 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiqiang Xu
Hard-Thresholding Meets Evolution Strategies in Reinforcement Learning
May 02, 2024
Evolution Strategies (ES) have emerged as a competitive alternative for model-free reinforcement learning, showcasing exemplary performance in tasks like Mujoco and Atari. Notably, they shine in scenarios with imperfect reward functions, making them invaluable for real-world applications where dense reward signals may be elusive. Yet, an inherent assumption in ES, that all input features are task-relevant, poses challenges, especially when confronted with irrelevant features common in real-world problems. This work scrutinizes this limitation, particularly focusing on the Natural Evolution Strategies (NES) variant. We propose NESHT, a novel approach that integrates Hard-Thresholding (HT) with NES to champion sparsity, ensuring only pertinent features are employed. Backed by rigorous analysis and empirical tests, NESHT demonstrates its promise in mitigating the pitfalls of irrelevant features and shines in complex decision-making problems like noisy Mujoco and Atari tasks.
MIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Learning Time-aware Graph Structures for Spatially Correlated Time Series Forecasting
Dec 27, 2023Spatio-temporal forecasting of future values of spatially correlated time series is important across many cyber-physical systems (CPS). Recent studies offer evidence that the use of graph neural networks to capture latent correlations between time series holds a potential for enhanced forecasting. However, most existing methods rely on pre-defined or self-learning graphs, which are either static or unintentionally dynamic, and thus cannot model the time-varying correlations that exhibit trends and periodicities caused by the regularity of the underlying processes in CPS. To tackle such limitation, we propose Time-aware Graph Structure Learning (TagSL), which extracts time-aware correlations among time series by measuring the interaction of node and time representations in high-dimensional spaces. Notably, we introduce time discrepancy learning that utilizes contrastive learning with distance-based regularization terms to constrain learned spatial correlations to a trend sequence. Additionally, we propose a periodic discriminant function to enable the capture of periodic changes from the state of nodes. Next, we present a Graph Convolution-based Gated Recurrent Unit (GCGRU) that jointly captures spatial and temporal dependencies while learning time-aware and node-specific patterns. Finally, we introduce a unified framework named Time-aware Graph Convolutional Recurrent Network (TGCRN), combining TagSL, and GCGRU in an encoder-decoder architecture for multi-step spatio-temporal forecasting. We report on experiments with TGCRN and popular existing approaches on five real-world datasets, thus providing evidence that TGCRN is capable of advancing the state-of-the-art. We also cover a detailed ablation study and visualization analysis, offering detailed insight into the effectiveness of time-aware structure learning.
Behavior Optimized Image Generation
Nov 18, 2023The last few years have witnessed great success on image generation, which has crossed the acceptance thresholds of aesthetics, making it directly applicable to personal and commercial applications. However, images, especially in marketing and advertising applications, are often created as a means to an end as opposed to just aesthetic concerns. The goal can be increasing sales, getting more clicks, likes, or image sales (in the case of stock businesses). Therefore, the generated images need to perform well on these key performance indicators (KPIs), in addition to being aesthetically good. In this paper, we make the first endeavor to answer the question of "How can one infuse the knowledge of the end-goal within the image generation process itself to create not just better-looking images but also "better-performing'' images?''. We propose BoigLLM, an LLM that understands both image content and user behavior. BoigLLM knows how an image should look to get a certain required KPI. We show that BoigLLM outperforms 13x larger models such as GPT-3.5 and GPT-4 in this task, demonstrating that while these state-of-the-art models can understand images, they lack information on how these images perform in the real world. To generate actual pixels of behavior-conditioned images, we train a diffusion-based model (BoigSD) to align with a proposed BoigLLM-defined reward. We show the performance of the overall pipeline on two datasets covering two different behaviors: a stock dataset with the number of forward actions as the KPI and a dataset containing tweets with the total likes as the KPI, denoted as BoigBench. To advance research in the direction of utility-driven image generation and understanding, we release BoigBench, a benchmark dataset containing 168 million enterprise tweets with their media, brand account names, time of post, and total likes.
SR-R$^2$KAC: Improving Single Image Defocus Deblurring
Jul 30, 2023
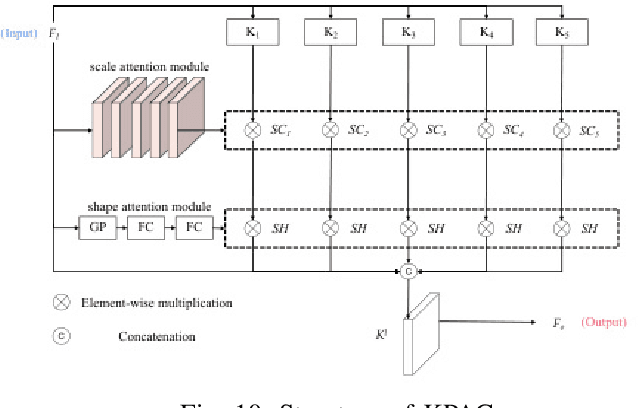


We propose an efficient deep learning method for single image defocus deblurring (SIDD) by further exploring inverse kernel properties. Although the current inverse kernel method, i.e., kernel-sharing parallel atrous convolution (KPAC), can address spatially varying defocus blurs, it has difficulty in handling large blurs of this kind. To tackle this issue, we propose a Residual and Recursive Kernel-sharing Atrous Convolution (R$^2$KAC). R$^2$KAC builds on a significant observation of inverse kernels, that is, successive use of inverse-kernel-based deconvolutions with fixed size helps remove unexpected large blurs but produces ringing artifacts. Specifically, on top of kernel-sharing atrous convolutions used to simulate multi-scale inverse kernels, R$^2$KAC applies atrous convolutions recursively to simulate a large inverse kernel. Specifically, on top of kernel-sharing atrous convolutions, R$^2$KAC stacks atrous convolutions recursively to simulate a large inverse kernel. To further alleviate the contingent effect of recursive stacking, i.e., ringing artifacts, we add identity shortcuts between atrous convolutions to simulate residual deconvolutions. Lastly, a scale recurrent module is embedded in the R$^2$KAC network, leading to SR-R$^2$KAC, so that multi-scale information from coarse to fine is exploited to progressively remove the spatially varying defocus blurs. Extensive experimental results show that our method achieves the state-of-the-art performance.
A Cover Time Study of a non-Markovian Algorithm
Jun 08, 2023



Given a traversal algorithm, cover time is the expected number of steps needed to visit all nodes in a given graph. A smaller cover time means a higher exploration efficiency of traversal algorithm. Although random walk algorithms have been studied extensively in the existing literature, there has been no cover time result for any non-Markovian method. In this work, we stand on a theoretical perspective and show that the negative feedback strategy (a count-based exploration method) is better than the naive random walk search. In particular, the former strategy can locally improve the search efficiency for an arbitrary graph. It also achieves smaller cover times for special but important graphs, including clique graphs, tree graphs, etc. Moreover, we make connections between our results and reinforcement learning literature to give new insights on why classical UCB and MCTS algorithms are so useful. Various numerical results corroborate our theoretical findings.
Label-Retrieval-Augmented Diffusion Models for Learning from Noisy Labels
May 31, 2023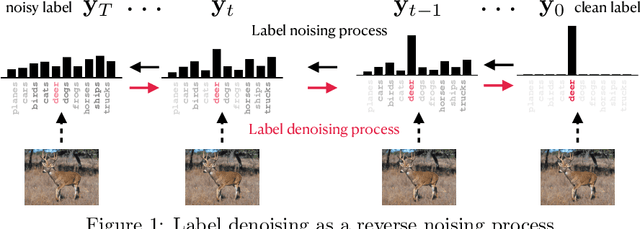
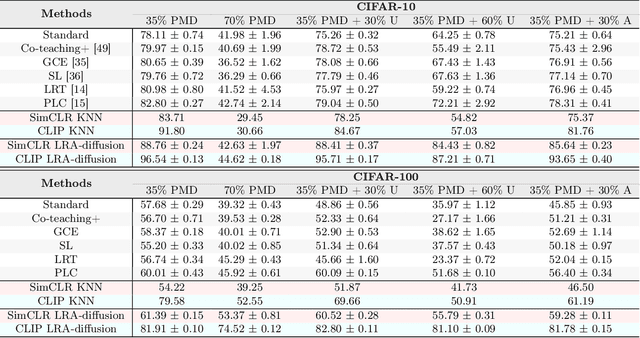
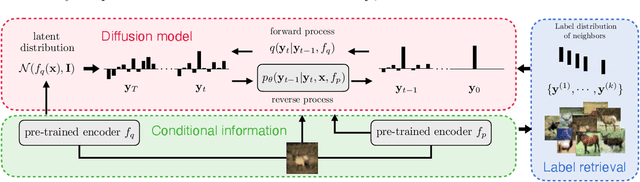
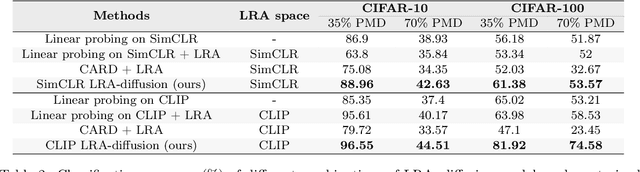
Learning from noisy labels is an important and long-standing problem in machine learning for real applications. One of the main research lines focuses on learning a label corrector to purify potential noisy labels. However, these methods typically rely on strict assumptions and are limited to certain types of label noise. In this paper, we reformulate the label-noise problem from a generative-model perspective, $\textit{i.e.}$, labels are generated by gradually refining an initial random guess. This new perspective immediately enables existing powerful diffusion models to seamlessly learn the stochastic generative process. Once the generative uncertainty is modeled, we can perform classification inference using maximum likelihood estimation of labels. To mitigate the impact of noisy labels, we propose the $\textbf{L}$abel-$\textbf{R}$etrieval-$\textbf{A}$ugmented (LRA) diffusion model, which leverages neighbor consistency to effectively construct pseudo-clean labels for diffusion training. Our model is flexible and general, allowing easy incorporation of different types of conditional information, $\textit{e.g.}$, use of pre-trained models, to further boost model performance. Extensive experiments are conducted for evaluation. Our model achieves new state-of-the-art (SOTA) results on all the standard real-world benchmark datasets. Remarkably, by incorporating conditional information from the powerful CLIP model, our method can boost the current SOTA accuracy by 10-20 absolute points in many cases.
Robust Offline Reinforcement Learning with Gradient Penalty and Constraint Relaxation
Oct 19, 2022



A promising paradigm for offline reinforcement learning (RL) is to constrain the learned policy to stay close to the dataset behaviors, known as policy constraint offline RL. However, existing works heavily rely on the purity of the data, exhibiting performance degradation or even catastrophic failure when learning from contaminated datasets containing impure trajectories of diverse levels. e.g., expert level, medium level, etc., while offline contaminated data logs exist commonly in the real world. To mitigate this, we first introduce gradient penalty over the learned value function to tackle the exploding Q-functions. We then relax the closeness constraints towards non-optimal actions with critic weighted constraint relaxation. Experimental results show that the proposed techniques effectively tame the non-optimal trajectories for policy constraint offline RL methods, evaluated on a set of contaminated D4RL Mujoco and Adroit datasets.
No existence of linear algorithm for Fourier phase retrieval
Sep 13, 2022Fourier phase retrieval, which seeks to reconstruct a signal from its Fourier magnitude, is of fundamental importance in fields of engineering and science. In this paper, we give a theoretical understanding of algorithms for Fourier phase retrieval. Particularly, we show if there exists an algorithm which could reconstruct an arbitrary signal ${\mathbf x}\in {\mathbb C}^N$ in $ \mbox{Poly}(N) \log(1/\epsilon)$ time to reach $\epsilon$-precision from its magnitude of discrete Fourier transform and its initial value $x(0)$, then $\mathcal{ P}=\mathcal{NP}$. This demystifies the phenomenon that, although almost all signals are determined uniquely by their Fourier magnitude with a prior conditions, there is no algorithm with theoretical guarantees being proposed over the past few decades. Our proofs employ the result in computational complexity theory that Product Partition problem is NP-complete in the strong sense.
Unsupervised Video Domain Adaptation: A Disentanglement Perspective
Aug 15, 2022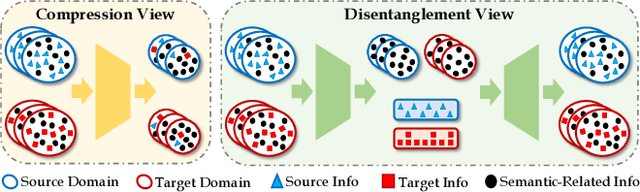

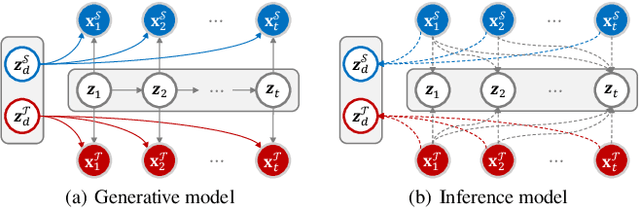
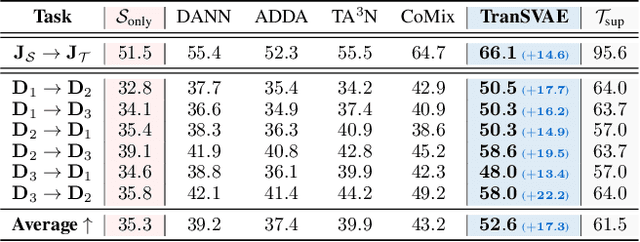
Unsupervised video domain adaptation is a practical yet challenging task. In this work, for the first time, we tackle it from a disentanglement view. Our key idea is to disentangle the domain-related information from the data during the adaptation process. Specifically, we consider the generation of cross-domain videos from two sets of latent factors, one encoding the static domain-related information and another encoding the temporal and semantic-related information. A Transfer Sequential VAE (TranSVAE) framework is then developed to model such generation. To better serve for adaptation, we further propose several objectives to constrain the latent factors in TranSVAE. Extensive experiments on the UCF-HMDB, Jester, and Epic-Kitchens datasets verify the effectiveness and superiority of TranSVAE compared with several state-of-the-art methods. Code is publicly available at https://github.com/ldkong1205/TranSVAE.