 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXueqi Ma
Gradformer: Graph Transformer with Exponential Decay
Apr 24, 2024
Graph Transformers (GTs) have demonstrated their advantages across a wide range of tasks. However, the self-attention mechanism in GTs overlooks the graph's inductive biases, particularly biases related to structure, which are crucial for the graph tasks. Although some methods utilize positional encoding and attention bias to model inductive biases, their effectiveness is still suboptimal analytically. Therefore, this paper presents Gradformer, a method innovatively integrating GT with the intrinsic inductive bias by applying an exponential decay mask to the attention matrix. Specifically, the values in the decay mask matrix diminish exponentially, correlating with the decreasing node proximities within the graph structure. This design enables Gradformer to retain its ability to capture information from distant nodes while focusing on the graph's local details. Furthermore, Gradformer introduces a learnable constraint into the decay mask, allowing different attention heads to learn distinct decay masks. Such an design diversifies the attention heads, enabling a more effective assimilation of diverse structural information within the graph. Extensive experiments on various benchmarks demonstrate that Gradformer consistently outperforms the Graph Neural Network and GT baseline models in various graph classification and regression tasks. Additionally, Gradformer has proven to be an effective method for training deep GT models, maintaining or even enhancing accuracy compared to shallow models as the network deepens, in contrast to the significant accuracy drop observed in other GT models.Codes are available at \url{https://github.com/LiuChuang0059/Gradformer}.
Where to Mask: Structure-Guided Masking for Graph Masked Autoencoders
Apr 24, 2024



Graph masked autoencoders (GMAE) have emerged as a significant advancement in self-supervised pre-training for graph-structured data. Previous GMAE models primarily utilize a straightforward random masking strategy for nodes or edges during training. However, this strategy fails to consider the varying significance of different nodes within the graph structure. In this paper, we investigate the potential of leveraging the graph's structural composition as a fundamental and unique prior in the masked pre-training process. To this end, we introduce a novel structure-guided masking strategy (i.e., StructMAE), designed to refine the existing GMAE models. StructMAE involves two steps: 1) Structure-based Scoring: Each node is evaluated and assigned a score reflecting its structural significance. Two distinct types of scoring manners are proposed: predefined and learnable scoring. 2) Structure-guided Masking: With the obtained assessment scores, we develop an easy-to-hard masking strategy that gradually increases the structural awareness of the self-supervised reconstruction task. Specifically, the strategy begins with random masking and progresses to masking structure-informative nodes based on the assessment scores. This design gradually and effectively guides the model in learning graph structural information. Furthermore, extensive experiments consistently demonstrate that our StructMAE method outperforms existing state-of-the-art GMAE models in both unsupervised and transfer learning tasks. Codes are available at https://github.com/LiuChuang0059/StructMAE.
Exploring Sparsity in Graph Transformers
Dec 09, 2023
Graph Transformers (GTs) have achieved impressive results on various graph-related tasks. However, the huge computational cost of GTs hinders their deployment and application, especially in resource-constrained environments. Therefore, in this paper, we explore the feasibility of sparsifying GTs, a significant yet under-explored topic. We first discuss the redundancy of GTs based on the characteristics of existing GT models, and then propose a comprehensive \textbf{G}raph \textbf{T}ransformer \textbf{SP}arsification (GTSP) framework that helps to reduce the computational complexity of GTs from four dimensions: the input graph data, attention heads, model layers, and model weights. Specifically, GTSP designs differentiable masks for each individual compressible component, enabling effective end-to-end pruning. We examine our GTSP through extensive experiments on prominent GTs, including GraphTrans, Graphormer, and GraphGPS. The experimental results substantiate that GTSP effectively cuts computational costs, accompanied by only marginal decreases in accuracy or, in some cases, even improvements. For instance, GTSP yields a reduction of 30\% in Floating Point Operations while contributing to a 1.8\% increase in Area Under the Curve accuracy on OGBG-HIV dataset. Furthermore, we provide several insights on the characteristics of attention heads and the behavior of attention mechanisms, all of which have immense potential to inspire future research endeavors in this domain.
Careful Selection and Thoughtful Discarding: Graph Explicit Pooling Utilizing Discarded Nodes
Nov 21, 2023



Graph pooling has been increasingly recognized as crucial for Graph Neural Networks (GNNs) to facilitate hierarchical graph representation learning. Existing graph pooling methods commonly consist of two stages: selecting top-ranked nodes and discarding the remaining to construct coarsened graph representations. However, this paper highlights two key issues with these methods: 1) The process of selecting nodes to discard frequently employs additional Graph Convolutional Networks or Multilayer Perceptrons, lacking a thorough evaluation of each node's impact on the final graph representation and subsequent prediction tasks. 2) Current graph pooling methods tend to directly discard the noise segment (dropped) of the graph without accounting for the latent information contained within these elements. To address the first issue, we introduce a novel Graph Explicit Pooling (GrePool) method, which selects nodes by explicitly leveraging the relationships between the nodes and final representation vectors crucial for classification. The second issue is addressed using an extended version of GrePool (i.e., GrePool+), which applies a uniform loss on the discarded nodes. This addition is designed to augment the training process and improve classification accuracy. Furthermore, we conduct comprehensive experiments across 12 widely used datasets to validate our proposed method's effectiveness, including the Open Graph Benchmark datasets. Our experimental results uniformly demonstrate that GrePool outperforms 14 baseline methods for most datasets. Likewise, implementing GrePool+ enhances GrePool's performance without incurring additional computational costs.
Comprehensive Graph Gradual Pruning for Sparse Training in Graph Neural Networks
Jul 19, 2022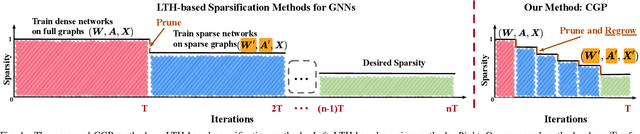
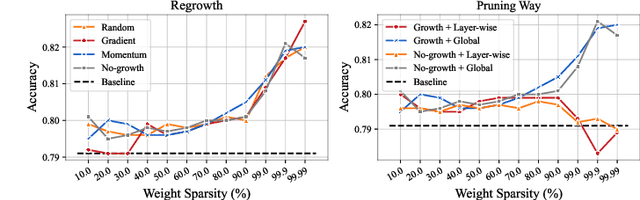
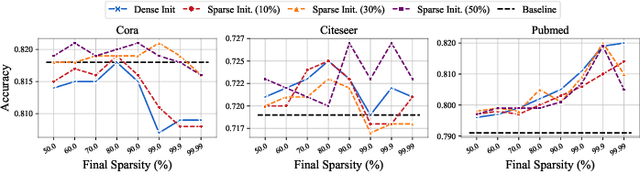
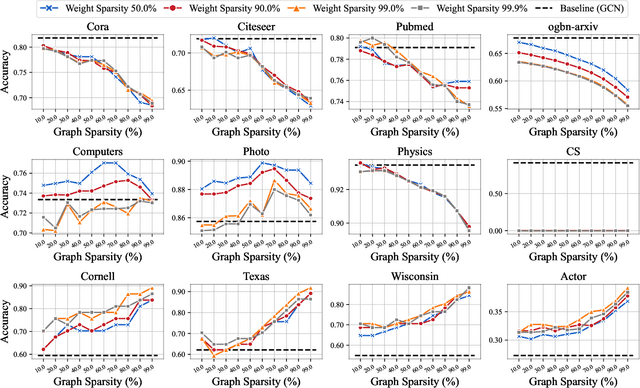
Graph Neural Networks (GNNs) tend to suffer from high computation costs due to the exponentially increasing scale of graph data and the number of model parameters, which restricts their utility in practical applications. To this end, some recent works focus on sparsifying GNNs with the lottery ticket hypothesis (LTH) to reduce inference costs while maintaining performance levels. However, the LTH-based methods suffer from two major drawbacks: 1) they require exhaustive and iterative training of dense models, resulting in an extremely large training computation cost, and 2) they only trim graph structures and model parameters but ignore the node feature dimension, where significant redundancy exists. To overcome the above limitations, we propose a comprehensive graph gradual pruning framework termed CGP. This is achieved by designing a during-training graph pruning paradigm to dynamically prune GNNs within one training process. Unlike LTH-based methods, the proposed CGP approach requires no re-training, which significantly reduces the computation costs. Furthermore, we design a co-sparsifying strategy to comprehensively trim all three core elements of GNNs: graph structures, node features, and model parameters. Meanwhile, aiming at refining the pruning operation, we introduce a regrowth process into our CGP framework, in order to re-establish the pruned but important connections. The proposed CGP is evaluated by using a node classification task across 6 GNN architectures, including shallow models (GCN and GAT), shallow-but-deep-propagation models (SGC and APPNP), and deep models (GCNII and ResGCN), on a total of 14 real-world graph datasets, including large-scale graph datasets from the challenging Open Graph Benchmark. Experiments reveal that our proposed strategy greatly improves both training and inference efficiency while matching or even exceeding the accuracy of existing methods.
Ensemble p-Laplacian Regularization for Remote Sensing Image Recognition
Jun 21, 2018



Recently, manifold regularized semi-supervised learning (MRSSL) received considerable attention because it successfully exploits the geometry of the intrinsic data probability distribution including both labeled and unlabeled samples to leverage the performance of a learning model. As a natural nonlinear generalization of graph Laplacian, p-Laplacian has been proved having the rich theoretical foundations to better preserve the local structure. However, it is difficult to determine the fitting graph p-Lapalcian i.e. the parameter which is a critical factor for the performance of graph p-Laplacian. Therefore, we develop an ensemble p-Laplacian regularization (EpLapR) to fully approximate the intrinsic manifold of the data distribution. EpLapR incorporates multiple graphs into a regularization term in order to sufficiently explore the complementation of graph p-Laplacian. Specifically, we construct a fused graph by introducing an optimization approach to assign suitable weights on different p-value graphs. And then, we conduct semi-supervised learning framework on the fused graph. Extensive experiments on UC-Merced data set demonstrate the effectiveness and efficiency of the proposed method.
Hypergraph p-Laplacian Regularization for Remote Sensing Image Recognition
Jun 21, 2018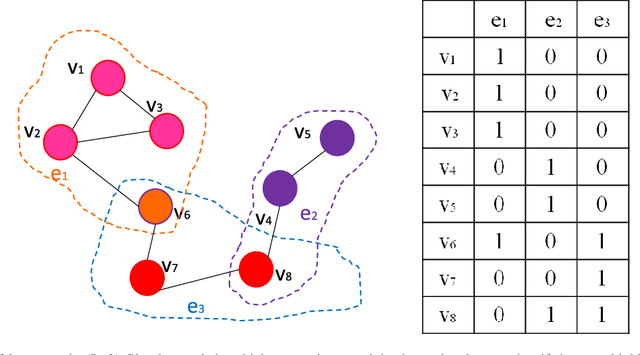
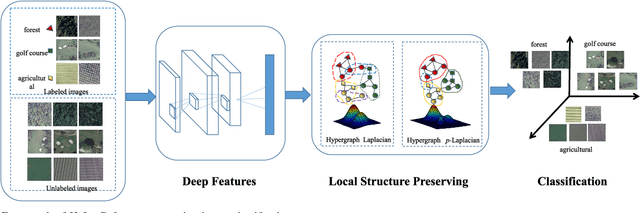
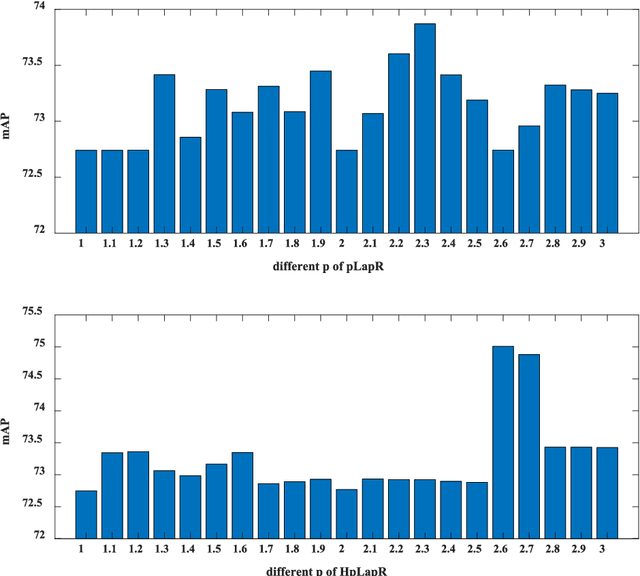
It is of great importance to preserve locality and similarity information in semi-supervised learning (SSL) based applications. Graph based SSL and manifold regularization based SSL including Laplacian regularization (LapR) and Hypergraph Laplacian regularization (HLapR) are representative SSL methods and have achieved prominent performance by exploiting the relationship of sample distribution. However, it is still a great challenge to exactly explore and exploit the local structure of the data distribution. In this paper, we present an effect and effective approximation algorithm of Hypergraph p-Laplacian and then propose Hypergraph p-Laplacian regularization (HpLapR) to preserve the geometry of the probability distribution. In particular, p-Laplacian is a nonlinear generalization of the standard graph Laplacian and Hypergraph is a generalization of a standard graph. Therefore, the proposed HpLapR provides more potential to exploiting the local structure preserving. We apply HpLapR to logistic regression and conduct the implementations for remote sensing image recognition. We compare the proposed HpLapR to several popular manifold regularization based SSL methods including LapR, HLapR and HpLapR on UC-Merced dataset. The experimental results demonstrate the superiority of the proposed HpLapR.