 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChristian S. Jensen
A Unified Replay-based Continuous Learning Framework for Spatio-Temporal Prediction on Streaming Data
Apr 23, 2024
The widespread deployment of wireless and mobile devices results in a proliferation of spatio-temporal data that is used in applications, e.g., traffic prediction, human mobility mining, and air quality prediction, where spatio-temporal prediction is often essential to enable safety, predictability, or reliability. Many recent proposals that target deep learning for spatio-temporal prediction suffer from so-called catastrophic forgetting, where previously learned knowledge is entirely forgotten when new data arrives. Such proposals may experience deteriorating prediction performance when applied in settings where data streams into the system. To enable spatio-temporal prediction on streaming data, we propose a unified replay-based continuous learning framework. The framework includes a replay buffer of previously learned samples that are fused with training data using a spatio-temporal mixup mechanism in order to preserve historical knowledge effectively, thus avoiding catastrophic forgetting. To enable holistic representation preservation, the framework also integrates a general spatio-temporal autoencoder with a carefully designed spatio-temporal simple siamese (STSimSiam) network that aims to ensure prediction accuracy and avoid holistic feature loss by means of mutual information maximization. The framework further encompasses five spatio-temporal data augmentation methods to enhance the performance of STSimSiam. Extensive experiments on real data offer insight into the effectiveness of the proposed framework.
QCore: Data-Efficient, On-Device Continual Calibration for Quantized Models -- Extended Version
Apr 22, 2024We are witnessing an increasing availability of streaming data that may contain valuable information on the underlying processes. It is thus attractive to be able to deploy machine learning models on edge devices near sensors such that decisions can be made instantaneously, rather than first having to transmit incoming data to servers. To enable deployment on edge devices with limited storage and computational capabilities, the full-precision parameters in standard models can be quantized to use fewer bits. The resulting quantized models are then calibrated using back-propagation and full training data to ensure accuracy. This one-time calibration works for deployments in static environments. However, model deployment in dynamic edge environments call for continual calibration to adaptively adjust quantized models to fit new incoming data, which may have different distributions. The first difficulty in enabling continual calibration on the edge is that the full training data may be too large and thus not always available on edge devices. The second difficulty is that the use of back-propagation on the edge for repeated calibration is too expensive. We propose QCore to enable continual calibration on the edge. First, it compresses the full training data into a small subset to enable effective calibration of quantized models with different bit-widths. We also propose means of updating the subset when new streaming data arrives to reflect changes in the environment, while not forgetting earlier training data. Second, we propose a small bit-flipping network that works with the subset to update quantized model parameters, thus enabling efficient continual calibration without back-propagation. An experimental study, conducted with real-world data in a continual learning setting, offers insight into the properties of QCore and shows that it is capable of outperforming strong baseline methods.
TFB: Towards Comprehensive and Fair Benchmarking of Time Series Forecasting Methods
Apr 08, 2024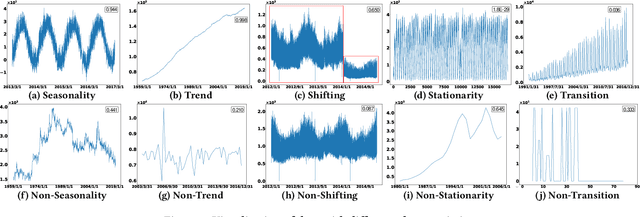
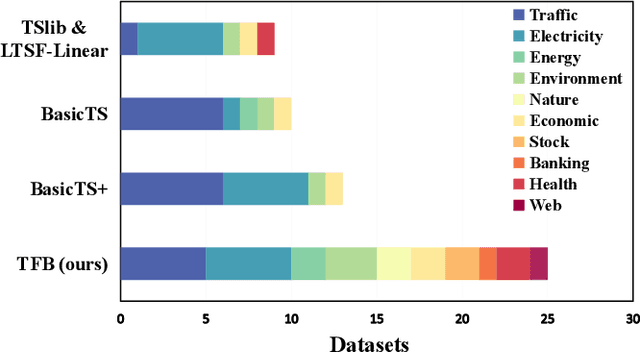

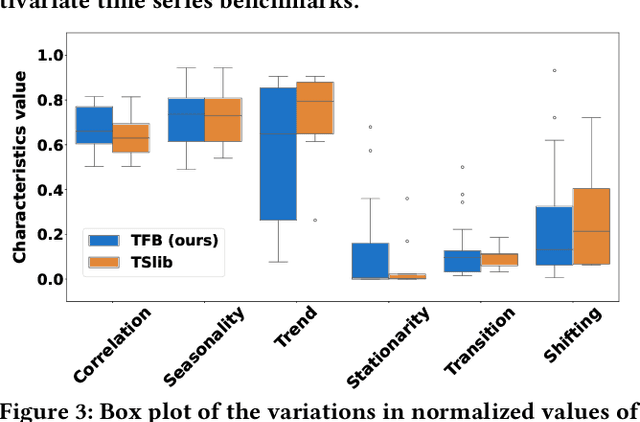
Time series are generated in diverse domains such as economic, traffic, health, and energy, where forecasting of future values has numerous important applications. Not surprisingly, many forecasting methods are being proposed. To ensure progress, it is essential to be able to study and compare such methods empirically in a comprehensive and reliable manner. To achieve this, we propose TFB, an automated benchmark for Time Series Forecasting (TSF) methods. TFB advances the state-of-the-art by addressing shortcomings related to datasets, comparison methods, and evaluation pipelines: 1) insufficient coverage of data domains, 2) stereotype bias against traditional methods, and 3) inconsistent and inflexible pipelines. To achieve better domain coverage, we include datasets from 10 different domains: traffic, electricity, energy, the environment, nature, economic, stock markets, banking, health, and the web. We also provide a time series characterization to ensure that the selected datasets are comprehensive. To remove biases against some methods, we include a diverse range of methods, including statistical learning, machine learning, and deep learning methods, and we also support a variety of evaluation strategies and metrics to ensure a more comprehensive evaluations of different methods. To support the integration of different methods into the benchmark and enable fair comparisons, TFB features a flexible and scalable pipeline that eliminates biases. Next, we employ TFB to perform a thorough evaluation of 21 Univariate Time Series Forecasting (UTSF) methods on 8,068 univariate time series and 14 Multivariate Time Series Forecasting (MTSF) methods on 25 datasets. The benchmark code and data are available at https://github.com/decisionintelligence/TFB.
Graph Augmentation for Recommendation
Mar 25, 2024Graph augmentation with contrastive learning has gained significant attention in the field of recommendation systems due to its ability to learn expressive user representations, even when labeled data is limited. However, directly applying existing GCL models to real-world recommendation environments poses challenges. There are two primary issues to address. Firstly, the lack of consideration for data noise in contrastive learning can result in noisy self-supervised signals, leading to degraded performance. Secondly, many existing GCL approaches rely on graph neural network (GNN) architectures, which can suffer from over-smoothing problems due to non-adaptive message passing. To address these challenges, we propose a principled framework called GraphAug. This framework introduces a robust data augmentor that generates denoised self-supervised signals, enhancing recommender systems. The GraphAug framework incorporates a graph information bottleneck (GIB)-regularized augmentation paradigm, which automatically distills informative self-supervision information and adaptively adjusts contrastive view generation. Through rigorous experimentation on real-world datasets, we thoroughly assessed the performance of our novel GraphAug model. The outcomes consistently unveil its superiority over existing baseline methods. The source code for our model is publicly available at: https://github.com/HKUDS/GraphAug.
* 13 pages and accepted by ICDE 2024
E2USD: Efficient-yet-effective Unsupervised State Detection for Multivariate Time Series
Mar 01, 2024We propose E2USD that enables efficient-yet-accurate unsupervised MTS state detection. E2USD exploits a Fast Fourier Transform-based Time Series Compressor (FFTCompress) and a Decomposed Dual-view Embedding Module (DDEM) that together encode input MTSs at low computational overhead. Additionally, we propose a False Negative Cancellation Contrastive Learning method (FNCCLearning) to counteract the effects of false negatives and to achieve more cluster-friendly embedding spaces. To reduce computational overhead further in streaming settings, we introduce Adaptive Threshold Detection (ADATD). Comprehensive experiments with six baselines and six datasets offer evidence that E2USD is capable of SOTA accuracy at significantly reduced computational overhead. Our code is available at https://github.com/AI4CTS/E2Usd.
GenSTL: General Sparse Trajectory Learning via Auto-regressive Generation of Feature Domains
Feb 11, 2024Trajectories are sequences of timestamped location samples. In sparse trajectories, the locations are sampled infrequently; and while such trajectories are prevalent in real-world settings, they are challenging to use to enable high-quality transportation-related applications. Current methodologies either assume densely sampled and accurately map-matched trajectories, or they rely on two-stage schemes, yielding sub-optimal applications. To extend the utility of sparse trajectories, we propose a novel sparse trajectory learning framework, GenSTL. The framework is pre-trained to form connections between sparse trajectories and dense counterparts using auto-regressive generation of feature domains. GenSTL can subsequently be applied directly in downstream tasks, or it can be fine-tuned first. This way, GenSTL eliminates the reliance on the availability of large-scale dense and map-matched trajectory data. The inclusion of a well-crafted feature domain encoding layer and a hierarchical masked trajectory encoder enhances GenSTL's learning capabilities and adaptability. Experiments on two real-world trajectory datasets offer insight into the framework's ability to contend with sparse trajectories with different sampling intervals and its versatility across different downstream tasks, thus offering evidence of its practicality in real-world applications.
Learning Time-aware Graph Structures for Spatially Correlated Time Series Forecasting
Dec 27, 2023Spatio-temporal forecasting of future values of spatially correlated time series is important across many cyber-physical systems (CPS). Recent studies offer evidence that the use of graph neural networks to capture latent correlations between time series holds a potential for enhanced forecasting. However, most existing methods rely on pre-defined or self-learning graphs, which are either static or unintentionally dynamic, and thus cannot model the time-varying correlations that exhibit trends and periodicities caused by the regularity of the underlying processes in CPS. To tackle such limitation, we propose Time-aware Graph Structure Learning (TagSL), which extracts time-aware correlations among time series by measuring the interaction of node and time representations in high-dimensional spaces. Notably, we introduce time discrepancy learning that utilizes contrastive learning with distance-based regularization terms to constrain learned spatial correlations to a trend sequence. Additionally, we propose a periodic discriminant function to enable the capture of periodic changes from the state of nodes. Next, we present a Graph Convolution-based Gated Recurrent Unit (GCGRU) that jointly captures spatial and temporal dependencies while learning time-aware and node-specific patterns. Finally, we introduce a unified framework named Time-aware Graph Convolutional Recurrent Network (TGCRN), combining TagSL, and GCGRU in an encoder-decoder architecture for multi-step spatio-temporal forecasting. We report on experiments with TGCRN and popular existing approaches on five real-world datasets, thus providing evidence that TGCRN is capable of advancing the state-of-the-art. We also cover a detailed ablation study and visualization analysis, offering detailed insight into the effectiveness of time-aware structure learning.
Missing Value Imputation for Multi-attribute Sensor Data Streams via Message Propagation (Extended Version)
Nov 14, 2023Sensor data streams occur widely in various real-time applications in the context of the Internet of Things (IoT). However, sensor data streams feature missing values due to factors such as sensor failures, communication errors, or depleted batteries. Missing values can compromise the quality of real-time analytics tasks and downstream applications. Existing imputation methods either make strong assumptions about streams or have low efficiency. In this study, we aim to accurately and efficiently impute missing values in data streams that satisfy only general characteristics in order to benefit real-time applications more widely. First, we propose a message propagation imputation network (MPIN) that is able to recover the missing values of data instances in a time window. We give a theoretical analysis of why MPIN is effective. Second, we present a continuous imputation framework that consists of data update and model update mechanisms to enable MPIN to perform continuous imputation both effectively and efficiently. Extensive experiments on multiple real datasets show that MPIN can outperform the existing data imputers by wide margins and that the continuous imputation framework is efficient and accurate.
Exploring Progress in Multivariate Time Series Forecasting: Comprehensive Benchmarking and Heterogeneity Analysis
Oct 09, 2023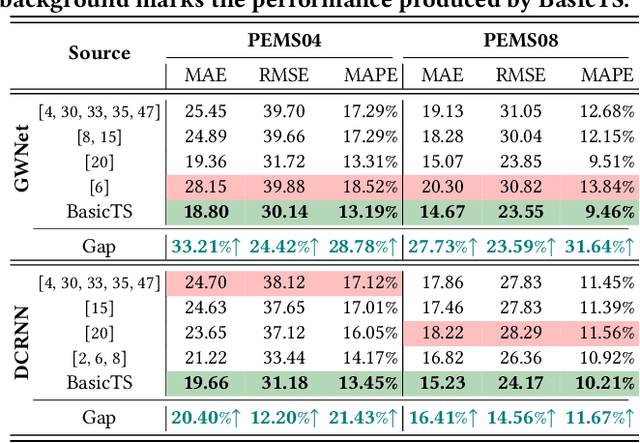
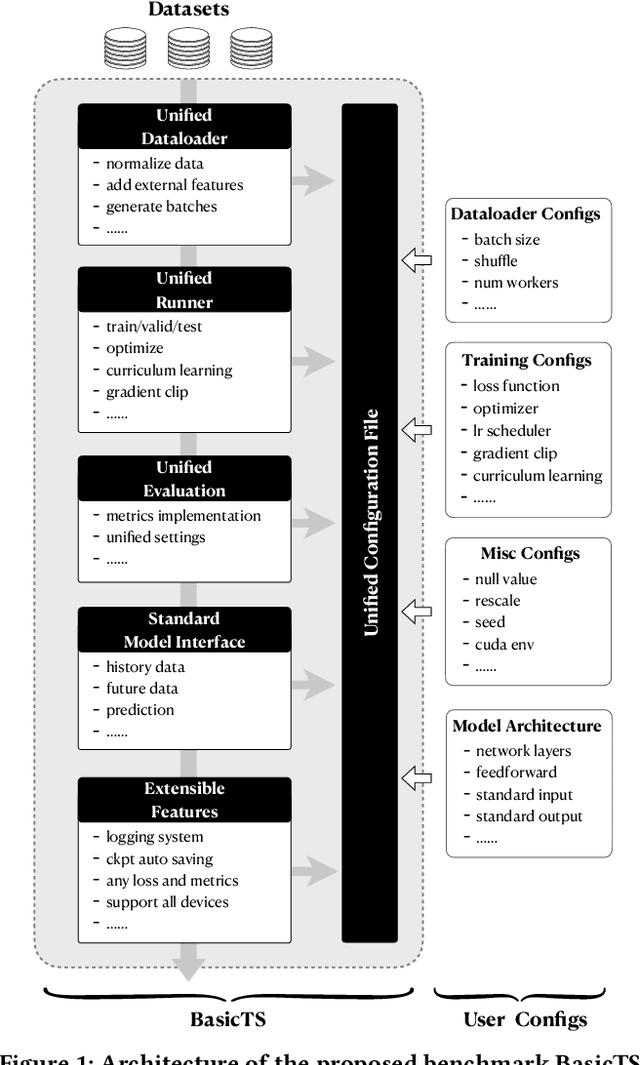
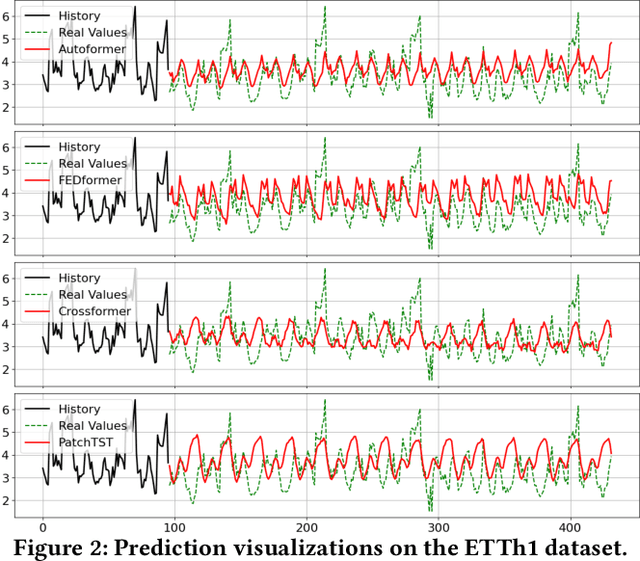
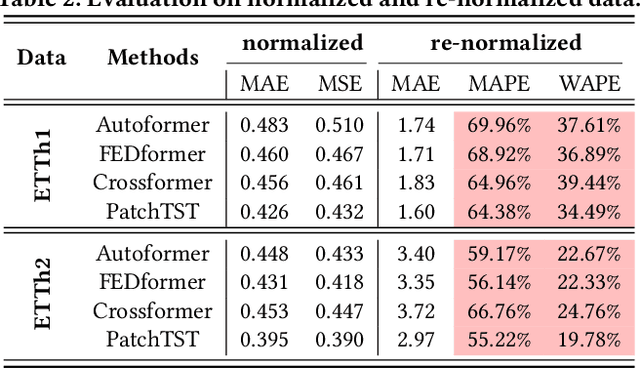
Multivariate Time Series (MTS) widely exists in real-word complex systems, such as traffic and energy systems, making their forecasting crucial for understanding and influencing these systems. Recently, deep learning-based approaches have gained much popularity for effectively modeling temporal and spatial dependencies in MTS, specifically in Long-term Time Series Forecasting (LTSF) and Spatial-Temporal Forecasting (STF). However, the fair benchmarking issue and the choice of technical approaches have been hotly debated in related work. Such controversies significantly hinder our understanding of progress in this field. Thus, this paper aims to address these controversies to present insights into advancements achieved. To resolve benchmarking issues, we introduce BasicTS, a benchmark designed for fair comparisons in MTS forecasting. BasicTS establishes a unified training pipeline and reasonable evaluation settings, enabling an unbiased evaluation of over 30 popular MTS forecasting models on more than 18 datasets. Furthermore, we highlight the heterogeneity among MTS datasets and classify them based on temporal and spatial characteristics. We further prove that neglecting heterogeneity is the primary reason for generating controversies in technical approaches. Moreover, based on the proposed BasicTS and rich heterogeneous MTS datasets, we conduct an exhaustive and reproducible performance and efficiency comparison of popular models, providing insights for researchers in selecting and designing MTS forecasting models.
LightPath: Lightweight and Scalable Path Representation Learning
Jul 19, 2023
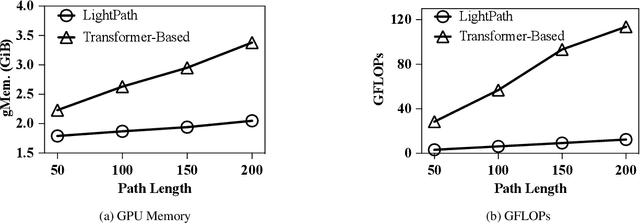
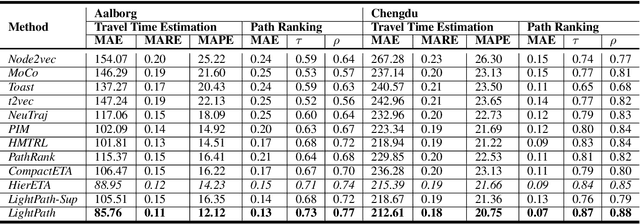
Movement paths are used widely in intelligent transportation and smart city applications. To serve such applications, path representation learning aims to provide compact representations of paths that enable efficient and accurate operations when used for different downstream tasks such as path ranking and travel cost estimation. In many cases, it is attractive that the path representation learning is lightweight and scalable; in resource-limited environments and under green computing limitations, it is essential. Yet, existing path representation learning studies focus on accuracy and pay at most secondary attention to resource consumption and scalability. We propose a lightweight and scalable path representation learning framework, termed LightPath, that aims to reduce resource consumption and achieve scalability without affecting accuracy, thus enabling broader applicability. More specifically, we first propose a sparse auto-encoder that ensures that the framework achieves good scalability with respect to path length. Next, we propose a relational reasoning framework to enable faster training of more robust sparse path encoders. We also propose global-local knowledge distillation to further reduce the size and improve the performance of sparse path encoders. Finally, we report extensive experiments on two real-world datasets to offer insight into the efficiency, scalability, and effectiveness of the proposed framework.