 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJia Wu
MoCha-Stereo: Motif Channel Attention Network for Stereo Matching
Apr 11, 2024
Learning-based stereo matching techniques have made significant progress. However, existing methods inevitably lose geometrical structure information during the feature channel generation process, resulting in edge detail mismatches. In this paper, the Motif Cha}nnel Attention Stereo Matching Network (MoCha-Stereo) is designed to address this problem. We provide the Motif Channel Correlation Volume (MCCV) to determine more accurate edge matching costs. MCCV is achieved by projecting motif channels, which capture common geometric structures in feature channels, onto feature maps and cost volumes. In addition, edge variations in %potential feature channels of the reconstruction error map also affect details matching, we propose the Reconstruction Error Motif Penalty (REMP) module to further refine the full-resolution disparity estimation. REMP integrates the frequency information of typical channel features from the reconstruction error. MoCha-Stereo ranks 1st on the KITTI-2015 and KITTI-2012 Reflective leaderboards. Our structure also shows excellent performance in Multi-View Stereo. Code is avaliable at https://github.com/ZYangChen/MoCha-Stereo.
* Accepted to CVPR 2024
Exploring Sparsity in Graph Transformers
Dec 09, 2023Graph Transformers (GTs) have achieved impressive results on various graph-related tasks. However, the huge computational cost of GTs hinders their deployment and application, especially in resource-constrained environments. Therefore, in this paper, we explore the feasibility of sparsifying GTs, a significant yet under-explored topic. We first discuss the redundancy of GTs based on the characteristics of existing GT models, and then propose a comprehensive \textbf{G}raph \textbf{T}ransformer \textbf{SP}arsification (GTSP) framework that helps to reduce the computational complexity of GTs from four dimensions: the input graph data, attention heads, model layers, and model weights. Specifically, GTSP designs differentiable masks for each individual compressible component, enabling effective end-to-end pruning. We examine our GTSP through extensive experiments on prominent GTs, including GraphTrans, Graphormer, and GraphGPS. The experimental results substantiate that GTSP effectively cuts computational costs, accompanied by only marginal decreases in accuracy or, in some cases, even improvements. For instance, GTSP yields a reduction of 30\% in Floating Point Operations while contributing to a 1.8\% increase in Area Under the Curve accuracy on OGBG-HIV dataset. Furthermore, we provide several insights on the characteristics of attention heads and the behavior of attention mechanisms, all of which have immense potential to inspire future research endeavors in this domain.
Careful Selection and Thoughtful Discarding: Graph Explicit Pooling Utilizing Discarded Nodes
Nov 21, 2023Graph pooling has been increasingly recognized as crucial for Graph Neural Networks (GNNs) to facilitate hierarchical graph representation learning. Existing graph pooling methods commonly consist of two stages: selecting top-ranked nodes and discarding the remaining to construct coarsened graph representations. However, this paper highlights two key issues with these methods: 1) The process of selecting nodes to discard frequently employs additional Graph Convolutional Networks or Multilayer Perceptrons, lacking a thorough evaluation of each node's impact on the final graph representation and subsequent prediction tasks. 2) Current graph pooling methods tend to directly discard the noise segment (dropped) of the graph without accounting for the latent information contained within these elements. To address the first issue, we introduce a novel Graph Explicit Pooling (GrePool) method, which selects nodes by explicitly leveraging the relationships between the nodes and final representation vectors crucial for classification. The second issue is addressed using an extended version of GrePool (i.e., GrePool+), which applies a uniform loss on the discarded nodes. This addition is designed to augment the training process and improve classification accuracy. Furthermore, we conduct comprehensive experiments across 12 widely used datasets to validate our proposed method's effectiveness, including the Open Graph Benchmark datasets. Our experimental results uniformly demonstrate that GrePool outperforms 14 baseline methods for most datasets. Likewise, implementing GrePool+ enhances GrePool's performance without incurring additional computational costs.
Uncertainty-guided Boundary Learning for Imbalanced Social Event Detection
Oct 30, 2023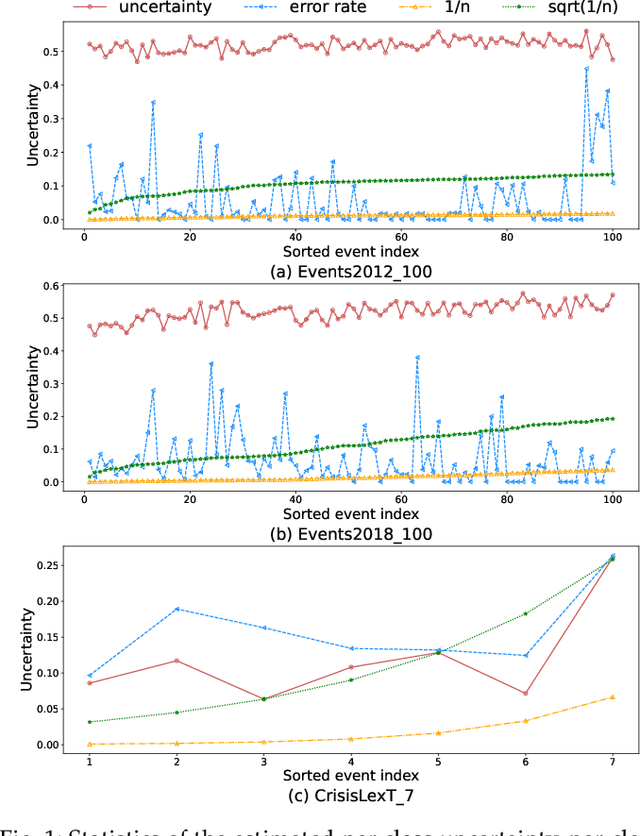
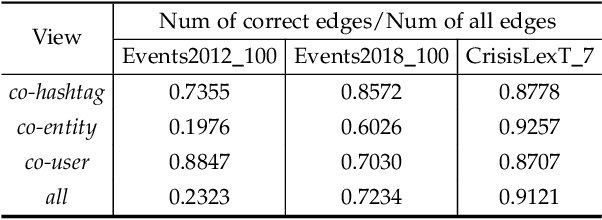
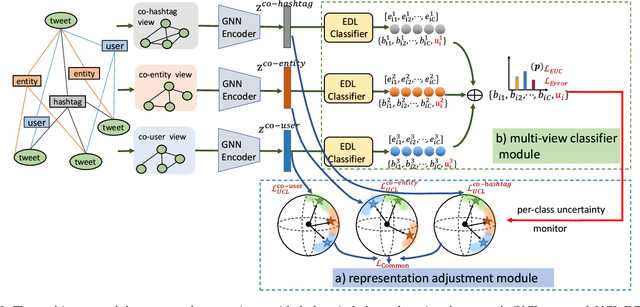
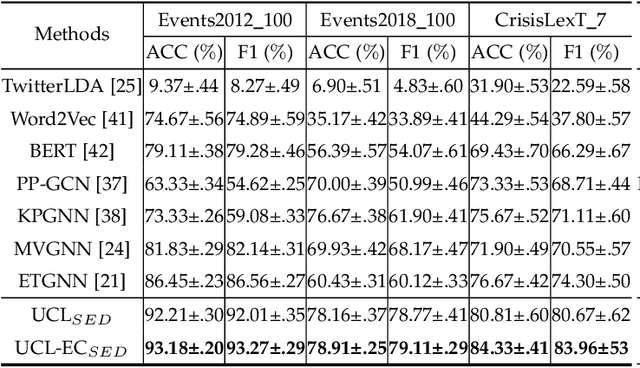
Real-world social events typically exhibit a severe class-imbalance distribution, which makes the trained detection model encounter a serious generalization challenge. Most studies solve this problem from the frequency perspective and emphasize the representation or classifier learning for tail classes. While in our observation, compared to the rarity of classes, the calibrated uncertainty estimated from well-trained evidential deep learning networks better reflects model performance. To this end, we propose a novel uncertainty-guided class imbalance learning framework - UCL$_{SED}$, and its variant - UCL-EC$_{SED}$, for imbalanced social event detection tasks. We aim to improve the overall model performance by enhancing model generalization to those uncertain classes. Considering performance degradation usually comes from misclassifying samples as their confusing neighboring classes, we focus on boundary learning in latent space and classifier learning with high-quality uncertainty estimation. First, we design a novel uncertainty-guided contrastive learning loss, namely UCL and its variant - UCL-EC, to manipulate distinguishable representation distribution for imbalanced data. During training, they force all classes, especially uncertain ones, to adaptively adjust a clear separable boundary in the feature space. Second, to obtain more robust and accurate class uncertainty, we combine the results of multi-view evidential classifiers via the Dempster-Shafer theory under the supervision of an additional calibration method. We conduct experiments on three severely imbalanced social event datasets including Events2012\_100, Events2018\_100, and CrisisLexT\_7. Our model significantly improves social event representation and classification tasks in almost all classes, especially those uncertain ones.
* Accepted by TKDE 2023
Discriminative Graph-level Anomaly Detection via Dual-students-teacher Model
Aug 03, 2023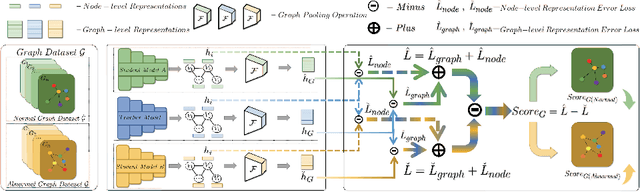
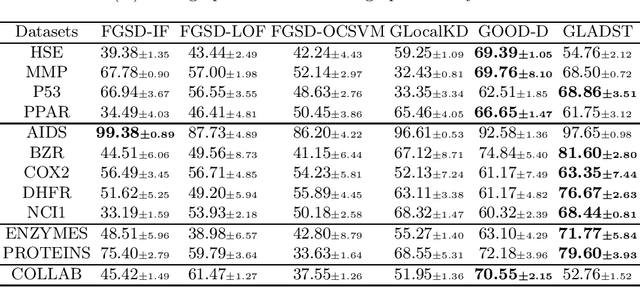
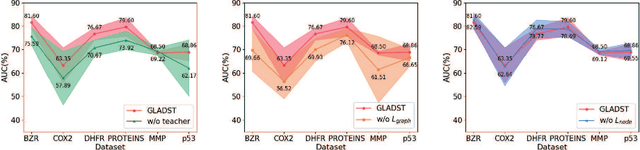
Different from the current node-level anomaly detection task, the goal of graph-level anomaly detection is to find abnormal graphs that significantly differ from others in a graph set. Due to the scarcity of research on the work of graph-level anomaly detection, the detailed description of graph-level anomaly is insufficient. Furthermore, existing works focus on capturing anomalous graph information to learn better graph representations, but they ignore the importance of an effective anomaly score function for evaluating abnormal graphs. Thus, in this work, we first define anomalous graph information including node and graph property anomalies in a graph set and adopt node-level and graph-level information differences to identify them, respectively. Then, we introduce a discriminative graph-level anomaly detection framework with dual-students-teacher model, where the teacher model with a heuristic loss are trained to make graph representations more divergent. Then, two competing student models trained by normal and abnormal graphs respectively fit graph representations of the teacher model in terms of node-level and graph-level representation perspectives. Finally, we combine representation errors between two student models to discriminatively distinguish anomalous graphs. Extensive experiment analysis demonstrates that our method is effective for the graph-level anomaly detection task on graph datasets in the real world.
Hyperbolic Geometric Graph Representation Learning for Hierarchy-imbalance Node Classification
Apr 11, 2023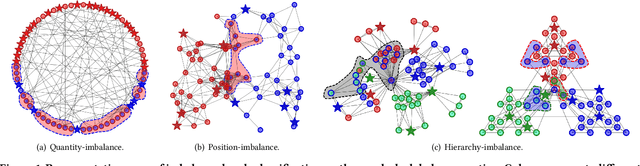
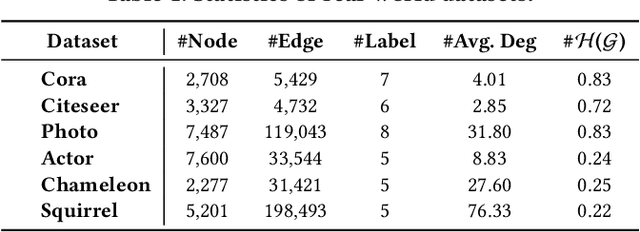
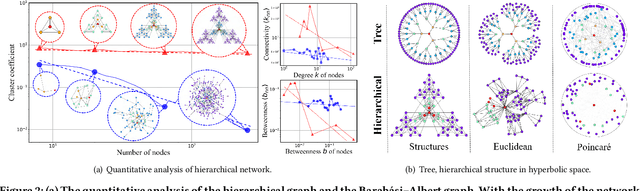
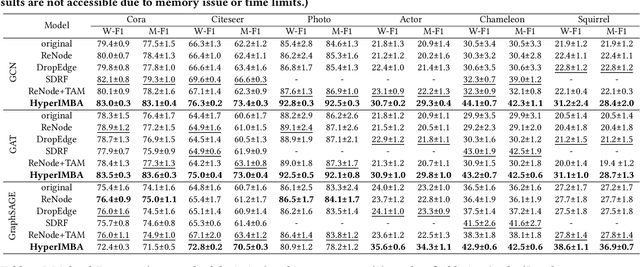
Learning unbiased node representations for imbalanced samples in the graph has become a more remarkable and important topic. For the graph, a significant challenge is that the topological properties of the nodes (e.g., locations, roles) are unbalanced (topology-imbalance), other than the number of training labeled nodes (quantity-imbalance). Existing studies on topology-imbalance focus on the location or the local neighborhood structure of nodes, ignoring the global underlying hierarchical properties of the graph, i.e., hierarchy. In the real-world scenario, the hierarchical structure of graph data reveals important topological properties of graphs and is relevant to a wide range of applications. We find that training labeled nodes with different hierarchical properties have a significant impact on the node classification tasks and confirm it in our experiments. It is well known that hyperbolic geometry has a unique advantage in representing the hierarchical structure of graphs. Therefore, we attempt to explore the hierarchy-imbalance issue for node classification of graph neural networks with a novelty perspective of hyperbolic geometry, including its characteristics and causes. Then, we propose a novel hyperbolic geometric hierarchy-imbalance learning framework, named HyperIMBA, to alleviate the hierarchy-imbalance issue caused by uneven hierarchy-levels and cross-hierarchy connectivity patterns of labeled nodes.Extensive experimental results demonstrate the superior effectiveness of HyperIMBA for hierarchy-imbalance node classification tasks.
SE-GSL: A General and Effective Graph Structure Learning Framework through Structural Entropy Optimization
Mar 17, 2023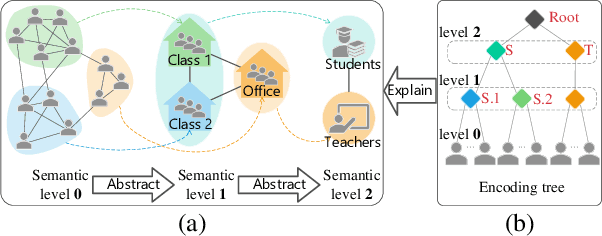
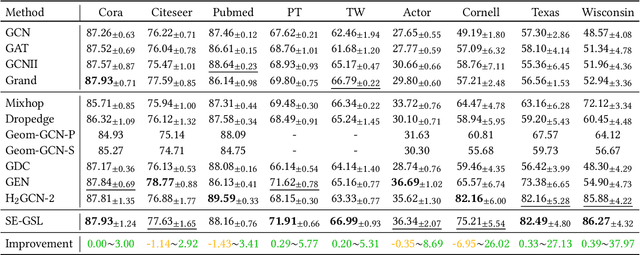
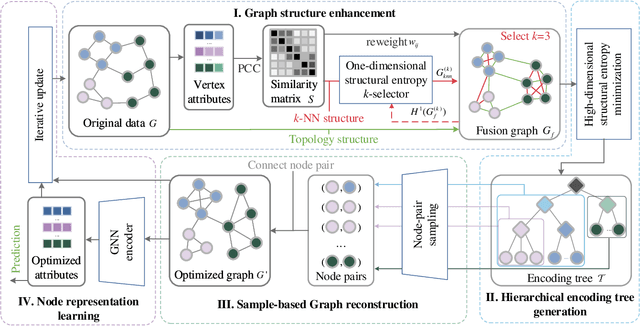
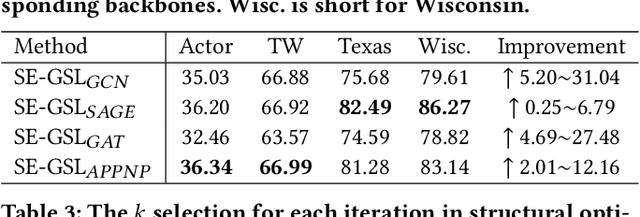
Graph Neural Networks (GNNs) are de facto solutions to structural data learning. However, it is susceptible to low-quality and unreliable structure, which has been a norm rather than an exception in real-world graphs. Existing graph structure learning (GSL) frameworks still lack robustness and interpretability. This paper proposes a general GSL framework, SE-GSL, through structural entropy and the graph hierarchy abstracted in the encoding tree. Particularly, we exploit the one-dimensional structural entropy to maximize embedded information content when auxiliary neighbourhood attributes are fused to enhance the original graph. A new scheme of constructing optimal encoding trees is proposed to minimize the uncertainty and noises in the graph whilst assuring proper community partition in hierarchical abstraction. We present a novel sample-based mechanism for restoring the graph structure via node structural entropy distribution. It increases the connectivity among nodes with larger uncertainty in lower-level communities. SE-GSL is compatible with various GNN models and enhances the robustness towards noisy and heterophily structures. Extensive experiments show significant improvements in the effectiveness and robustness of structure learning and node representation learning.
KGTrust: Evaluating Trustworthiness of SIoT via Knowledge Enhanced Graph Neural Networks
Feb 22, 2023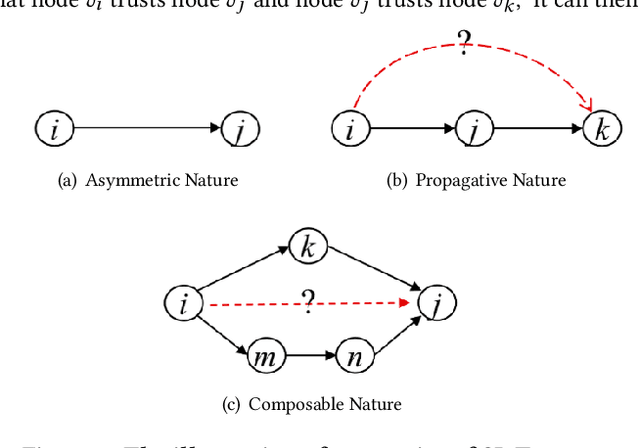
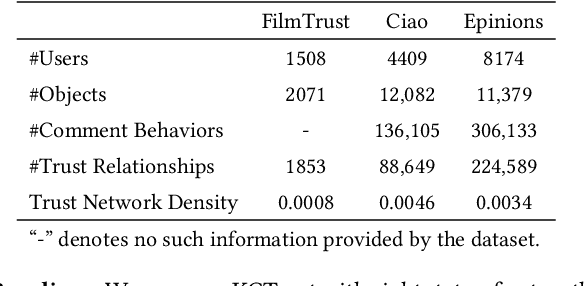
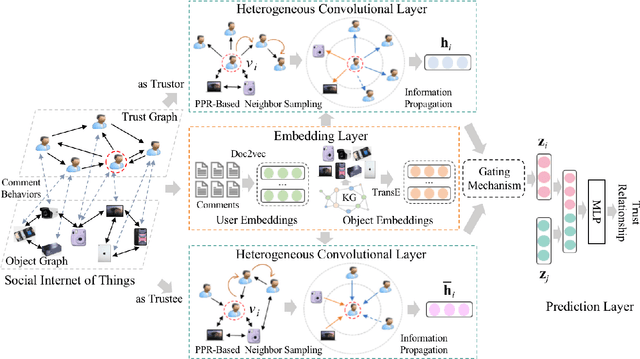
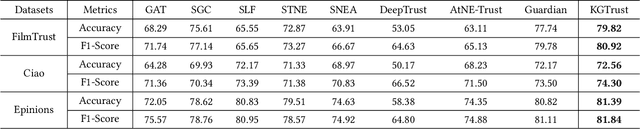
Social Internet of Things (SIoT), a promising and emerging paradigm that injects the notion of social networking into smart objects (i.e., things), paving the way for the next generation of Internet of Things. However, due to the risks and uncertainty, a crucial and urgent problem to be settled is establishing reliable relationships within SIoT, that is, trust evaluation. Graph neural networks for trust evaluation typically adopt a straightforward way such as one-hot or node2vec to comprehend node characteristics, which ignores the valuable semantic knowledge attached to nodes. Moreover, the underlying structure of SIoT is usually complex, including both the heterogeneous graph structure and pairwise trust relationships, which renders hard to preserve the properties of SIoT trust during information propagation. To address these aforementioned problems, we propose a novel knowledge-enhanced graph neural network (KGTrust) for better trust evaluation in SIoT. Specifically, we first extract useful knowledge from users' comment behaviors and external structured triples related to object descriptions, in order to gain a deeper insight into the semantics of users and objects. Furthermore, we introduce a discriminative convolutional layer that utilizes heterogeneous graph structure, node semantics, and augmented trust relationships to learn node embeddings from the perspective of a user as a trustor or a trustee, effectively capturing multi-aspect properties of SIoT trust during information propagation. Finally, a trust prediction layer is developed to estimate the trust relationships between pairwise nodes. Extensive experiments on three public datasets illustrate the superior performance of KGTrust over state-of-the-art methods.
Heterogeneous Social Event Detection via Hyperbolic Graph Representations
Feb 20, 2023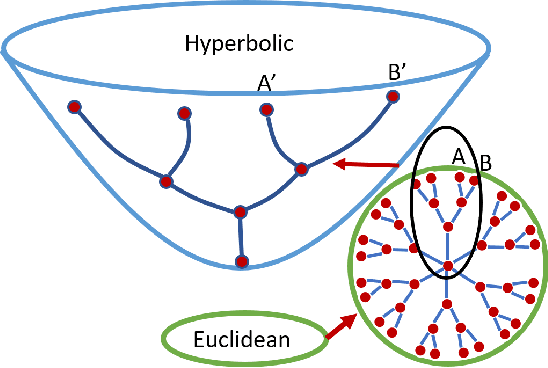

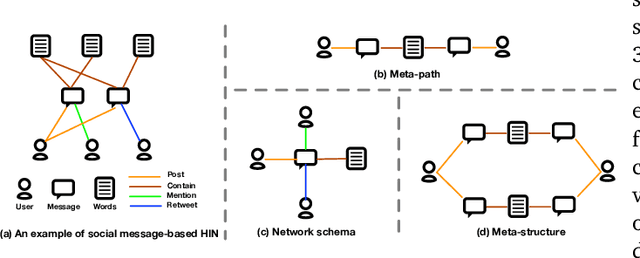
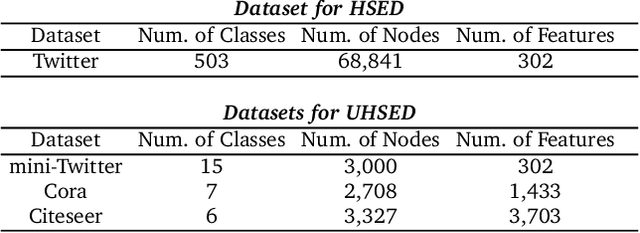
Social events reflect the dynamics of society and, here, natural disasters and emergencies receive significant attention. The timely detection of these events can provide organisations and individuals with valuable information to reduce or avoid losses. However, due to the complex heterogeneities of the content and structure of social media, existing models can only learn limited information; large amounts of semantic and structural information are ignored. In addition, due to high labour costs, it is rare for social media datasets to include high-quality labels, which also makes it challenging for models to learn information from social media. In this study, we propose two hyperbolic graph representation-based methods for detecting social events from heterogeneous social media environments. For cases where a dataset has labels, we designed a Hyperbolic Social Event Detection (HSED) model that converts complex social information into a unified social message graph. This model addresses the heterogeneity of social media, and, with this graph, the information in social media can be used to capture structural information based on the properties of hyperbolic space. For cases where the dataset is unlabelled, we designed an Unsupervised Hyperbolic Social Event Detection (UHSED). This model is based on the HSED model but includes graph contrastive learning to make it work in unlabelled scenarios. Extensive experiments demonstrate the superiority of the proposed approaches.