 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuxuan Xia
Bayesian Simultaneous Localization and Multi-Lane Tracking Using Onboard Sensors and a SD Map
May 07, 2024
High-definition map with accurate lane-level information is crucial for autonomous driving, but the creation of these maps is a resource-intensive process. To this end, we present a cost-effective solution to create lane-level roadmaps using only the global navigation satellite system (GNSS) and a camera on customer vehicles. Our proposed solution utilizes a prior standard-definition (SD) map, GNSS measurements, visual odometry, and lane marking edge detection points, to simultaneously estimate the vehicle's 6D pose, its position within a SD map, and also the 3D geometry of traffic lines. This is achieved using a Bayesian simultaneous localization and multi-object tracking filter, where the estimation of traffic lines is formulated as a multiple extended object tracking problem, solved using a trajectory Poisson multi-Bernoulli mixture (TPMBM) filter. In TPMBM filtering, traffic lines are modeled using B-spline trajectories, and each trajectory is parameterized by a sequence of control points. The proposed solution has been evaluated using experimental data collected by a test vehicle driving on highway. Preliminary results show that the traffic line estimates, overlaid on the satellite image, generally align with the lane markings up to some lateral offsets.
3D Extended Object Tracking by Fusing Roadside Sparse Radar Point Clouds and Pixel Keypoints
Apr 27, 2024Roadside perception is a key component in intelligent transportation systems. In this paper, we present a novel three-dimensional (3D) extended object tracking (EOT) method, which simultaneously estimates the object kinematics and extent state, in roadside perception using both the radar and camera data. Because of the influence of sensor viewing angle and limited angle resolution, radar measurements from objects are sparse and non-uniformly distributed, leading to inaccuracies in object extent and position estimation. To address this problem, we present a novel spherical Gaussian function weighted Gaussian mixture model. This model assumes that radar measurements originate from a series of probabilistic weighted radar reflectors on the vehicle's extent. Additionally, we utilize visual detection of vehicle keypoints to provide additional information on the positions of radar reflectors. Since keypoints may not always correspond to radar reflectors, we propose an elastic skeleton fusion mechanism, which constructs a virtual force to establish the relationship between the radar reflectors on the vehicle and its extent. Furthermore, to better describe the kinematic state of the vehicle and constrain its extent state, we develop a new 3D constant turn rate and velocity motion model, considering the complex 3D motion of the vehicle relative to the roadside sensor. Finally, we apply variational Bayesian approximation to the intractable measurement update step to enable recursive Bayesian estimation of the object's state. Simulation results using the Carla simulator and experimental results on the nuScenes dataset demonstrate the effectiveness and superiority of the proposed method in comparison to several state-of-the-art 3D EOT methods.
LiDAR Point Cloud-based Multiple Vehicle Tracking with Probabilistic Measurement-Region Association
Mar 12, 2024
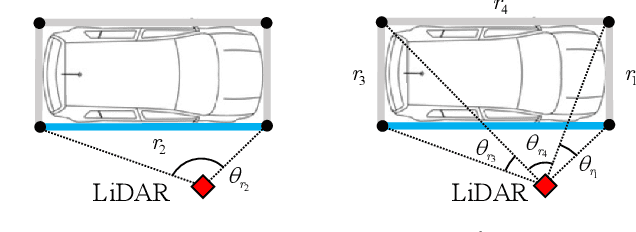

Multiple extended target tracking (ETT) has gained increasing attention due to the development of high-precision LiDAR and radar sensors in automotive applications. For LiDAR point cloud-based vehicle tracking, this paper presents a probabilistic measurement-region association (PMRA) ETT model, which can describe the complex measurement distribution by partitioning the target extent into different regions. The PMRA model overcomes the drawbacks of previous data-region association (DRA) models by eliminating the approximation error of constrained estimation and using continuous integrals to more reliably calculate the association probabilities. Furthermore, the PMRA model is integrated with the Poisson multi-Bernoulli mixture (PMBM) filter for tracking multiple vehicles. Simulation results illustrate the superior estimation accuracy of the proposed PMRA-PMBM filter in terms of both positions and extents of the vehicles comparing with PMBM filters using the gamma Gaussian inverse Wishart and DRA implementations.
Boosting Few-Shot Segmentation via Instance-Aware Data Augmentation and Local Consensus Guided Cross Attention
Jan 18, 2024Few-shot segmentation aims to train a segmentation model that can fast adapt to a novel task for which only a few annotated images are provided. Most recent models have adopted a prototype-based paradigm for few-shot inference. These approaches may have limited generalization capacity beyond the standard 1- or 5-shot settings. In this paper, we closely examine and reevaluate the fine-tuning based learning scheme that fine-tunes the classification layer of a deep segmentation network pre-trained on diverse base classes. To improve the generalizability of the classification layer optimized with sparsely annotated samples, we introduce an instance-aware data augmentation (IDA) strategy that augments the support images based on the relative sizes of the target objects. The proposed IDA effectively increases the support set's diversity and promotes the distribution consistency between support and query images. On the other hand, the large visual difference between query and support images may hinder knowledge transfer and cripple the segmentation performance. To cope with this challenge, we introduce the local consensus guided cross attention (LCCA) to align the query feature with support features based on their dense correlation, further improving the model's generalizability to the query image. The significant performance improvements on the standard few-shot segmentation benchmarks PASCAL-$5^i$ and COCO-$20^i$ verify the efficacy of our proposed method.
Transformer-Based Multi-Object Smoothing with Decoupled Data Association and Smoothing
Dec 22, 2023Multi-object tracking (MOT) is the task of estimating the state trajectories of an unknown and time-varying number of objects over a certain time window. Several algorithms have been proposed to tackle the multi-object smoothing task, where object detections can be conditioned on all the measurements in the time window. However, the best-performing methods suffer from intractable computational complexity and require approximations, performing suboptimally in complex settings. Deep learning based algorithms are a possible venue for tackling this issue but have not been applied extensively in settings where accurate multi-object models are available and measurements are low-dimensional. We propose a novel DL architecture specifically tailored for this setting that decouples the data association task from the smoothing task. We compare the performance of the proposed smoother to the state-of-the-art in different tasks of varying difficulty and provide, to the best of our knowledge, the first comparison between traditional Bayesian trackers and DL trackers in the smoothing problem setting.
Markov Chain Monte Carlo Data Association for Sets of Trajectories
Dec 06, 2023This paper considers a batch solution to the multi-object tracking problem based on sets of trajectories. Specifically, we present two offline implementations of the trajectory Poisson multi-Bernoulli mixture (TPMBM) filter for batch data based on Markov chain Monte Carlo (MCMC) sampling of the data association hypotheses. In contrast to online TPMBM implementations, the proposed offline implementations solve a large-scale, multi-scan data association problem across the entire time interval of interest, and therefore they can fully exploit all the measurement information available. Furthermore, by leveraging the efficient hypothesis structure of TPMBM filters, the proposed implementations compare favorably with other MCMC-based multi-object tracking algorithms. Simulation results show that the TPMBM implementation using the Metropolis-Hastings algorithm presents state-of-the-art multiple trajectory estimation performance.
V2X Cooperative Perception for Autonomous Driving: Recent Advances and Challenges
Oct 05, 2023

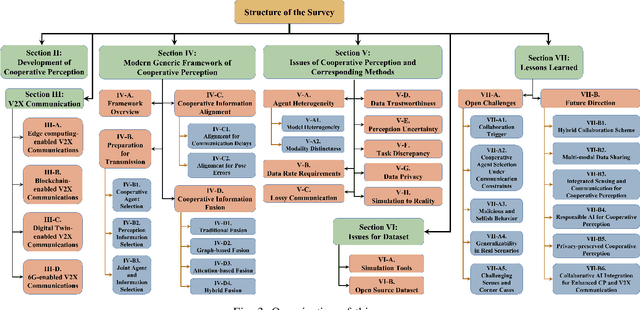
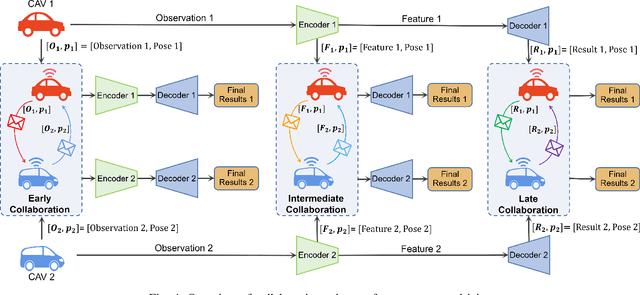
Accurate perception is essential for advancing autonomous driving and addressing safety challenges in modern transportation systems. Despite significant advancements in computer vision for object recognition, current perception methods still face difficulties in complex real-world traffic environments. Challenges such as physical occlusion and limited sensor field of view persist for individual vehicle systems. Cooperative Perception (CP) with Vehicle-to-Everything (V2X) technologies has emerged as a solution to overcome these obstacles and enhance driving automation systems. While some research has explored CP's fundamental architecture and critical components, there remains a lack of comprehensive summaries of the latest innovations, particularly in the context of V2X communication technologies. To address this gap, this paper provides a comprehensive overview of the evolution of CP technologies, spanning from early explorations to recent developments, including advancements in V2X communication technologies. Additionally, a contemporary generic framework is proposed to illustrate the V2X-based CP workflow, aiding in the structured understanding of CP system components. Furthermore, this paper categorizes prevailing V2X-based CP methodologies based on the critical issues they address. An extensive literature review is conducted within this taxonomy, evaluating existing datasets and simulators. Finally, open challenges and future directions in CP for autonomous driving are discussed by considering both perception and V2X communication advancements.
Which Framework is Suitable for Online 3D Multi-Object Tracking for Autonomous Driving with Automotive 4D Imaging Radar?
Sep 13, 2023



Online 3D multi-object tracking (MOT) has recently received significant research interests due to the expanding demand of 3D perception in advanced driver assistance systems (ADAS) and autonomous driving (AD). Among the existing 3D MOT frameworks for ADAS and AD, conventional point object tracking (POT) framework using the tracking-by-detection (TBD) strategy has been well studied and accepted for LiDAR and 4D imaging radar point clouds. In contrast, extended object tracking (EOT), another important framework which accepts the joint-detection-and-tracking (JDT) strategy, has rarely been explored for online 3D MOT applications. This paper provides the first systematical investigation of the EOT framework for online 3D MOT in real-world ADAS and AD scenarios. Specifically, the widely accepted TBD-POT framework, the recently investigated JDT-EOT framework, and our proposed TBD-EOT framework are compared via extensive evaluations on two open source 4D imaging radar datasets: View-of-Delft and TJ4DRadSet. Experiment results demonstrate that the conventional TBD-POT framework remains preferable for online 3D MOT with high tracking performance and low computational complexity, while the proposed TBD-EOT framework has the potential to outperform it in certain situations. However, the results also show that the JDT-EOT framework encounters multiple problems and performs inadequately in evaluation scenarios. After analyzing the causes of these phenomena based on various evaluation metrics and visualizations, we provide possible guidelines to improve the performance of these MOT frameworks on real-world data. These provide the first benchmark and important insights for the future development of 4D imaging radar-based online 3D MOT.
LEGO: Learning and Graph-Optimized Modular Tracker for Online Multi-Object Tracking with Point Clouds
Aug 19, 2023



Online multi-object tracking (MOT) plays a pivotal role in autonomous systems. The state-of-the-art approaches usually employ a tracking-by-detection method, and data association plays a critical role. This paper proposes a learning and graph-optimized (LEGO) modular tracker to improve data association performance in the existing literature. The proposed LEGO tracker integrates graph optimization and self-attention mechanisms, which efficiently formulate the association score map, facilitating the accurate and efficient matching of objects across time frames. To further enhance the state update process, the Kalman filter is added to ensure consistent tracking by incorporating temporal coherence in the object states. Our proposed method utilizing LiDAR alone has shown exceptional performance compared to other online tracking approaches, including LiDAR-based and LiDAR-camera fusion-based methods. LEGO ranked 1st at the time of submitting results to KITTI object tracking evaluation ranking board and remains 2nd at the time of submitting this paper, among all online trackers in the KITTI MOT benchmark for cars1
Scene Separation & Data Selection: Temporal Segmentation Algorithm for Real-Time Video Stream Analysis
Aug 01, 2023



We present 2SDS (Scene Separation and Data Selection algorithm), a temporal segmentation algorithm used in real-time video stream interpretation. It complements CNN-based models to make use of temporal information in videos. 2SDS can detect the change between scenes in a video stream by com-paring the image difference between two frames. It separates a video into segments (scenes), and by combining itself with a CNN model, 2SDS can select the optimal result for each scene. In this paper, we will be discussing some basic methods and concepts behind 2SDS, as well as presenting some preliminary experiment results regarding 2SDS. During these experiments, 2SDS has achieved an overall accuracy of over 90%.
* 5 pages, 4 figures, at IJCAI-ECAI 2022 workshop, First International Workshop on Spatio-Temporal Reasoning and Learning, July 24, 2022, Vienna, Austria