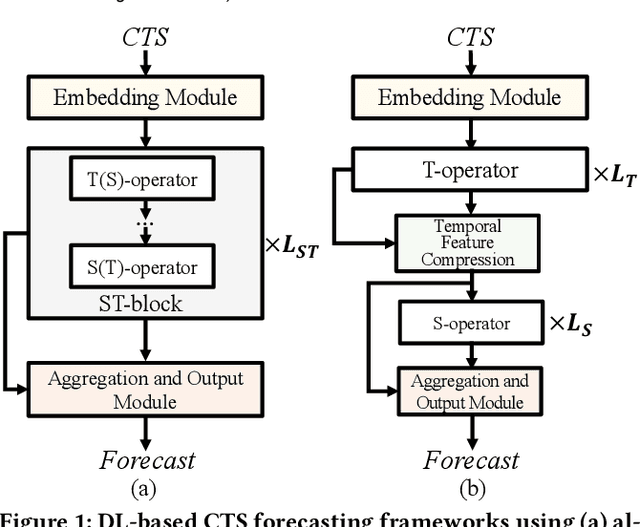



Correlated time series (CTS) forecasting plays an essential role in many practical applications, such as traffic management and server load control. Many deep learning models have been proposed to improve the accuracy of CTS forecasting. However, while models have become increasingly complex and computationally intensive, they struggle to improve accuracy. Pursuing a different direction, this study aims instead to enable much more efficient, lightweight models that preserve accuracy while being able to be deployed on resource-constrained devices. To achieve this goal, we characterize popular CTS forecasting models and yield two observations that indicate directions for lightweight CTS forecasting. On this basis, we propose the LightCTS framework that adopts plain stacking of temporal and spatial operators instead of alternate stacking that is much more computationally expensive. Moreover, LightCTS features light temporal and spatial operator modules, called L-TCN and GL-Former, that offer improved computational efficiency without compromising their feature extraction capabilities. LightCTS also encompasses a last-shot compression scheme to reduce redundant temporal features and speed up subsequent computations. Experiments with single-step and multi-step forecasting benchmark datasets show that LightCTS is capable of nearly state-of-the-art accuracy at much reduced computational and storage overheads.
AutoPINN: When AutoML Meets Physics-Informed Neural Networks
Dec 08, 2022

Physics-Informed Neural Networks (PINNs) have recently been proposed to solve scientific and engineering problems, where physical laws are introduced into neural networks as prior knowledge. With the embedded physical laws, PINNs enable the estimation of critical parameters, which are unobservable via physical tools, through observable variables. For example, Power Electronic Converters (PECs) are essential building blocks for the green energy transition. PINNs have been applied to estimate the capacitance, which is unobservable during PEC operations, using current and voltage, which can be observed easily during operations. The estimated capacitance facilitates self-diagnostics of PECs. Existing PINNs are often manually designed, which is time-consuming and may lead to suboptimal performance due to a large number of design choices for neural network architectures and hyperparameters. In addition, PINNs are often deployed on different physical devices, e.g., PECs, with limited and varying resources. Therefore, it requires designing different PINN models under different resource constraints, making it an even more challenging task for manual design. To contend with the challenges, we propose Automated Physics-Informed Neural Networks (AutoPINN), a framework that enables the automated design of PINNs by combining AutoML and PINNs. Specifically, we first tailor a search space that allows finding high-accuracy PINNs for PEC internal parameter estimation. We then propose a resource-aware search strategy to explore the search space to find the best PINN model under different resource constraints. We experimentally demonstrate that AutoPINN is able to find more accurate PINN models than human-designed, state-of-the-art PINN models using fewer resources.
Joint Neural Architecture and Hyperparameter Search for Correlated Time Series Forecasting
Nov 29, 2022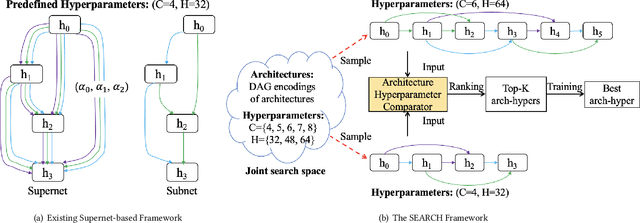



Sensors in cyber-physical systems often capture interconnected processes and thus emit correlated time series (CTS), the forecasting of which enables important applications. The key to successful CTS forecasting is to uncover the temporal dynamics of time series and the spatial correlations among time series. Deep learning-based solutions exhibit impressive performance at discerning these aspects. In particular, automated CTS forecasting, where the design of an optimal deep learning architecture is automated, enables forecasting accuracy that surpasses what has been achieved by manual approaches. However, automated CTS solutions remain in their infancy and are only able to find optimal architectures for predefined hyperparameters and scale poorly to large-scale CTS. To overcome these limitations, we propose SEARCH, a joint, scalable framework, to automatically devise effective CTS forecasting models. Specifically, we encode each candidate architecture and accompanying hyperparameters into a joint graph representation. We introduce an efficient Architecture-Hyperparameter Comparator (AHC) to rank all architecture-hyperparameter pairs, and we then further evaluate the top-ranked pairs to select a final result. Extensive experiments on six benchmark datasets demonstrate that SEARCH not only eliminates manual efforts but also is capable of better performance than manually designed and existing automatically designed CTS models. In addition, it shows excellent scalability to large CTS.
Design Automation for Fast, Lightweight, and Effective Deep Learning Models: A Survey
Aug 22, 2022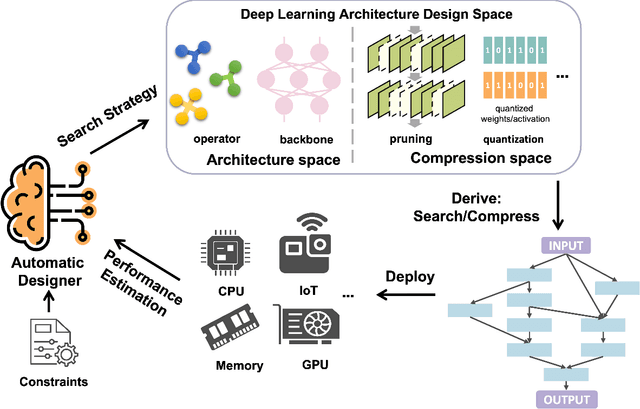
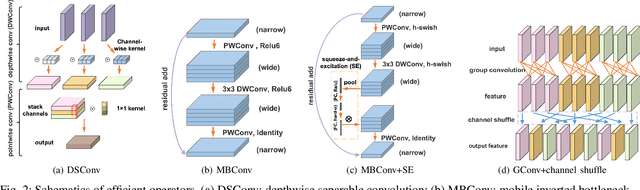
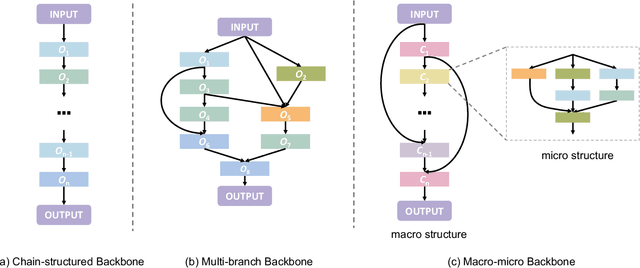
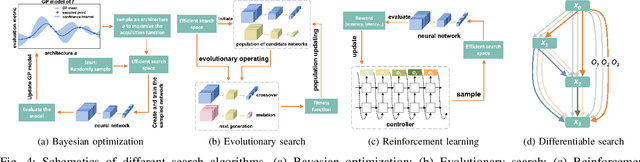
Deep learning technologies have demonstrated remarkable effectiveness in a wide range of tasks, and deep learning holds the potential to advance a multitude of applications, including in edge computing, where deep models are deployed on edge devices to enable instant data processing and response. A key challenge is that while the application of deep models often incurs substantial memory and computational costs, edge devices typically offer only very limited storage and computational capabilities that may vary substantially across devices. These characteristics make it difficult to build deep learning solutions that unleash the potential of edge devices while complying with their constraints. A promising approach to addressing this challenge is to automate the design of effective deep learning models that are lightweight, require only a little storage, and incur only low computational overheads. This survey offers comprehensive coverage of studies of design automation techniques for deep learning models targeting edge computing. It offers an overview and comparison of key metrics that are used commonly to quantify the proficiency of models in terms of effectiveness, lightness, and computational costs. The survey then proceeds to cover three categories of the state-of-the-art of deep model design automation techniques: automated neural architecture search, automated model compression, and joint automated design and compression. Finally, the survey covers open issues and directions for future research.
Uncertainty Quantification for Traffic Forecasting: A Unified Approach
Aug 11, 2022
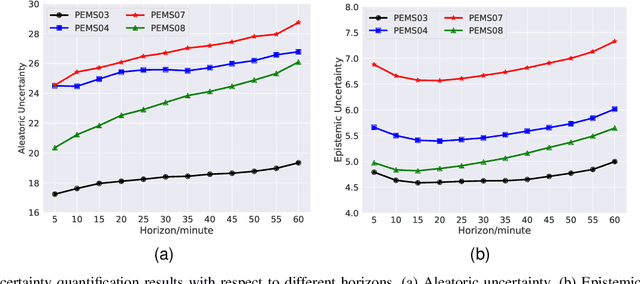
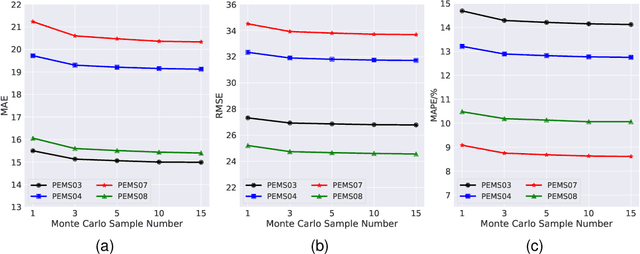
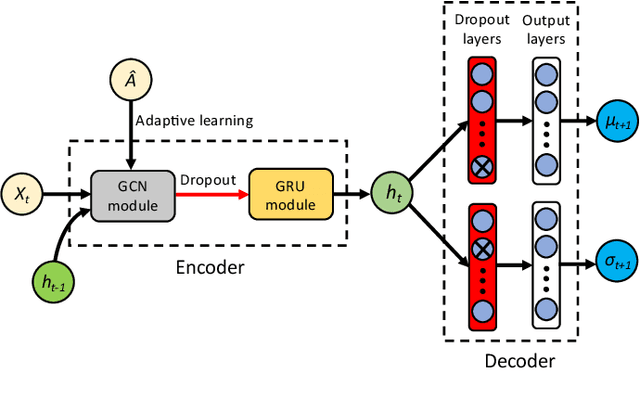
Uncertainty is an essential consideration for time series forecasting tasks. In this work, we specifically focus on quantifying the uncertainty of traffic forecasting. To achieve this, we develop Deep Spatio-Temporal Uncertainty Quantification (DeepSTUQ), which can estimate both aleatoric and epistemic uncertainty. We first leverage a spatio-temporal model to model the complex spatio-temporal correlations of traffic data. Subsequently, two independent sub-neural networks maximizing the heterogeneous log-likelihood are developed to estimate aleatoric uncertainty. For estimating epistemic uncertainty, we combine the merits of variational inference and deep ensembling by integrating the Monte Carlo dropout and the Adaptive Weight Averaging re-training methods, respectively. Finally, we propose a post-processing calibration approach based on Temperature Scaling, which improves the model's generalization ability to estimate uncertainty. Extensive experiments are conducted on four public datasets, and the empirical results suggest that the proposed method outperforms state-of-the-art methods in terms of both point prediction and uncertainty quantification.
AutoCTS: Automated Correlated Time Series Forecasting -- Extended Version
Dec 21, 2021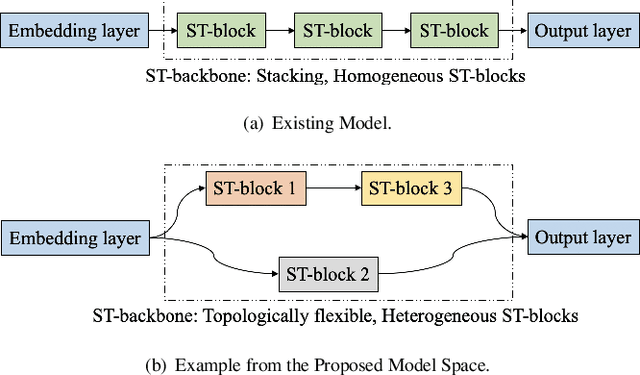
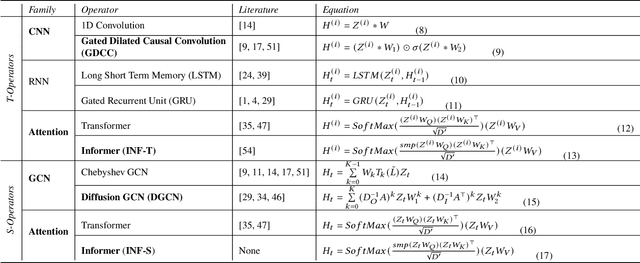
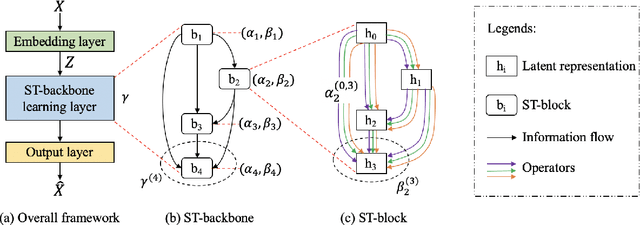

Correlated time series (CTS) forecasting plays an essential role in many cyber-physical systems, where multiple sensors emit time series that capture interconnected processes. Solutions based on deep learning that deliver state-of-the-art CTS forecasting performance employ a variety of spatio-temporal (ST) blocks that are able to model temporal dependencies and spatial correlations among time series. However, two challenges remain. First, ST-blocks are designed manually, which is time consuming and costly. Second, existing forecasting models simply stack the same ST-blocks multiple times, which limits the model potential. To address these challenges, we propose AutoCTS that is able to automatically identify highly competitive ST-blocks as well as forecasting models with heterogeneous ST-blocks connected using diverse topologies, as opposed to the same ST-blocks connected using simple stacking. Specifically, we design both a micro and a macro search space to model possible architectures of ST-blocks and the connections among heterogeneous ST-blocks, and we provide a search strategy that is able to jointly explore the search spaces to identify optimal forecasting models. Extensive experiments on eight commonly used CTS forecasting benchmark datasets justify our design choices and demonstrate that AutoCTS is capable of automatically discovering forecasting models that outperform state-of-the-art human-designed models. This is an extended version of ``AutoCTS: Automated Correlated Time Series Forecasting'', to appear in PVLDB 2022.
Deep Learning for Sensor-based Human Activity Recognition: Overview, Challenges and Opportunities
Jan 21, 2020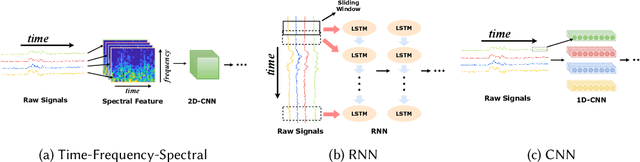
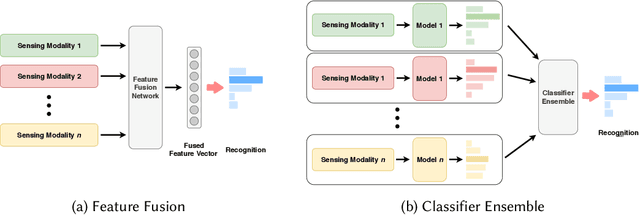
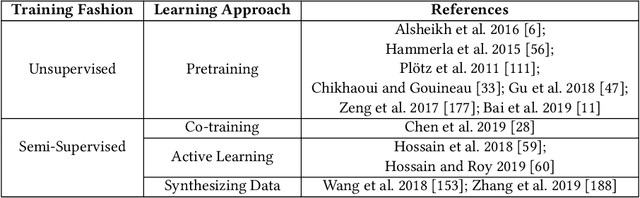
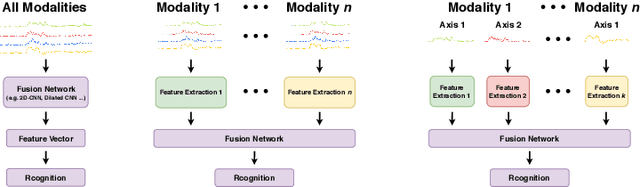
The vast proliferation of sensor devices and Internet of Things enables the applications of sensor-based activity recognition. However, there exist substantial challenges that could influence the performance of the recognition system in practical scenarios. Recently, as deep learning has demonstrated its effectiveness in many areas, plenty of deep methods have been investigated to address the challenges in activity recognition. In this study, we present a survey of the state-of-the-art deep learning methods for sensor-based human activity recognition. We first introduce the multi-modality of the sensory data and provide information for public datasets that can be used for evaluation in different challenge tasks. We then propose a new taxonomy to structure the deep methods by challenges. Challenges and challenge-related deep methods are summarized and analyzed to form an overview of the current research progress. At the end of this work, we discuss the open issues and provide some insights for future directions.
Multi-agent Attentional Activity Recognition
May 22, 2019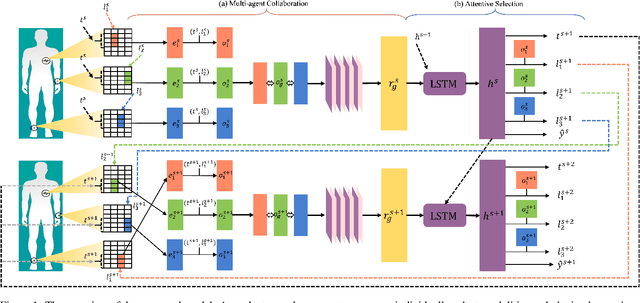
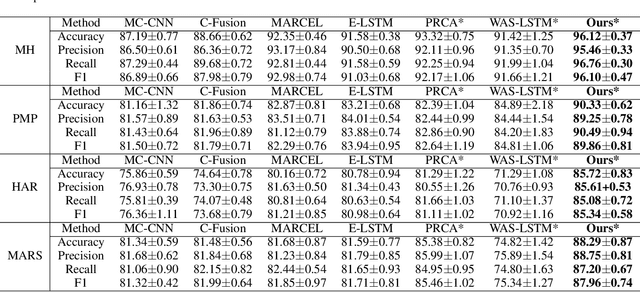
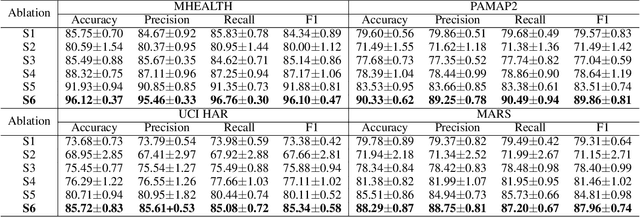
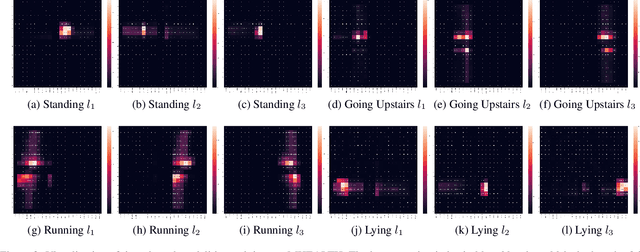
Multi-modality is an important feature of sensor based activity recognition. In this work, we consider two inherent characteristics of human activities, the spatially-temporally varying salience of features and the relations between activities and corresponding body part motions. Based on these, we propose a multi-agent spatial-temporal attention model. The spatial-temporal attention mechanism helps intelligently select informative modalities and their active periods. And the multiple agents in the proposed model represent activities with collective motions across body parts by independently selecting modalities associated with single motions. With a joint recognition goal, the agents share gained information and coordinate their selection policies to learn the optimal recognition model. The experimental results on four real-world datasets demonstrate that the proposed model outperforms the state-of-the-art methods.