 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShen Huang
Exploring Key Point Analysis with Pairwise Generation and Graph Partitioning
Apr 17, 2024
Key Point Analysis (KPA), the summarization of multiple arguments into a concise collection of key points, continues to be a significant and unresolved issue within the field of argument mining. Existing models adapt a two-stage pipeline of clustering arguments or generating key points for argument clusters. This approach rely on semantic similarity instead of measuring the existence of shared key points among arguments. Additionally, it only models the intra-cluster relationship among arguments, disregarding the inter-cluster relationship between arguments that do not share key points. To address these limitations, we propose a novel approach for KPA with pairwise generation and graph partitioning. Our objective is to train a generative model that can simultaneously provide a score indicating the presence of shared key point between a pair of arguments and generate the shared key point. Subsequently, to map generated redundant key points to a concise set of key points, we proceed to construct an arguments graph by considering the arguments as vertices, the generated key points as edges, and the scores as edge weights. We then propose a graph partitioning algorithm to partition all arguments sharing the same key points to the same subgraph. Notably, our experimental findings demonstrate that our proposed model surpasses previous models when evaluated on both the ArgKP and QAM datasets.
EcomGPT-CT: Continual Pre-training of E-commerce Large Language Models with Semi-structured Data
Dec 25, 2023Large Language Models (LLMs) pre-trained on massive corpora have exhibited remarkable performance on various NLP tasks. However, applying these models to specific domains still poses significant challenges, such as lack of domain knowledge, limited capacity to leverage domain knowledge and inadequate adaptation to domain-specific data formats. Considering the exorbitant cost of training LLMs from scratch and the scarcity of annotated data within particular domains, in this work, we focus on domain-specific continual pre-training of LLMs using E-commerce domain as an exemplar. Specifically, we explore the impact of continual pre-training on LLMs employing unlabeled general and E-commercial corpora. Furthermore, we design a mixing strategy among different data sources to better leverage E-commercial semi-structured data. We construct multiple tasks to assess LLMs' few-shot In-context Learning ability and their zero-shot performance after instruction tuning in E-commerce domain. Experimental results demonstrate the effectiveness of continual pre-training of E-commerce LLMs and the efficacy of our devised data mixing strategy.
EcomGPT: Instruction-tuning Large Language Models with Chain-of-Task Tasks for E-commerce
Aug 28, 2023



Recently, instruction-following Large Language Models (LLMs) , represented by ChatGPT, have exhibited exceptional performance in general Natural Language Processing (NLP) tasks. However, the unique characteristics of E-commerce data pose significant challenges to general LLMs. An LLM tailored specifically for E-commerce scenarios, possessing robust cross-dataset/task generalization capabilities, is a pressing necessity. To solve this issue, in this work, we proposed the first e-commerce instruction dataset EcomInstruct, with a total of 2.5 million instruction data. EcomInstruct scales up the data size and task diversity by constructing atomic tasks with E-commerce basic data types, such as product information, user reviews. Atomic tasks are defined as intermediate tasks implicitly involved in solving a final task, which we also call Chain-of-Task tasks. We developed EcomGPT with different parameter scales by training the backbone model BLOOMZ with the EcomInstruct. Benefiting from the fundamental semantic understanding capabilities acquired from the Chain-of-Task tasks, EcomGPT exhibits excellent zero-shot generalization capabilities. Extensive experiments and human evaluations demonstrate that EcomGPT outperforms ChatGPT in term of cross-dataset/task generalization on E-commerce tasks.
SeqGPT: An Out-of-the-box Large Language Model for Open Domain Sequence Understanding
Aug 21, 2023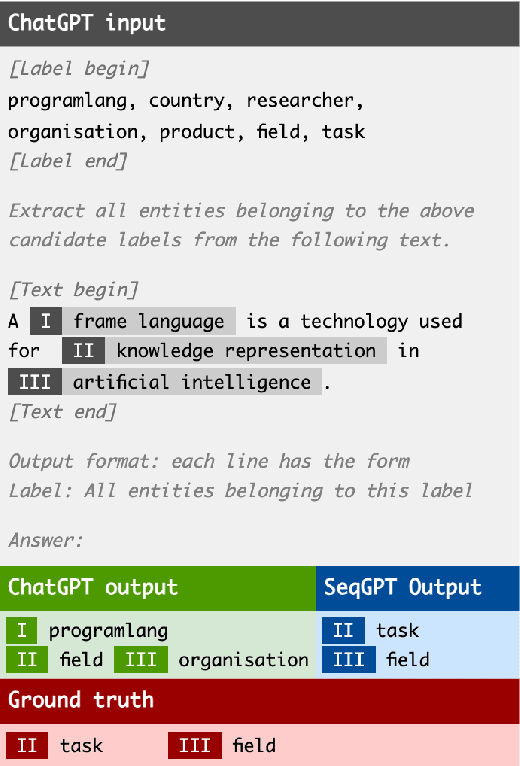
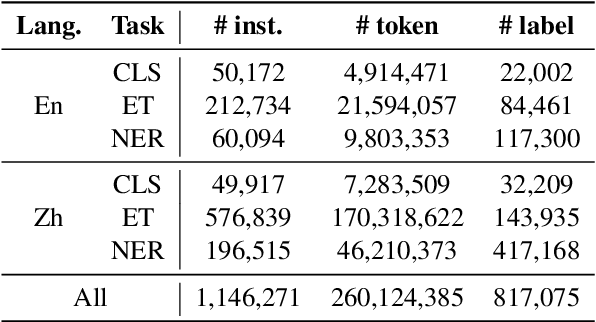

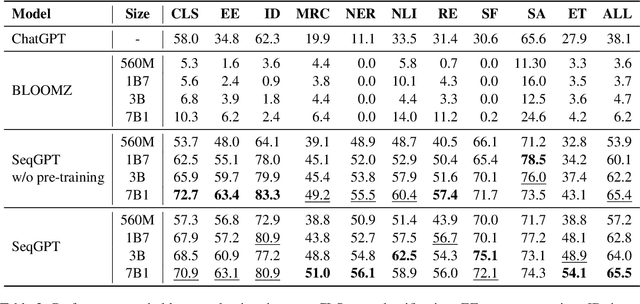
Large language models (LLMs) have shown impressive ability for open-domain NLP tasks. However, LLMs are sometimes too footloose for natural language understanding (NLU) tasks which always have restricted output and input format. Their performances on NLU tasks are highly related to prompts or demonstrations and are shown to be poor at performing several representative NLU tasks, such as event extraction and entity typing. To this end, we present SeqGPT, a bilingual (i.e., English and Chinese) open-source autoregressive model specially enhanced for open-domain natural language understanding. We express all NLU tasks with two atomic tasks, which define fixed instructions to restrict the input and output format but still ``open'' for arbitrarily varied label sets. The model is first instruction-tuned with extremely fine-grained labeled data synthesized by ChatGPT and then further fine-tuned by 233 different atomic tasks from 152 datasets across various domains. The experimental results show that SeqGPT has decent classification and extraction ability, and is capable of performing language understanding tasks on unseen domains. We also conduct empirical studies on the scaling of data and model size as well as on the transfer across tasks. Our model is accessible at https://github.com/Alibaba-NLP/SeqGPT.
Beam Retrieval: General End-to-End Retrieval for Multi-Hop Question Answering
Aug 17, 2023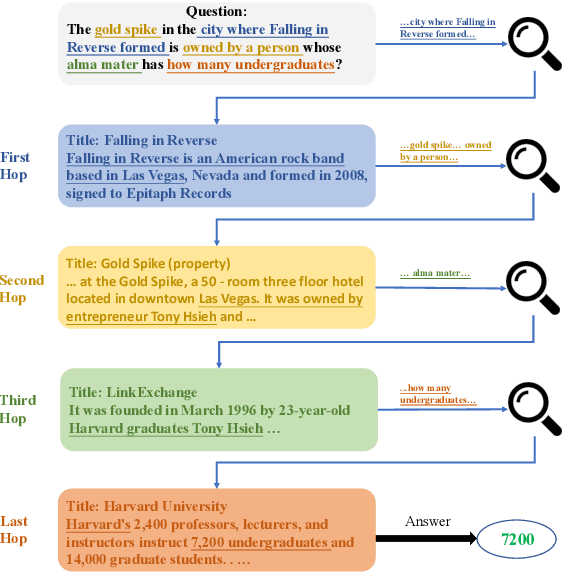
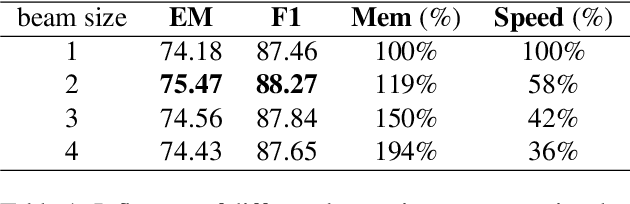
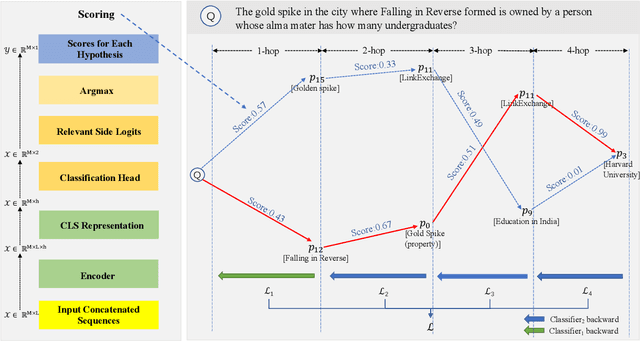
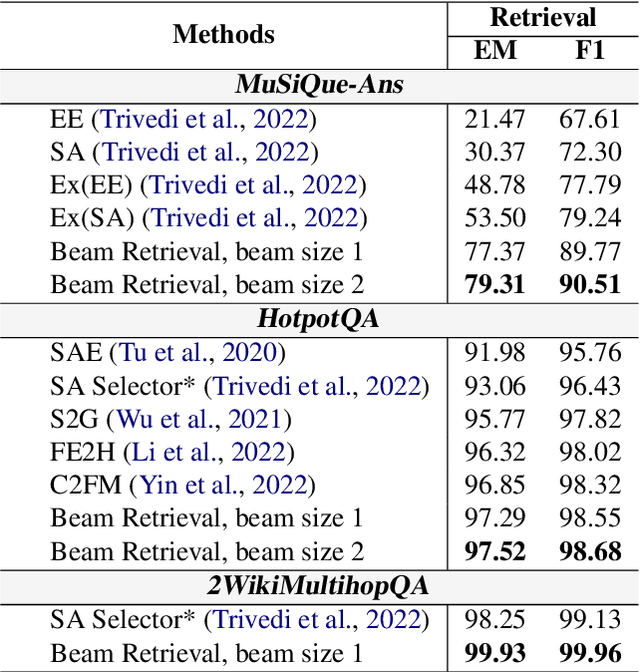
Multi-hop QA involves finding multiple relevant passages and step-by-step reasoning to answer complex questions. While previous approaches have developed retrieval modules for selecting relevant passages, they face challenges in scenarios beyond two hops, owing to the limited performance of one-step methods and the failure of two-step methods when selecting irrelevant passages in earlier stages. In this work, we introduce Beam Retrieval, a general end-to-end retrieval framework for multi-hop QA. This approach maintains multiple partial hypotheses of relevant passages at each step, expanding the search space and reducing the risk of missing relevant passages. Moreover, Beam Retrieval jointly optimizes an encoder and two classification heads by minimizing the combined loss across all hops. To establish a complete QA system, we incorporate a supervised reader or a zero-shot GPT-3.5. Experimental results demonstrate that Beam Retrieval achieves a nearly 50% improvement compared with baselines on challenging MuSiQue-Ans, and it also surpasses all previous retrievers on HotpotQA and 2WikiMultiHopQA. Providing high-quality context, Beam Retrieval helps our supervised reader achieve new state-of-the-art performance and substantially improves (up to 28.8 points) the QA performance of zero-shot GPT-3.5.
Bidirectional End-to-End Learning of Retriever-Reader Paradigm for Entity Linking
Jul 03, 2023



Entity Linking (EL) is a fundamental task for Information Extraction and Knowledge Graphs. The general form of EL (i.e., end-to-end EL) aims to first find mentions in the given input document and then link the mentions to corresponding entities in a specific knowledge base. Recently, the paradigm of retriever-reader promotes the progress of end-to-end EL, benefiting from the advantages of dense entity retrieval and machine reading comprehension. However, the existing study only trains the retriever and the reader separately in a pipeline manner, which ignores the benefit that the interaction between the retriever and the reader can bring to the task. To advance the retriever-reader paradigm to perform more perfectly on end-to-end EL, we propose BEER$^2$, a Bidirectional End-to-End training framework for Retriever and Reader. Through our designed bidirectional end-to-end training, BEER$^2$ guides the retriever and the reader to learn from each other, make progress together, and ultimately improve EL performance. Extensive experiments on benchmarks of multiple domains demonstrate the effectiveness of our proposed BEER$^2$.
DAMO-NLP at SemEval-2023 Task 2: A Unified Retrieval-augmented System for Multilingual Named Entity Recognition
May 09, 2023

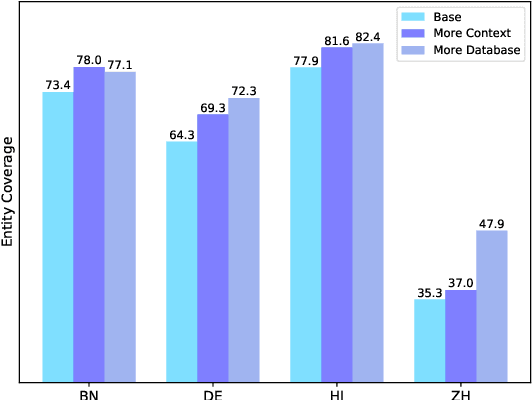
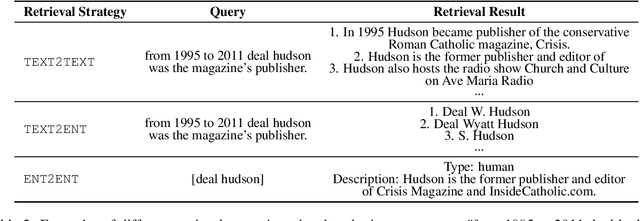
The MultiCoNER \RNum{2} shared task aims to tackle multilingual named entity recognition (NER) in fine-grained and noisy scenarios, and it inherits the semantic ambiguity and low-context setting of the MultiCoNER \RNum{1} task. To cope with these problems, the previous top systems in the MultiCoNER \RNum{1} either incorporate the knowledge bases or gazetteers. However, they still suffer from insufficient knowledge, limited context length, single retrieval strategy. In this paper, our team \textbf{DAMO-NLP} proposes a unified retrieval-augmented system (U-RaNER) for fine-grained multilingual NER. We perform error analysis on the previous top systems and reveal that their performance bottleneck lies in insufficient knowledge. Also, we discover that the limited context length causes the retrieval knowledge to be invisible to the model. To enhance the retrieval context, we incorporate the entity-centric Wikidata knowledge base, while utilizing the infusion approach to broaden the contextual scope of the model. Also, we explore various search strategies and refine the quality of retrieval knowledge. Our system\footnote{We will release the dataset, code, and scripts of our system at {\small \url{https://github.com/modelscope/AdaSeq/tree/master/examples/U-RaNER}}.} wins 9 out of 13 tracks in the MultiCoNER \RNum{2} shared task. Additionally, we compared our system with ChatGPT, one of the large language models which have unlocked strong capabilities on many tasks. The results show that there is still much room for improvement for ChatGPT on the extraction task.
Zero-Shot Information Extraction via Chatting with ChatGPT
Feb 20, 2023



Zero-shot information extraction (IE) aims to build IE systems from the unannotated text. It is challenging due to involving little human intervention. Challenging but worthwhile, zero-shot IE reduces the time and effort that data labeling takes. Recent efforts on large language models (LLMs, e.g., GPT-3, ChatGPT) show promising performance on zero-shot settings, thus inspiring us to explore prompt-based methods. In this work, we ask whether strong IE models can be constructed by directly prompting LLMs. Specifically, we transform the zero-shot IE task into a multi-turn question-answering problem with a two-stage framework (ChatIE). With the power of ChatGPT, we extensively evaluate our framework on three IE tasks: entity-relation triple extract, named entity recognition, and event extraction. Empirical results on six datasets across two languages show that ChatIE achieves impressive performance and even surpasses some full-shot models on several datasets (e.g., NYT11-HRL). We believe that our work could shed light on building IE models with limited resources.
DAMO-NLP at NLPCC-2022 Task 2: Knowledge Enhanced Robust NER for Speech Entity Linking
Sep 29, 2022Speech Entity Linking aims to recognize and disambiguate named entities in spoken languages. Conventional methods suffer gravely from the unfettered speech styles and the noisy transcripts generated by ASR systems. In this paper, we propose a novel approach called Knowledge Enhanced Named Entity Recognition (KENER), which focuses on improving robustness through painlessly incorporating proper knowledge in the entity recognition stage and thus improving the overall performance of entity linking. KENER first retrieves candidate entities for a sentence without mentions, and then utilizes the entity descriptions as extra information to help recognize mentions. The candidate entities retrieved by a dense retrieval module are especially useful when the input is short or noisy. Moreover, we investigate various data sampling strategies and design effective loss functions, in order to improve the quality of retrieved entities in both recognition and disambiguation stages. Lastly, a linking with filtering module is applied as the final safeguard, making it possible to filter out wrongly-recognized mentions. Our system achieves 1st place in Track 1 and 2nd place in Track 2 of NLPCC-2022 Shared Task 2.
Leveraging Phone Mask Training for Phonetic-Reduction-Robust E2E Uyghur Speech Recognition
Apr 02, 2022



In Uyghur speech, consonant and vowel reduction are often encountered, especially in spontaneous speech with high speech rate, which will cause a degradation of speech recognition performance. To solve this problem, we propose an effective phone mask training method for Conformer-based Uyghur end-to-end (E2E) speech recognition. The idea is to randomly mask off a certain percentage features of phones during model training, which simulates the above verbal phenomena and facilitates E2E model to learn more contextual information. According to experiments, the above issues can be greatly alleviated. In addition, deep investigations are carried out into different units in masking, which shows the effectiveness of our proposed masking unit. We also further study the masking method and optimize filling strategy of phone mask. Finally, compared with Conformer-based E2E baseline without mask training, our model demonstrates about 5.51% relative Word Error Rate (WER) reduction on reading speech and 12.92% on spontaneous speech, respectively. The above approach has also been verified on test-set of open-source data THUYG-20, which shows 20% relative improvements.
* Accepted by INTERSPEECH 2021