 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTao Huang
ProbRadarM3F: mmWave Radar based Human Skeletal Pose Estimation with Probability Map Guided Multi-Format Feature Fusion
May 08, 2024
Millimetre wave (mmWave) radar is a non-intrusive privacy and relatively convenient and inexpensive device, which has been demonstrated to be applicable in place of RGB cameras in human indoor pose estimation tasks. However, mmWave radar relies on the collection of reflected signals from the target, and the radar signals containing information is difficult to be fully applied. This has been a long-standing hindrance to the improvement of pose estimation accuracy. To address this major challenge, this paper introduces a probability map guided multi-format feature fusion model, ProbRadarM3F. This is a novel radar feature extraction framework using a traditional FFT method in parallel with a probability map based positional encoding method. ProbRadarM3F fuses the traditional heatmap features and the positional features, then effectively achieves the estimation of 14 keypoints of the human body. Experimental evaluation on the HuPR dataset proves the effectiveness of the model proposed in this paper, outperforming other methods experimented on this dataset with an AP of 69.9 %. The emphasis of our study is focusing on the position information that is not exploited before in radar singal. This provides direction to investigate other potential non-redundant information from mmWave rader.
Contrastive Learning Method for Sequential Recommendation based on Multi-Intention Disentanglement
Apr 28, 2024Sequential recommendation is one of the important branches of recommender system, aiming to achieve personalized recommended items for the future through the analysis and prediction of users' ordered historical interactive behaviors. However, along with the growth of the user volume and the increasingly rich behavioral information, how to understand and disentangle the user's interactive multi-intention effectively also poses challenges to behavior prediction and sequential recommendation. In light of these challenges, we propose a Contrastive Learning sequential recommendation method based on Multi-Intention Disentanglement (MIDCL). In our work, intentions are recognized as dynamic and diverse, and user behaviors are often driven by current multi-intentions, which means that the model needs to not only mine the most relevant implicit intention for each user, but also impair the influence from irrelevant intentions. Therefore, we choose Variational Auto-Encoder (VAE) to realize the disentanglement of users' multi-intentions, and propose two types of contrastive learning paradigms for finding the most relevant user's interactive intention, and maximizing the mutual information of positive sample pairs, respectively. Experimental results show that MIDCL not only has significant superiority over most existing baseline methods, but also brings a more interpretable case to the research about intention-based prediction and recommendation.
On the Federated Learning Framework for Cooperative Perception
Apr 26, 2024Cooperative perception is essential to enhance the efficiency and safety of future transportation systems, requiring extensive data sharing among vehicles on the road, which raises significant privacy concerns. Federated learning offers a promising solution by enabling data privacy-preserving collaborative enhancements in perception, decision-making, and planning among connected and autonomous vehicles (CAVs). However, federated learning is impeded by significant challenges arising from data heterogeneity across diverse clients, potentially diminishing model accuracy and prolonging convergence periods. This study introduces a specialized federated learning framework for CP, termed the federated dynamic weighted aggregation (FedDWA) algorithm, facilitated by dynamic adjusting loss (DALoss) function. This framework employs dynamic client weighting to direct model convergence and integrates a novel loss function that utilizes Kullback-Leibler divergence (KLD) to counteract the detrimental effects of non-independently and identically distributed (Non-IID) and unbalanced data. Utilizing the BEV transformer as the primary model, our rigorous testing on the OpenV2V dataset, augmented with FedBEVT data, demonstrates significant improvements in the average intersection over union (IoU). These results highlight the substantial potential of our federated learning framework to address data heterogeneity challenges in CP, thereby enhancing the accuracy of environmental perception models and facilitating more robust and efficient collaborative learning solutions in the transportation sector.
Promoting CNNs with Cross-Architecture Knowledge Distillation for Efficient Monocular Depth Estimation
Apr 25, 2024Recently, the performance of monocular depth estimation (MDE) has been significantly boosted with the integration of transformer models. However, the transformer models are usually computationally-expensive, and their effectiveness in light-weight models are limited compared to convolutions. This limitation hinders their deployment on resource-limited devices. In this paper, we propose a cross-architecture knowledge distillation method for MDE, dubbed DisDepth, to enhance efficient CNN models with the supervision of state-of-the-art transformer models. Concretely, we first build a simple framework of convolution-based MDE, which is then enhanced with a novel local-global convolution module to capture both local and global information in the image. To effectively distill valuable information from the transformer teacher and bridge the gap between convolution and transformer features, we introduce a method to acclimate the teacher with a ghost decoder. The ghost decoder is a copy of the student's decoder, and adapting the teacher with the ghost decoder aligns the features to be student-friendly while preserving their original performance. Furthermore, we propose an attentive knowledge distillation loss that adaptively identifies features valuable for depth estimation. This loss guides the student to focus more on attentive regions, improving its performance. Extensive experiments on KITTI and NYU Depth V2 datasets demonstrate the effectiveness of DisDepth. Our method achieves significant improvements on various efficient backbones, showcasing its potential for efficient monocular depth estimation.
A Universal Knowledge Embedded Contrastive Learning Framework for Hyperspectral Image Classification
Apr 06, 2024Hyperspectral image (HSI) classification techniques have been intensively studied and a variety of models have been developed. However, these HSI classification models are confined to pocket models and unrealistic ways of datasets partitioning. The former limits the generalization performance of the model and the latter is partitioned leads to inflated model evaluation metrics, which results in plummeting model performance in the real world. Therefore, we propose a universal knowledge embedded contrastive learning framework (KnowCL) for supervised, unsupervised, and semisupervised HSI classification, which largely closes the gap of HSI classification models between pocket models and standard vision backbones. We present a new HSI processing pipeline in conjunction with a range of data transformation and augmentation techniques that provide diverse data representations and realistic data partitioning. The proposed framework based on this pipeline is compatible with all kinds of backbones and can fully exploit labeled and unlabeled samples with expected training time. Furthermore, we design a new loss function, which can adaptively fuse the supervised loss and unsupervised loss, enhancing the learning performance. This proposed new classification paradigm shows great potentials in exploring for HSI classification technology. The code can be accessed at https://github.com/quanweiliu/KnowCL.
Diverse and Tailored Image Generation for Zero-shot Multi-label Classification
Apr 04, 2024Recently, zero-shot multi-label classification has garnered considerable attention for its capacity to operate predictions on unseen labels without human annotations. Nevertheless, prevailing approaches often use seen classes as imperfect proxies for unseen ones, resulting in suboptimal performance. Drawing inspiration from the success of text-to-image generation models in producing realistic images, we propose an innovative solution: generating synthetic data to construct a training set explicitly tailored for proxyless training on unseen labels. Our approach introduces a novel image generation framework that produces multi-label synthetic images of unseen classes for classifier training. To enhance diversity in the generated images, we leverage a pre-trained large language model to generate diverse prompts. Employing a pre-trained multi-modal CLIP model as a discriminator, we assess whether the generated images accurately represent the target classes. This enables automatic filtering of inaccurately generated images, preserving classifier accuracy. To refine text prompts for more precise and effective multi-label object generation, we introduce a CLIP score-based discriminative loss to fine-tune the text encoder in the diffusion model. Additionally, to enhance visual features on the target task while maintaining the generalization of original features and mitigating catastrophic forgetting resulting from fine-tuning the entire visual encoder, we propose a feature fusion module inspired by transformer attention mechanisms. This module aids in capturing global dependencies between multiple objects more effectively. Extensive experimental results validate the effectiveness of our approach, demonstrating significant improvements over state-of-the-art methods.
EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
Mar 15, 2024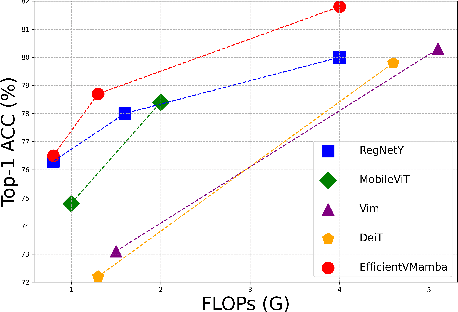
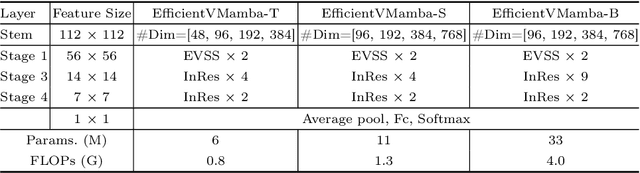
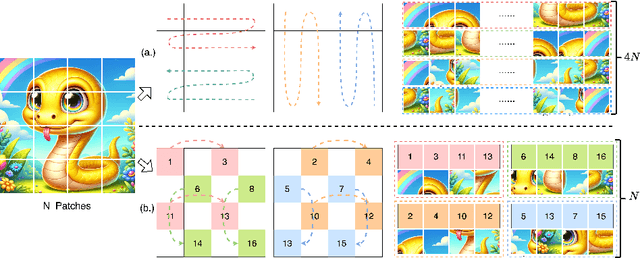
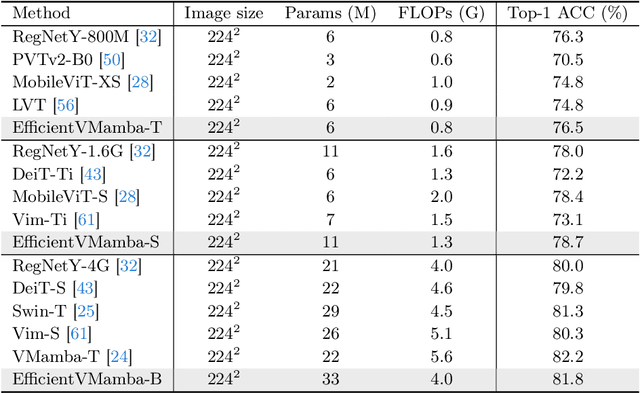
Prior efforts in light-weight model development mainly centered on CNN and Transformer-based designs yet faced persistent challenges. CNNs adept at local feature extraction compromise resolution while Transformers offer global reach but escalate computational demands $\mathcal{O}(N^2)$. This ongoing trade-off between accuracy and efficiency remains a significant hurdle. Recently, state space models (SSMs), such as Mamba, have shown outstanding performance and competitiveness in various tasks such as language modeling and computer vision, while reducing the time complexity of global information extraction to $\mathcal{O}(N)$. Inspired by this, this work proposes to explore the potential of visual state space models in light-weight model design and introduce a novel efficient model variant dubbed EfficientVMamba. Concretely, our EfficientVMamba integrates a atrous-based selective scan approach by efficient skip sampling, constituting building blocks designed to harness both global and local representational features. Additionally, we investigate the integration between SSM blocks and convolutions, and introduce an efficient visual state space block combined with an additional convolution branch, which further elevate the model performance. Experimental results show that, EfficientVMamba scales down the computational complexity while yields competitive results across a variety of vision tasks. For example, our EfficientVMamba-S with $1.3$G FLOPs improves Vim-Ti with $1.5$G FLOPs by a large margin of $5.6\%$ accuracy on ImageNet. Code is available at: \url{https://github.com/TerryPei/EfficientVMamba}.
LocalMamba: Visual State Space Model with Windowed Selective Scan
Mar 14, 2024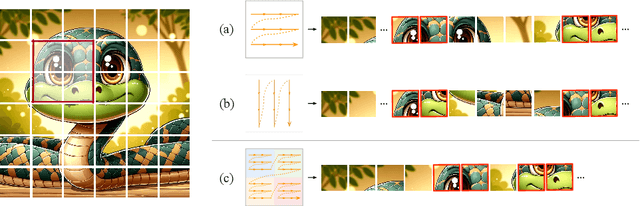
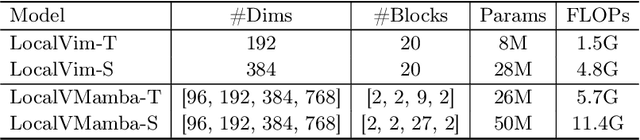
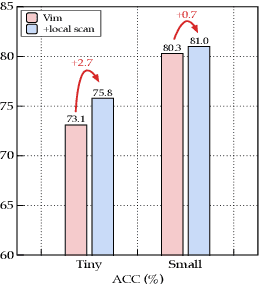
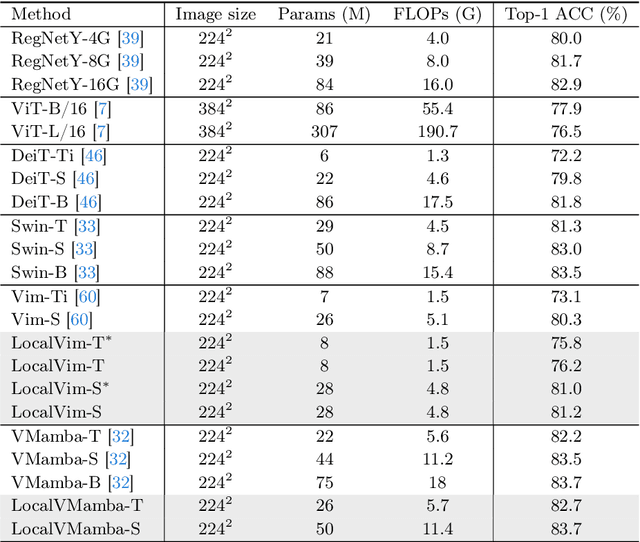
Recent advancements in state space models, notably Mamba, have demonstrated significant progress in modeling long sequences for tasks like language understanding. Yet, their application in vision tasks has not markedly surpassed the performance of traditional Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). This paper posits that the key to enhancing Vision Mamba (ViM) lies in optimizing scan directions for sequence modeling. Traditional ViM approaches, which flatten spatial tokens, overlook the preservation of local 2D dependencies, thereby elongating the distance between adjacent tokens. We introduce a novel local scanning strategy that divides images into distinct windows, effectively capturing local dependencies while maintaining a global perspective. Additionally, acknowledging the varying preferences for scan patterns across different network layers, we propose a dynamic method to independently search for the optimal scan choices for each layer, substantially improving performance. Extensive experiments across both plain and hierarchical models underscore our approach's superiority in effectively capturing image representations. For example, our model significantly outperforms Vim-Ti by 3.1% on ImageNet with the same 1.5G FLOPs. Code is available at: https://github.com/hunto/LocalMamba.
LiDAR Point Cloud-based Multiple Vehicle Tracking with Probabilistic Measurement-Region Association
Mar 12, 2024
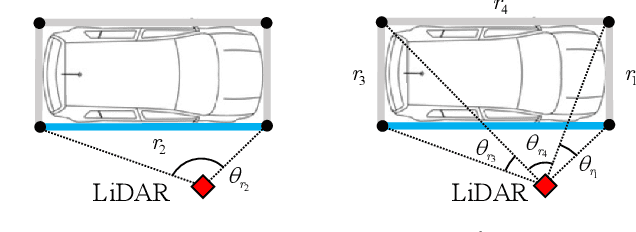
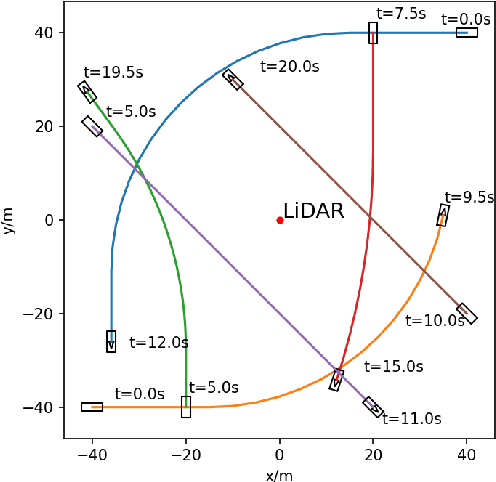

Multiple extended target tracking (ETT) has gained increasing attention due to the development of high-precision LiDAR and radar sensors in automotive applications. For LiDAR point cloud-based vehicle tracking, this paper presents a probabilistic measurement-region association (PMRA) ETT model, which can describe the complex measurement distribution by partitioning the target extent into different regions. The PMRA model overcomes the drawbacks of previous data-region association (DRA) models by eliminating the approximation error of constrained estimation and using continuous integrals to more reliably calculate the association probabilities. Furthermore, the PMRA model is integrated with the Poisson multi-Bernoulli mixture (PMBM) filter for tracking multiple vehicles. Simulation results illustrate the superior estimation accuracy of the proposed PMRA-PMBM filter in terms of both positions and extents of the vehicles comparing with PMBM filters using the gamma Gaussian inverse Wishart and DRA implementations.
Active Generation for Image Classification
Mar 11, 2024
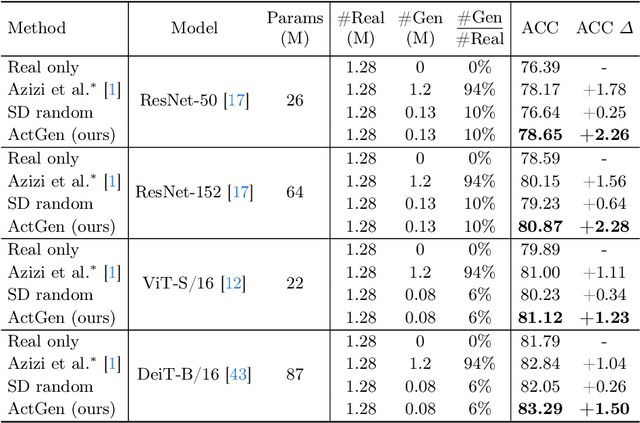

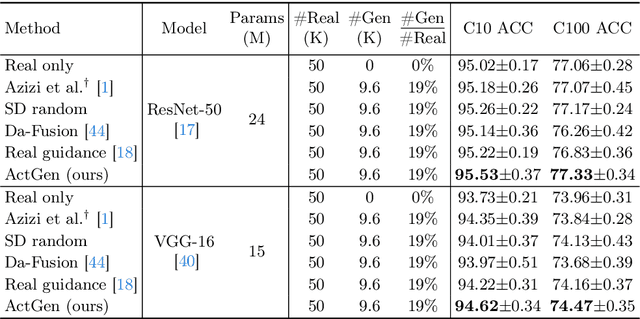
Recently, the growing capabilities of deep generative models have underscored their potential in enhancing image classification accuracy. However, existing methods often demand the generation of a disproportionately large number of images compared to the original dataset, while having only marginal improvements in accuracy. This computationally expensive and time-consuming process hampers the practicality of such approaches. In this paper, we propose to address the efficiency of image generation by focusing on the specific needs and characteristics of the model. With a central tenet of active learning, our method, named ActGen, takes a training-aware approach to image generation. It aims to create images akin to the challenging or misclassified samples encountered by the current model and incorporates these generated images into the training set to augment model performance. ActGen introduces an attentive image guidance technique, using real images as guides during the denoising process of a diffusion model. The model's attention on class prompt is leveraged to ensure the preservation of similar foreground object while diversifying the background. Furthermore, we introduce a gradient-based generation guidance method, which employs two losses to generate more challenging samples and prevent the generated images from being too similar to previously generated ones. Experimental results on the CIFAR and ImageNet datasets demonstrate that our method achieves better performance with a significantly reduced number of generated images.