 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLi Guo
Robust Resource Allocation for STAR-RIS Assisted SWIPT Systems
Mar 22, 2024
A simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) assisted simultaneous wireless information and power transfer (SWIPT) system is proposed. More particularly, an STAR-RIS is deployed to assist in the information/power transfer from a multi-antenna access point (AP) to multiple single-antenna information users (IUs) and energy users (EUs), where two practical STAR-RIS operating protocols, namely energy splitting (ES) and time switching (TS), are employed. Under the imperfect channel state information (CSI) condition, a multi-objective optimization problem (MOOP) framework, that simultaneously maximizes the minimum data rate and minimum harvested power, is employed to investigate the fundamental rate-energy trade-off between IUs and EUs. To obtain the optimal robust resource allocation strategy, the MOOP is first transformed into a single-objective optimization problem (SOOP) via the {\epsilon}-constraint method, which is then reformulated by approximating semi-infinite inequality constraints with the S-procedure. For ES, an alternating optimization (AO)-based algorithm is proposed to jointly design AP active beamforming and STAR-RIS passive beamforming, where a penalty method is leveraged in STAR-RIS beamforming design. Furthermore, the developed algorithm is extended to optimize the time allocation policy and beamforming vectors in a two-layer iterative manner for TS. Numerical results reveal that: 1) deploying STAR-RISs achieves a significant performance gain over conventional RISs, especially in terms of harvested power for EUs; 2) the ES protocol obtains a better user fairness performance when focusing only on IUs or EUs, while the TS protocol yields a better balance between IUs and EUs; 3) the imperfect CSI affects IUs more significantly than EUs, whereas TS can confer a more robust design to attenuate these effects.
Coexisting Passive RIS and Active Relay Assisted NOMA Systems
Mar 22, 2024A novel coexisting passive reconfigurable intelligent surface (RIS) and active decode-and-forward (DF) relay assisted non-orthogonal multiple access (NOMA) transmission framework is proposed. In particular, two communication protocols are conceived, namely Hybrid NOMA (H-NOMA) and Full NOMA (F-NOMA). Based on the proposed two protocols, both the sum rate maximization and max-min rate fairness problems are formulated for jointly optimizing the power allocation at the access point and relay as well as the passive beamforming design at the RIS. To tackle the non-convex problems, an alternating optimization (AO) based algorithm is first developed, where the transmit power and the RIS phase-shift are alternatingly optimized by leveraging the two-dimensional search and rank-relaxed difference-of-convex (DC) programming, respectively. Then, a two-layer penalty based joint optimization (JO) algorithm is developed to jointly optimize the resource allocation coefficients within each iteration. Finally, numerical results demonstrate that: i) the proposed coexisting RIS and relay assisted transmission framework is capable of achieving a significant user performance improvement than conventional schemes without RIS or relay; ii) compared with the AO algorithm, the JO algorithm requires less execution time at the cost of a slight performance loss; and iii) the H-NOMA and F-NOMA protocols are generally preferable for ensuring user rate fairness and enhancing user sum rate, respectively.
STAR-RIS Assisted Downlink Active and Uplink Backscatter Communications with NOMA
Mar 22, 2024A simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) assisted downlink (DL) active and uplink (UL) backscatter communication (BackCom) framework is proposed. More particularly, a full-duplex (FD) base station (BS) communicates with the DL users via the STAR-RIS's transmission link, while exciting and receiving the information from the UL BackCom devices with the aid of the STAR-RIS's reflection link. Non-orthogonal multiple access (NOMA) is exploited in both DL and UL communications for improving the spectrum efficiency. The system weighted sum rate maximization problem is formulated for jointly optimizing the FD BS active receive and transmit beamforming, the STAR- RIS passive beamforming, and the DL NOMA decoding orders, subject to the DL user's individual rate constraint. To tackle this challenging non-convex problem, we propose an alternating optimization (AO) based algorithm for the joint active and passive beamforming design with a given DL NOMA decoding order. To address the potential high computational complexity required for exhaustive searching all the NOMA decoding orders, an efficient NOMA user ordering scheme is further developed. Finally, numerical results demonstrate that: i) compared with the baseline schemes employing conventional RISs or space division multiple access, the proposed scheme achieves higher performance gains; and ii) higher UL rate gain is obtained at a cost of DL performance degradation, as a remedy, a more flexible performance tradeoff can be achieved by introducing the STAR-RIS.
HCF-Net: Hierarchical Context Fusion Network for Infrared Small Object Detection
Mar 16, 2024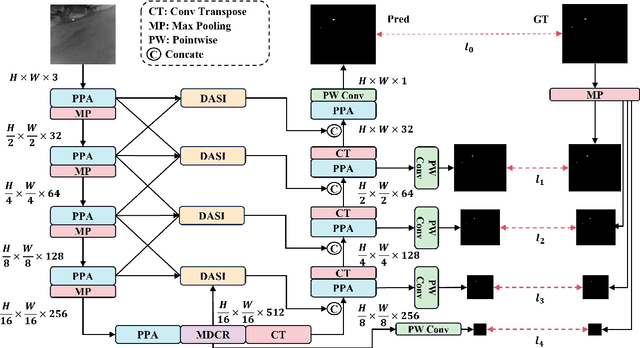
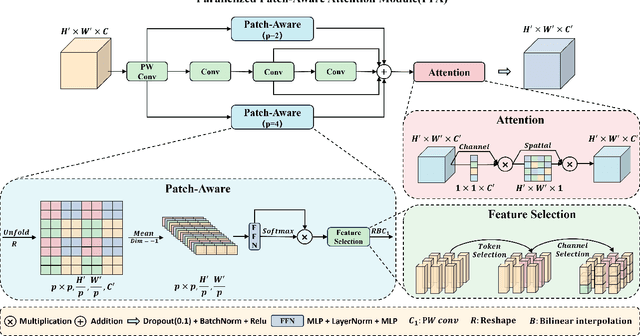
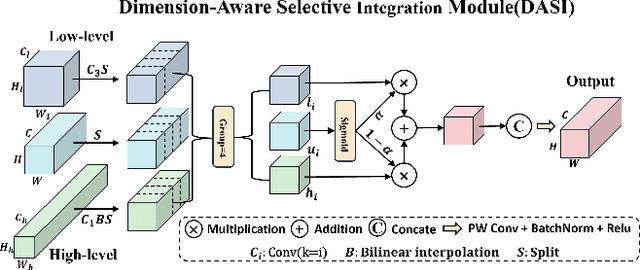
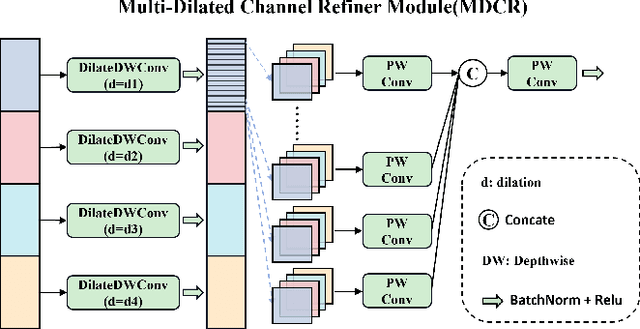
Infrared small object detection is an important computer vision task involving the recognition and localization of tiny objects in infrared images, which usually contain only a few pixels. However, it encounters difficulties due to the diminutive size of the objects and the generally complex backgrounds in infrared images. In this paper, we propose a deep learning method, HCF-Net, that significantly improves infrared small object detection performance through multiple practical modules. Specifically, it includes the parallelized patch-aware attention (PPA) module, dimension-aware selective integration (DASI) module, and multi-dilated channel refiner (MDCR) module. The PPA module uses a multi-branch feature extraction strategy to capture feature information at different scales and levels. The DASI module enables adaptive channel selection and fusion. The MDCR module captures spatial features of different receptive field ranges through multiple depth-separable convolutional layers. Extensive experimental results on the SIRST infrared single-frame image dataset show that the proposed HCF-Net performs well, surpassing other traditional and deep learning models. Code is available at https://github.com/zhengshuchen/HCFNet.
Hybrid Active-Passive RIS Transmitter Enabled Energy-Efficient Multi-User Communications
Mar 04, 2024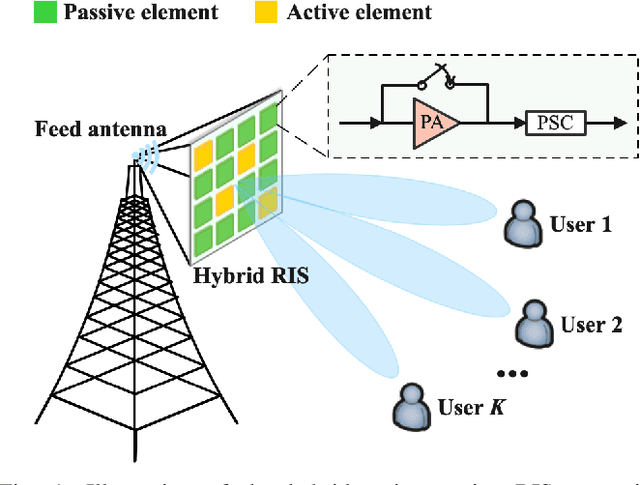
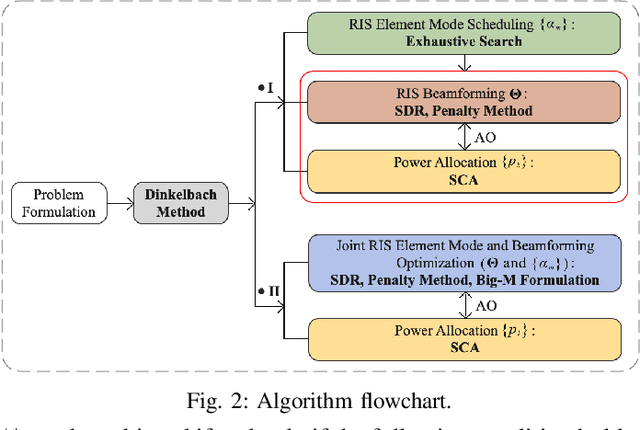
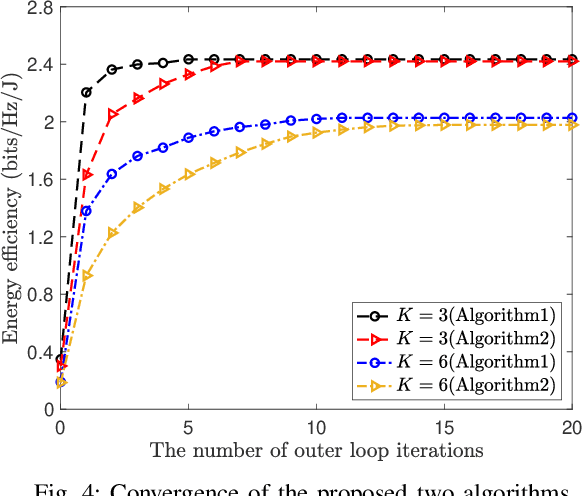
A novel hybrid active-passive reconfigurable intelligent surface (RIS) transmitter enabled downlink multi-user communication system is investigated. Specifically, RISs are exploited to serve as transmitter antennas, where each element can flexibly switch between active and passive modes to deliver information to multiple users. The system energy efficiency (EE) maximization problem is formulated by jointly optimizing the RIS element scheduling and beamforming coefficients, as well as the power allocation coefficients, subject to the user's individual rate requirement and the maximum RIS amplification power constraint. Using the Dinkelbach relaxation, the original mixed-integer nonlinear programming problem is transformed into a nonfractional optimization problem with a two-layer structure, which is solved by the alternating optimization approach. In particular, an exhaustive search method is proposed to determine the optimal operating mode for each RIS element. Then, the RIS beamforming and power allocation coefficients are properly designed in an alternating manner. To overcome the potentially high complexity caused by exhaustive searching, we further develop a joint RIS element mode and beamforming optimization scheme by exploiting the Big-M formulation technique. Numerical results validate that: 1) The proposed hybrid RIS scheme yields higher EE than the baseline multi-antenna schemes employing fully active/passive RIS or conventional radio frequency chains; 2) Both proposed algorithms are effective in improving the system performance, especially the latter can achieve precise design of RIS elements with low complexity; and 3) For a fixed-size hybrid RIS, maximum EE can be reaped by setting only a minority of elements to operate in the active mode.
Cross Entropy versus Label Smoothing: A Neural Collapse Perspective
Feb 07, 2024Label smoothing loss is a widely adopted technique to mitigate overfitting in deep neural networks. This paper studies label smoothing from the perspective of Neural Collapse (NC), a powerful empirical and theoretical framework which characterizes model behavior during the terminal phase of training. We first show empirically that models trained with label smoothing converge faster to neural collapse solutions and attain a stronger level of neural collapse. Additionally, we show that at the same level of NC1, models under label smoothing loss exhibit intensified NC2. These findings provide valuable insights into the performance benefits and enhanced model calibration under label smoothing loss. We then leverage the unconstrained feature model to derive closed-form solutions for the global minimizers for both loss functions and further demonstrate that models under label smoothing have a lower conditioning number and, therefore, theoretically converge faster. Our study, combining empirical evidence and theoretical results, not only provides nuanced insights into the differences between label smoothing and cross-entropy losses, but also serves as an example of how the powerful neural collapse framework can be used to improve our understanding of DNNs.
Local Feature Matching Using Deep Learning: A Survey
Jan 31, 2024Local feature matching enjoys wide-ranging applications in the realm of computer vision, encompassing domains such as image retrieval, 3D reconstruction, and object recognition. However, challenges persist in improving the accuracy and robustness of matching due to factors like viewpoint and lighting variations. In recent years, the introduction of deep learning models has sparked widespread exploration into local feature matching techniques. The objective of this endeavor is to furnish a comprehensive overview of local feature matching methods. These methods are categorized into two key segments based on the presence of detectors. The Detector-based category encompasses models inclusive of Detect-then-Describe, Joint Detection and Description, Describe-then-Detect, as well as Graph Based techniques. In contrast, the Detector-free category comprises CNN Based, Transformer Based, and Patch Based methods. Our study extends beyond methodological analysis, incorporating evaluations of prevalent datasets and metrics to facilitate a quantitative comparison of state-of-the-art techniques. The paper also explores the practical application of local feature matching in diverse domains such as Structure from Motion, Remote Sensing Image Registration, and Medical Image Registration, underscoring its versatility and significance across various fields. Ultimately, we endeavor to outline the current challenges faced in this domain and furnish future research directions, thereby serving as a reference for researchers involved in local feature matching and its interconnected domains.
Boosting Few-Shot Segmentation via Instance-Aware Data Augmentation and Local Consensus Guided Cross Attention
Jan 18, 2024Few-shot segmentation aims to train a segmentation model that can fast adapt to a novel task for which only a few annotated images are provided. Most recent models have adopted a prototype-based paradigm for few-shot inference. These approaches may have limited generalization capacity beyond the standard 1- or 5-shot settings. In this paper, we closely examine and reevaluate the fine-tuning based learning scheme that fine-tunes the classification layer of a deep segmentation network pre-trained on diverse base classes. To improve the generalizability of the classification layer optimized with sparsely annotated samples, we introduce an instance-aware data augmentation (IDA) strategy that augments the support images based on the relative sizes of the target objects. The proposed IDA effectively increases the support set's diversity and promotes the distribution consistency between support and query images. On the other hand, the large visual difference between query and support images may hinder knowledge transfer and cripple the segmentation performance. To cope with this challenge, we introduce the local consensus guided cross attention (LCCA) to align the query feature with support features based on their dense correlation, further improving the model's generalizability to the query image. The significant performance improvements on the standard few-shot segmentation benchmarks PASCAL-$5^i$ and COCO-$20^i$ verify the efficacy of our proposed method.
Spectral Prompt Tuning:Unveiling Unseen Classes for Zero-Shot Semantic Segmentation
Dec 20, 2023Recently, CLIP has found practical utility in the domain of pixel-level zero-shot segmentation tasks. The present landscape features two-stage methodologies beset by issues such as intricate pipelines and elevated computational costs. While current one-stage approaches alleviate these concerns and incorporate Visual Prompt Training (VPT) to uphold CLIP's generalization capacity, they still fall short in fully harnessing CLIP's potential for pixel-level unseen class demarcation and precise pixel predictions. To further stimulate CLIP's zero-shot dense prediction capability, we propose SPT-SEG, a one-stage approach that improves CLIP's adaptability from image to pixel. Specifically, we initially introduce Spectral Prompt Tuning (SPT), incorporating spectral prompts into the CLIP visual encoder's shallow layers to capture structural intricacies of images, thereby enhancing comprehension of unseen classes. Subsequently, we introduce the Spectral Guided Decoder (SGD), utilizing both high and low-frequency information to steer the network's spatial focus towards more prominent classification features, enabling precise pixel-level prediction outcomes. Through extensive experiments on two public datasets, we demonstrate the superiority of our method over state-of-the-art approaches, performing well across all classes and particularly excelling in handling unseen classes. Code is available at:https://github.com/clearxu/SPT.
The Development of LLMs for Embodied Navigation
Nov 18, 2023In recent years, the rapid advancement of Large Language Models (LLMs) such as the Generative Pre-trained Transformer (GPT) has attracted increasing attention due to their potential in a variety of practical applications. The application of LLMs with Embodied Intelligence has emerged as a significant area of focus. Among the myriad applications of LLMs, navigation tasks are particularly noteworthy because they demand a deep understanding of the environment and quick, accurate decision-making. LLMs can augment embodied intelligence systems with sophisticated environmental perception and decision-making support, leveraging their robust language and image-processing capabilities. This article offers an exhaustive summary of the symbiosis between LLMs and embodied intelligence with a focus on navigation. It reviews state-of-the-art models, research methodologies, and assesses the advantages and disadvantages of existing embodied navigation models and datasets. Finally, the article elucidates the role of LLMs in embodied intelligence, based on current research, and forecasts future directions in the field. A comprehensive list of studies in this survey is available at https://github.com/Rongtao-Xu/Awesome-LLM-EN