 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiao Li
Semantic Satellite Communications Based on Generative Foundation Model
Apr 18, 2024
Satellite communications can provide massive connections and seamless coverage, but they also face several challenges, such as rain attenuation, long propagation delays, and co-channel interference. To improve transmission efficiency and address severe scenarios, semantic communication has become a popular choice, particularly when equipped with foundation models (FMs). In this study, we introduce an FM-based semantic satellite communication framework, termed FMSAT. This framework leverages FM-based segmentation and reconstruction to significantly reduce bandwidth requirements and accurately recover semantic features under high noise and interference. Considering the high speed of satellites, an adaptive encoder-decoder is proposed to protect important features and avoid frequent retransmissions. Meanwhile, a well-received image can provide a reference for repairing damaged images under sudden attenuation. Since acknowledgment feedback is subject to long propagation delays when retransmission is unavoidable, a novel error detection method is proposed to roughly detect semantic errors at the regenerative satellite. With the proposed detectors at both the satellite and the gateway, the quality of the received images can be ensured. The simulation results demonstrate that the proposed method can significantly reduce bandwidth requirements, adapt to complex satellite scenarios, and protect semantic information with an acceptable transmission delay.
Exploring Key Point Analysis with Pairwise Generation and Graph Partitioning
Apr 17, 2024Key Point Analysis (KPA), the summarization of multiple arguments into a concise collection of key points, continues to be a significant and unresolved issue within the field of argument mining. Existing models adapt a two-stage pipeline of clustering arguments or generating key points for argument clusters. This approach rely on semantic similarity instead of measuring the existence of shared key points among arguments. Additionally, it only models the intra-cluster relationship among arguments, disregarding the inter-cluster relationship between arguments that do not share key points. To address these limitations, we propose a novel approach for KPA with pairwise generation and graph partitioning. Our objective is to train a generative model that can simultaneously provide a score indicating the presence of shared key point between a pair of arguments and generate the shared key point. Subsequently, to map generated redundant key points to a concise set of key points, we proceed to construct an arguments graph by considering the arguments as vertices, the generated key points as edges, and the scores as edge weights. We then propose a graph partitioning algorithm to partition all arguments sharing the same key points to the same subgraph. Notably, our experimental findings demonstrate that our proposed model surpasses previous models when evaluated on both the ArgKP and QAM datasets.
BAdam: A Memory Efficient Full Parameter Training Method for Large Language Models
Apr 03, 2024This work presents BAdam, an optimizer that leverages the block coordinate optimization framework with Adam as the inner solver. BAdam offers a memory efficient approach to the full parameter finetuning of large language models and reduces running time of the backward process thanks to the chain rule property. Experimentally, we apply BAdam to instruction-tune the Llama 2-7B model on the Alpaca-GPT4 dataset using a single RTX3090-24GB GPU. The results indicate that BAdam exhibits superior convergence behavior in comparison to LoRA and LOMO. Furthermore, our downstream performance evaluation of the instruction-tuned models using the MT-bench shows that BAdam modestly surpasses LoRA and more substantially outperforms LOMO. Finally, we compare BAdam with Adam on a medium-sized task, i.e., finetuning RoBERTa-large on the SuperGLUE benchmark. The results demonstrate that BAdam is capable of narrowing the performance gap with Adam. Our code is available at https://github.com/Ledzy/BAdam.
Autonomous Driving With Perception Uncertainties: Deep-Ensemble Based Adaptive Cruise Control
Mar 22, 2024Autonomous driving depends on perception systems to understand the environment and to inform downstream decision-making. While advanced perception systems utilizing black-box Deep Neural Networks (DNNs) demonstrate human-like comprehension, their unpredictable behavior and lack of interpretability may hinder their deployment in safety critical scenarios. In this paper, we develop an Ensemble of DNN regressors (Deep Ensemble) that generates predictions with quantification of prediction uncertainties. In the scenario of Adaptive Cruise Control (ACC), we employ the Deep Ensemble to estimate distance headway to the lead vehicle from RGB images and enable the downstream controller to account for the estimation uncertainty. We develop an adaptive cruise controller that utilizes Stochastic Model Predictive Control (MPC) with chance constraints to provide a probabilistic safety guarantee. We evaluate our ACC algorithm using a high-fidelity traffic simulator and a real-world traffic dataset and demonstrate the ability of the proposed approach to effect speed tracking and car following while maintaining a safe distance headway. The out-of-distribution scenarios are also examined.
RCoCo: Contrastive Collective Link Prediction across Multiplex Network in Riemannian Space
Mar 04, 2024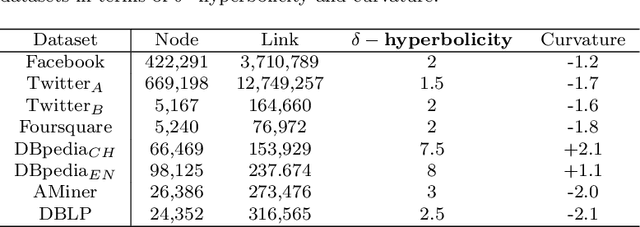
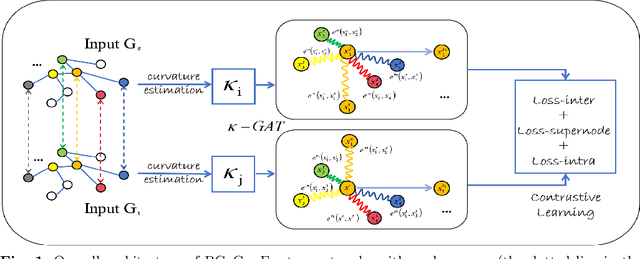

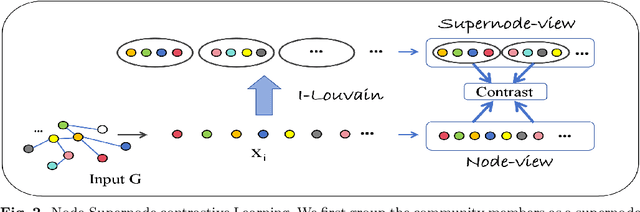
Link prediction typically studies the probability of future interconnection among nodes with the observation in a single social network. More often than not, real scenario is presented as a multiplex network with common (anchor) users active in multiple social networks. In the literature, most existing works study either the intra-link prediction in a single network or inter-link prediction among networks (a.k.a. network alignment), and consider two learning tasks are independent from each other, which is still away from the fact. On the representation space, the vast majority of existing methods are built upon the traditional Euclidean space, unaware of the inherent geometry of social networks. The third issue is on the scarce anchor users. Annotating anchor users is laborious and expensive, and thus it is impractical to work with quantities of anchor users. Herein, in light of the issues above, we propose to study a challenging yet practical problem of Geometry-aware Collective Link Prediction across Multiplex Network. To address this problem, we present a novel contrastive model, RCoCo, which collaborates intra- and inter-network behaviors in Riemannian spaces. In RCoCo, we design a curvature-aware graph attention network ($\kappa-$GAT), conducting attention mechanism in Riemannian manifold whose curvature is estimated by the Ricci curvatures over the network. Thereafter, we formulate intra- and inter-contrastive loss in the manifolds, in which we augment graphs by exploring the high-order structure of community and information transfer on anchor users. Finally, we conduct extensive experiments with 14 strong baselines on 8 real-world datasets, and show the effectiveness of RCoCo.
FormulaQA: A Question Answering Dataset for Formula-Based Numerical Reasoning
Feb 21, 2024The application of formulas is a fundamental ability of humans when addressing numerical reasoning problems. However, existing numerical reasoning datasets seldom explicitly indicate the formulas employed during the reasoning steps. To bridge this gap, we propose a question answering dataset for formula-based numerical reasoning called FormulaQA, from junior high school physics examinations. We further conduct evaluations on LLMs with size ranging from 7B to over 100B parameters utilizing zero-shot and few-shot chain-of-thoughts methods and we explored the approach of using retrieval-augmented LLMs when providing an external formula database. We also fine-tune on smaller models with size not exceeding 2B. Our empirical findings underscore the significant potential for improvement in existing models when applied to our complex, formula-driven FormulaQA.
System-level Safety Guard: Safe Tracking Control through Uncertain Neural Network Dynamics Models
Dec 11, 2023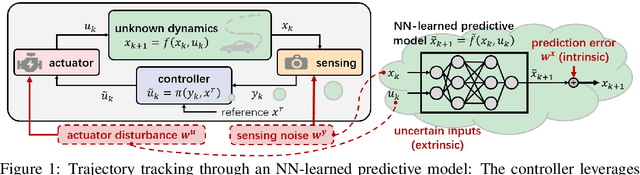
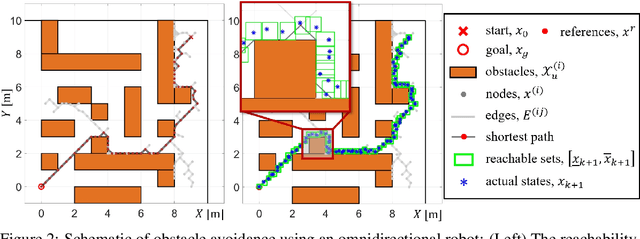
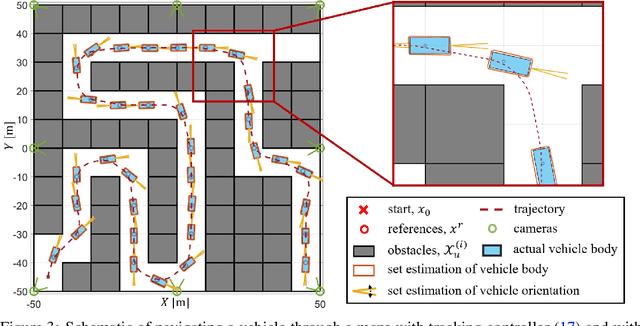
The Neural Network (NN), as a black-box function approximator, has been considered in many control and robotics applications. However, difficulties in verifying the overall system safety in the presence of uncertainties hinder the modular deployment of NN in safety-critical systems. In this paper, we leverage the NNs as predictive models for trajectory tracking of unknown dynamical systems. We consider controller design in the presence of both intrinsic uncertainty and uncertainties from other system modules. In this setting, we formulate the constrained trajectory tracking problem and show that it can be solved using Mixed-integer Linear Programming (MILP). The proposed MILP-based solution enjoys a provable safety guarantee for the overall system, and the approach is empirically demonstrated in robot navigation and obstacle avoidance through simulations. The demonstration videos are available at https://xiaolisean.github.io/publication/2023-11-01-L4DC2024.
High Probability Guarantees for Random Reshuffling
Dec 08, 2023We consider the stochastic gradient method with random reshuffling ($\mathsf{RR}$) for tackling smooth nonconvex optimization problems. $\mathsf{RR}$ finds broad applications in practice, notably in training neural networks. In this work, we first investigate the concentration property of $\mathsf{RR}$'s sampling procedure and establish a new high probability sample complexity guarantee for driving the gradient (without expectation) below $\varepsilon$, which effectively characterizes the efficiency of a single $\mathsf{RR}$ execution. Our derived complexity matches the best existing in-expectation one up to a logarithmic term while imposing no additional assumptions nor changing $\mathsf{RR}$'s updating rule. Furthermore, by leveraging our derived high probability descent property and bound on the stochastic error, we propose a simple and computable stopping criterion for $\mathsf{RR}$ (denoted as $\mathsf{RR}$-$\mathsf{sc}$). This criterion is guaranteed to be triggered after a finite number of iterations, and then $\mathsf{RR}$-$\mathsf{sc}$ returns an iterate with its gradient below $\varepsilon$ with high probability. Moreover, building on the proposed stopping criterion, we design a perturbed random reshuffling method ($\mathsf{p}$-$\mathsf{RR}$) that involves an additional randomized perturbation procedure near stationary points. We derive that $\mathsf{p}$-$\mathsf{RR}$ provably escapes strict saddle points and efficiently returns a second-order stationary point with high probability, without making any sub-Gaussian tail-type assumptions on the stochastic gradient errors. Finally, we conduct numerical experiments on neural network training to support our theoretical findings.
A New Random Reshuffling Method for Nonsmooth Nonconvex Finite-sum Optimization
Dec 02, 2023In this work, we propose and study a novel stochastic optimization algorithm, termed the normal map-based proximal random reshuffling (norm-PRR) method, for nonsmooth nonconvex finite-sum problems. Random reshuffling techniques are prevalent and widely utilized in large-scale applications, e.g., in the training of neural networks. While the convergence behavior and advantageous acceleration effects of random reshuffling methods are fairly well understood in the smooth setting, much less seems to be known in the nonsmooth case and only few proximal-type random reshuffling approaches with provable guarantees exist. We establish the iteration complexity ${\cal O}(n^{-1/3}T^{-2/3})$ for norm-PRR, where $n$ is the number of component functions and $T$ counts the total number of iteration. We also provide novel asymptotic convergence results for norm-PRR. Specifically, under the Kurdyka-{\L}ojasiewicz (KL) inequality, we establish strong limit-point convergence, i.e., the iterates generated by norm-PRR converge to a single stationary point. Moreover, we derive last iterate convergence rates of the form ${\cal O}(k^{-p})$; here, $p \in [0, 1]$ depends on the KL exponent $\theta \in [0,1)$ and step size dynamics. Finally, we present preliminary numerical results on machine learning problems that demonstrate the efficiency of the proposed method.
Low-Complexity Joint Beamforming for RIS-Assisted MU-MISO Systems Based on Model-Driven Deep Learning
Nov 26, 2023Reconfigurable intelligent surfaces (RIS) can improve signal propagation environments by adjusting the phase of the incident signal. However, optimizing the phase shifts jointly with the beamforming vector at the access point is challenging due to the non-convex objective function and constraints. In this study, we propose an algorithm based on weighted minimum mean square error optimization and power iteration to maximize the weighted sum rate (WSR) of a RIS-assisted downlink multi-user multiple-input single-output system. To further improve performance, a model-driven deep learning (DL) approach is designed, where trainable variables and graph neural networks are introduced to accelerate the convergence of the proposed algorithm. We also extend the proposed method to include beamforming with imperfect channel state information and derive a two-timescale stochastic optimization algorithm. Simulation results show that the proposed algorithm outperforms state-of-the-art algorithms in terms of complexity and WSR. Specifically, the model-driven DL approach has a runtime that is approximately 3% of the state-of-the-art algorithm to achieve the same performance. Additionally, the proposed algorithm with 2-bit phase shifters outperforms the compared algorithm with continuous phase shift.