 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianzong Wang
Medical Speech Symptoms Classification via Disentangled Representation
Mar 08, 2024
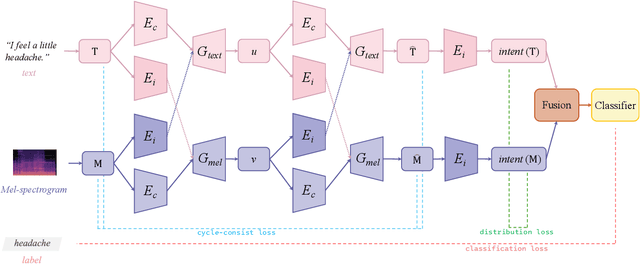
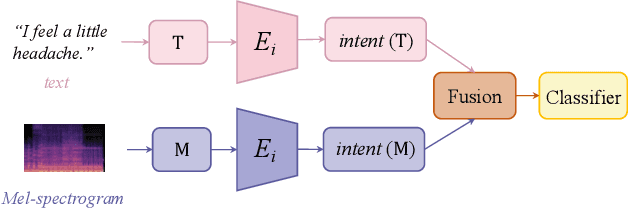
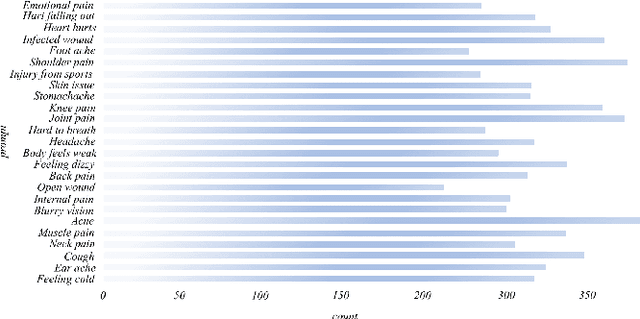
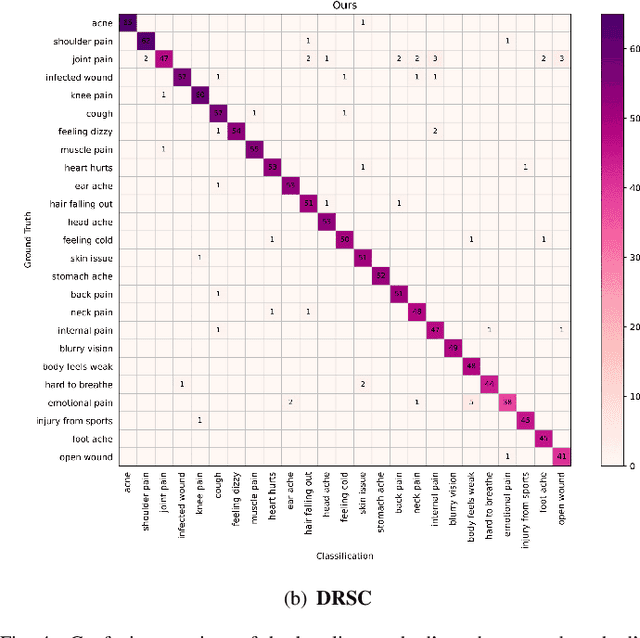
Intent is defined for understanding spoken language in existing works. Both textual features and acoustic features involved in medical speech contain intent, which is important for symptomatic diagnosis. In this paper, we propose a medical speech classification model named DRSC that automatically learns to disentangle intent and content representations from textual-acoustic data for classification. The intent representations of the text domain and the Mel-spectrogram domain are extracted via intent encoders, and then the reconstructed text feature and the Mel-spectrogram feature are obtained through two exchanges. After combining the intent from two domains into a joint representation, the integrated intent representation is fed into a decision layer for classification. Experimental results show that our model obtains an average accuracy rate of 95% in detecting 25 different medical symptoms.
Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning
Feb 01, 2024Instruction tuning is critical to improve LLMs but usually suffers from low-quality and redundant data. Data filtering for instruction tuning has proved important in improving both the efficiency and performance of the tuning process. But it also leads to extra cost and computation due to the involvement of LLMs in this process. To reduce the filtering cost, we study Superfiltering: Can we use a smaller and weaker model to select data for finetuning a larger and stronger model? Despite the performance gap between weak and strong language models, we find their highly consistent capability to perceive instruction difficulty and data selection results. This enables us to use a much smaller and more efficient model to filter the instruction data used to train a larger language model. Not only does it largely speed up the data filtering, but the filtered-data-finetuned LLM achieves even better performance on standard benchmarks. Extensive experiments validate the efficacy and efficiency of our approach.
Value-Driven Mixed-Precision Quantization for Patch-Based Inference on Microcontrollers
Jan 24, 2024Deploying neural networks on microcontroller units (MCUs) presents substantial challenges due to their constrained computation and memory resources. Previous researches have explored patch-based inference as a strategy to conserve memory without sacrificing model accuracy. However, this technique suffers from severe redundant computation overhead, leading to a substantial increase in execution latency. A feasible solution to address this issue is mixed-precision quantization, but it faces the challenges of accuracy degradation and a time-consuming search time. In this paper, we propose QuantMCU, a novel patch-based inference method that utilizes value-driven mixed-precision quantization to reduce redundant computation. We first utilize value-driven patch classification (VDPC) to maintain the model accuracy. VDPC classifies patches into two classes based on whether they contain outlier values. For patches containing outlier values, we apply 8-bit quantization to the feature maps on the dataflow branches that follow. In addition, for patches without outlier values, we utilize value-driven quantization search (VDQS) on the feature maps of their following dataflow branches to reduce search time. Specifically, VDQS introduces a novel quantization search metric that takes into account both computation and accuracy, and it employs entropy as an accuracy representation to avoid additional training. VDQS also adopts an iterative approach to determine the bitwidth of each feature map to further accelerate the search process. Experimental results on real-world MCU devices show that QuantMCU can reduce computation by 2.2x on average while maintaining comparable model accuracy compared to the state-of-the-art patch-based inference methods.
P2DT: Mitigating Forgetting in task-incremental Learning with progressive prompt Decision Transformer
Jan 22, 2024Catastrophic forgetting poses a substantial challenge for managing intelligent agents controlled by a large model, causing performance degradation when these agents face new tasks. In our work, we propose a novel solution - the Progressive Prompt Decision Transformer (P2DT). This method enhances a transformer-based model by dynamically appending decision tokens during new task training, thus fostering task-specific policies. Our approach mitigates forgetting in continual and offline reinforcement learning scenarios. Moreover, P2DT leverages trajectories collected via traditional reinforcement learning from all tasks and generates new task-specific tokens during training, thereby retaining knowledge from previous studies. Preliminary results demonstrate that our model effectively alleviates catastrophic forgetting and scales well with increasing task environments.
INCPrompt: Task-Aware incremental Prompting for Rehearsal-Free Class-incremental Learning
Jan 22, 2024This paper introduces INCPrompt, an innovative continual learning solution that effectively addresses catastrophic forgetting. INCPrompt's key innovation lies in its use of adaptive key-learner and task-aware prompts that capture task-relevant information. This unique combination encapsulates general knowledge across tasks and encodes task-specific knowledge. Our comprehensive evaluation across multiple continual learning benchmarks demonstrates INCPrompt's superiority over existing algorithms, showing its effectiveness in mitigating catastrophic forgetting while maintaining high performance. These results highlight the significant impact of task-aware incremental prompting on continual learning performance.
Learning Disentangled Speech Representations with Contrastive Learning and Time-Invariant Retrieval
Jan 18, 2024Voice conversion refers to transferring speaker identity with well-preserved content. Better disentanglement of speech representations leads to better voice conversion. Recent studies have found that phonetic information from input audio has the potential ability to well represent content. Besides, the speaker-style modeling with pre-trained models making the process more complex. To tackle these issues, we introduce a new method named "CTVC" which utilizes disentangled speech representations with contrastive learning and time-invariant retrieval. Specifically, a similarity-based compression module is used to facilitate a more intimate connection between the frame-level hidden features and linguistic information at phoneme-level. Additionally, a time-invariant retrieval is proposed for timbre extraction based on multiple segmentations and mutual information. Experimental results demonstrate that "CTVC" outperforms previous studies and improves the sound quality and similarity of converted results.
Leveraging Biases in Large Language Models: "bias-kNN'' for Effective Few-Shot Learning
Jan 18, 2024Large Language Models (LLMs) have shown significant promise in various applications, including zero-shot and few-shot learning. However, their performance can be hampered by inherent biases. Instead of traditionally sought methods that aim to minimize or correct these biases, this study introduces a novel methodology named ``bias-kNN''. This approach capitalizes on the biased outputs, harnessing them as primary features for kNN and supplementing with gold labels. Our comprehensive evaluations, spanning diverse domain text classification datasets and different GPT-2 model sizes, indicate the adaptability and efficacy of the ``bias-kNN'' method. Remarkably, this approach not only outperforms conventional in-context learning in few-shot scenarios but also demonstrates robustness across a spectrum of samples, templates and verbalizers. This study, therefore, presents a unique perspective on harnessing biases, transforming them into assets for enhanced model performance.
ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
Jan 16, 2024Existing emotional speech synthesis methods often utilize an utterance-level style embedding extracted from reference audio, neglecting the inherent multi-scale property of speech prosody. We introduce ED-TTS, a multi-scale emotional speech synthesis model that leverages Speech Emotion Diarization (SED) and Speech Emotion Recognition (SER) to model emotions at different levels. Specifically, our proposed approach integrates the utterance-level emotion embedding extracted by SER with fine-grained frame-level emotion embedding obtained from SED. These embeddings are used to condition the reverse process of the denoising diffusion probabilistic model (DDPM). Additionally, we employ cross-domain SED to accurately predict soft labels, addressing the challenge of a scarcity of fine-grained emotion-annotated datasets for supervising emotional TTS training.
EmoTalker: Emotionally Editable Talking Face Generation via Diffusion Model
Jan 16, 2024In recent years, the field of talking faces generation has attracted considerable attention, with certain methods adept at generating virtual faces that convincingly imitate human expressions. However, existing methods face challenges related to limited generalization, particularly when dealing with challenging identities. Furthermore, methods for editing expressions are often confined to a singular emotion, failing to adapt to intricate emotions. To overcome these challenges, this paper proposes EmoTalker, an emotionally editable portraits animation approach based on the diffusion model. EmoTalker modifies the denoising process to ensure preservation of the original portrait's identity during inference. To enhance emotion comprehension from text input, Emotion Intensity Block is introduced to analyze fine-grained emotions and strengths derived from prompts. Additionally, a crafted dataset is harnessed to enhance emotion comprehension within prompts. Experiments show the effectiveness of EmoTalker in generating high-quality, emotionally customizable facial expressions.
GAIA: Delving into Gradient-based Attribution Abnormality for Out-of-distribution Detection
Nov 16, 2023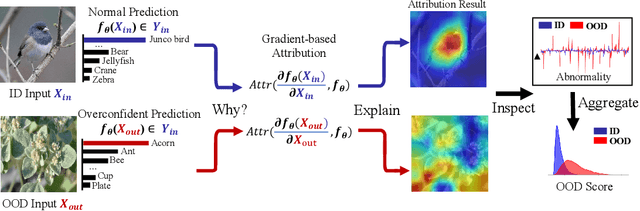
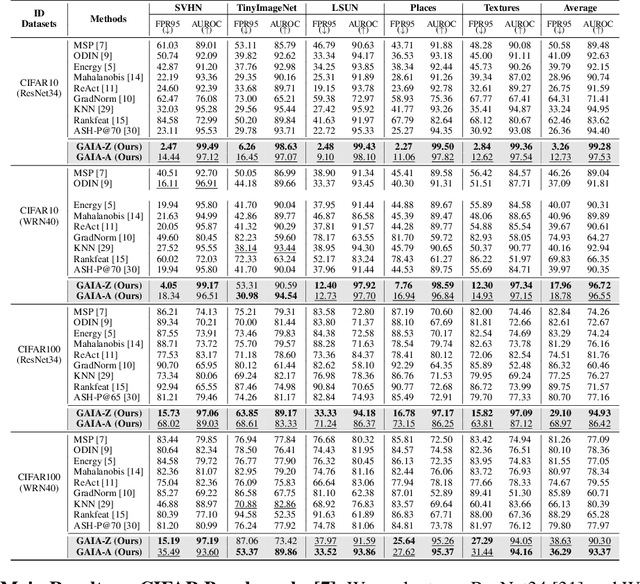
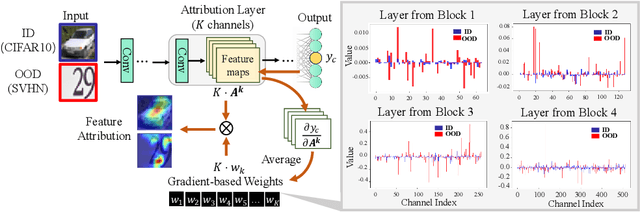
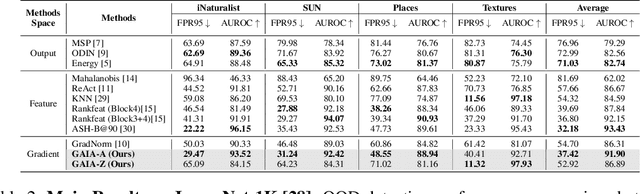
Detecting out-of-distribution (OOD) examples is crucial to guarantee the reliability and safety of deep neural networks in real-world settings. In this paper, we offer an innovative perspective on quantifying the disparities between in-distribution (ID) and OOD data -- analyzing the uncertainty that arises when models attempt to explain their predictive decisions. This perspective is motivated by our observation that gradient-based attribution methods encounter challenges in assigning feature importance to OOD data, thereby yielding divergent explanation patterns. Consequently, we investigate how attribution gradients lead to uncertain explanation outcomes and introduce two forms of abnormalities for OOD detection: the zero-deflation abnormality and the channel-wise average abnormality. We then propose GAIA, a simple and effective approach that incorporates Gradient Abnormality Inspection and Aggregation. The effectiveness of GAIA is validated on both commonly utilized (CIFAR) and large-scale (ImageNet-1k) benchmarks. Specifically, GAIA reduces the average FPR95 by 23.10% on CIFAR10 and by 45.41% on CIFAR100 compared to advanced post-hoc methods.