 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNing Cheng
Towards Comprehensive Multimodal Perception: Introducing the Touch-Language-Vision Dataset
Mar 14, 2024

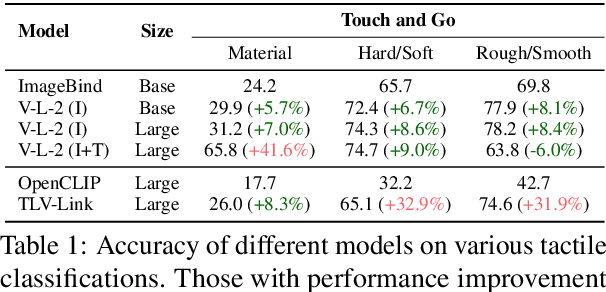
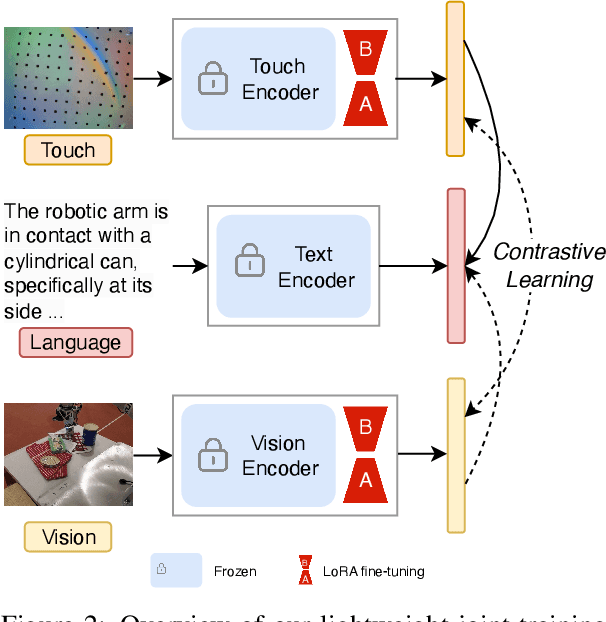
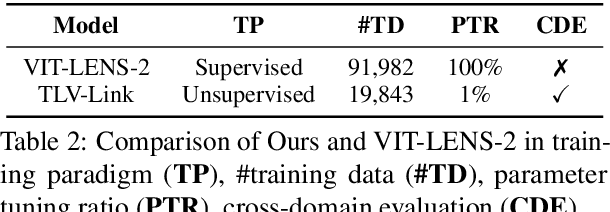
Tactility provides crucial support and enhancement for the perception and interaction capabilities of both humans and robots. Nevertheless, the multimodal research related to touch primarily focuses on visual and tactile modalities, with limited exploration in the domain of language. Beyond vocabulary, sentence-level descriptions contain richer semantics. Based on this, we construct a touch-language-vision dataset named TLV (Touch-Language-Vision) by human-machine cascade collaboration, featuring sentence-level descriptions for multimode alignment. The new dataset is used to fine-tune our proposed lightweight training framework, TLV-Link (Linking Touch, Language, and Vision through Alignment), achieving effective semantic alignment with minimal parameter adjustments (1%). Project Page: https://xiaoen0.github.io/touch.page/.
Medical Speech Symptoms Classification via Disentangled Representation
Mar 08, 2024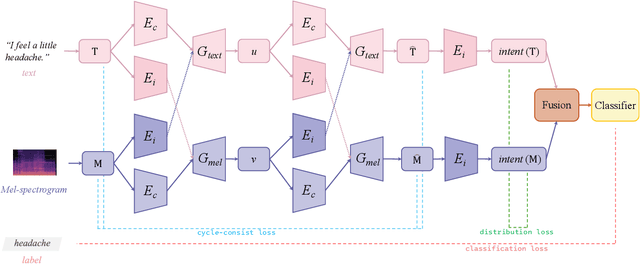
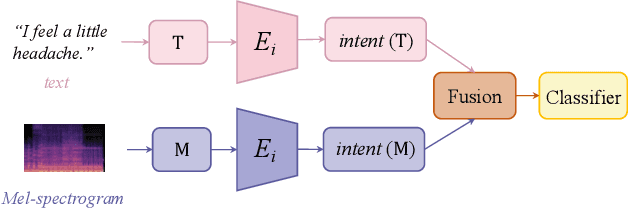
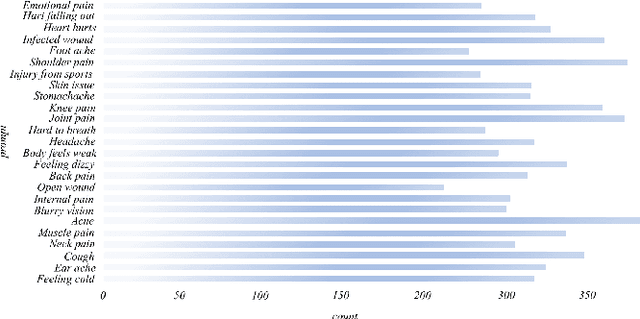
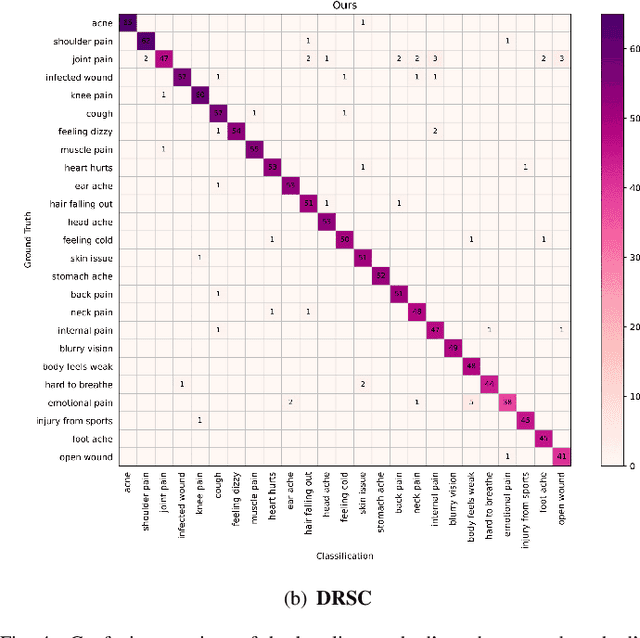
Intent is defined for understanding spoken language in existing works. Both textual features and acoustic features involved in medical speech contain intent, which is important for symptomatic diagnosis. In this paper, we propose a medical speech classification model named DRSC that automatically learns to disentangle intent and content representations from textual-acoustic data for classification. The intent representations of the text domain and the Mel-spectrogram domain are extracted via intent encoders, and then the reconstructed text feature and the Mel-spectrogram feature are obtained through two exchanges. After combining the intent from two domains into a joint representation, the integrated intent representation is fed into a decision layer for classification. Experimental results show that our model obtains an average accuracy rate of 95% in detecting 25 different medical symptoms.
Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning
Feb 01, 2024Instruction tuning is critical to improve LLMs but usually suffers from low-quality and redundant data. Data filtering for instruction tuning has proved important in improving both the efficiency and performance of the tuning process. But it also leads to extra cost and computation due to the involvement of LLMs in this process. To reduce the filtering cost, we study Superfiltering: Can we use a smaller and weaker model to select data for finetuning a larger and stronger model? Despite the performance gap between weak and strong language models, we find their highly consistent capability to perceive instruction difficulty and data selection results. This enables us to use a much smaller and more efficient model to filter the instruction data used to train a larger language model. Not only does it largely speed up the data filtering, but the filtered-data-finetuned LLM achieves even better performance on standard benchmarks. Extensive experiments validate the efficacy and efficiency of our approach.
Learning Disentangled Speech Representations with Contrastive Learning and Time-Invariant Retrieval
Jan 18, 2024Voice conversion refers to transferring speaker identity with well-preserved content. Better disentanglement of speech representations leads to better voice conversion. Recent studies have found that phonetic information from input audio has the potential ability to well represent content. Besides, the speaker-style modeling with pre-trained models making the process more complex. To tackle these issues, we introduce a new method named "CTVC" which utilizes disentangled speech representations with contrastive learning and time-invariant retrieval. Specifically, a similarity-based compression module is used to facilitate a more intimate connection between the frame-level hidden features and linguistic information at phoneme-level. Additionally, a time-invariant retrieval is proposed for timbre extraction based on multiple segmentations and mutual information. Experimental results demonstrate that "CTVC" outperforms previous studies and improves the sound quality and similarity of converted results.
Leveraging Biases in Large Language Models: "bias-kNN'' for Effective Few-Shot Learning
Jan 18, 2024Large Language Models (LLMs) have shown significant promise in various applications, including zero-shot and few-shot learning. However, their performance can be hampered by inherent biases. Instead of traditionally sought methods that aim to minimize or correct these biases, this study introduces a novel methodology named ``bias-kNN''. This approach capitalizes on the biased outputs, harnessing them as primary features for kNN and supplementing with gold labels. Our comprehensive evaluations, spanning diverse domain text classification datasets and different GPT-2 model sizes, indicate the adaptability and efficacy of the ``bias-kNN'' method. Remarkably, this approach not only outperforms conventional in-context learning in few-shot scenarios but also demonstrates robustness across a spectrum of samples, templates and verbalizers. This study, therefore, presents a unique perspective on harnessing biases, transforming them into assets for enhanced model performance.
EmoTalker: Emotionally Editable Talking Face Generation via Diffusion Model
Jan 16, 2024In recent years, the field of talking faces generation has attracted considerable attention, with certain methods adept at generating virtual faces that convincingly imitate human expressions. However, existing methods face challenges related to limited generalization, particularly when dealing with challenging identities. Furthermore, methods for editing expressions are often confined to a singular emotion, failing to adapt to intricate emotions. To overcome these challenges, this paper proposes EmoTalker, an emotionally editable portraits animation approach based on the diffusion model. EmoTalker modifies the denoising process to ensure preservation of the original portrait's identity during inference. To enhance emotion comprehension from text input, Emotion Intensity Block is introduced to analyze fine-grained emotions and strengths derived from prompts. Additionally, a crafted dataset is harnessed to enhance emotion comprehension within prompts. Experiments show the effectiveness of EmoTalker in generating high-quality, emotionally customizable facial expressions.
ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
Jan 16, 2024Existing emotional speech synthesis methods often utilize an utterance-level style embedding extracted from reference audio, neglecting the inherent multi-scale property of speech prosody. We introduce ED-TTS, a multi-scale emotional speech synthesis model that leverages Speech Emotion Diarization (SED) and Speech Emotion Recognition (SER) to model emotions at different levels. Specifically, our proposed approach integrates the utterance-level emotion embedding extracted by SER with fine-grained frame-level emotion embedding obtained from SED. These embeddings are used to condition the reverse process of the denoising diffusion probabilistic model (DDPM). Additionally, we employ cross-domain SED to accurately predict soft labels, addressing the challenge of a scarcity of fine-grained emotion-annotated datasets for supervising emotional TTS training.
DQR-TTS: Semi-supervised Text-to-speech Synthesis with Dynamic Quantized Representation
Nov 29, 2023Most existing neural-based text-to-speech methods rely on extensive datasets and face challenges under low-resource condition. In this paper, we introduce a novel semi-supervised text-to-speech synthesis model that learns from both paired and unpaired data to address this challenge. The key component of the proposed model is a dynamic quantized representation module, which is integrated into a sequential autoencoder. When given paired data, the module incorporates a trainable codebook that learns quantized representations under the supervision of the paired data. However, due to the limited paired data in low-resource scenario, these paired data are difficult to cover all phonemes. Then unpaired data is fed to expand the dynamic codebook by adding quantized representation vectors that are sufficiently distant from the existing ones during training. Experiments show that with less than 120 minutes of paired data, the proposed method outperforms existing methods in both subjective and objective metrics.
CLN-VC: Text-Free Voice Conversion Based on Fine-Grained Style Control and Contrastive Learning with Negative Samples Augmentation
Nov 15, 2023Better disentanglement of speech representation is essential to improve the quality of voice conversion. Recently contrastive learning is applied to voice conversion successfully based on speaker labels. However, the performance of model will reduce in conversion between similar speakers. Hence, we propose an augmented negative sample selection to address the issue. Specifically, we create hard negative samples based on the proposed speaker fusion module to improve learning ability of speaker encoder. Furthermore, considering the fine-grain modeling of speaker style, we employ a reference encoder to extract fine-grained style and conduct the augmented contrastive learning on global style. The experimental results show that the proposed method outperforms previous work in voice conversion tasks.
CP-EB: Talking Face Generation with Controllable Pose and Eye Blinking Embedding
Nov 15, 2023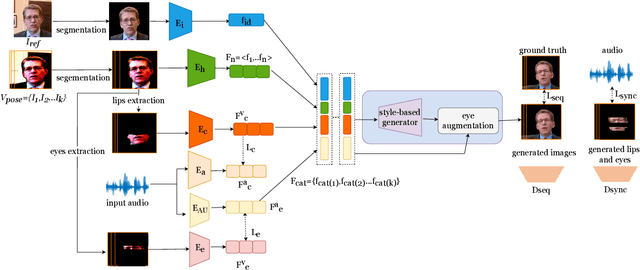
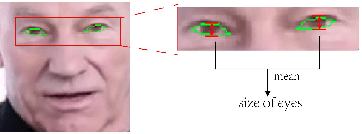
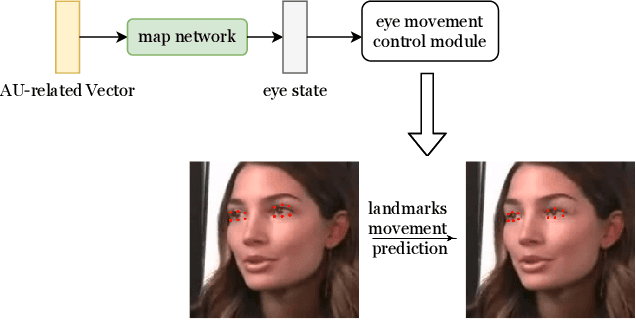

This paper proposes a talking face generation method named "CP-EB" that takes an audio signal as input and a person image as reference, to synthesize a photo-realistic people talking video with head poses controlled by a short video clip and proper eye blinking embedding. It's noted that not only the head pose but also eye blinking are both important aspects for deep fake detection. The implicit control of poses by video has already achieved by the state-of-art work. According to recent research, eye blinking has weak correlation with input audio which means eye blinks extraction from audio and generation are possible. Hence, we propose a GAN-based architecture to extract eye blink feature from input audio and reference video respectively and employ contrastive training between them, then embed it into the concatenated features of identity and poses to generate talking face images. Experimental results show that the proposed method can generate photo-realistic talking face with synchronous lips motions, natural head poses and blinking eyes.