 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShwai He
RESSA: Repair Sparse Vision-Language Models via Sparse Cross-Modality Adaptation
Apr 03, 2024
Vision-Language Models (VLMs), integrating diverse information from multiple modalities, have shown remarkable success across various tasks. However, deploying VLMs, comprising large-scale vision and language models poses challenges in resource-constrained scenarios. While pruning followed by finetuning offers a potential solution to maintain performance with smaller model sizes, its application to VLMs remains relatively unexplored, presenting two main questions: how to distribute sparsity across different modality-specific models, and how to repair the performance of pruned sparse VLMs. To answer the first question, we conducted preliminary studies on VLM pruning and found that pruning vision models and language models with the same sparsity ratios contribute to nearly optimal performance. For the second question, unlike finetuning unimodal sparse models, sparse VLMs involve cross-modality interactions, requiring specialized techniques for post-pruning performance repair. Moreover, while parameter-efficient LoRA finetuning has been proposed to repair the performance of sparse models, a significant challenge of weights merging arises due to the incompatibility of dense LoRA modules with sparse models that destroy the sparsity of pruned models. To tackle these challenges, we propose to Repair Sparse Vision-Language Models via Sparse Cross-modality Adaptation (RESSA). RESSA utilizes cross-modality finetuning to enhance task-specific performance and facilitate knowledge distillation from original dense models. Additionally, we introduce SparseLoRA, which applies sparsity directly to LoRA weights, enabling seamless integration with sparse models. Our experimental results validate the effectiveness of RESSA, showcasing significant enhancements, such as an 11.3\% improvement under 2:4 sparsity and a remarkable 47.6\% enhancement under unstructured 70\% sparsity.
Reformatted Alignment
Feb 19, 2024The quality of finetuning data is crucial for aligning large language models (LLMs) with human values. Current methods to improve data quality are either labor-intensive or prone to factual errors caused by LLM hallucinations. This paper explores elevating the quality of existing instruction data to better align with human values, introducing a simple and effective approach named ReAlign, which reformats the responses of instruction data into a format that better aligns with pre-established criteria and the collated evidence. This approach minimizes human annotation, hallucination, and the difficulty in scaling, remaining orthogonal to existing alignment techniques. Experimentally, ReAlign significantly boosts the general alignment ability, math reasoning, factuality, and readability of the LLMs. Encouragingly, without introducing any additional data or advanced training techniques, and merely by reformatting the response, LLaMA-2-13B's mathematical reasoning ability on GSM8K can be improved from 46.77% to 56.63% in accuracy. Additionally, a mere 5% of ReAlign data yields a 67% boost in general alignment ability measured by the Alpaca dataset. This work highlights the need for further research into the science and mechanistic interpretability of LLMs. We have made the associated code and data publicly accessible to support future studies at https://github.com/GAIR-NLP/ReAlign.
Selective Reflection-Tuning: Student-Selected Data Recycling for LLM Instruction-Tuning
Feb 15, 2024Instruction tuning is critical to large language models (LLMs) for achieving better instruction following and task adaptation capabilities but its success heavily relies on the training data quality. Many recent methods focus on improving the data quality but often overlook the compatibility of the data with the student model being finetuned. This paper introduces Selective Reflection-Tuning, a novel paradigm that synergizes a teacher LLM's reflection and introspection for improving existing data quality with the data selection capability of the student LLM, to automatically refine existing instruction-tuning data. This teacher-student collaboration produces high-quality and student-compatible instruction-response pairs, resulting in sample-efficient instruction tuning and LLMs of superior performance. Selective Reflection-Tuning is a data augmentation and synthesis that generally improves LLM finetuning and self-improvement without collecting brand-new data. We apply our method to Alpaca and WizardLM data and achieve much stronger and top-tier 7B and 13B LLMs. Our codes, models, and data will be released at https://github.com/tianyi-lab/Reflection_Tuning.
Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning
Feb 01, 2024Instruction tuning is critical to improve LLMs but usually suffers from low-quality and redundant data. Data filtering for instruction tuning has proved important in improving both the efficiency and performance of the tuning process. But it also leads to extra cost and computation due to the involvement of LLMs in this process. To reduce the filtering cost, we study Superfiltering: Can we use a smaller and weaker model to select data for finetuning a larger and stronger model? Despite the performance gap between weak and strong language models, we find their highly consistent capability to perceive instruction difficulty and data selection results. This enables us to use a much smaller and more efficient model to filter the instruction data used to train a larger language model. Not only does it largely speed up the data filtering, but the filtered-data-finetuned LLM achieves even better performance on standard benchmarks. Extensive experiments validate the efficacy and efficiency of our approach.
Merging Experts into One: Improving Computational Efficiency of Mixture of Experts
Oct 22, 2023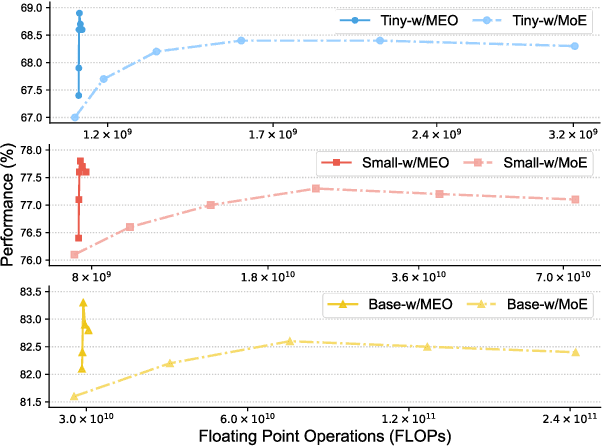

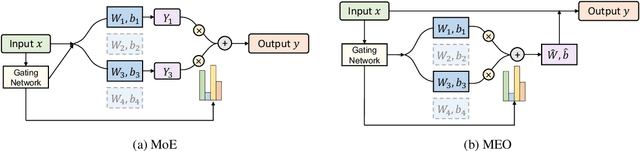

Scaling the size of language models usually leads to remarkable advancements in NLP tasks. But it often comes with a price of growing computational cost. Although a sparse Mixture of Experts (MoE) can reduce the cost by activating a small subset of parameters (e.g., one expert) for each input, its computation escalates significantly if increasing the number of activated experts, limiting its practical utility. Can we retain the advantages of adding more experts without substantially increasing the computational costs? In this paper, we first demonstrate the superiority of selecting multiple experts and then propose a computation-efficient approach called \textbf{\texttt{Merging Experts into One}} (MEO), which reduces the computation cost to that of a single expert. Extensive experiments show that MEO significantly improves computational efficiency, e.g., FLOPS drops from 72.0G of vanilla MoE to 28.6G (MEO). Moreover, we propose a token-level attention block that further enhances the efficiency and performance of token-level MEO, e.g., 83.3\% (MEO) vs. 82.6\% (vanilla MoE) average score on the GLUE benchmark. Our code will be released upon acceptance. Code will be released at: \url{https://github.com/Shwai-He/MEO}.
Reflection-Tuning: Data Recycling Improves LLM Instruction-Tuning
Oct 18, 2023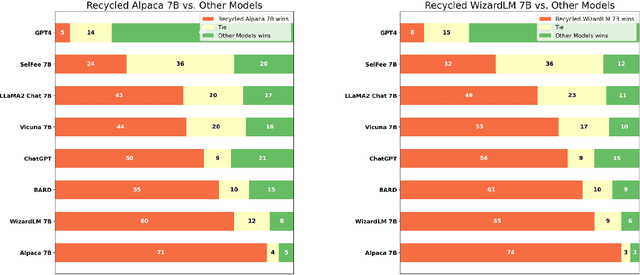
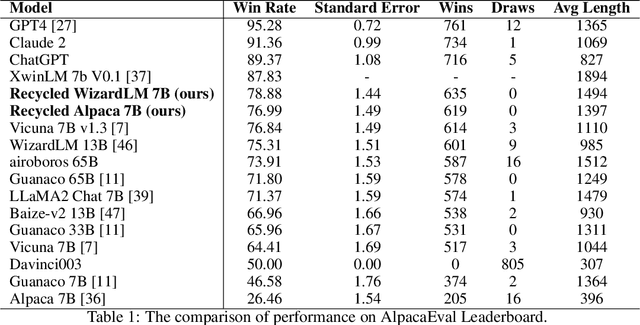
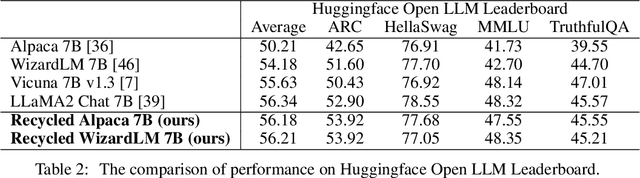

Recent advancements in Large Language Models (LLMs) have expanded the horizons of natural language understanding and generation. Notably, the output control and alignment with the input of LLMs can be refined through instruction tuning. However, as highlighted in several studies, low-quality data in the training set are usually detrimental to instruction tuning, resulting in inconsistent or even misleading LLM outputs. We propose a novel method, termed "reflection-tuning," which addresses the problem by self-improvement and judging capabilities of LLMs. This approach utilizes an oracle LLM to recycle the original training data by introspecting and enhancing the quality of instructions and responses in the data. Extensive experiments on widely used evaluation benchmarks show that LLMs trained with our recycled data outperform those trained with existing datasets in various benchmarks.
MerA: Merging Pretrained Adapters For Few-Shot Learning
Aug 30, 2023
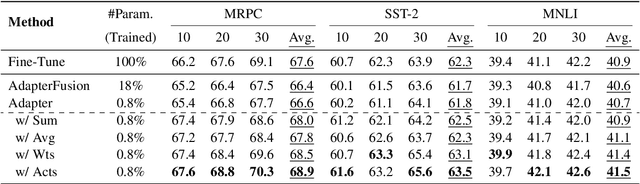


Adapter tuning, which updates only a few parameters, has become a mainstream method for fine-tuning pretrained language models to downstream tasks. However, it often yields subpar results in few-shot learning. AdapterFusion, which assembles pretrained adapters using composition layers tailored to specific tasks, is a possible solution but significantly increases trainable parameters and deployment costs. Despite this, our preliminary study reveals that even single adapters can outperform Adapterfusion in few-shot learning, urging us to propose \textbf{\texttt{Merging Pretrained Adapters}} (MerA) that efficiently incorporates pretrained adapters to a single model through model fusion. Extensive experiments on two PLMs demonstrate that MerA achieves substantial improvements compared to both single adapters and AdapterFusion. To further enhance the capacity of MerA, we also introduce a simple yet effective technique, referred to as the "\textit{same-track}" setting, that merges adapters from the same track of pretraining tasks. With the implementation of the "\textit{same-track}" setting, we observe even more impressive gains, surpassing the performance of both full fine-tuning and adapter tuning by a substantial margin, e.g., 3.5\% in MRPC and 5.0\% in MNLI.
Cherry Hypothesis: Identifying the Cherry on the Cake for Dynamic Networks
Nov 10, 2022

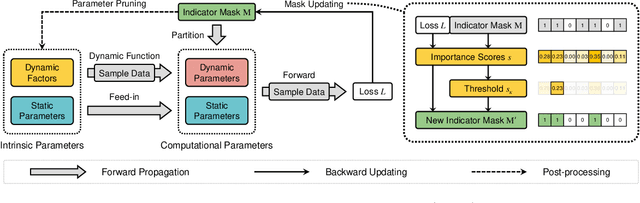
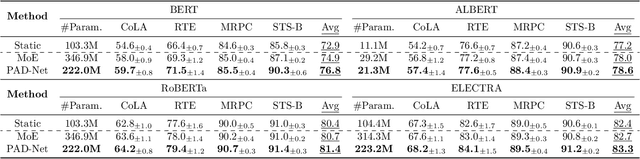
Dynamic networks have been extensively explored as they can considerably improve the model's representation power with acceptable computational cost. The common practice in implementing dynamic networks is to convert given static layers into fully dynamic ones where all parameters are dynamic and vary with the input. Recent studies empirically show the trend that the more dynamic layers contribute to ever-increasing performance. However, such a fully dynamic setting 1) may cause redundant parameters and high deployment costs, limiting the applicability of dynamic networks to a broader range of tasks and models, and more importantly, 2) contradicts the previous discovery in the human brain that \textit{when human brains process an attention-demanding task, only partial neurons in the task-specific areas are activated by the input, while the rest neurons leave in a baseline state.} Critically, there is no effort to understand and resolve the above contradictory finding, leaving the primal question -- to make the computational parameters fully dynamic or not? -- unanswered. The main contributions of our work are challenging the basic commonsense in dynamic networks, and, proposing and validating the \textsc{cherry hypothesis} -- \textit{A fully dynamic network contains a subset of dynamic parameters that when transforming other dynamic parameters into static ones, can maintain or even exceed the performance of the original network.} Technically, we propose a brain-inspired partially dynamic network, namely PAD-Net, to transform the redundant dynamic parameters into static ones. Also, we further design Iterative Mode Partition to partition the dynamic- and static-subnet, which alleviates the redundancy in traditional fully dynamic networks. Our hypothesis and method are comprehensively supported by large-scale experiments with typical advanced dynamic methods.
SparseAdapter: An Easy Approach for Improving the Parameter-Efficiency of Adapters
Oct 11, 2022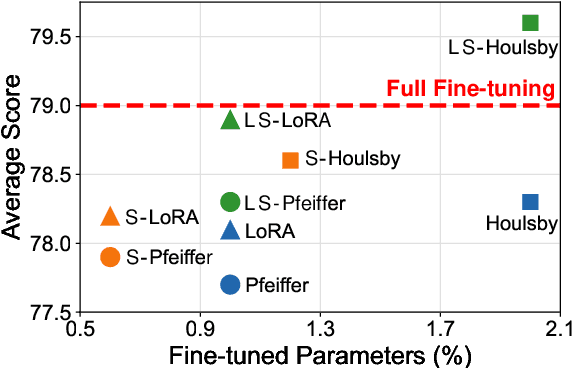
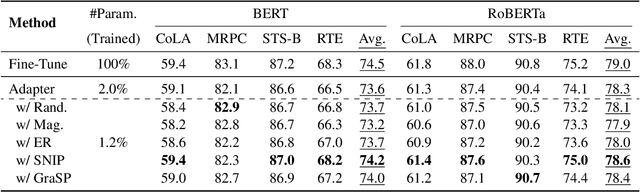
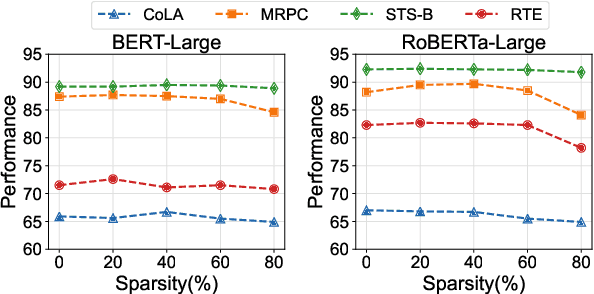
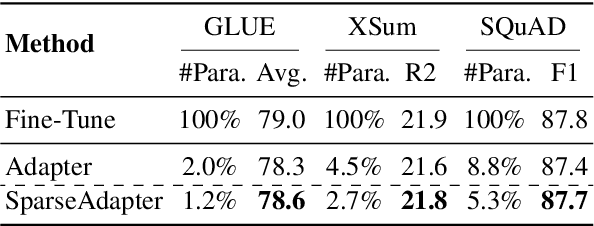
Adapter Tuning, which freezes the pretrained language models (PLMs) and only fine-tunes a few extra modules, becomes an appealing efficient alternative to the full model fine-tuning. Although computationally efficient, the recent Adapters often increase parameters (e.g. bottleneck dimension) for matching the performance of full model fine-tuning, which we argue goes against their original intention. In this work, we re-examine the parameter-efficiency of Adapters through the lens of network pruning (we name such plug-in concept as \texttt{SparseAdapter}) and find that SparseAdapter can achieve comparable or better performance than standard Adapters when the sparse ratio reaches up to 80\%. Based on our findings, we introduce an easy but effective setting ``\textit{Large-Sparse}'' to improve the model capacity of Adapters under the same parameter budget. Experiments on five competitive Adapters upon three advanced PLMs show that with proper sparse method (e.g. SNIP) and ratio (e.g. 40\%) SparseAdapter can consistently outperform their corresponding counterpart. Encouragingly, with the \textit{Large-Sparse} setting, we can obtain further appealing gains, even outperforming the full fine-tuning by a large margin. Our code will be released at: \url{https://github.com/Shwai-He/SparseAdapter}.
Vega-MT: The JD Explore Academy Translation System for WMT22
Sep 21, 2022
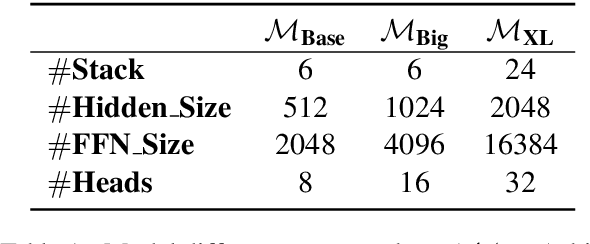
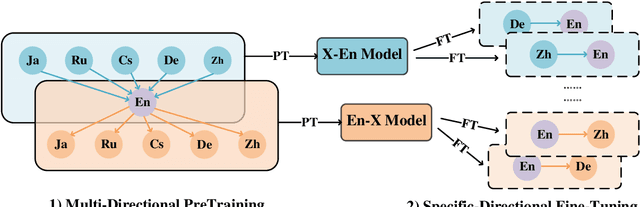

We describe the JD Explore Academy's submission of the WMT 2022 shared general translation task. We participated in all high-resource tracks and one medium-resource track, including Chinese-English, German-English, Czech-English, Russian-English, and Japanese-English. We push the limit of our previous work -- bidirectional training for translation by scaling up two main factors, i.e. language pairs and model sizes, namely the \textbf{Vega-MT} system. As for language pairs, we scale the "bidirectional" up to the "multidirectional" settings, covering all participating languages, to exploit the common knowledge across languages, and transfer them to the downstream bilingual tasks. As for model sizes, we scale the Transformer-Big up to the extremely large model that owns nearly 4.7 Billion parameters, to fully enhance the model capacity for our Vega-MT. Also, we adopt the data augmentation strategies, e.g. cycle translation for monolingual data, and bidirectional self-training for bilingual and monolingual data, to comprehensively exploit the bilingual and monolingual data. To adapt our Vega-MT to the general domain test set, generalization tuning is designed. Based on the official automatic scores of constrained systems, in terms of the sacreBLEU shown in Figure-1, we got the 1st place on {Zh-En (33.5), En-Zh (49.7), De-En (33.7), En-De (37.8), Cs-En (54.9), En-Cs (41.4) and En-Ru (32.7)}, 2nd place on {Ru-En (45.1) and Ja-En (25.6)}, and 3rd place on {En-Ja(41.5)}, respectively; W.R.T the COMET, we got the 1st place on {Zh-En (45.1), En-Zh (61.7), De-En (58.0), En-De (63.2), Cs-En (74.7), Ru-En (64.9), En-Ru (69.6) and En-Ja (65.1)}, 2nd place on {En-Cs (95.3) and Ja-En (40.6)}, respectively. Models will be released to facilitate the MT community through GitHub and OmniForce Platform.