 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiao Zhang
QCore: Data-Efficient, On-Device Continual Calibration for Quantized Models -- Extended Version
Apr 22, 2024
We are witnessing an increasing availability of streaming data that may contain valuable information on the underlying processes. It is thus attractive to be able to deploy machine learning models on edge devices near sensors such that decisions can be made instantaneously, rather than first having to transmit incoming data to servers. To enable deployment on edge devices with limited storage and computational capabilities, the full-precision parameters in standard models can be quantized to use fewer bits. The resulting quantized models are then calibrated using back-propagation and full training data to ensure accuracy. This one-time calibration works for deployments in static environments. However, model deployment in dynamic edge environments call for continual calibration to adaptively adjust quantized models to fit new incoming data, which may have different distributions. The first difficulty in enabling continual calibration on the edge is that the full training data may be too large and thus not always available on edge devices. The second difficulty is that the use of back-propagation on the edge for repeated calibration is too expensive. We propose QCore to enable continual calibration on the edge. First, it compresses the full training data into a small subset to enable effective calibration of quantized models with different bit-widths. We also propose means of updating the subset when new streaming data arrives to reflect changes in the environment, while not forgetting earlier training data. Second, we propose a small bit-flipping network that works with the subset to update quantized model parameters, thus enabling efficient continual calibration without back-propagation. An experimental study, conducted with real-world data in a continual learning setting, offers insight into the properties of QCore and shows that it is capable of outperforming strong baseline methods.
GAgent: An Adaptive Rigid-Soft Gripping Agent with Vision Language Models for Complex Lighting Environments
Mar 16, 2024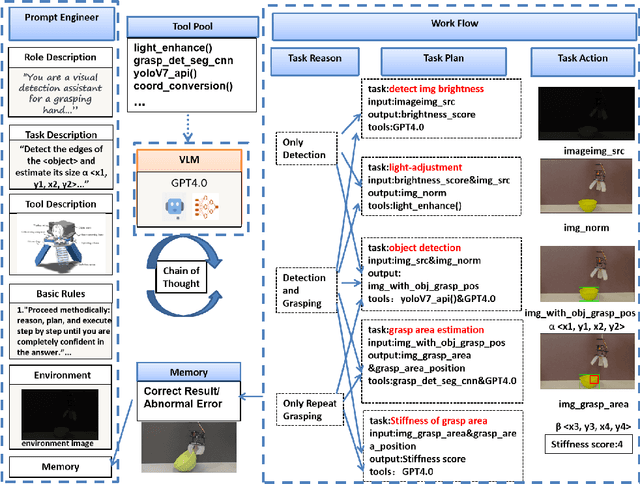

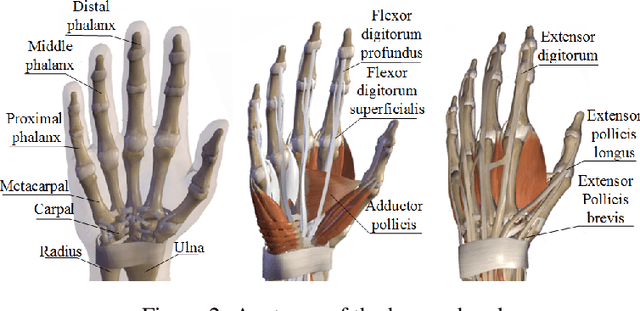
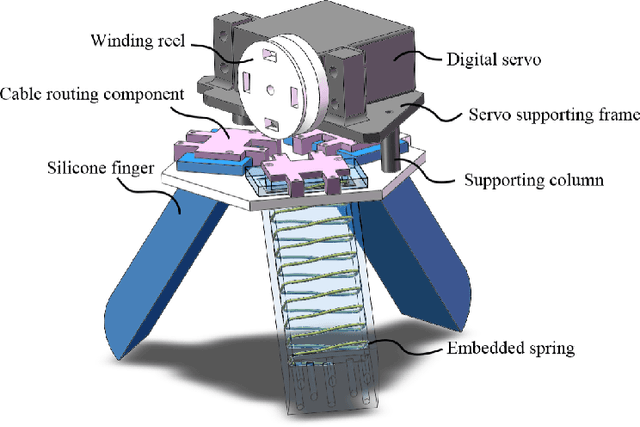
This paper introduces GAgent: an Gripping Agent designed for open-world environments that provides advanced cognitive abilities via VLM agents and flexible grasping abilities with variable stiffness soft grippers. GAgent comprises three primary components - Prompt Engineer module, Visual-Language Model (VLM) core and Workflow module. These three modules enhance gripper success rates by recognizing objects and materials and accurately estimating grasp area even under challenging lighting conditions. As part of creativity, researchers also created a bionic hybrid soft gripper with variable stiffness capable of gripping heavy loads while still gently engaging objects. This intelligent agent, featuring VLM-based cognitive processing with bionic design, shows promise as it could potentially benefit UAVs in various scenarios.
Leveraging CLIP for Inferring Sensitive Information and Improving Model Fairness
Mar 15, 2024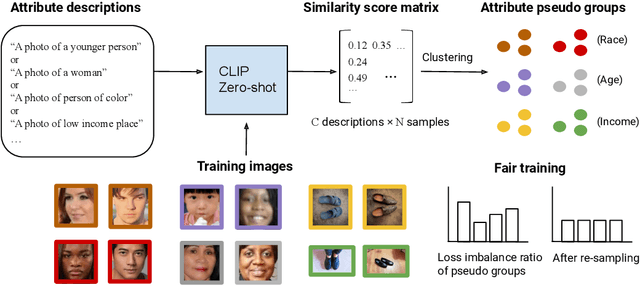

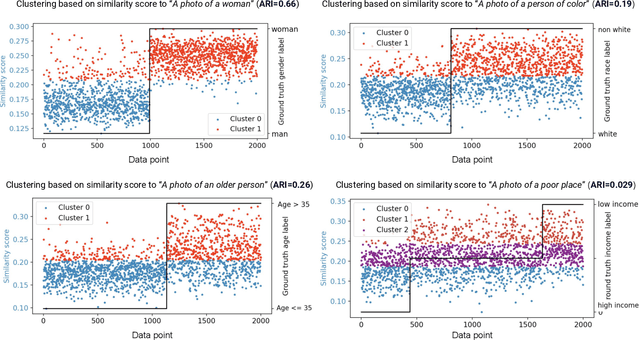

Performance disparities across sub-populations are known to exist in deep learning-based vision recognition models, but previous work has largely addressed such fairness concerns assuming knowledge of sensitive attribute labels. To overcome this reliance, previous strategies have involved separate learning structures to expose and adjust for disparities. In this work, we explore a new paradigm that does not require sensitive attribute labels, and evades the need for extra training by leveraging the vision-language model, CLIP, as a rich knowledge source to infer sensitive information. We present sample clustering based on similarity derived from image and attribute-specified language embeddings and assess their correspondence to true attribute distribution. We train a target model by re-sampling and augmenting under-performed clusters. Extensive experiments on multiple benchmark bias datasets show clear fairness gains of the model over existing baselines, which indicate that CLIP can extract discriminative sensitive information prompted by language, and used to promote model fairness.
Rich Semantic Knowledge Enhanced Large Language Models for Few-shot Chinese Spell Checking
Mar 13, 2024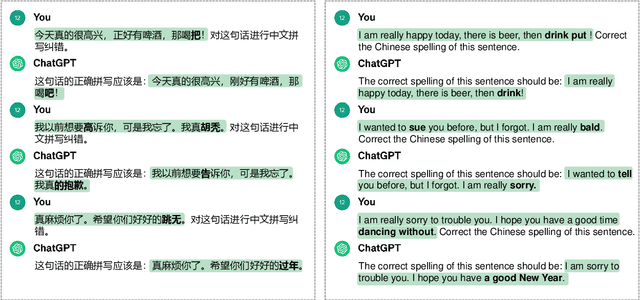
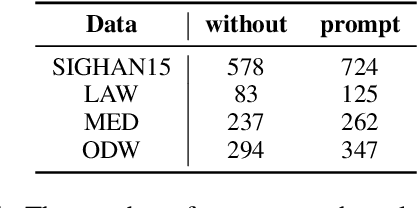
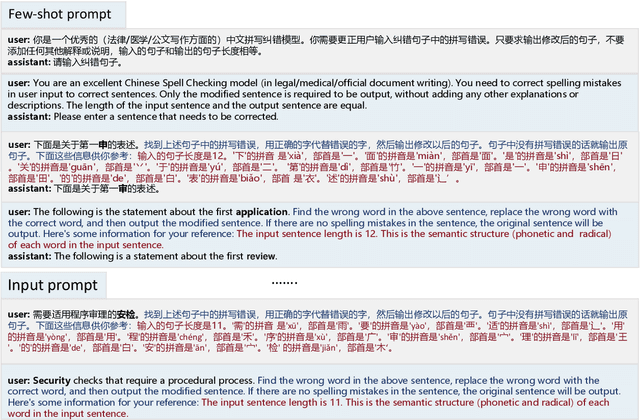
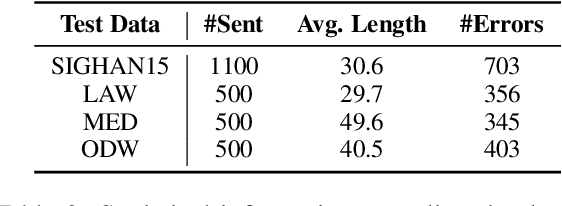
Chinese Spell Checking (CSC) is a widely used technology, which plays a vital role in speech to text (STT) and optical character recognition (OCR). Most of the existing CSC approaches relying on BERT architecture achieve excellent performance. However, limited by the scale of the foundation model, BERT-based method does not work well in few-shot scenarios, showing certain limitations in practical applications. In this paper, we explore using an in-context learning method named RS-LLM (Rich Semantic based LLMs) to introduce large language models (LLMs) as the foundation model. Besides, we study the impact of introducing various Chinese rich semantic information in our framework. We found that by introducing a small number of specific Chinese rich semantic structures, LLMs achieve better performance than the BERT-based model on few-shot CSC task. Furthermore, we conduct experiments on multiple datasets, and the experimental results verified the superiority of our proposed framework.
Impact on Public Health Decision Making by Utilizing Big Data Without Domain Knowledge
Feb 08, 2024New data sources, and artificial intelligence (AI) methods to extract information from them are becoming plentiful, and relevant to decision making in many societal applications. An important example is street view imagery, available in over 100 countries, and considered for applications such as assessing built environment aspects in relation to community health outcomes. Relevant to such uses, important examples of bias in the use of AI are evident when decision-making based on data fails to account for the robustness of the data, or predictions are based on spurious correlations. To study this risk, we utilize 2.02 million GSV images along with health, demographic, and socioeconomic data from New York City. Initially, we demonstrate that built environment characteristics inferred from GSV labels at the intra-city level may exhibit inadequate alignment with the ground truth. We also find that the average individual-level behavior of physical inactivity significantly mediates the impact of built environment features by census tract, as measured through GSV. Finally, using a causal framework which accounts for these mediators of environmental impacts on health, we find that altering 10% of samples in the two lowest tertiles would result in a 4.17 (95% CI 3.84 to 4.55) or 17.2 (95% CI 14.4 to 21.3) times bigger decrease on the prevalence of obesity or diabetes, than the same proportional intervention on the number of crosswalks by census tract. This work illustrates important issues of robustness and model specification for informing effective allocation of interventions using new data sources.
Common-Sense Bias Discovery and Mitigation for Classification Tasks
Feb 08, 2024Machine learning model bias can arise from dataset composition: sensitive features correlated to the learning target disturb the model decision rule and lead to performance differences along the features. Existing de-biasing work captures prominent and delicate image features which are traceable in model latent space, like colors of digits or background of animals. However, using the latent space is not sufficient to understand all dataset feature correlations. In this work, we propose a framework to extract feature clusters in a dataset based on image descriptions, allowing us to capture both subtle and coarse features of the images. The feature co-occurrence pattern is formulated and correlation is measured, utilizing a human-in-the-loop for examination. The analyzed features and correlations are human-interpretable, so we name the method Common-Sense Bias Discovery (CSBD). Having exposed sensitive correlations in a dataset, we demonstrate that downstream model bias can be mitigated by adjusting image sampling weights, without requiring a sensitive group label supervision. Experiments show that our method discovers novel biases on multiple classification tasks for two benchmark image datasets, and the intervention outperforms state-of-the-art unsupervised bias mitigation methods.
Unsupervised Generation of Pseudo Normal PET from MRI with Diffusion Model for Epileptic Focus Localization
Feb 02, 2024[$^{18}$F]fluorodeoxyglucose (FDG) positron emission tomography (PET) has emerged as a crucial tool in identifying the epileptic focus, especially in cases where magnetic resonance imaging (MRI) diagnosis yields indeterminate results. FDG PET can provide the metabolic information of glucose and help identify abnormal areas that are not easily found through MRI. However, the effectiveness of FDG PET-based assessment and diagnosis depends on the selection of a healthy control group. The healthy control group typically consists of healthy individuals similar to epilepsy patients in terms of age, gender, and other aspects for providing normal FDG PET data, which will be used as a reference for enhancing the accuracy and reliability of the epilepsy diagnosis. However, significant challenges arise when a healthy PET control group is unattainable. Yaakub \emph{et al.} have previously introduced a Pix2PixGAN-based method for MRI to PET translation. This method used paired MRI and FDG PET scans from healthy individuals for training, and produced pseudo normal FDG PET images from patient MRIs that are subsequently used for lesion detection. However, this approach requires a large amount of high-quality, paired MRI and PET images from healthy control subjects, which may not always be available. In this study, we investigated unsupervised learning methods for unpaired MRI to PET translation for generating pseudo normal FDG PET for epileptic focus localization. Two deep learning methods, CycleGAN and SynDiff, were employed, and we found that diffusion-based method achieved improved performance in accurately localizing the epileptic focus.
The Risk of Federated Learning to Skew Fine-Tuning Features and Underperform Out-of-Distribution Robustness
Jan 25, 2024To tackle the scarcity and privacy issues associated with domain-specific datasets, the integration of federated learning in conjunction with fine-tuning has emerged as a practical solution. However, our findings reveal that federated learning has the risk of skewing fine-tuning features and compromising the out-of-distribution robustness of the model. By introducing three robustness indicators and conducting experiments across diverse robust datasets, we elucidate these phenomena by scrutinizing the diversity, transferability, and deviation within the model feature space. To mitigate the negative impact of federated learning on model robustness, we introduce GNP, a \underline{G}eneral \underline{N}oisy \underline{P}rojection-based robust algorithm, ensuring no deterioration of accuracy on the target distribution. Specifically, the key strategy for enhancing model robustness entails the transfer of robustness from the pre-trained model to the fine-tuned model, coupled with adding a small amount of Gaussian noise to augment the representative capacity of the model. Comprehensive experimental results demonstrate that our approach markedly enhances the robustness across diverse scenarios, encompassing various parameter-efficient fine-tuning methods and confronting different levels of data heterogeneity.
Generalized Neural Networks for Real-Time Earthquake Early Warning
Dec 23, 2023Deep learning enhances earthquake monitoring capabilities by mining seismic waveforms directly. However, current neural networks, trained within specific areas, face challenges in generalizing to diverse regions. Here, we employ a data recombination method to create generalized earthquakes occurring at any location with arbitrary station distributions for neural network training. The trained models can then be applied to various regions with different monitoring setups for earthquake detection and parameter evaluation from continuous seismic waveform streams. This allows real-time Earthquake Early Warning (EEW) to be initiated at the very early stages of an occurring earthquake. When applied to substantial earthquake sequences across Japan and California (US), our models reliably report earthquake locations and magnitudes within 4 seconds after the first triggered station, with mean errors of 2.6-6.3 km and 0.05-0.17, respectively. These generalized neural networks facilitate global applications of real-time EEW, eliminating complex empirical configurations typically required by traditional methods.
Perception of Misalignment States for Sky Survey Telescopes with the Digital Twin and the Deep Neural Networks
Nov 30, 2023Sky survey telescopes play a critical role in modern astronomy, but misalignment of their optical elements can introduce significant variations in point spread functions, leading to reduced data quality. To address this, we need a method to obtain misalignment states, aiding in the reconstruction of accurate point spread functions for data processing methods or facilitating adjustments of optical components for improved image quality. Since sky survey telescopes consist of many optical elements, they result in a vast array of potential misalignment states, some of which are intricately coupled, posing detection challenges. However, by continuously adjusting the misalignment states of optical elements, we can disentangle coupled states. Based on this principle, we propose a deep neural network to extract misalignment states from continuously varying point spread functions in different field of views. To ensure sufficient and diverse training data, we recommend employing a digital twin to obtain data for neural network training. Additionally, we introduce the state graph to store misalignment data and explore complex relationships between misalignment states and corresponding point spread functions, guiding the generation of training data from experiments. Once trained, the neural network estimates misalignment states from observation data, regardless of the impacts caused by atmospheric turbulence, noise, and limited spatial sampling rates in the detector. The method proposed in this paper could be used to provide prior information for the active optics system and the optical system alignment.