 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZixuan Dong
Cross Entropy versus Label Smoothing: A Neural Collapse Perspective
Feb 07, 2024
Label smoothing loss is a widely adopted technique to mitigate overfitting in deep neural networks. This paper studies label smoothing from the perspective of Neural Collapse (NC), a powerful empirical and theoretical framework which characterizes model behavior during the terminal phase of training. We first show empirically that models trained with label smoothing converge faster to neural collapse solutions and attain a stronger level of neural collapse. Additionally, we show that at the same level of NC1, models under label smoothing loss exhibit intensified NC2. These findings provide valuable insights into the performance benefits and enhanced model calibration under label smoothing loss. We then leverage the unconstrained feature model to derive closed-form solutions for the global minimizers for both loss functions and further demonstrate that models under label smoothing have a lower conditioning number and, therefore, theoretically converge faster. Our study, combining empirical evidence and theoretical results, not only provides nuanced insights into the differences between label smoothing and cross-entropy losses, but also serves as an example of how the powerful neural collapse framework can be used to improve our understanding of DNNs.
Pre-training with Synthetic Data Helps Offline Reinforcement Learning
Oct 06, 2023

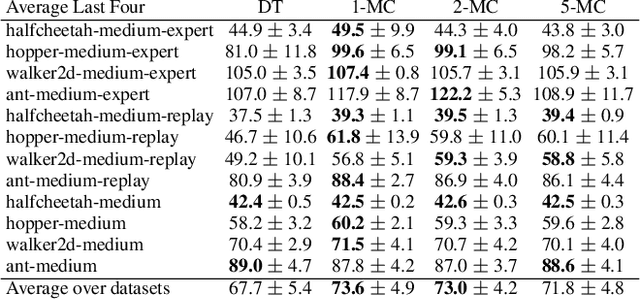
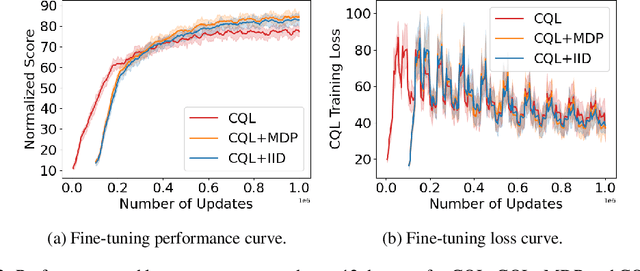
Recently, it has been shown that for offline deep reinforcement learning (DRL), pre-training Decision Transformer with a large language corpus can improve downstream performance (Reid et al., 2022). A natural question to ask is whether this performance gain can only be achieved with language pre-training, or can be achieved with simpler pre-training schemes which do not involve language. In this paper, we first show that language is not essential for improved performance, and indeed pre-training with synthetic IID data for a small number of updates can match the performance gains from pre-training with a large language corpus; moreover, pre-training with data generated by a one-step Markov chain can further improve the performance. Inspired by these experimental results, we then consider pre-training Conservative Q-Learning (CQL), a popular offline DRL algorithm, which is Q-learning-based and typically employs a Multi-Layer Perceptron (MLP) backbone. Surprisingly, pre-training with simple synthetic data for a small number of updates can also improve CQL, providing consistent performance improvement on D4RL Gym locomotion datasets. The results of this paper not only illustrate the importance of pre-training for offline DRL but also show that the pre-training data can be synthetic and generated with remarkably simple mechanisms.
On the Convergence of Monte Carlo UCB for Random-Length Episodic MDPs
Sep 07, 2022



In reinforcement learning, Monte Carlo algorithms update the Q function by averaging the episodic returns. In the Monte Carlo UCB (MC-UCB) algorithm, the action taken in each state is the action that maximizes the Q function plus a UCB exploration term, which biases the choice of actions to those that have been chosen less frequently. Although there has been significant work on establishing regret bounds for MC-UCB, most of that work has been focused on finite-horizon versions of the problem, for which each episode terminates after a constant number of steps. For such finite-horizon problems, the optimal policy depends both on the current state and the time within the episode. However, for many natural episodic problems, such as games like Go and Chess and robotic tasks, the episode is of random length and the optimal policy is stationary. For such environments, it is an open question whether the Q-function in MC-UCB will converge to the optimal Q function; we conjecture that, unlike Q-learning, it does not converge for all MDPs. We nevertheless show that for a large class of MDPs, which includes stochastic MDPs such as blackjack and deterministic MDPs such as Go, the Q-function in MC-UCB converges almost surely to the optimal Q function. An immediate corollary of this result is that it also converges almost surely for all finite-horizon MDPs. We also provide numerical experiments, providing further insights into MC-UCB.