 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRui Sun
Precoder Design for User-Centric Network Massive MIMO with Matrix Manifold Optimization
Apr 11, 2024
In this paper, we investigate the precoder design for user-centric network (UCN) massive multiple-input multiple-output (mMIMO) downlink with matrix manifold optimization. In UCN mMIMO systems, each user terminal (UT) is served by a subset of base stations (BSs) instead of all the BSs, facilitating the implementation of the system and lowering the dimension of the precoders to be designed. By proving that the precoder set satisfying the per-BS power constraints forms a Riemannian submanifold of a linear product manifold, we transform the constrained precoder design problem in Euclidean space to an unconstrained one on the Riemannian submanifold. Riemannian ingredients, including orthogonal projection, Riemannian gradient, retraction and vector transport, of the problem on the Riemannian submanifold are further derived, with which the Riemannian conjugate gradient (RCG) design method is proposed for solving the unconstrained problem. The proposed method avoids the inverses of large dimensional matrices, which is beneficial in practice. The complexity analyses show the high computational efficiency of RCG precoder design. Simulation results demonstrate the numerical superiority of the proposed precoder design and the high efficiency of the UCN mMIMO system.
Image-to-Image Matching via Foundation Models: A New Perspective for Open-Vocabulary Semantic Segmentation
Mar 30, 2024Open-vocabulary semantic segmentation (OVS) aims to segment images of arbitrary categories specified by class labels or captions. However, most previous best-performing methods, whether pixel grouping methods or region recognition methods, suffer from false matches between image features and category labels. We attribute this to the natural gap between the textual features and visual features. In this work, we rethink how to mitigate false matches from the perspective of image-to-image matching and propose a novel relation-aware intra-modal matching (RIM) framework for OVS based on visual foundation models. RIM achieves robust region classification by firstly constructing diverse image-modal reference features and then matching them with region features based on relation-aware ranking distribution. The proposed RIM enjoys several merits. First, the intra-modal reference features are better aligned, circumventing potential ambiguities that may arise in cross-modal matching. Second, the ranking-based matching process harnesses the structure information implicit in the inter-class relationships, making it more robust than comparing individually. Extensive experiments on three benchmarks demonstrate that RIM outperforms previous state-of-the-art methods by large margins, obtaining a lead of more than 10% in mIoU on PASCAL VOC benchmark.
Modeling Unified Semantic Discourse Structure for High-quality Headline Generation
Mar 23, 2024Headline generation aims to summarize a long document with a short, catchy title that reflects the main idea. This requires accurately capturing the core document semantics, which is challenging due to the lengthy and background information-rich na ture of the texts. In this work, We propose using a unified semantic discourse structure (S3) to represent document semantics, achieved by combining document-level rhetorical structure theory (RST) trees with sentence-level abstract meaning representation (AMR) graphs to construct S3 graphs. The hierarchical composition of sentence, clause, and word intrinsically characterizes the semantic meaning of the overall document. We then develop a headline generation framework, in which the S3 graphs are encoded as contextual features. To consolidate the efficacy of S3 graphs, we further devise a hierarchical structure pruning mechanism to dynamically screen the redundant and nonessential nodes within the graph. Experimental results on two headline generation datasets demonstrate that our method outperforms existing state-of-art methods consistently. Our work can be instructive for a broad range of document modeling tasks, more than headline or summarization generation.
Enhancing Protein Predictive Models via Proteins Data Augmentation: A Benchmark and New Directions
Mar 01, 2024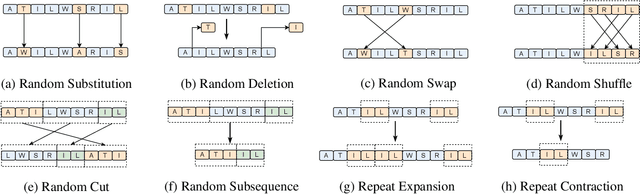
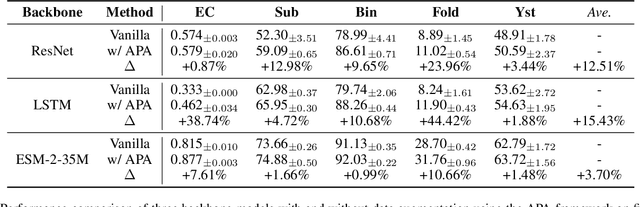
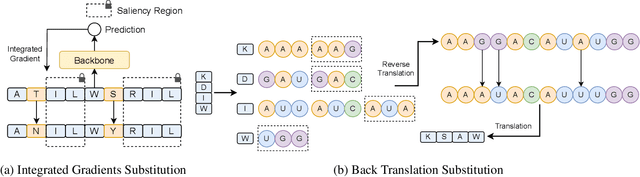
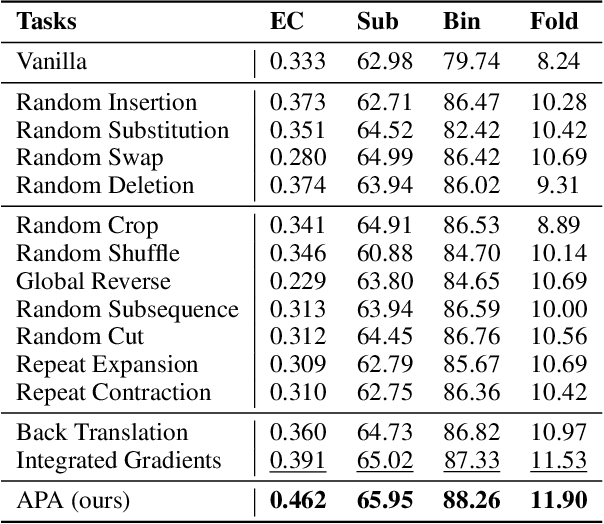
Augmentation is an effective alternative to utilize the small amount of labeled protein data. However, most of the existing work focuses on design-ing new architectures or pre-training tasks, and relatively little work has studied data augmentation for proteins. This paper extends data augmentation techniques previously used for images and texts to proteins and then benchmarks these techniques on a variety of protein-related tasks, providing the first comprehensive evaluation of protein augmentation. Furthermore, we propose two novel semantic-level protein augmentation methods, namely Integrated Gradients Substitution and Back Translation Substitution, which enable protein semantic-aware augmentation through saliency detection and biological knowledge. Finally, we integrate extended and proposed augmentations into an augmentation pool and propose a simple but effective framework, namely Automated Protein Augmentation (APA), which can adaptively select the most suitable augmentation combinations for different tasks. Extensive experiments have shown that APA enhances the performance of five protein related tasks by an average of 10.55% across three architectures compared to vanilla implementations without augmentation, highlighting its potential to make a great impact on the field.
Perception of Misalignment States for Sky Survey Telescopes with the Digital Twin and the Deep Neural Networks
Nov 30, 2023Sky survey telescopes play a critical role in modern astronomy, but misalignment of their optical elements can introduce significant variations in point spread functions, leading to reduced data quality. To address this, we need a method to obtain misalignment states, aiding in the reconstruction of accurate point spread functions for data processing methods or facilitating adjustments of optical components for improved image quality. Since sky survey telescopes consist of many optical elements, they result in a vast array of potential misalignment states, some of which are intricately coupled, posing detection challenges. However, by continuously adjusting the misalignment states of optical elements, we can disentangle coupled states. Based on this principle, we propose a deep neural network to extract misalignment states from continuously varying point spread functions in different field of views. To ensure sufficient and diverse training data, we recommend employing a digital twin to obtain data for neural network training. Additionally, we introduce the state graph to store misalignment data and explore complex relationships between misalignment states and corresponding point spread functions, guiding the generation of training data from experiments. Once trained, the neural network estimates misalignment states from observation data, regardless of the impacts caused by atmospheric turbulence, noise, and limited spatial sampling rates in the detector. The method proposed in this paper could be used to provide prior information for the active optics system and the optical system alignment.
GENOME: GenerativE Neuro-symbOlic visual reasoning by growing and reusing ModulEs
Nov 08, 2023Recent works have shown that Large Language Models (LLMs) could empower traditional neuro-symbolic models via programming capabilities to translate language into module descriptions, thus achieving strong visual reasoning results while maintaining the model's transparency and efficiency. However, these models usually exhaustively generate the entire code snippet given each new instance of a task, which is extremely ineffective. We propose generative neuro-symbolic visual reasoning by growing and reusing modules. Specifically, our model consists of three unique stages, module initialization, module generation, and module execution. First, given a vision-language task, we adopt LLMs to examine whether we could reuse and grow over established modules to handle this new task. If not, we initialize a new module needed by the task and specify the inputs and outputs of this new module. After that, the new module is created by querying LLMs to generate corresponding code snippets that match the requirements. In order to get a better sense of the new module's ability, we treat few-shot training examples as test cases to see if our new module could pass these cases. If yes, the new module is added to the module library for future reuse. Finally, we evaluate the performance of our model on the testing set by executing the parsed programs with the newly made visual modules to get the results. We find the proposed model possesses several advantages. First, it performs competitively on standard tasks like visual question answering and referring expression comprehension; Second, the modules learned from one task can be seamlessly transferred to new tasks; Last but not least, it is able to adapt to new visual reasoning tasks by observing a few training examples and reusing modules.
Reverse Chain: A Generic-Rule for LLMs to Master Multi-API Planning
Oct 10, 2023
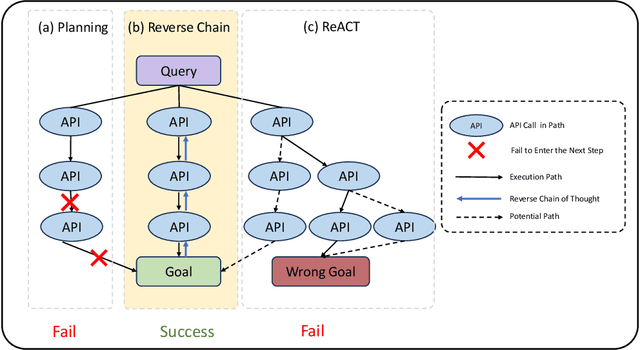

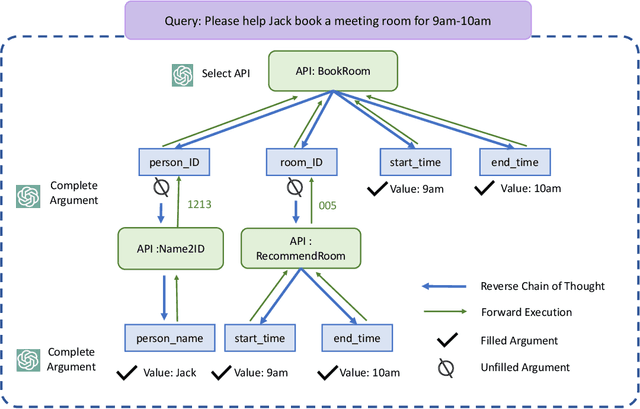
While enabling large language models to implement function calling (known as APIs) can greatly enhance the performance of LLMs, function calling is still a challenging task due to the complicated relations between different APIs, especially in a context-learning setting without fine-tuning. This paper proposes a simple yet controllable target-driven approach called Reverse Chain to empower LLMs with capabilities to use external APIs with only prompts. Given that most open-source LLMs have limited tool-use or tool-plan capabilities, LLMs in Reverse Chain are only employed to implement simple tasks, e.g., API selection and argument completion, and a generic rule is employed to implement a controllable multiple functions calling. In this generic rule, after selecting a final API to handle a given task via LLMs, we first ask LLMs to fill the required arguments from user query and context. Some missing arguments could be further completed by letting LLMs select another API based on API description before asking user. This process continues until a given task is completed. Extensive numerical experiments indicate an impressive capability of Reverse Chain on implementing multiple function calling. Interestingly enough, the experiments also reveal that tool-use capabilities of the existing LLMs, e.g., ChatGPT, can be greatly improved via Reverse Chain.
SafetyBench: Evaluating the Safety of Large Language Models with Multiple Choice Questions
Sep 13, 2023

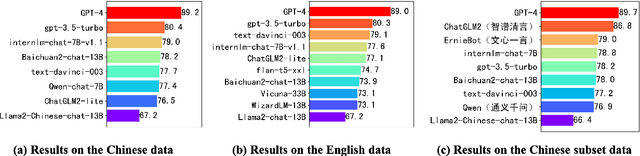
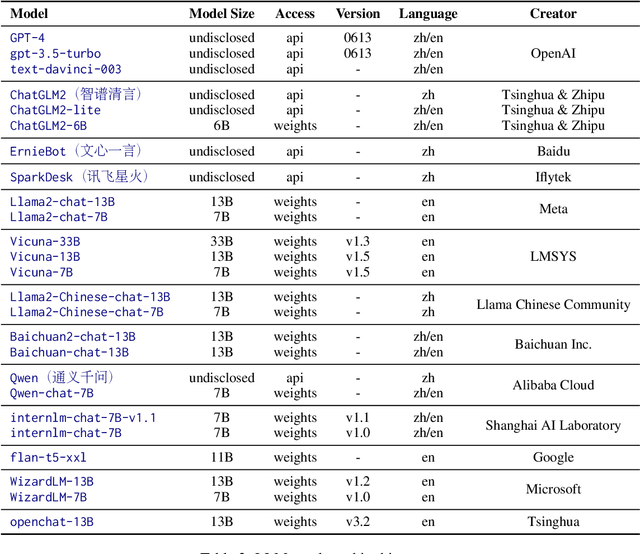
With the rapid development of Large Language Models (LLMs), increasing attention has been paid to their safety concerns. Consequently, evaluating the safety of LLMs has become an essential task for facilitating the broad applications of LLMs. Nevertheless, the absence of comprehensive safety evaluation benchmarks poses a significant impediment to effectively assess and enhance the safety of LLMs. In this work, we present SafetyBench, a comprehensive benchmark for evaluating the safety of LLMs, which comprises 11,435 diverse multiple choice questions spanning across 7 distinct categories of safety concerns. Notably, SafetyBench also incorporates both Chinese and English data, facilitating the evaluation in both languages. Our extensive tests over 25 popular Chinese and English LLMs in both zero-shot and few-shot settings reveal a substantial performance advantage for GPT-4 over its counterparts, and there is still significant room for improving the safety of current LLMs. We believe SafetyBench will enable fast and comprehensive evaluation of LLMs' safety, and foster the development of safer LLMs. Data and evaluation guidelines are available at https://github.com/thu-coai/SafetyBench. Submission entrance and leaderboard are available at https://llmbench.ai/safety.
Kernel-Based Tests for Likelihood-Free Hypothesis Testing
Aug 17, 2023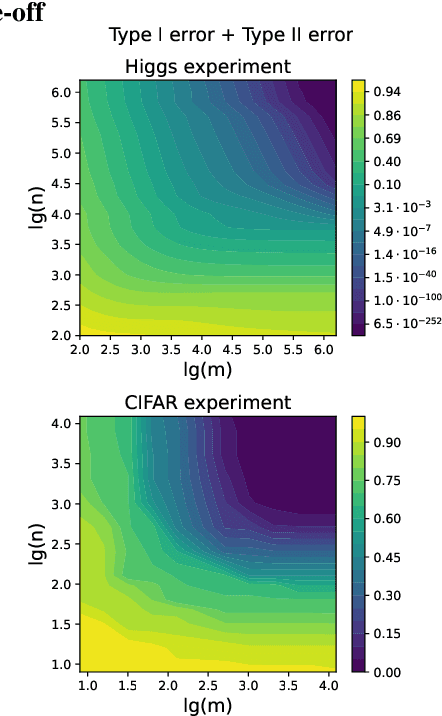
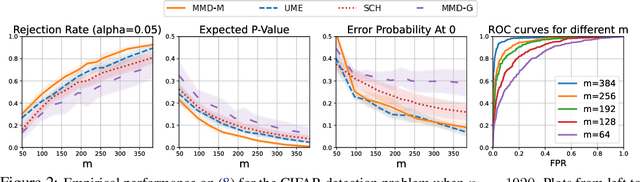
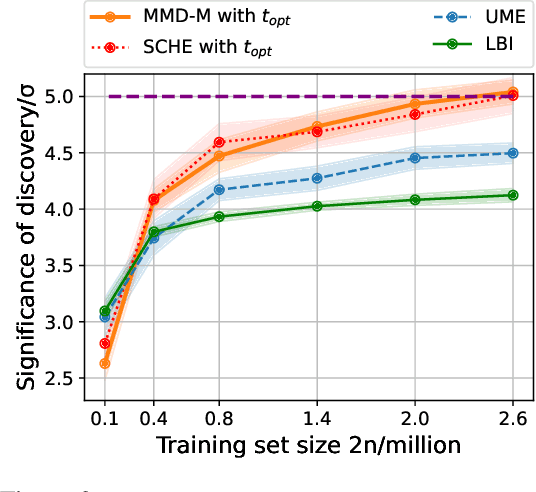

Given $n$ observations from two balanced classes, consider the task of labeling an additional $m$ inputs that are known to all belong to \emph{one} of the two classes. Special cases of this problem are well-known: with complete knowledge of class distributions ($n=\infty$) the problem is solved optimally by the likelihood-ratio test; when $m=1$ it corresponds to binary classification; and when $m\approx n$ it is equivalent to two-sample testing. The intermediate settings occur in the field of likelihood-free inference, where labeled samples are obtained by running forward simulations and the unlabeled sample is collected experimentally. In recent work it was discovered that there is a fundamental trade-off between $m$ and $n$: increasing the data sample $m$ reduces the amount $n$ of training/simulation data needed. In this work we (a) introduce a generalization where unlabeled samples come from a mixture of the two classes -- a case often encountered in practice; (b) study the minimax sample complexity for non-parametric classes of densities under \textit{maximum mean discrepancy} (MMD) separation; and (c) investigate the empirical performance of kernels parameterized by neural networks on two tasks: detection of the Higgs boson and detection of planted DDPM generated images amidst CIFAR-10 images. For both problems we confirm the existence of the theoretically predicted asymmetric $m$ vs $n$ trade-off.
UniFine: A Unified and Fine-grained Approach for Zero-shot Vision-Language Understanding
Jul 03, 2023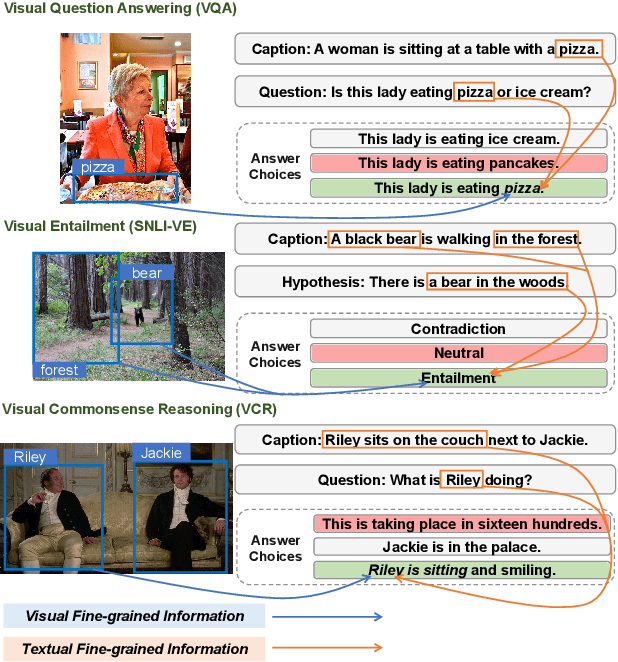
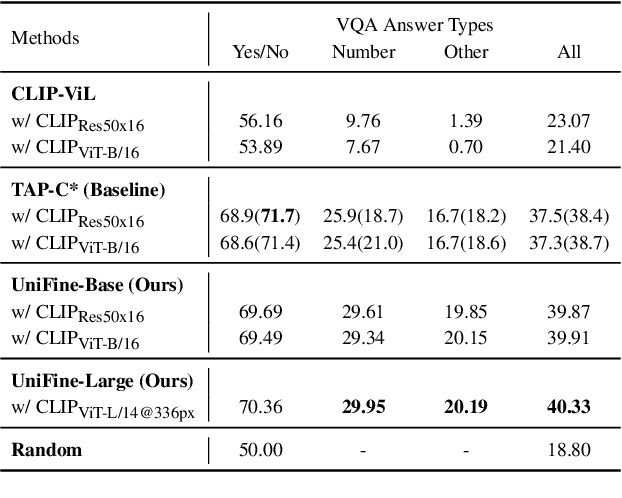

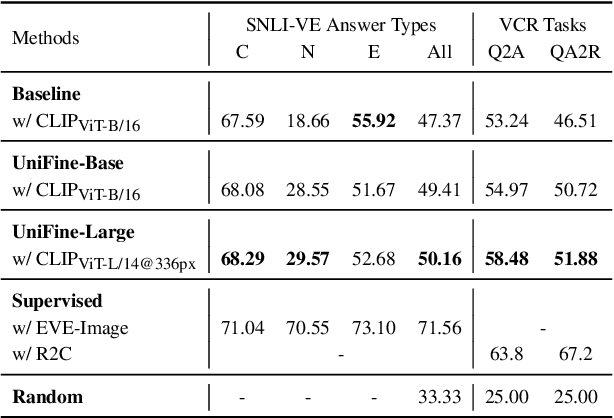
Vision-language tasks, such as VQA, SNLI-VE, and VCR are challenging because they require the model's reasoning ability to understand the semantics of the visual world and natural language. Supervised methods working for vision-language tasks have been well-studied. However, solving these tasks in a zero-shot setting is less explored. Since Contrastive Language-Image Pre-training (CLIP) has shown remarkable zero-shot performance on image-text matching, previous works utilized its strong zero-shot ability by converting vision-language tasks into an image-text matching problem, and they mainly consider global-level matching (e.g., the whole image or sentence). However, we find visual and textual fine-grained information, e.g., keywords in the sentence and objects in the image, can be fairly informative for semantics understanding. Inspired by this, we propose a unified framework to take advantage of the fine-grained information for zero-shot vision-language learning, covering multiple tasks such as VQA, SNLI-VE, and VCR. Our experiments show that our framework outperforms former zero-shot methods on VQA and achieves substantial improvement on SNLI-VE and VCR. Furthermore, our ablation studies confirm the effectiveness and generalizability of our proposed method. Code will be available at https://github.com/ThreeSR/UniFine