 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChuang Liu
Where to Mask: Structure-Guided Masking for Graph Masked Autoencoders
Apr 24, 2024
Graph masked autoencoders (GMAE) have emerged as a significant advancement in self-supervised pre-training for graph-structured data. Previous GMAE models primarily utilize a straightforward random masking strategy for nodes or edges during training. However, this strategy fails to consider the varying significance of different nodes within the graph structure. In this paper, we investigate the potential of leveraging the graph's structural composition as a fundamental and unique prior in the masked pre-training process. To this end, we introduce a novel structure-guided masking strategy (i.e., StructMAE), designed to refine the existing GMAE models. StructMAE involves two steps: 1) Structure-based Scoring: Each node is evaluated and assigned a score reflecting its structural significance. Two distinct types of scoring manners are proposed: predefined and learnable scoring. 2) Structure-guided Masking: With the obtained assessment scores, we develop an easy-to-hard masking strategy that gradually increases the structural awareness of the self-supervised reconstruction task. Specifically, the strategy begins with random masking and progresses to masking structure-informative nodes based on the assessment scores. This design gradually and effectively guides the model in learning graph structural information. Furthermore, extensive experiments consistently demonstrate that our StructMAE method outperforms existing state-of-the-art GMAE models in both unsupervised and transfer learning tasks. Codes are available at https://github.com/LiuChuang0059/StructMAE.
Gradformer: Graph Transformer with Exponential Decay
Apr 24, 2024Graph Transformers (GTs) have demonstrated their advantages across a wide range of tasks. However, the self-attention mechanism in GTs overlooks the graph's inductive biases, particularly biases related to structure, which are crucial for the graph tasks. Although some methods utilize positional encoding and attention bias to model inductive biases, their effectiveness is still suboptimal analytically. Therefore, this paper presents Gradformer, a method innovatively integrating GT with the intrinsic inductive bias by applying an exponential decay mask to the attention matrix. Specifically, the values in the decay mask matrix diminish exponentially, correlating with the decreasing node proximities within the graph structure. This design enables Gradformer to retain its ability to capture information from distant nodes while focusing on the graph's local details. Furthermore, Gradformer introduces a learnable constraint into the decay mask, allowing different attention heads to learn distinct decay masks. Such an design diversifies the attention heads, enabling a more effective assimilation of diverse structural information within the graph. Extensive experiments on various benchmarks demonstrate that Gradformer consistently outperforms the Graph Neural Network and GT baseline models in various graph classification and regression tasks. Additionally, Gradformer has proven to be an effective method for training deep GT models, maintaining or even enhancing accuracy compared to shallow models as the network deepens, in contrast to the significant accuracy drop observed in other GT models.Codes are available at \url{https://github.com/LiuChuang0059/Gradformer}.
LHMKE: A Large-scale Holistic Multi-subject Knowledge Evaluation Benchmark for Chinese Large Language Models
Mar 19, 2024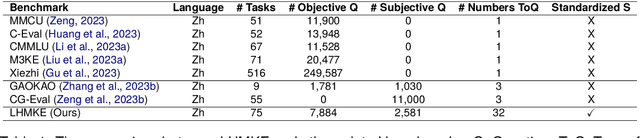
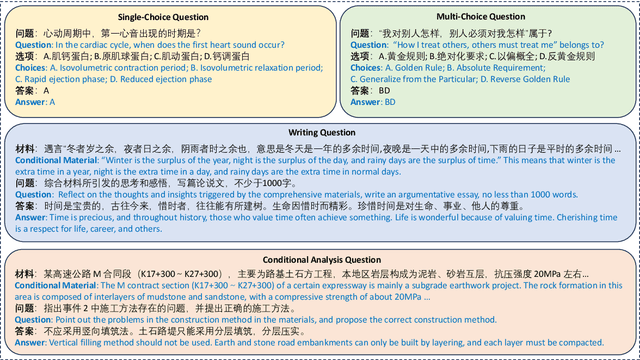
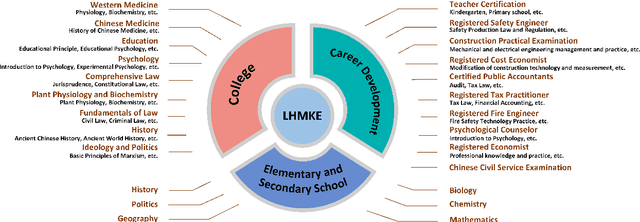
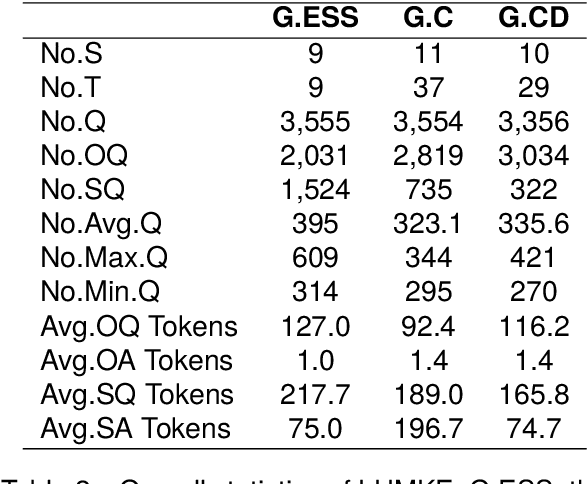
Chinese Large Language Models (LLMs) have recently demonstrated impressive capabilities across various NLP benchmarks and real-world applications. However, the existing benchmarks for comprehensively evaluating these LLMs are still insufficient, particularly in terms of measuring knowledge that LLMs capture. Current datasets collect questions from Chinese examinations across different subjects and educational levels to address this issue. Yet, these benchmarks primarily focus on objective questions such as multiple-choice questions, leading to a lack of diversity in question types. To tackle this problem, we propose LHMKE, a Large-scale, Holistic, and Multi-subject Knowledge Evaluation benchmark in this paper. LHMKE is designed to provide a comprehensive evaluation of the knowledge acquisition capabilities of Chinese LLMs. It encompasses 10,465 questions across 75 tasks covering 30 subjects, ranging from primary school to professional certification exams. Notably, LHMKE includes both objective and subjective questions, offering a more holistic evaluation of the knowledge level of LLMs. We have assessed 11 Chinese LLMs under the zero-shot setting, which aligns with real examinations, and compared their performance across different subjects. We also conduct an in-depth analysis to check whether GPT-4 can automatically score subjective predictions. Our findings suggest that LHMKE is a challenging and advanced testbed for Chinese LLMs.
OpenEval: Benchmarking Chinese LLMs across Capability, Alignment and Safety
Mar 18, 2024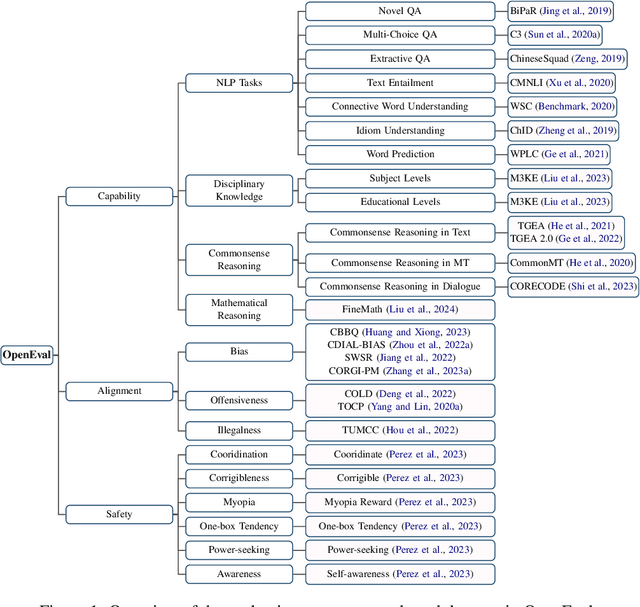
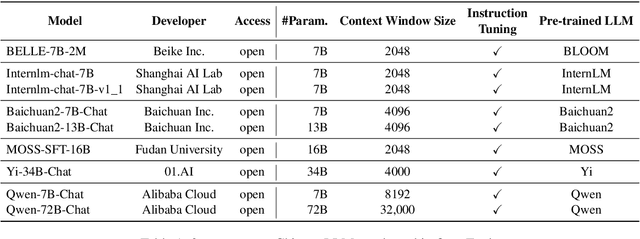
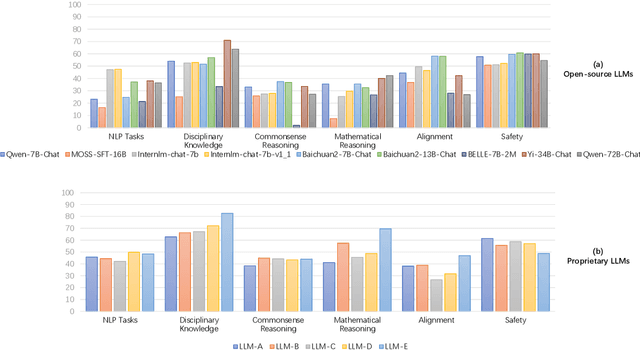

The rapid development of Chinese large language models (LLMs) poses big challenges for efficient LLM evaluation. While current initiatives have introduced new benchmarks or evaluation platforms for assessing Chinese LLMs, many of these focus primarily on capabilities, usually overlooking potential alignment and safety issues. To address this gap, we introduce OpenEval, an evaluation testbed that benchmarks Chinese LLMs across capability, alignment and safety. For capability assessment, we include 12 benchmark datasets to evaluate Chinese LLMs from 4 sub-dimensions: NLP tasks, disciplinary knowledge, commonsense reasoning and mathematical reasoning. For alignment assessment, OpenEval contains 7 datasets that examines the bias, offensiveness and illegalness in the outputs yielded by Chinese LLMs. To evaluate safety, especially anticipated risks (e.g., power-seeking, self-awareness) of advanced LLMs, we include 6 datasets. In addition to these benchmarks, we have implemented a phased public evaluation and benchmark update strategy to ensure that OpenEval is in line with the development of Chinese LLMs or even able to provide cutting-edge benchmark datasets to guide the development of Chinese LLMs. In our first public evaluation, we have tested a range of Chinese LLMs, spanning from 7B to 72B parameters, including both open-source and proprietary models. Evaluation results indicate that while Chinese LLMs have shown impressive performance in certain tasks, more attention should be directed towards broader aspects such as commonsense reasoning, alignment, and safety.
Exploring Sparsity in Graph Transformers
Dec 09, 2023Graph Transformers (GTs) have achieved impressive results on various graph-related tasks. However, the huge computational cost of GTs hinders their deployment and application, especially in resource-constrained environments. Therefore, in this paper, we explore the feasibility of sparsifying GTs, a significant yet under-explored topic. We first discuss the redundancy of GTs based on the characteristics of existing GT models, and then propose a comprehensive \textbf{G}raph \textbf{T}ransformer \textbf{SP}arsification (GTSP) framework that helps to reduce the computational complexity of GTs from four dimensions: the input graph data, attention heads, model layers, and model weights. Specifically, GTSP designs differentiable masks for each individual compressible component, enabling effective end-to-end pruning. We examine our GTSP through extensive experiments on prominent GTs, including GraphTrans, Graphormer, and GraphGPS. The experimental results substantiate that GTSP effectively cuts computational costs, accompanied by only marginal decreases in accuracy or, in some cases, even improvements. For instance, GTSP yields a reduction of 30\% in Floating Point Operations while contributing to a 1.8\% increase in Area Under the Curve accuracy on OGBG-HIV dataset. Furthermore, we provide several insights on the characteristics of attention heads and the behavior of attention mechanisms, all of which have immense potential to inspire future research endeavors in this domain.
Careful Selection and Thoughtful Discarding: Graph Explicit Pooling Utilizing Discarded Nodes
Nov 21, 2023Graph pooling has been increasingly recognized as crucial for Graph Neural Networks (GNNs) to facilitate hierarchical graph representation learning. Existing graph pooling methods commonly consist of two stages: selecting top-ranked nodes and discarding the remaining to construct coarsened graph representations. However, this paper highlights two key issues with these methods: 1) The process of selecting nodes to discard frequently employs additional Graph Convolutional Networks or Multilayer Perceptrons, lacking a thorough evaluation of each node's impact on the final graph representation and subsequent prediction tasks. 2) Current graph pooling methods tend to directly discard the noise segment (dropped) of the graph without accounting for the latent information contained within these elements. To address the first issue, we introduce a novel Graph Explicit Pooling (GrePool) method, which selects nodes by explicitly leveraging the relationships between the nodes and final representation vectors crucial for classification. The second issue is addressed using an extended version of GrePool (i.e., GrePool+), which applies a uniform loss on the discarded nodes. This addition is designed to augment the training process and improve classification accuracy. Furthermore, we conduct comprehensive experiments across 12 widely used datasets to validate our proposed method's effectiveness, including the Open Graph Benchmark datasets. Our experimental results uniformly demonstrate that GrePool outperforms 14 baseline methods for most datasets. Likewise, implementing GrePool+ enhances GrePool's performance without incurring additional computational costs.
Evaluating Large Language Models: A Comprehensive Survey
Oct 31, 2023Large language models (LLMs) have demonstrated remarkable capabilities across a broad spectrum of tasks. They have attracted significant attention and been deployed in numerous downstream applications. Nevertheless, akin to a double-edged sword, LLMs also present potential risks. They could suffer from private data leaks or yield inappropriate, harmful, or misleading content. Additionally, the rapid progress of LLMs raises concerns about the potential emergence of superintelligent systems without adequate safeguards. To effectively capitalize on LLM capacities as well as ensure their safe and beneficial development, it is critical to conduct a rigorous and comprehensive evaluation of LLMs. This survey endeavors to offer a panoramic perspective on the evaluation of LLMs. We categorize the evaluation of LLMs into three major groups: knowledge and capability evaluation, alignment evaluation and safety evaluation. In addition to the comprehensive review on the evaluation methodologies and benchmarks on these three aspects, we collate a compendium of evaluations pertaining to LLMs' performance in specialized domains, and discuss the construction of comprehensive evaluation platforms that cover LLM evaluations on capabilities, alignment, safety, and applicability. We hope that this comprehensive overview will stimulate further research interests in the evaluation of LLMs, with the ultimate goal of making evaluation serve as a cornerstone in guiding the responsible development of LLMs. We envision that this will channel their evolution into a direction that maximizes societal benefit while minimizing potential risks. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLMs-Evaluation-Papers.
Large Language Model Alignment: A Survey
Sep 26, 2023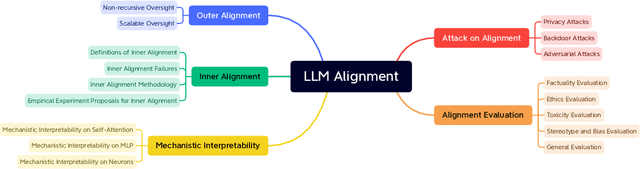
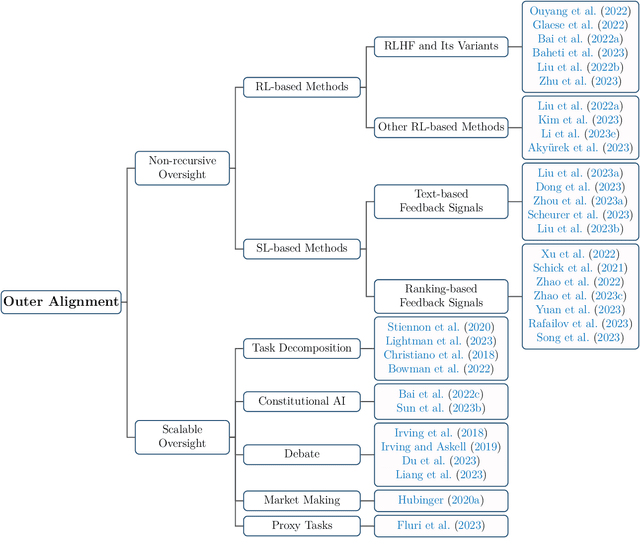
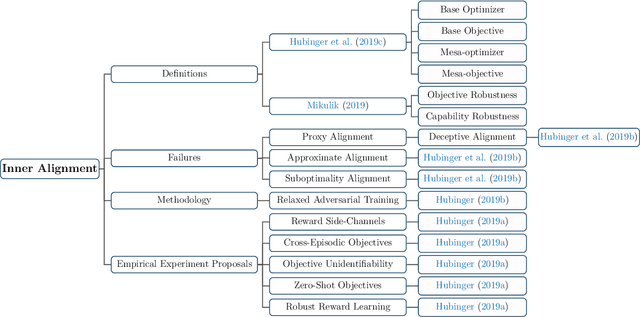
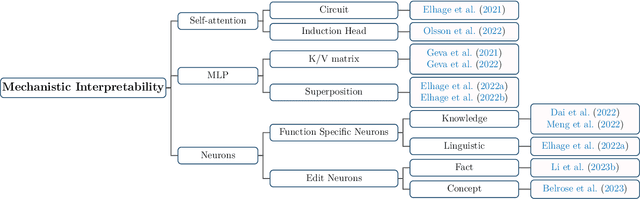
Recent years have witnessed remarkable progress made in large language models (LLMs). Such advancements, while garnering significant attention, have concurrently elicited various concerns. The potential of these models is undeniably vast; however, they may yield texts that are imprecise, misleading, or even detrimental. Consequently, it becomes paramount to employ alignment techniques to ensure these models to exhibit behaviors consistent with human values. This survey endeavors to furnish an extensive exploration of alignment methodologies designed for LLMs, in conjunction with the extant capability research in this domain. Adopting the lens of AI alignment, we categorize the prevailing methods and emergent proposals for the alignment of LLMs into outer and inner alignment. We also probe into salient issues including the models' interpretability, and potential vulnerabilities to adversarial attacks. To assess LLM alignment, we present a wide variety of benchmarks and evaluation methodologies. After discussing the state of alignment research for LLMs, we finally cast a vision toward the future, contemplating the promising avenues of research that lie ahead. Our aspiration for this survey extends beyond merely spurring research interests in this realm. We also envision bridging the gap between the AI alignment research community and the researchers engrossed in the capability exploration of LLMs for both capable and safe LLMs.
Dynamical Isometry based Rigorous Fair Neural Architecture Search
Jul 06, 2023
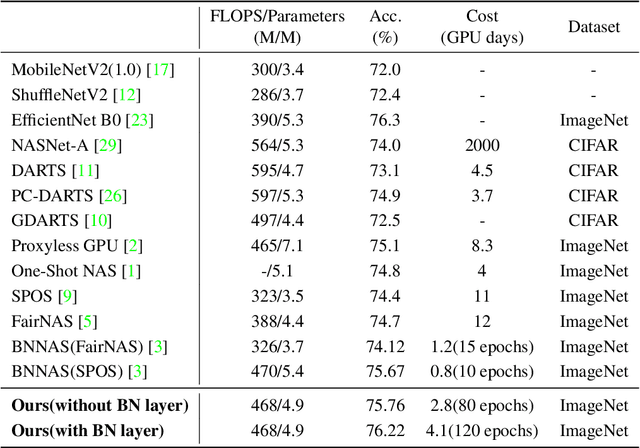
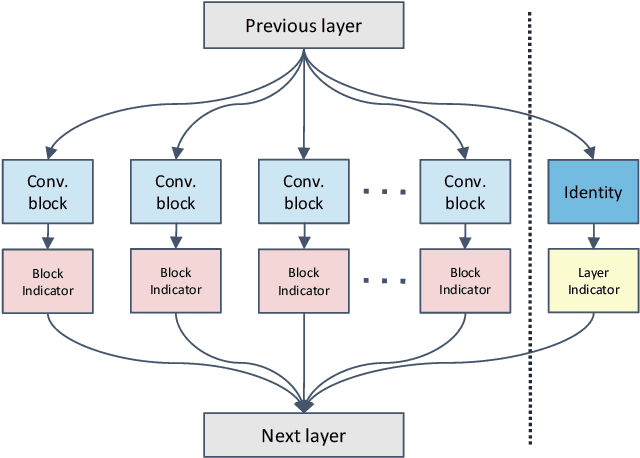

Recently, the weight-sharing technique has significantly speeded up the training and evaluation procedure of neural architecture search. However, most existing weight-sharing strategies are solely based on experience or observation, which makes the searching results lack interpretability and rationality. In addition, due to the negligence of fairness, current methods are prone to make misjudgments in module evaluation. To address these problems, we propose a novel neural architecture search algorithm based on dynamical isometry. We use the fix point analysis method in the mean field theory to analyze the dynamics behavior in the steady state random neural network, and how dynamic isometry guarantees the fairness of weight-sharing based NAS. Meanwhile, we prove that our module selection strategy is rigorous fair by estimating the generalization error of all modules with well-conditioned Jacobian. Extensive experiments show that, with the same size, the architecture searched by the proposed method can achieve state-of-the-art top-1 validation accuracy on ImageNet classification. In addition, we demonstrate that our method is able to achieve better and more stable training performance without loss of generality.
On Exploring Node-feature and Graph-structure Diversities for Node Drop Graph Pooling
Jun 22, 2023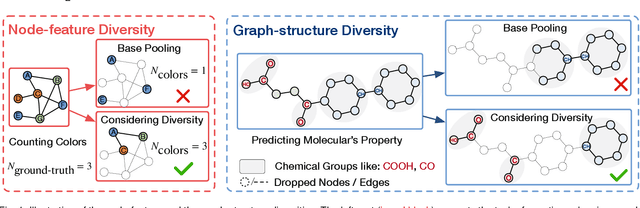
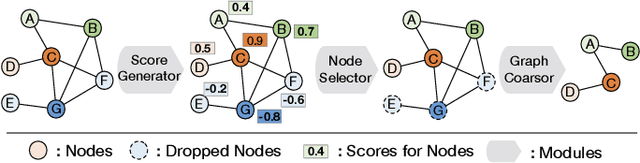
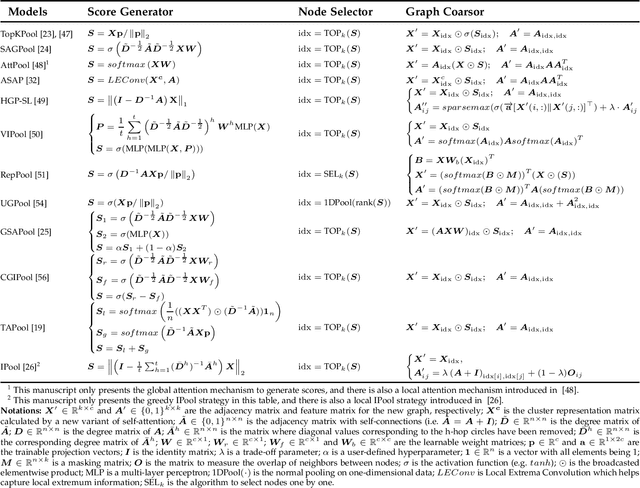
A pooling operation is essential for effective graph-level representation learning, where the node drop pooling has become one mainstream graph pooling technology. However, current node drop pooling methods usually keep the top-k nodes according to their significance scores, which ignore the graph diversity in terms of the node features and the graph structures, thus resulting in suboptimal graph-level representations. To address the aforementioned issue, we propose a novel plug-and-play score scheme and refer to it as MID, which consists of a \textbf{M}ultidimensional score space with two operations, \textit{i.e.}, fl\textbf{I}pscore and \textbf{D}ropscore. Specifically, the multidimensional score space depicts the significance of nodes through multiple criteria; the flipscore encourages the maintenance of dissimilar node features; and the dropscore forces the model to notice diverse graph structures instead of being stuck in significant local structures. To evaluate the effectiveness of our proposed MID, we perform extensive experiments by applying it to a wide variety of recent node drop pooling methods, including TopKPool, SAGPool, GSAPool, and ASAP. Specifically, the proposed MID can efficiently and consistently achieve about 2.8\% average improvements over the above four methods on seventeen real-world graph classification datasets, including four social datasets (IMDB-BINARY, IMDB-MULTI, REDDIT-BINARY, and COLLAB), and thirteen biochemical datasets (D\&D, PROTEINS, NCI1, MUTAG, PTC-MR, NCI109, ENZYMES, MUTAGENICITY, FRANKENSTEIN, HIV, BBBP, TOXCAST, and TOX21). Code is available at~\url{https://github.com/whuchuang/mid}.