 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDonghong Ji
Modeling Unified Semantic Discourse Structure for High-quality Headline Generation
Mar 23, 2024
Headline generation aims to summarize a long document with a short, catchy title that reflects the main idea. This requires accurately capturing the core document semantics, which is challenging due to the lengthy and background information-rich na ture of the texts. In this work, We propose using a unified semantic discourse structure (S3) to represent document semantics, achieved by combining document-level rhetorical structure theory (RST) trees with sentence-level abstract meaning representation (AMR) graphs to construct S3 graphs. The hierarchical composition of sentence, clause, and word intrinsically characterizes the semantic meaning of the overall document. We then develop a headline generation framework, in which the S3 graphs are encoded as contextual features. To consolidate the efficacy of S3 graphs, we further devise a hierarchical structure pruning mechanism to dynamically screen the redundant and nonessential nodes within the graph. Experimental results on two headline generation datasets demonstrate that our method outperforms existing state-of-art methods consistently. Our work can be instructive for a broad range of document modeling tasks, more than headline or summarization generation.
CMNER: A Chinese Multimodal NER Dataset based on Social Media
Mar 01, 2024Multimodal Named Entity Recognition (MNER) is a pivotal task designed to extract named entities from text with the support of pertinent images. Nonetheless, a notable paucity of data for Chinese MNER has considerably impeded the progress of this natural language processing task within the Chinese domain. Consequently, in this study, we compile a Chinese Multimodal NER dataset (CMNER) utilizing data sourced from Weibo, China's largest social media platform. Our dataset encompasses 5,000 Weibo posts paired with 18,326 corresponding images. The entities are classified into four distinct categories: person, location, organization, and miscellaneous. We perform baseline experiments on CMNER, and the outcomes underscore the effectiveness of incorporating images for NER. Furthermore, we conduct cross-lingual experiments on the publicly available English MNER dataset (Twitter2015), and the results substantiate our hypothesis that Chinese and English multimodal NER data can mutually enhance the performance of the NER model.
Reverse Multi-Choice Dialogue Commonsense Inference with Graph-of-Thought
Dec 27, 2023With the proliferation of dialogic data across the Internet, the Dialogue Commonsense Multi-choice Question Answering (DC-MCQ) task has emerged as a response to the challenge of comprehending user queries and intentions. Although prevailing methodologies exhibit effectiveness in addressing single-choice questions, they encounter difficulties in handling multi-choice queries due to the heightened intricacy and informational density. In this paper, inspired by the human cognitive process of progressively excluding options, we propose a three-step Reverse Exclusion Graph-of-Thought (ReX-GoT) framework, including Option Exclusion, Error Analysis, and Combine Information. Specifically, our ReX-GoT mimics human reasoning by gradually excluding irrelevant options and learning the reasons for option errors to choose the optimal path of the GoT and ultimately infer the correct answer. By progressively integrating intricate clues, our method effectively reduces the difficulty of multi-choice reasoning and provides a novel solution for DC-MCQ. Extensive experiments on the CICERO and CICERO$_{v2}$ datasets validate the significant improvement of our approach on DC-MCQ task. On zero-shot setting, our model outperform the best baseline by 17.67% in terms of F1 score for the multi-choice task. Most strikingly, our GPT3.5-based ReX-GoT framework achieves a remarkable 39.44% increase in F1 score.
Compositional Generalization for Multi-label Text Classification: A Data-Augmentation Approach
Dec 20, 2023Despite significant advancements in multi-label text classification, the ability of existing models to generalize to novel and seldom-encountered complex concepts, which are compositions of elementary ones, remains underexplored. This research addresses this gap. By creating unique data splits across three benchmarks, we assess the compositional generalization ability of existing multi-label text classification models. Our results show that these models often fail to generalize to compositional concepts encountered infrequently during training, leading to inferior performance on tests with these new combinations. To address this, we introduce a data augmentation method that leverages two innovative text generation models designed to enhance the classification models' capacity for compositional generalization. Our experiments show that this data augmentation approach significantly improves the compositional generalization capabilities of classification models on our benchmarks, with both generation models surpassing other text generation baselines.
Revisiting Disentanglement and Fusion on Modality and Context in Conversational Multimodal Emotion Recognition
Aug 12, 2023
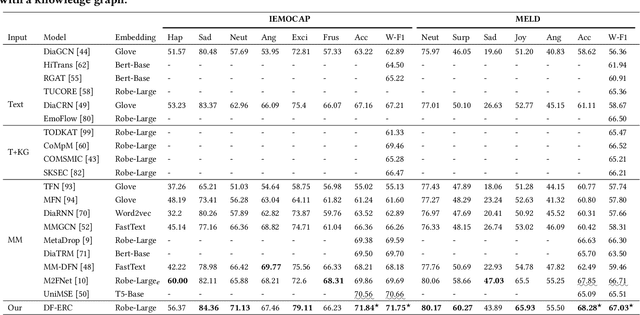
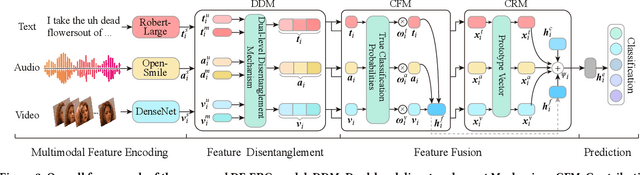
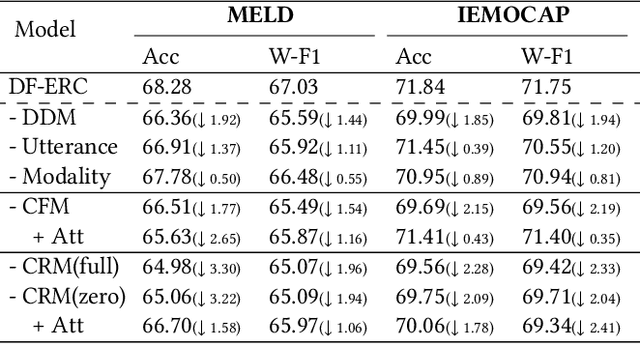
It has been a hot research topic to enable machines to understand human emotions in multimodal contexts under dialogue scenarios, which is tasked with multimodal emotion analysis in conversation (MM-ERC). MM-ERC has received consistent attention in recent years, where a diverse range of methods has been proposed for securing better task performance. Most existing works treat MM-ERC as a standard multimodal classification problem and perform multimodal feature disentanglement and fusion for maximizing feature utility. Yet after revisiting the characteristic of MM-ERC, we argue that both the feature multimodality and conversational contextualization should be properly modeled simultaneously during the feature disentanglement and fusion steps. In this work, we target further pushing the task performance by taking full consideration of the above insights. On the one hand, during feature disentanglement, based on the contrastive learning technique, we devise a Dual-level Disentanglement Mechanism (DDM) to decouple the features into both the modality space and utterance space. On the other hand, during the feature fusion stage, we propose a Contribution-aware Fusion Mechanism (CFM) and a Context Refusion Mechanism (CRM) for multimodal and context integration, respectively. They together schedule the proper integrations of multimodal and context features. Specifically, CFM explicitly manages the multimodal feature contributions dynamically, while CRM flexibly coordinates the introduction of dialogue contexts. On two public MM-ERC datasets, our system achieves new state-of-the-art performance consistently. Further analyses demonstrate that all our proposed mechanisms greatly facilitate the MM-ERC task by making full use of the multimodal and context features adaptively. Note that our proposed methods have the great potential to facilitate a broader range of other conversational multimodal tasks.
A Bi-directional Multi-hop Inference Model for Joint Dialog Sentiment Classification and Act Recognition
Aug 12, 2023
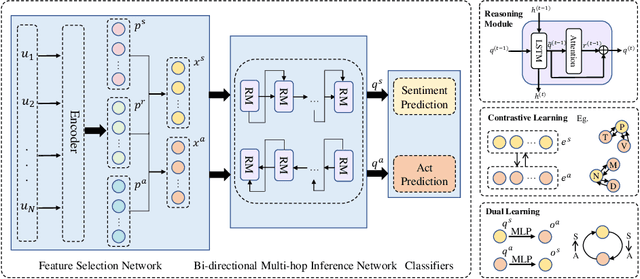
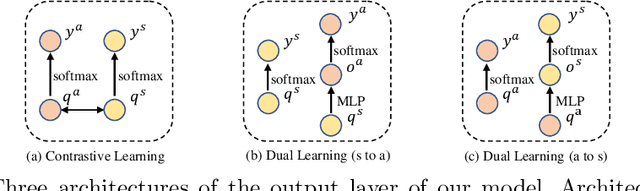
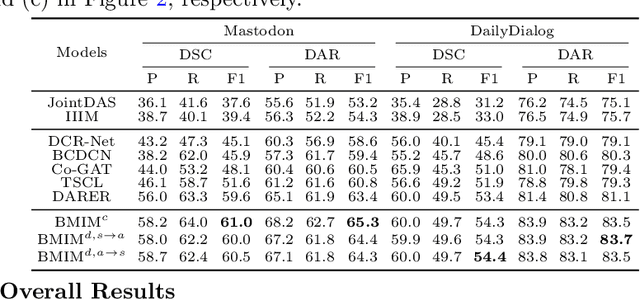
The joint task of Dialog Sentiment Classification (DSC) and Act Recognition (DAR) aims to predict the sentiment label and act label for each utterance in a dialog simultaneously. However, current methods encode the dialog context in only one direction, which limits their ability to thoroughly comprehend the context. Moreover, these methods overlook the explicit correlations between sentiment and act labels, which leads to an insufficient ability to capture rich sentiment and act clues and hinders effective and accurate reasoning. To address these issues, we propose a Bi-directional Multi-hop Inference Model (BMIM) that leverages a feature selection network and a bi-directional multi-hop inference network to iteratively extract and integrate rich sentiment and act clues in a bi-directional manner. We also employ contrastive learning and dual learning to explicitly model the correlations of sentiment and act labels. Our experiments on two widely-used datasets show that BMIM outperforms state-of-the-art baselines by at least 2.6% on F1 score in DAR and 1.4% on F1 score in DSC. Additionally, Our proposed model not only improves the performance but also enhances the interpretability of the joint sentiment and act prediction task.
DialogRE^C+: An Extension of DialogRE to Investigate How Much Coreference Helps Relation Extraction in Dialogs
Aug 12, 2023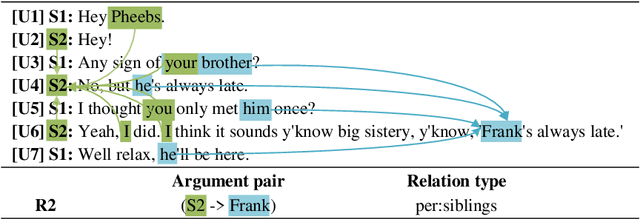
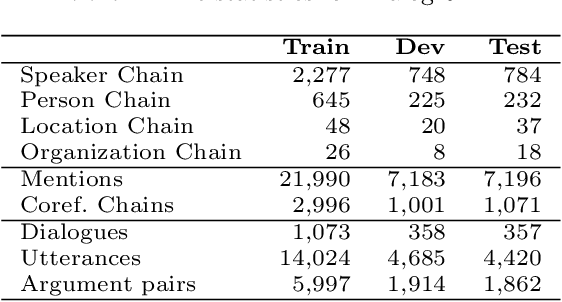

Dialogue relation extraction (DRE) that identifies the relations between argument pairs in dialogue text, suffers much from the frequent occurrence of personal pronouns, or entity and speaker coreference. This work introduces a new benchmark dataset DialogRE^C+, introducing coreference resolution into the DRE scenario. With the aid of high-quality coreference knowledge, the reasoning of argument relations is expected to be enhanced. In DialogRE^C+ dataset, we manually annotate total 5,068 coreference chains over 36,369 argument mentions based on the existing DialogRE data, where four different coreference chain types namely speaker chain, person chain, location chain and organization chain are explicitly marked. We further develop 4 coreference-enhanced graph-based DRE models, which learn effective coreference representations for improving the DRE task. We also train a coreference resolution model based on our annotations and evaluate the effect of automatically extracted coreference chains demonstrating the practicality of our dataset and its potential to other domains and tasks.
TKDP: Threefold Knowledge-enriched Deep Prompt Tuning for Few-shot Named Entity Recognition
Jun 10, 2023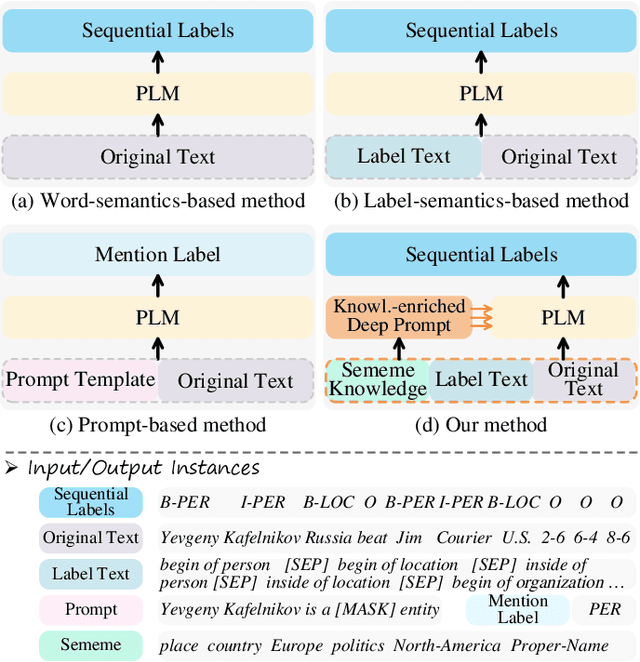

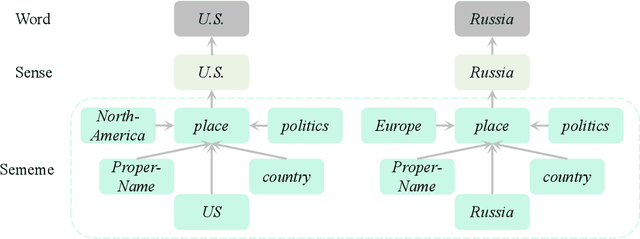
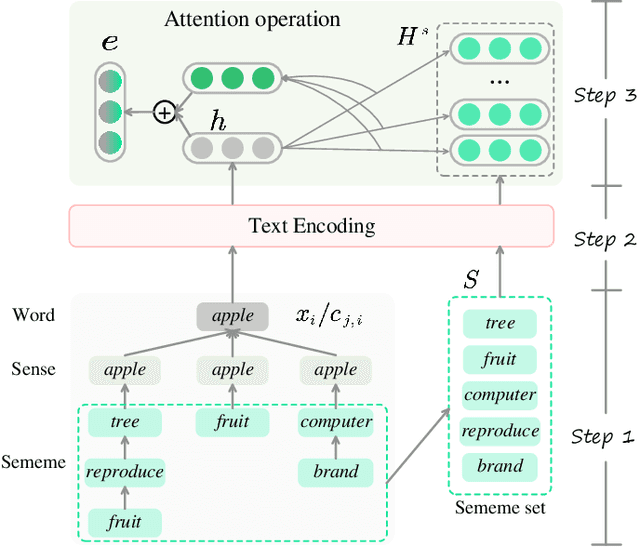
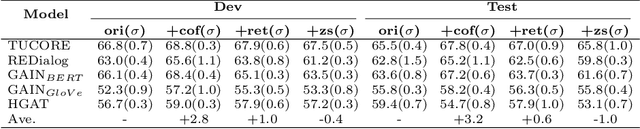
Few-shot named entity recognition (NER) exploits limited annotated instances to identify named mentions. Effectively transferring the internal or external resources thus becomes the key to few-shot NER. While the existing prompt tuning methods have shown remarkable few-shot performances, they still fail to make full use of knowledge. In this work, we investigate the integration of rich knowledge to prompt tuning for stronger few-shot NER. We propose incorporating the deep prompt tuning framework with threefold knowledge (namely TKDP), including the internal 1) context knowledge and the external 2) label knowledge & 3) sememe knowledge. TKDP encodes the three feature sources and incorporates them into the soft prompt embeddings, which are further injected into an existing pre-trained language model to facilitate predictions. On five benchmark datasets, our knowledge-enriched model boosts by at most 11.53% F1 over the raw deep prompt method, and significantly outperforms 8 strong-performing baseline systems in 5-/10-/20-shot settings, showing great potential in few-shot NER. Our TKDP can be broadly adapted to other few-shot tasks without effort.
ECQED: Emotion-Cause Quadruple Extraction in Dialogs
Jun 10, 2023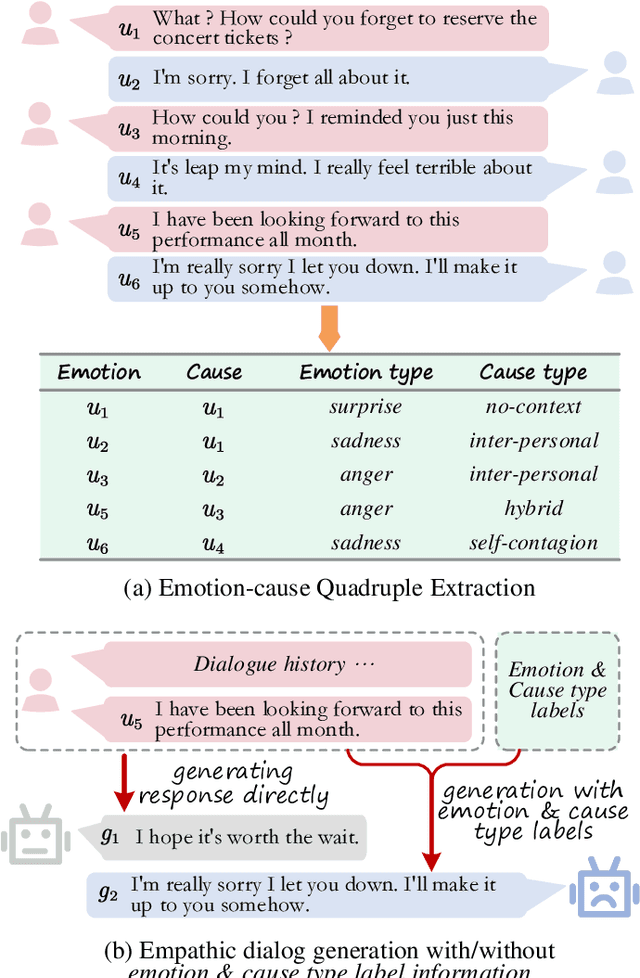
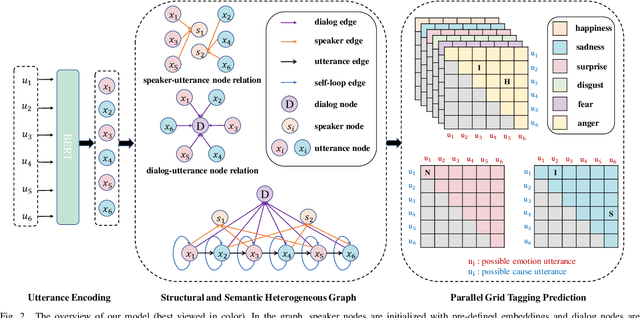
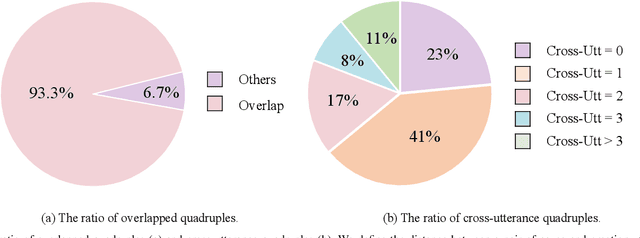
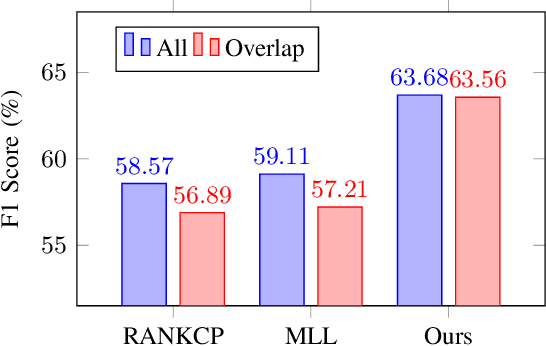
The existing emotion-cause pair extraction (ECPE) task, unfortunately, ignores extracting the emotion type and cause type, while these fine-grained meta-information can be practically useful in real-world applications, i.e., chat robots and empathic dialog generation. Also the current ECPE is limited to the scenario of single text piece, while neglecting the studies at dialog level that should have more realistic values. In this paper, we extend the ECPE task with a broader definition and scenario, presenting a new task, Emotion-Cause Quadruple Extraction in Dialogs (ECQED), which requires detecting emotion-cause utterance pairs and emotion and cause types. We present an ECQED model based on a structural and semantic heterogeneous graph as well as a parallel grid tagging scheme, which advances in effectively incorporating the dialog context structure, meanwhile solving the challenging overlapped quadruple issue. Via experiments we show that introducing the fine-grained emotion and cause features evidently helps better dialog generation. Also our proposed ECQED system shows exceptional superiority over baselines on both the emotion-cause quadruple or pair extraction tasks, meanwhile being highly efficient.
Revisiting Conversation Discourse for Dialogue Disentanglement
Jun 10, 2023
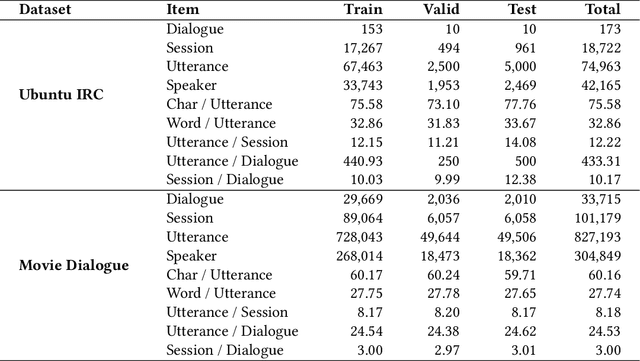
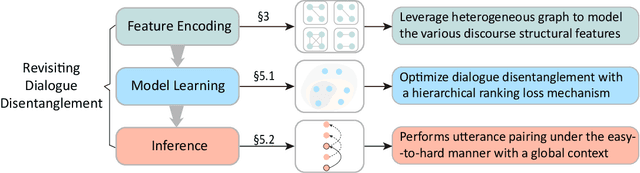

Dialogue disentanglement aims to detach the chronologically ordered utterances into several independent sessions. Conversation utterances are essentially organized and described by the underlying discourse, and thus dialogue disentanglement requires the full understanding and harnessing of the intrinsic discourse attribute. In this paper, we propose enhancing dialogue disentanglement by taking full advantage of the dialogue discourse characteristics. First of all, in feature encoding stage, we construct the heterogeneous graph representations to model the various dialogue-specific discourse structural features, including the static speaker-role structures (i.e., speaker-utterance and speaker-mentioning structure) and the dynamic contextual structures (i.e., the utterance-distance and partial-replying structure). We then develop a structure-aware framework to integrate the rich structural features for better modeling the conversational semantic context. Second, in model learning stage, we perform optimization with a hierarchical ranking loss mechanism, which groups dialogue utterances into different discourse levels and carries training covering pair-wise and session-wise levels hierarchically. Third, in inference stage, we devise an easy-first decoding algorithm, which performs utterance pairing under the easy-to-hard manner with a global context, breaking the constraint of traditional sequential decoding order. On two benchmark datasets, our overall system achieves new state-of-the-art performances on all evaluations. In-depth analyses further demonstrate the efficacy of each proposed idea and also reveal how our methods help advance the task. Our work has great potential to facilitate broader multi-party multi-thread dialogue applications.