 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKewei Tu
RoT: Enhancing Large Language Models with Reflection on Search Trees
Apr 11, 2024
Large language models (LLMs) have demonstrated impressive capability in reasoning and planning when integrated with tree-search-based prompting methods. However, since these methods ignore the previous search experiences, they often make the same mistakes in the search process. To address this issue, we introduce Reflection on search Trees (RoT), an LLM reflection framework designed to improve the performance of tree-search-based prompting methods. It uses a strong LLM to summarize guidelines from previous tree search experiences to enhance the ability of a weak LLM. The guidelines are instructions about solving this task through tree search which can prevent the weak LLMs from making similar mistakes in the past search process. In addition, we proposed a novel state selection method, which identifies the critical information from historical search processes to help RoT generate more specific and meaningful guidelines. In our extensive experiments, we find that RoT significantly improves the performance of LLMs in reasoning or planning tasks with various tree-search-based prompting methods (e.g., BFS and MCTS). Non-tree-search-based prompting methods such as Chain-of-Thought (CoT) can also benefit from RoT guidelines since RoT can provide task-specific knowledge collected from the search experience.
Improving Retrieval Augmented Open-Domain Question-Answering with Vectorized Contexts
Apr 02, 2024In the era of large language models, applying techniques such as Retrieval Augmented Generation can better address Open-Domain Question-Answering problems. Due to constraints including model sizes and computing resources, the length of context is often limited, and it becomes challenging to empower the model to cover overlong contexts while answering questions from open domains. This paper proposes a general and convenient method to covering longer contexts in Open-Domain Question-Answering tasks. It leverages a small encoder language model that effectively encodes contexts, and the encoding applies cross-attention with origin inputs. With our method, the origin language models can cover several times longer contexts while keeping the computing requirements close to the baseline. Our experiments demonstrate that after fine-tuning, there is improved performance across two held-in datasets, four held-out datasets, and also in two In Context Learning settings.
Using Interpretation Methods for Model Enhancement
Apr 02, 2024In the age of neural natural language processing, there are plenty of works trying to derive interpretations of neural models. Intuitively, when gold rationales exist during training, one can additionally train the model to match its interpretation with the rationales. However, this intuitive idea has not been fully explored. In this paper, we propose a framework of utilizing interpretation methods and gold rationales to enhance models. Our framework is very general in the sense that it can incorporate various interpretation methods. Previously proposed gradient-based methods can be shown as an instance of our framework. We also propose two novel instances utilizing two other types of interpretation methods, erasure/replace-based and extractor-based methods, for model enhancement. We conduct comprehensive experiments on a variety of tasks. Experimental results show that our framework is effective especially in low-resource settings in enhancing models with various interpretation methods, and our two newly-proposed methods outperform gradient-based methods in most settings. Code is available at https://github.com/Chord-Chen-30/UIMER.
* EMNLP 2023
Generative Pretrained Structured Transformers: Unsupervised Syntactic Language Models at Scale
Mar 18, 2024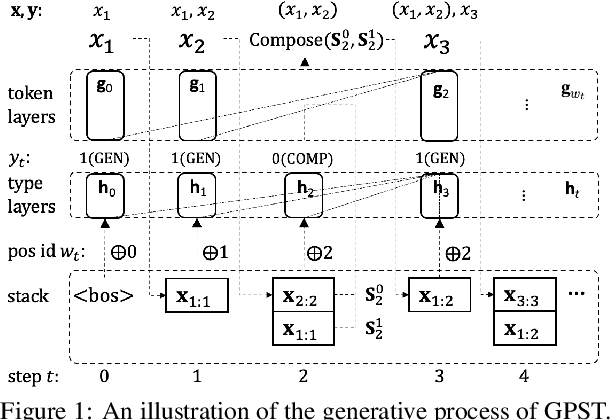
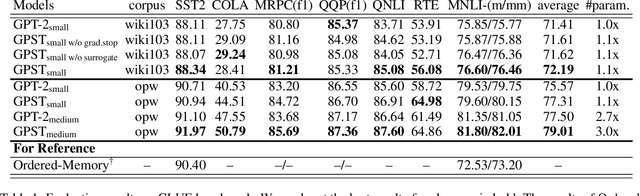

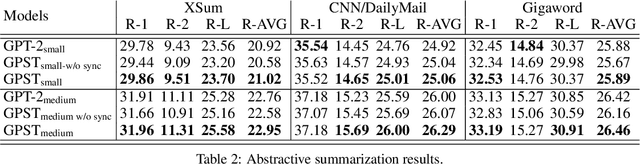
A syntactic language model (SLM) incrementally generates a sentence with its syntactic tree in a left-to-right manner. We present Generative Pretrained Structured Transformers (GPST), an unsupervised SLM at scale capable of being pre-trained from scratch on raw texts with high parallelism. GPST circumvents the limitations of previous SLMs such as relying on gold trees and sequential training. It consists of two components, a usual SLM supervised by a uni-directional language modeling loss, and an additional composition model, which induces syntactic parse trees and computes constituent representations, supervised by a bi-directional language modeling loss. We propose a representation surrogate to enable joint parallel training of the two models in a hard-EM fashion. We pre-train GPST on OpenWebText, a corpus with $9$ billion tokens, and demonstrate the superiority of GPST over GPT-2 with a comparable size in numerous tasks covering both language understanding and language generation. Meanwhile, GPST also significantly outperforms existing unsupervised SLMs on left-to-right grammar induction, while holding a substantial acceleration on training.
Probabilistic Transformer: A Probabilistic Dependency Model for Contextual Word Representation
Nov 26, 2023Syntactic structures used to play a vital role in natural language processing (NLP), but since the deep learning revolution, NLP has been gradually dominated by neural models that do not consider syntactic structures in their design. One vastly successful class of neural models is transformers. When used as an encoder, a transformer produces contextual representation of words in the input sentence. In this work, we propose a new model of contextual word representation, not from a neural perspective, but from a purely syntactic and probabilistic perspective. Specifically, we design a conditional random field that models discrete latent representations of all words in a sentence as well as dependency arcs between them; and we use mean field variational inference for approximate inference. Strikingly, we find that the computation graph of our model resembles transformers, with correspondences between dependencies and self-attention and between distributions over latent representations and contextual embeddings of words. Experiments show that our model performs competitively to transformers on small to medium sized datasets. We hope that our work could help bridge the gap between traditional syntactic and probabilistic approaches and cutting-edge neural approaches to NLP, and inspire more linguistically-principled neural approaches in the future.
Conic10K: A Challenging Math Problem Understanding and Reasoning Dataset
Nov 09, 2023Mathematical understanding and reasoning are crucial tasks for assessing the capabilities of artificial intelligence (AI). However, existing benchmarks either require just a few steps of reasoning, or only contain a small amount of data in one specific topic, making it hard to analyse AI's behaviour with reference to different problems within a specific topic in detail. In this work, we propose Conic10K, a challenging math problem dataset on conic sections in Chinese senior high school education. Our dataset contains various problems with different reasoning depths, while only the knowledge from conic sections is required. Since the dataset only involves a narrow range of knowledge, it is easy to separately analyse the knowledge a model possesses and the reasoning ability it has. For each problem, we provide a high-quality formal representation, the reasoning steps, and the final solution. Experiments show that existing large language models, including GPT-4, exhibit weak performance on complex reasoning. We hope that our findings could inspire more advanced techniques for precise natural language understanding and reasoning. Our dataset and codes are available at https://github.com/whyNLP/Conic10K.
Joint Entity and Relation Extraction with Span Pruning and Hypergraph Neural Networks
Oct 26, 2023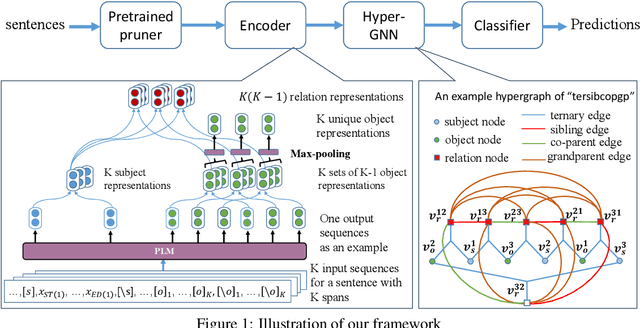
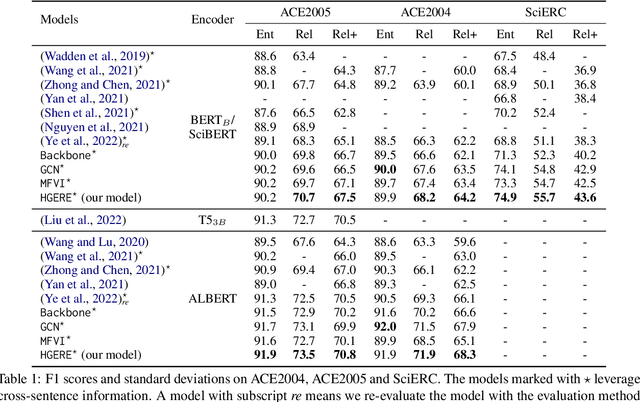
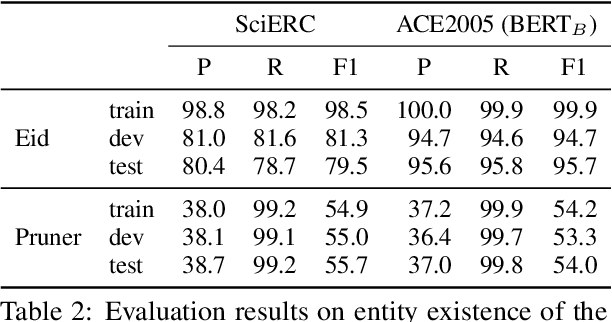
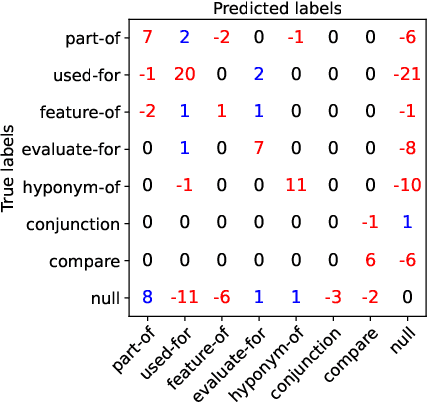
Entity and Relation Extraction (ERE) is an important task in information extraction. Recent marker-based pipeline models achieve state-of-the-art performance, but still suffer from the error propagation issue. Also, most of current ERE models do not take into account higher-order interactions between multiple entities and relations, while higher-order modeling could be beneficial.In this work, we propose HyperGraph neural network for ERE ($\hgnn{}$), which is built upon the PL-marker (a state-of-the-art marker-based pipleline model). To alleviate error propagation,we use a high-recall pruner mechanism to transfer the burden of entity identification and labeling from the NER module to the joint module of our model. For higher-order modeling, we build a hypergraph, where nodes are entities (provided by the span pruner) and relations thereof, and hyperedges encode interactions between two different relations or between a relation and its associated subject and object entities. We then run a hypergraph neural network for higher-order inference by applying message passing over the built hypergraph. Experiments on three widely used benchmarks (\acef{}, \ace{} and \scierc{}) for ERE task show significant improvements over the previous state-of-the-art PL-marker.
Simple Hardware-Efficient PCFGs with Independent Left and Right Productions
Oct 23, 2023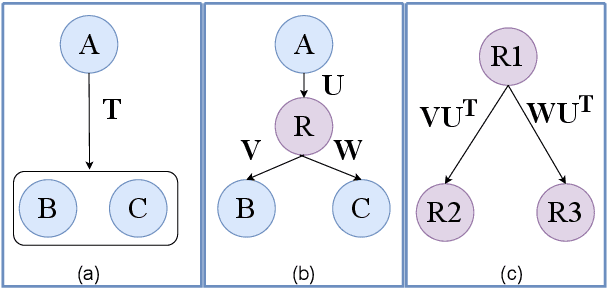
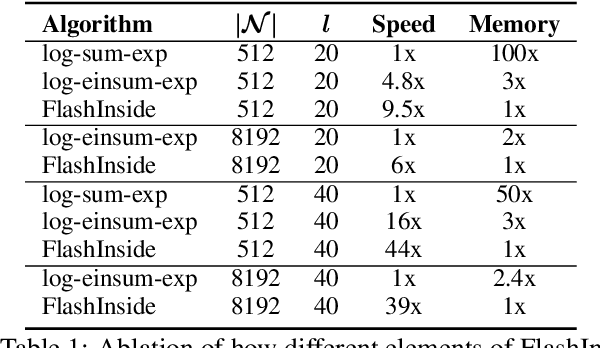
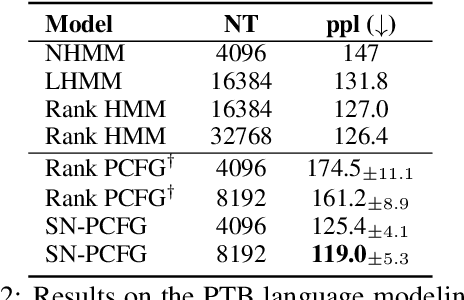
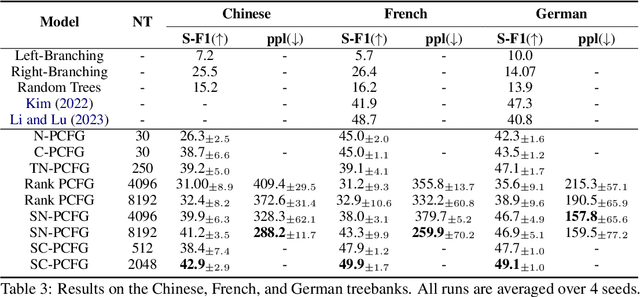
Scaling dense PCFGs to thousands of nonterminals via a low-rank parameterization of the rule probability tensor has been shown to be beneficial for unsupervised parsing. However, PCFGs scaled this way still perform poorly as a language model, and even underperform similarly-sized HMMs. This work introduces \emph{SimplePCFG}, a simple PCFG formalism with independent left and right productions. Despite imposing a stronger independence assumption than the low-rank approach, we find that this formalism scales more effectively both as a language model and as an unsupervised parser. As an unsupervised parser, our simple PCFG obtains an average F1 of 65.1 on the English PTB, and as a language model, it obtains a perplexity of 119.0, outperforming similarly-sized low-rank PCFGs. We further introduce \emph{FlashInside}, a hardware IO-aware implementation of the inside algorithm for efficiently scaling simple PCFGs.
AMR Parsing with Causal Hierarchical Attention and Pointers
Oct 18, 2023Translation-based AMR parsers have recently gained popularity due to their simplicity and effectiveness. They predict linearized graphs as free texts, avoiding explicit structure modeling. However, this simplicity neglects structural locality in AMR graphs and introduces unnecessary tokens to represent coreferences. In this paper, we introduce new target forms of AMR parsing and a novel model, CHAP, which is equipped with causal hierarchical attention and the pointer mechanism, enabling the integration of structures into the Transformer decoder. We empirically explore various alternative modeling options. Experiments show that our model outperforms baseline models on four out of five benchmarks in the setting of no additional data.
Augmenting transformers with recursively composed multi-grained representations
Sep 28, 2023We present ReCAT, a recursive composition augmented Transformer that is able to explicitly model hierarchical syntactic structures of raw texts without relying on gold trees during both learning and inference. Existing research along this line restricts data to follow a hierarchical tree structure and thus lacks inter-span communications. To overcome the problem, we propose a novel contextual inside-outside (CIO) layer that learns contextualized representations of spans through bottom-up and top-down passes, where a bottom-up pass forms representations of high-level spans by composing low-level spans, while a top-down pass combines information inside and outside a span. By stacking several CIO layers between the embedding layer and the attention layers in Transformer, the ReCAT model can perform both deep intra-span and deep inter-span interactions, and thus generate multi-grained representations fully contextualized with other spans. Moreover, the CIO layers can be jointly pre-trained with Transformers, making ReCAT enjoy scaling ability, strong performance, and interpretability at the same time. We conduct experiments on various sentence-level and span-level tasks. Evaluation results indicate that ReCAT can significantly outperform vanilla Transformer models on all span-level tasks and baselines that combine recursive networks with Transformers on natural language inference tasks. More interestingly, the hierarchical structures induced by ReCAT exhibit strong consistency with human-annotated syntactic trees, indicating good interpretability brought by the CIO layers.