 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLei Jiang
GCN-DevLSTM: Path Development for Skeleton-Based Action Recognition
Mar 22, 2024
Skeleton-based action recognition (SAR) in videos is an important but challenging task in computer vision. The recent state-of-the-art models for SAR are primarily based on graph convolutional neural networks (GCNs), which are powerful in extracting the spatial information of skeleton data. However, it is yet clear that such GCN-based models can effectively capture the temporal dynamics of human action sequences. To this end, we propose the DevLSTM module, which exploits the path development -- a principled and parsimonious representation for sequential data by leveraging the Lie group structure. The path development, originated from Rough path theory, can effectively capture the order of events in high-dimensional stream data with massive dimension reduction and consequently enhance the LSTM module substantially. Our proposed G-DevLSTM module can be conveniently plugged into the temporal graph, complementing existing advanced GCN-based models. Our empirical studies on the NTU60, NTU120 and Chalearn2013 datasets demonstrate that our proposed hybrid model significantly outperforms the current best-performing methods in SAR tasks. The code is available at https://github.com/DeepIntoStreams/GCN-DevLSTM.
IoTCO2: Assessing the End-To-End Carbon Footprint of Internet-of-Things-Enabled Deep Learning
Mar 16, 2024

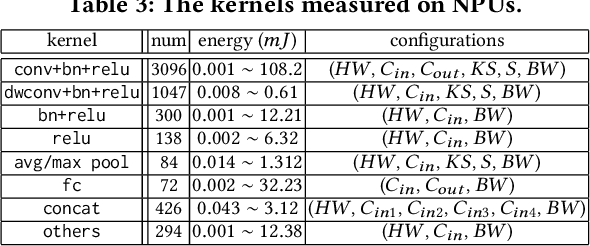
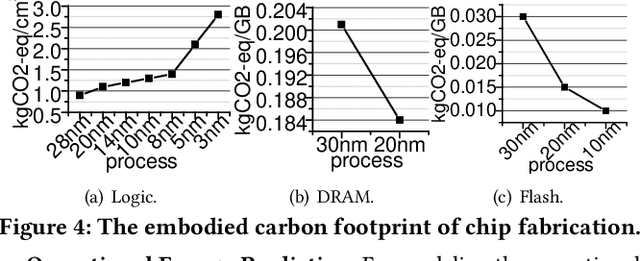
To improve privacy and ensure quality-of-service (QoS), deep learning (DL) models are increasingly deployed on Internet of Things (IoT) devices for data processing, significantly increasing the carbon footprint associated with DL on IoT, covering both operational and embodied aspects. Existing operational energy predictors often overlook quantized DL models and emerging neural processing units (NPUs), while embodied carbon footprint modeling tools neglect non-computing hardware components common in IoT devices, creating a gap in accurate carbon footprint modeling tools for IoT-enabled DL. This paper introduces \textit{\carb}, an end-to-end modeling tool for precise carbon footprint estimation in IoT-enabled DL, demonstrating a maximum $\pm21\%$ deviation in carbon footprint values compared to actual measurements across various DL models. Additionally, practical applications of \carb are showcased through multiple user case studies.
Prompt Based Tri-Channel Graph Convolution Neural Network for Aspect Sentiment Triplet Extraction
Dec 24, 2023Aspect Sentiment Triplet Extraction (ASTE) is an emerging task to extract a given sentence's triplets, which consist of aspects, opinions, and sentiments. Recent studies tend to address this task with a table-filling paradigm, wherein word relations are encoded in a two-dimensional table, and the process involves clarifying all the individual cells to extract triples. However, these studies ignore the deep interaction between neighbor cells, which we find quite helpful for accurate extraction. To this end, we propose a novel model for the ASTE task, called Prompt-based Tri-Channel Graph Convolution Neural Network (PT-GCN), which converts the relation table into a graph to explore more comprehensive relational information. Specifically, we treat the original table cells as nodes and utilize a prompt attention score computation module to determine the edges' weights. This enables us to construct a target-aware grid-like graph to enhance the overall extraction process. After that, a triple-channel convolution module is conducted to extract precise sentiment knowledge. Extensive experiments on the benchmark datasets show that our model achieves state-of-the-art performance. The code is available at https://github.com/KunPunCN/PT-GCN.
TrojFair: Trojan Fairness Attacks
Dec 16, 2023Deep learning models have been incorporated into high-stakes sectors, including healthcare diagnosis, loan approvals, and candidate recruitment, among others. Consequently, any bias or unfairness in these models can harm those who depend on such models. In response, many algorithms have emerged to ensure fairness in deep learning. However, while the potential for harm is substantial, the resilience of these fair deep learning models against malicious attacks has never been thoroughly explored, especially in the context of emerging Trojan attacks. Moving beyond prior research, we aim to fill this void by introducing \textit{TrojFair}, a Trojan fairness attack. Unlike existing attacks, TrojFair is model-agnostic and crafts a Trojaned model that functions accurately and equitably for clean inputs. However, it displays discriminatory behaviors \text{-} producing both incorrect and unfair results \text{-} for specific groups with tainted inputs containing a trigger. TrojFair is a stealthy Fairness attack that is resilient to existing model fairness audition detectors since the model for clean inputs is fair. TrojFair achieves a target group attack success rate exceeding $88.77\%$, with an average accuracy loss less than $0.44\%$. It also maintains a high discriminative score between the target and non-target groups across various datasets and models.
TrojFSP: Trojan Insertion in Few-shot Prompt Tuning
Dec 16, 2023Prompt tuning is one of the most effective solutions to adapting a fixed pre-trained language model (PLM) for various downstream tasks, especially with only a few input samples. However, the security issues, e.g., Trojan attacks, of prompt tuning on a few data samples are not well-studied. Transferring established data poisoning attacks directly to few-shot prompt tuning presents multiple challenges. One significant issue is the \textit{poisoned imbalance issue}, where non-target class samples are added to the target class, resulting in a greater number of target-class samples compared to non-target class. While this issue is not critical in regular tuning, it significantly hampers the few-shot prompt tuning, making it difficult to simultaneously achieve a high attack success rate (ASR) and maintain clean data accuracy (CDA). Additionally, few-shot prompting is prone to overfitting in terms of both ASR and CDA. In this paper, we introduce \textit{TrojFSP}, a method designed to address the challenges. To solve the poisoned imbalance issue, we develop a \textit{Target-Class Shrink (TC-Shrink)} technique, which aims to equalize the number of poisoning samples. To combat overfitting, we employ a \textit{Selective Token Poisoning} technique to boost attack performance. Furthermore, we introduce a \textit{Trojan-Trigger Attention} objective function to amplify the attention of the poisoned trojan prompt on triggers. Experiments show that our TrojFSP achieves an ASR of over 99\% while maintaining negligible decreases in CDA across various PLMs and datasets.
SA-Med2D-20M Dataset: Segment Anything in 2D Medical Imaging with 20 Million masks
Nov 20, 2023Segment Anything Model (SAM) has achieved impressive results for natural image segmentation with input prompts such as points and bounding boxes. Its success largely owes to massive labeled training data. However, directly applying SAM to medical image segmentation cannot perform well because SAM lacks medical knowledge -- it does not use medical images for training. To incorporate medical knowledge into SAM, we introduce SA-Med2D-20M, a large-scale segmentation dataset of 2D medical images built upon numerous public and private datasets. It consists of 4.6 million 2D medical images and 19.7 million corresponding masks, covering almost the whole body and showing significant diversity. This paper describes all the datasets collected in SA-Med2D-20M and details how to process these datasets. Furthermore, comprehensive statistics of SA-Med2D-20M are presented to facilitate the better use of our dataset, which can help the researchers build medical vision foundation models or apply their models to downstream medical applications. We hope that the large scale and diversity of SA-Med2D-20M can be leveraged to develop medical artificial intelligence for enhancing diagnosis, medical image analysis, knowledge sharing, and education. The data with the redistribution license is publicly available at https://github.com/OpenGVLab/SAM-Med2D.
Uncertainty-guided Boundary Learning for Imbalanced Social Event Detection
Oct 30, 2023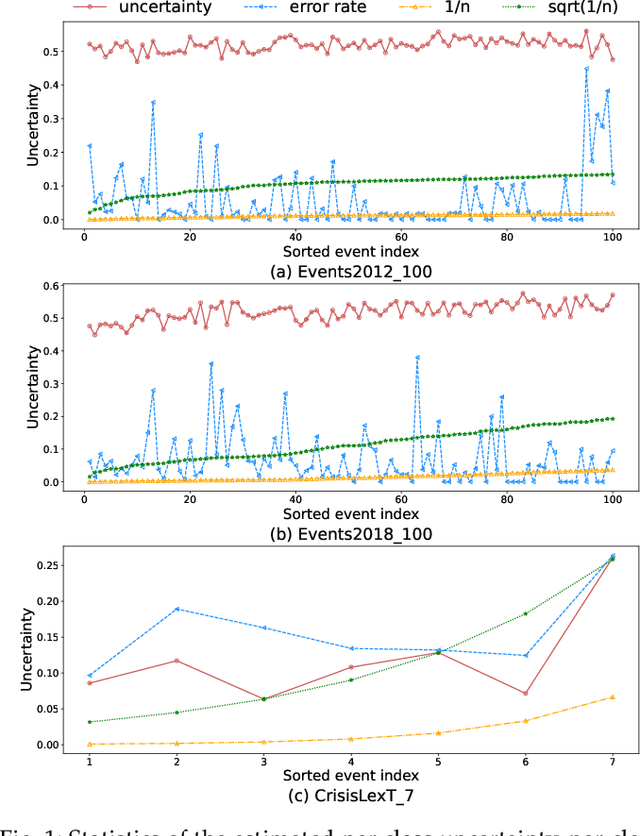
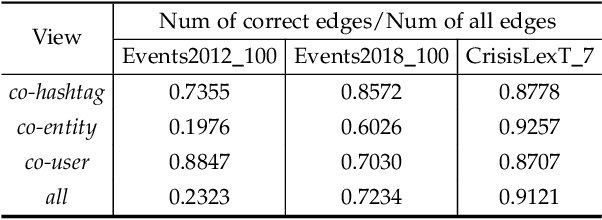
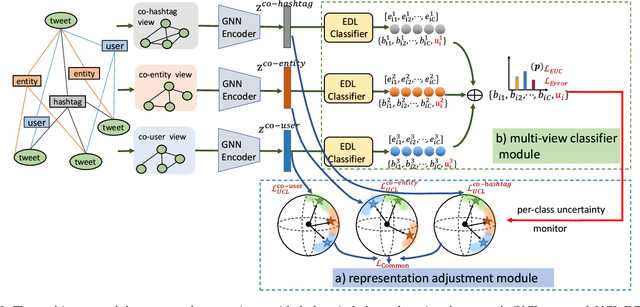
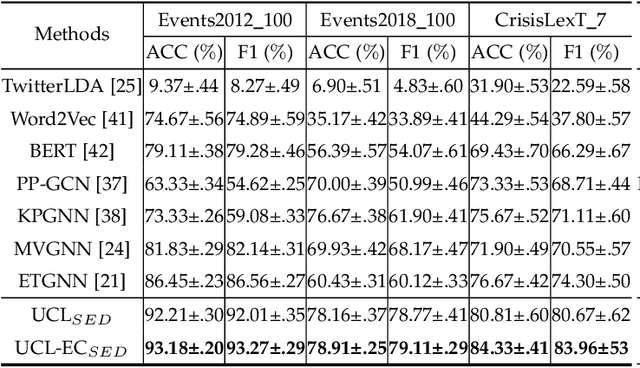
Real-world social events typically exhibit a severe class-imbalance distribution, which makes the trained detection model encounter a serious generalization challenge. Most studies solve this problem from the frequency perspective and emphasize the representation or classifier learning for tail classes. While in our observation, compared to the rarity of classes, the calibrated uncertainty estimated from well-trained evidential deep learning networks better reflects model performance. To this end, we propose a novel uncertainty-guided class imbalance learning framework - UCL$_{SED}$, and its variant - UCL-EC$_{SED}$, for imbalanced social event detection tasks. We aim to improve the overall model performance by enhancing model generalization to those uncertain classes. Considering performance degradation usually comes from misclassifying samples as their confusing neighboring classes, we focus on boundary learning in latent space and classifier learning with high-quality uncertainty estimation. First, we design a novel uncertainty-guided contrastive learning loss, namely UCL and its variant - UCL-EC, to manipulate distinguishable representation distribution for imbalanced data. During training, they force all classes, especially uncertain ones, to adaptively adjust a clear separable boundary in the feature space. Second, to obtain more robust and accurate class uncertainty, we combine the results of multi-view evidential classifiers via the Dempster-Shafer theory under the supervision of an additional calibration method. We conduct experiments on three severely imbalanced social event datasets including Events2012\_100, Events2018\_100, and CrisisLexT\_7. Our model significantly improves social event representation and classification tasks in almost all classes, especially those uncertain ones.
* Accepted by TKDE 2023
LLMCarbon: Modeling the end-to-end Carbon Footprint of Large Language Models
Sep 25, 2023The carbon footprint associated with large language models (LLMs) is a significant concern, encompassing emissions from their training, inference, experimentation, and storage processes, including operational and embodied carbon emissions. An essential aspect is accurately estimating the carbon impact of emerging LLMs even before their training, which heavily relies on GPU usage. Existing studies have reported the carbon footprint of LLM training, but only one tool, mlco2, can predict the carbon footprint of new neural networks prior to physical training. However, mlco2 has several serious limitations. It cannot extend its estimation to dense or mixture-of-experts (MoE) LLMs, disregards critical architectural parameters, focuses solely on GPUs, and cannot model embodied carbon footprints. Addressing these gaps, we introduce \textit{LLMCarbon}, an end-to-end carbon footprint projection model designed for both dense and MoE LLMs. Compared to mlco2, LLMCarbon significantly enhances the accuracy of carbon footprint estimations for various LLMs.
SAM-Med2D
Aug 30, 2023

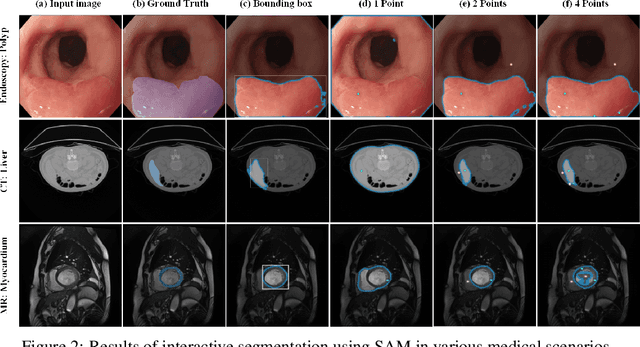
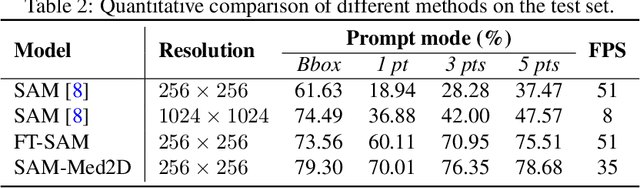
The Segment Anything Model (SAM) represents a state-of-the-art research advancement in natural image segmentation, achieving impressive results with input prompts such as points and bounding boxes. However, our evaluation and recent research indicate that directly applying the pretrained SAM to medical image segmentation does not yield satisfactory performance. This limitation primarily arises from significant domain gap between natural images and medical images. To bridge this gap, we introduce SAM-Med2D, the most comprehensive studies on applying SAM to medical 2D images. Specifically, we first collect and curate approximately 4.6M images and 19.7M masks from public and private datasets, constructing a large-scale medical image segmentation dataset encompassing various modalities and objects. Then, we comprehensively fine-tune SAM on this dataset and turn it into SAM-Med2D. Unlike previous methods that only adopt bounding box or point prompts as interactive segmentation approach, we adapt SAM to medical image segmentation through more comprehensive prompts involving bounding boxes, points, and masks. We additionally fine-tune the encoder and decoder of the original SAM to obtain a well-performed SAM-Med2D, leading to the most comprehensive fine-tuning strategies to date. Finally, we conducted a comprehensive evaluation and analysis to investigate the performance of SAM-Med2D in medical image segmentation across various modalities, anatomical structures, and organs. Concurrently, we validated the generalization capability of SAM-Med2D on 9 datasets from MICCAI 2023 challenge. Overall, our approach demonstrated significantly superior performance and generalization capability compared to SAM.
SSL-Cleanse: Trojan Detection and Mitigation in Self-Supervised Learning
Mar 16, 2023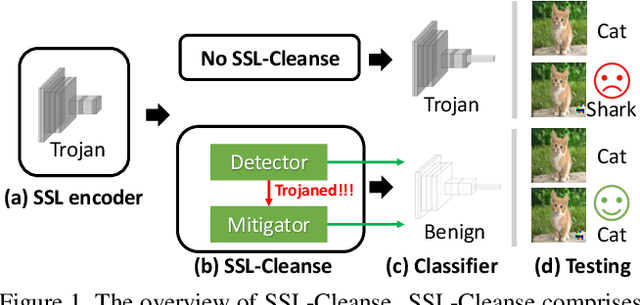
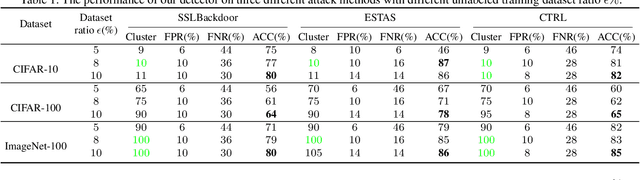


Self-supervised learning (SSL) is a commonly used approach to learning and encoding data representations. By using a pre-trained SSL image encoder and training a downstream classifier on top of it, impressive performance can be achieved on various tasks with very little labeled data. The increasing usage of SSL has led to an uptick in security research related to SSL encoders and the development of various Trojan attacks. The danger posed by Trojan attacks inserted in SSL encoders lies in their ability to operate covertly and spread widely among various users and devices. The presence of backdoor behavior in Trojaned encoders can inadvertently be inherited by downstream classifiers, making it even more difficult to detect and mitigate the threat. Although current Trojan detection methods in supervised learning can potentially safeguard SSL downstream classifiers, identifying and addressing triggers in the SSL encoder before its widespread dissemination is a challenging task. This is because downstream tasks are not always known, dataset labels are not available, and even the original training dataset is not accessible during the SSL encoder Trojan detection. This paper presents an innovative technique called SSL-Cleanse that is designed to detect and mitigate backdoor attacks in SSL encoders. We evaluated SSL-Cleanse on various datasets using 300 models, achieving an average detection success rate of 83.7% on ImageNet-100. After mitigating backdoors, on average, backdoored encoders achieve 0.24% attack success rate without great accuracy loss, proving the effectiveness of SSL-Cleanse.