 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFei Wang
Cooperative Sentiment Agents for Multimodal Sentiment Analysis
Apr 19, 2024
In this paper, we propose a new Multimodal Representation Learning (MRL) method for Multimodal Sentiment Analysis (MSA), which facilitates the adaptive interaction between modalities through Cooperative Sentiment Agents, named Co-SA. Co-SA comprises two critical components: the Sentiment Agents Establishment (SAE) phase and the Sentiment Agents Cooperation (SAC) phase. During the SAE phase, each sentiment agent deals with an unimodal signal and highlights explicit dynamic sentiment variations within the modality via the Modality-Sentiment Disentanglement (MSD) and Deep Phase Space Reconstruction (DPSR) modules. Subsequently, in the SAC phase, Co-SA meticulously designs task-specific interaction mechanisms for sentiment agents so that coordinating multimodal signals to learn the joint representation. Specifically, Co-SA equips an independent policy model for each sentiment agent that captures significant properties within the modality. These policies are optimized mutually through the unified reward adaptive to downstream tasks. Benefitting from the rewarding mechanism, Co-SA transcends the limitation of pre-defined fusion modes and adaptively captures unimodal properties for MRL in the multimodal interaction setting. To demonstrate the effectiveness of Co-SA, we apply it to address Multimodal Sentiment Analysis (MSA) and Multimodal Emotion Recognition (MER) tasks. Our comprehensive experimental results demonstrate that Co-SA excels at discovering diverse cross-modal features, encompassing both common and complementary aspects. The code can be available at https://github.com/smwanghhh/Co-SA.
Offset Unlearning for Large Language Models
Apr 17, 2024Despite the strong capabilities of Large Language Models (LLMs) to acquire knowledge from their training corpora, the memorization of sensitive information in the corpora such as copyrighted, harmful, and private content has led to ethical and legal concerns. In response to these challenges, unlearning has emerged as a potential remedy for LLMs affected by problematic training data. However, previous unlearning techniques are either not applicable to black-box LLMs due to required access to model internal weights, or violate data protection principles by retaining sensitive data for inference-time correction. We propose $\delta$-unlearning, an offset unlearning framework for black-box LLMs. Instead of tuning the black-box LLM itself, $\delta$-unlearning learns the logit offset needed for unlearning by contrasting the logits from a pair of smaller models. Experiments demonstrate that $\delta$-unlearning can effectively unlearn target data while maintaining similar or even stronger performance on general out-of-forget-scope tasks. $\delta$-unlearning also effectively incorporates different unlearning algorithms, making our approach a versatile solution to adapting various existing unlearning algorithms to black-box LLMs.
HSIDMamba: Exploring Bidirectional State-Space Models for Hyperspectral Denoising
Apr 15, 2024Effectively discerning spatial-spectral dependencies in HSI denoising is crucial, but prevailing methods using convolution or transformers still face computational efficiency limitations. Recently, the emerging Selective State Space Model(Mamba) has risen with its nearly linear computational complexity in processing natural language sequences, which inspired us to explore its potential in handling long spectral sequences. In this paper, we propose HSIDMamba(HSDM), tailored to exploit the linear complexity for effectively capturing spatial-spectral dependencies in HSI denoising. In particular, HSDM comprises multiple Hyperspectral Continuous Scan Blocks, incorporating BCSM(Bidirectional Continuous Scanning Mechanism), scale residual, and spectral attention mechanisms to enhance the capture of long-range and local spatial-spectral information. BCSM strengthens spatial-spectral interactions by linking forward and backward scans and enhancing information from eight directions through SSM, significantly enhancing the perceptual capability of HSDM and improving denoising performance more effectively. Extensive evaluations against HSI denoising benchmarks validate the superior performance of HSDM, achieving state-of-the-art results in performance and surpassing the efficiency of the latest transformer architectures by $30\%$.
FraGNNet: A Deep Probabilistic Model for Mass Spectrum Prediction
Apr 02, 2024The process of identifying a compound from its mass spectrum is a critical step in the analysis of complex mixtures. Typical solutions for the mass spectrum to compound (MS2C) problem involve matching the unknown spectrum against a library of known spectrum-molecule pairs, an approach that is limited by incomplete library coverage. Compound to mass spectrum (C2MS) models can improve retrieval rates by augmenting real libraries with predicted spectra. Unfortunately, many existing C2MS models suffer from problems with prediction resolution, scalability, or interpretability. We develop a new probabilistic method for C2MS prediction, FraGNNet, that can efficiently and accurately predict high-resolution spectra. FraGNNet uses a structured latent space to provide insight into the underlying processes that define the spectrum. Our model achieves state-of-the-art performance in terms of prediction error, and surpasses existing C2MS models as a tool for retrieval-based MS2C.
Self-Improvement Programming for Temporal Knowledge Graph Question Answering
Apr 02, 2024Temporal Knowledge Graph Question Answering (TKGQA) aims to answer questions with temporal intent over Temporal Knowledge Graphs (TKGs). The core challenge of this task lies in understanding the complex semantic information regarding multiple types of time constraints (e.g., before, first) in questions. Existing end-to-end methods implicitly model the time constraints by learning time-aware embeddings of questions and candidate answers, which is far from understanding the question comprehensively. Motivated by semantic-parsing-based approaches that explicitly model constraints in questions by generating logical forms with symbolic operators, we design fundamental temporal operators for time constraints and introduce a novel self-improvement Programming method for TKGQA (Prog-TQA). Specifically, Prog-TQA leverages the in-context learning ability of Large Language Models (LLMs) to understand the combinatory time constraints in the questions and generate corresponding program drafts with a few examples given. Then, it aligns these drafts to TKGs with the linking module and subsequently executes them to generate the answers. To enhance the ability to understand questions, Prog-TQA is further equipped with a self-improvement strategy to effectively bootstrap LLMs using high-quality self-generated drafts. Extensive experiments demonstrate the superiority of the proposed Prog-TQA on MultiTQ and CronQuestions datasets, especially in the Hits@1 metric.
Monotonic Paraphrasing Improves Generalization of Language Model Prompting
Mar 24, 2024Performance of large language models (LLMs) may vary with different prompts or instructions of even the same task. One commonly recognized factor for this phenomenon is the model's familiarity with the given prompt or instruction, which is typically estimated by its perplexity. However, finding the prompt with the lowest perplexity is challenging, given the enormous space of possible prompting phrases. In this paper, we propose monotonic paraphrasing (MonoPara), an end-to-end decoding strategy that paraphrases given prompts or instructions into their lower perplexity counterparts based on an ensemble of a paraphrase LM for prompt (or instruction) rewriting, and a target LM (i.e. the prompt or instruction executor) that constrains the generation for lower perplexity. The ensemble decoding process can efficiently paraphrase the original prompt without altering its semantic meaning, while monotonically decreasing the perplexity of each generation as calculated by the target LM. We explore in detail both greedy and search-based decoding as two alternative decoding schemes of MonoPara. Notably, MonoPara does not require any training and can monotonically lower the perplexity of the paraphrased prompt or instruction, leading to improved performance of zero-shot LM prompting as evaluated on a wide selection of tasks. In addition, MonoPara is also shown to effectively improve LMs' generalization on perturbed and unseen task instructions.
Training Small Multimodal Models to Bridge Biomedical Competency Gap: A Case Study in Radiology Imaging
Mar 20, 2024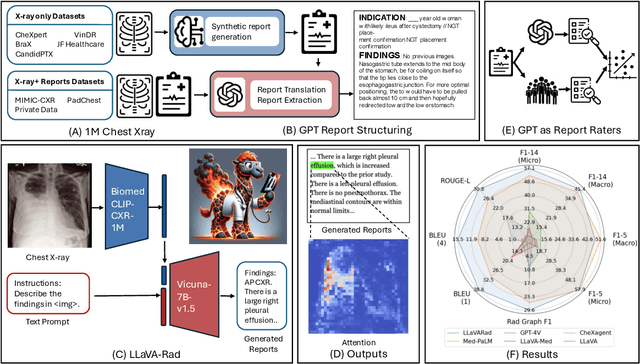
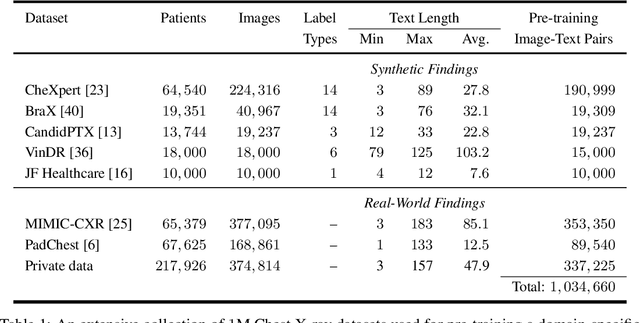
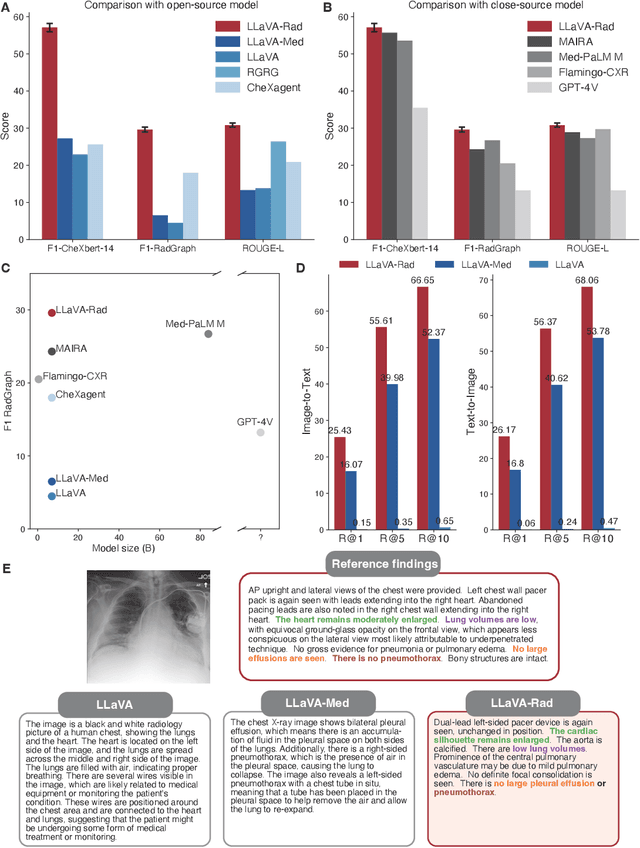
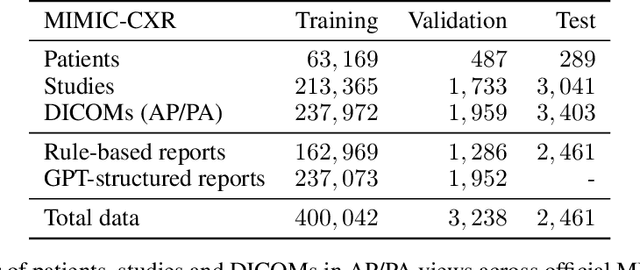
The scaling laws and extraordinary performance of large foundation models motivate the development and utilization of such large models in biomedicine. However, despite early promising results on some biomedical benchmarks, there are still major challenges that need to be addressed before these models can be used in real-world applications. Frontier models such as GPT-4V still have major competency gaps in multimodal capabilities for biomedical applications. Moreover, pragmatic issues such as access, cost, latency, and compliance make it hard for clinicians to use privately-hosted state-of-the-art large models directly on private patient data. In this paper, we explore training open-source small multimodal models (SMMs) to bridge biomedical competency gaps for unmet clinical needs. To maximize data efficiency, we adopt a modular approach by incorporating state-of-the-art pre-trained models for image and text modalities, and focusing on training a lightweight adapter to ground each modality to the text embedding space. We conduct a comprehensive study of this approach on radiology imaging. For training, we assemble a large dataset with over 1 million image-text pairs. For evaluation, we propose a clinically driven novel approach using GPT-4 and demonstrate its parity with expert evaluation. We also study grounding qualitatively using attention. For best practice, we conduct a systematic ablation study on various choices in data engineering and multimodal training. The resulting LLaVA-Rad (7B) model attains state-of-the-art results on radiology tasks such as report generation and cross-modal retrieval, even outperforming much larger models such as GPT-4V and Med-PaLM M (84B). LLaVA-Rad is fast and can be run on a single V100 GPU in private settings, offering a promising state-of-the-art tool for real-world clinical applications.
LocalMamba: Visual State Space Model with Windowed Selective Scan
Mar 14, 2024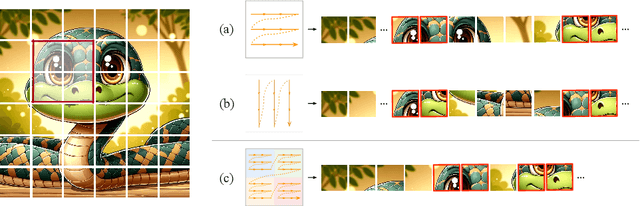
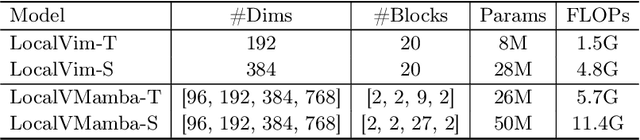
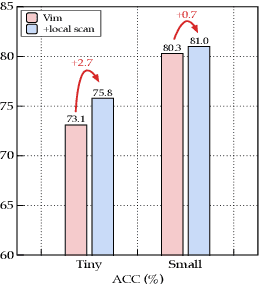
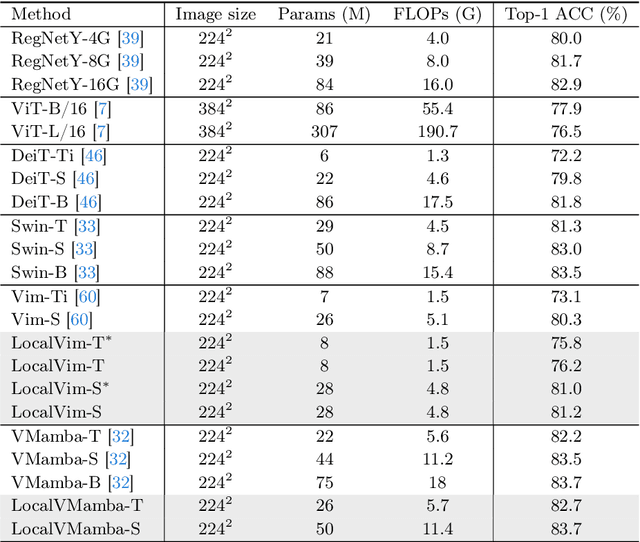
Recent advancements in state space models, notably Mamba, have demonstrated significant progress in modeling long sequences for tasks like language understanding. Yet, their application in vision tasks has not markedly surpassed the performance of traditional Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). This paper posits that the key to enhancing Vision Mamba (ViM) lies in optimizing scan directions for sequence modeling. Traditional ViM approaches, which flatten spatial tokens, overlook the preservation of local 2D dependencies, thereby elongating the distance between adjacent tokens. We introduce a novel local scanning strategy that divides images into distinct windows, effectively capturing local dependencies while maintaining a global perspective. Additionally, acknowledging the varying preferences for scan patterns across different network layers, we propose a dynamic method to independently search for the optimal scan choices for each layer, substantially improving performance. Extensive experiments across both plain and hierarchical models underscore our approach's superiority in effectively capturing image representations. For example, our model significantly outperforms Vim-Ti by 3.1% on ImageNet with the same 1.5G FLOPs. Code is available at: https://github.com/hunto/LocalMamba.
Frequency Decoupling for Motion Magnification via Multi-Level Isomorphic Architecture
Mar 12, 2024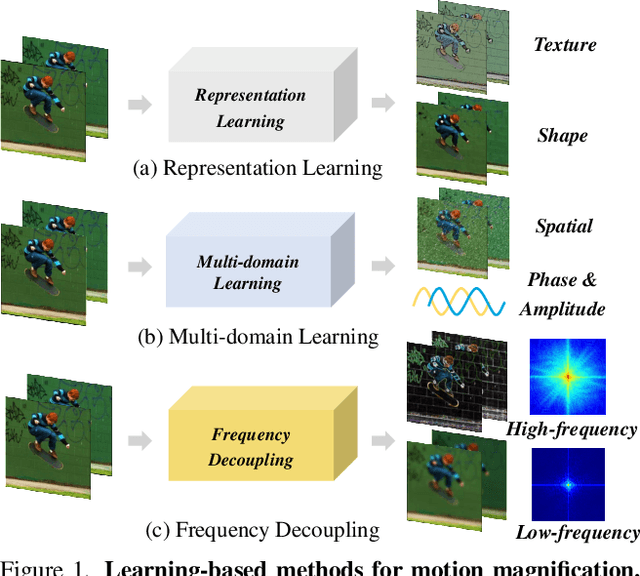
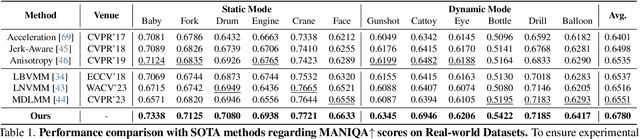
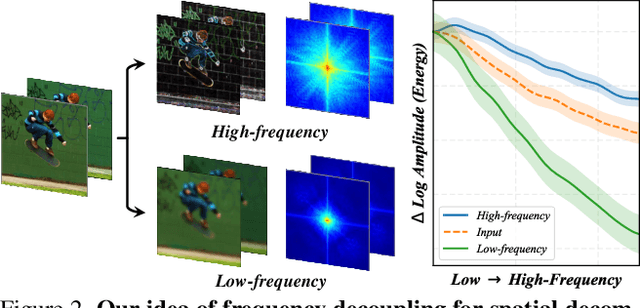
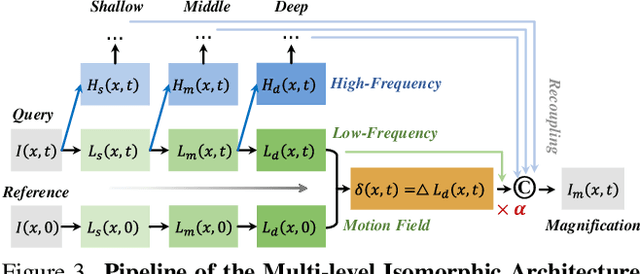
Video Motion Magnification (VMM) aims to reveal subtle and imperceptible motion information of objects in the macroscopic world. Prior methods directly model the motion field from the Eulerian perspective by Representation Learning that separates shape and texture or Multi-domain Learning from phase fluctuations. Inspired by the frequency spectrum, we observe that the low-frequency components with stable energy always possess spatial structure and less noise, making them suitable for modeling the subtle motion field. To this end, we present FD4MM, a new paradigm of Frequency Decoupling for Motion Magnification with a Multi-level Isomorphic Architecture to capture multi-level high-frequency details and a stable low-frequency structure (motion field) in video space. Since high-frequency details and subtle motions are susceptible to information degradation due to their inherent subtlety and unavoidable external interference from noise, we carefully design Sparse High/Low-pass Filters to enhance the integrity of details and motion structures, and a Sparse Frequency Mixer to promote seamless recoupling. Besides, we innovatively design a contrastive regularization for this task to strengthen the model's ability to discriminate irrelevant features, reducing undesired motion magnification. Extensive experiments on both Real-world and Synthetic Datasets show that our FD4MM outperforms SOTA methods. Meanwhile, FD4MM reduces FLOPs by 1.63$\times$ and boosts inference speed by 1.68$\times$ than the latest method. Our code is available at https://github.com/Jiafei127/FD4MM.