 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZiyang Chen
MoCha-Stereo: Motif Channel Attention Network for Stereo Matching
Apr 11, 2024
Learning-based stereo matching techniques have made significant progress. However, existing methods inevitably lose geometrical structure information during the feature channel generation process, resulting in edge detail mismatches. In this paper, the Motif Cha}nnel Attention Stereo Matching Network (MoCha-Stereo) is designed to address this problem. We provide the Motif Channel Correlation Volume (MCCV) to determine more accurate edge matching costs. MCCV is achieved by projecting motif channels, which capture common geometric structures in feature channels, onto feature maps and cost volumes. In addition, edge variations in %potential feature channels of the reconstruction error map also affect details matching, we propose the Reconstruction Error Motif Penalty (REMP) module to further refine the full-resolution disparity estimation. REMP integrates the frequency information of typical channel features from the reconstruction error. MoCha-Stereo ranks 1st on the KITTI-2015 and KITTI-2012 Reflective leaderboards. Our structure also shows excellent performance in Multi-View Stereo. Code is avaliable at https://github.com/ZYangChen/MoCha-Stereo.
* Accepted to CVPR 2024
Real Acoustic Fields: An Audio-Visual Room Acoustics Dataset and Benchmark
Mar 27, 2024

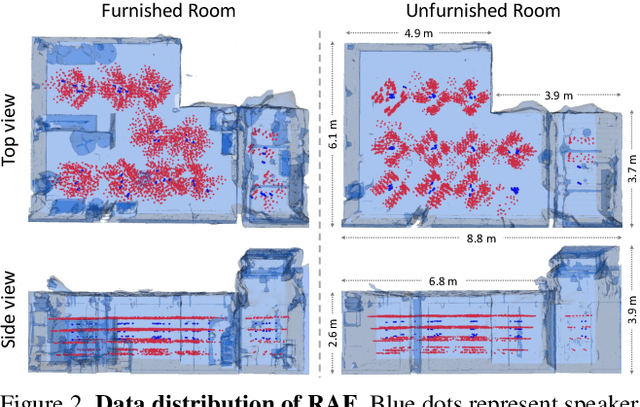
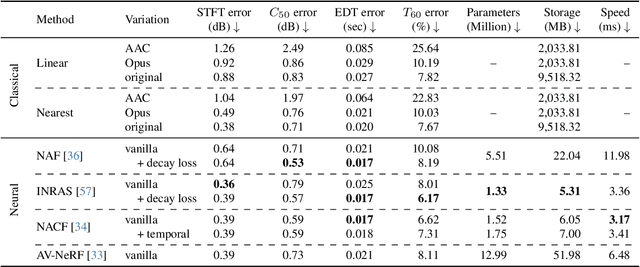
We present a new dataset called Real Acoustic Fields (RAF) that captures real acoustic room data from multiple modalities. The dataset includes high-quality and densely captured room impulse response data paired with multi-view images, and precise 6DoF pose tracking data for sound emitters and listeners in the rooms. We used this dataset to evaluate existing methods for novel-view acoustic synthesis and impulse response generation which previously relied on synthetic data. In our evaluation, we thoroughly assessed existing audio and audio-visual models against multiple criteria and proposed settings to enhance their performance on real-world data. We also conducted experiments to investigate the impact of incorporating visual data (i.e., images and depth) into neural acoustic field models. Additionally, we demonstrated the effectiveness of a simple sim2real approach, where a model is pre-trained with simulated data and fine-tuned with sparse real-world data, resulting in significant improvements in the few-shot learning approach. RAF is the first dataset to provide densely captured room acoustic data, making it an ideal resource for researchers working on audio and audio-visual neural acoustic field modeling techniques. Demos and datasets are available on our project page: https://facebookresearch.github.io/real-acoustic-fields/
Binding Touch to Everything: Learning Unified Multimodal Tactile Representations
Jan 31, 2024The ability to associate touch with other modalities has huge implications for humans and computational systems. However, multimodal learning with touch remains challenging due to the expensive data collection process and non-standardized sensor outputs. We introduce UniTouch, a unified tactile model for vision-based touch sensors connected to multiple modalities, including vision, language, and sound. We achieve this by aligning our UniTouch embeddings to pretrained image embeddings already associated with a variety of other modalities. We further propose learnable sensor-specific tokens, allowing the model to learn from a set of heterogeneous tactile sensors, all at the same time. UniTouch is capable of conducting various touch sensing tasks in the zero-shot setting, from robot grasping prediction to touch image question answering. To the best of our knowledge, UniTouch is the first to demonstrate such capabilities. Project page: https://cfeng16.github.io/UniTouch/
SegRap2023: A Benchmark of Organs-at-Risk and Gross Tumor Volume Segmentation for Radiotherapy Planning of Nasopharyngeal Carcinoma
Dec 15, 2023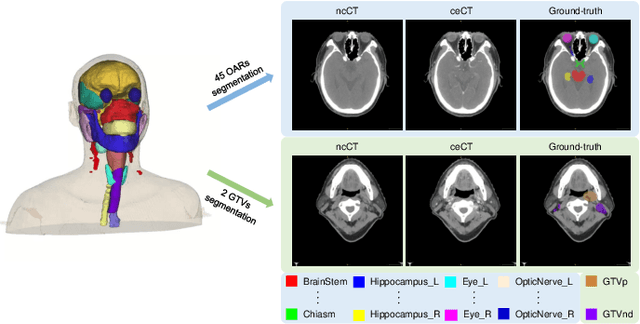

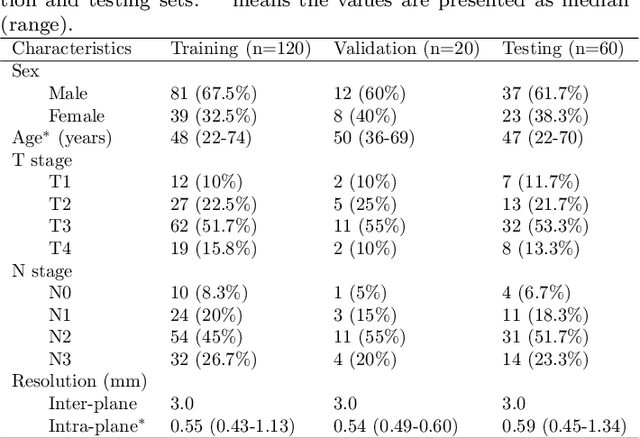
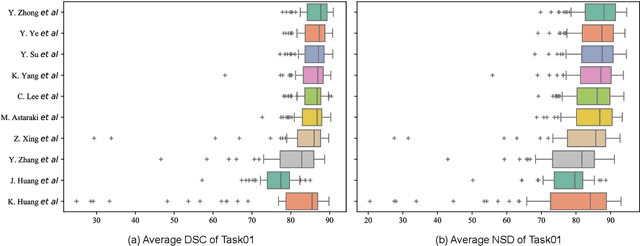
Radiation therapy is a primary and effective NasoPharyngeal Carcinoma (NPC) treatment strategy. The precise delineation of Gross Tumor Volumes (GTVs) and Organs-At-Risk (OARs) is crucial in radiation treatment, directly impacting patient prognosis. Previously, the delineation of GTVs and OARs was performed by experienced radiation oncologists. Recently, deep learning has achieved promising results in many medical image segmentation tasks. However, for NPC OARs and GTVs segmentation, few public datasets are available for model development and evaluation. To alleviate this problem, the SegRap2023 challenge was organized in conjunction with MICCAI2023 and presented a large-scale benchmark for OAR and GTV segmentation with 400 Computed Tomography (CT) scans from 200 NPC patients, each with a pair of pre-aligned non-contrast and contrast-enhanced CT scans. The challenge's goal was to segment 45 OARs and 2 GTVs from the paired CT scans. In this paper, we detail the challenge and analyze the solutions of all participants. The average Dice similarity coefficient scores for all submissions ranged from 76.68\% to 86.70\%, and 70.42\% to 73.44\% for OARs and GTVs, respectively. We conclude that the segmentation of large-size OARs is well-addressed, and more efforts are needed for GTVs and small-size or thin-structure OARs. The benchmark will remain publicly available here: https://segrap2023.grand-challenge.org
Each Test Image Deserves A Specific Prompt: Continual Test-Time Adaptation for 2D Medical Image Segmentation
Nov 30, 2023Distribution shift widely exists in medical images acquired from different medical centres and poses a significant obstacle to deploying the pre-trained semantic segmentation model in real-world applications. Test-time adaptation has proven its effectiveness in tackling the cross-domain distribution shift during inference. However, most existing methods achieve adaptation by updating the pre-trained models, rendering them susceptible to error accumulation and catastrophic forgetting when encountering a series of distribution shifts (i.e., under the continual test-time adaptation setup). To overcome these challenges caused by updating the models, in this paper, we freeze the pre-trained model and propose the Visual Prompt-based Test-Time Adaptation (VPTTA) method to train a specific prompt for each test image to align the statistics in the batch normalization layers. Specifically, we present the low-frequency prompt, which is lightweight with only a few parameters and can be effectively trained in a single iteration. To enhance prompt initialization, we equip VPTTA with a memory bank to benefit the current prompt from previous ones. Additionally, we design a warm-up mechanism, which mixes source and target statistics to construct warm-up statistics, thereby facilitating the training process. Extensive experiments demonstrate the superiority of our VPTTA over other state-of-the-art methods on two medical image segmentation benchmark tasks. The code and weights of pre-trained source models are available at https://github.com/Chen-Ziyang/VPTTA.
Continual Self-supervised Learning: Towards Universal Multi-modal Medical Data Representation Learning
Nov 30, 2023Self-supervised learning is an efficient pre-training method for medical image analysis. However, current research is mostly confined to specific-modality data pre-training, consuming considerable time and resources without achieving universality across different modalities. A straightforward solution is combining all modality data for joint self-supervised pre-training, which poses practical challenges. Firstly, our experiments reveal conflicts in representation learning as the number of modalities increases. Secondly, multi-modal data collected in advance cannot cover all real-world scenarios. In this paper, we reconsider versatile self-supervised learning from the perspective of continual learning and propose MedCoSS, a continuous self-supervised learning approach for multi-modal medical data. Unlike joint self-supervised learning, MedCoSS assigns different modality data to different training stages, forming a multi-stage pre-training process. To balance modal conflicts and prevent catastrophic forgetting, we propose a rehearsal-based continual learning method. We introduce the k-means sampling strategy to retain data from previous modalities and rehearse it when learning new modalities. Instead of executing the pretext task on buffer data, a feature distillation strategy and an intra-modal mixup strategy are applied to these data for knowledge retention. We conduct continuous self-supervised pre-training on a large-scale multi-modal unlabeled dataset, including clinical reports, X-rays, CT scans, MRI scans, and pathological images. Experimental results demonstrate MedCoSS's exceptional generalization ability across nine downstream datasets and its significant scalability in integrating new modality data. Code and pre-trained weight are available at https://github.com/yeerwen/MedCoSS.
Temporal Knowledge Question Answering via Abstract Reasoning Induction
Nov 15, 2023In this paper, we tackle the significant challenge of temporal knowledge reasoning in Large Language Models (LLMs), an area where such models frequently encounter difficulties. These difficulties often result in the generation of misleading or incorrect information, primarily due to their limited capacity to process evolving factual knowledge and complex temporal logic. In response, we propose a novel, constructivism-based approach that advocates for a paradigm shift in LLM learning towards an active, ongoing process of knowledge synthesis and customization. At the heart of our proposal is the Abstract Reasoning Induction ARI framework, which divides temporal reasoning into two distinct phases: Knowledge-agnostic and Knowledge-based. This division aims to reduce instances of hallucinations and improve LLMs' capacity for integrating abstract methodologies derived from historical data. Our approach achieves remarkable improvements, with relative gains of 29.7\% and 9.27\% on two temporal QA datasets, underscoring its efficacy in advancing temporal reasoning in LLMs. The code will be released at https://github.com/czy1999/ARI.
A Survey of Large Language Models Attribution
Nov 07, 2023Open-domain generative systems have gained significant attention in the field of conversational AI (e.g., generative search engines). This paper presents a comprehensive review of the attribution mechanisms employed by these systems, particularly large language models. Though attribution or citation improve the factuality and verifiability, issues like ambiguous knowledge reservoirs, inherent biases, and the drawbacks of excessive attribution can hinder the effectiveness of these systems. The aim of this survey is to provide valuable insights for researchers, aiding in the refinement of attribution methodologies to enhance the reliability and veracity of responses generated by open-domain generative systems. We believe that this field is still in its early stages; hence, we maintain a repository to keep track of ongoing studies at https://github.com/HITsz-TMG/awesome-llm-attributions.
SAMN: A Sample Attention Memory Network Combining SVM and NN in One Architecture
Sep 25, 2023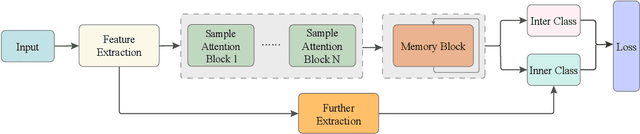
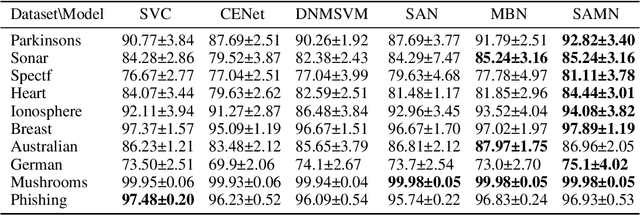
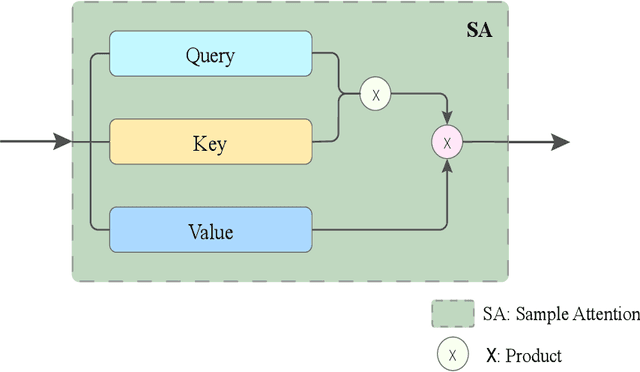
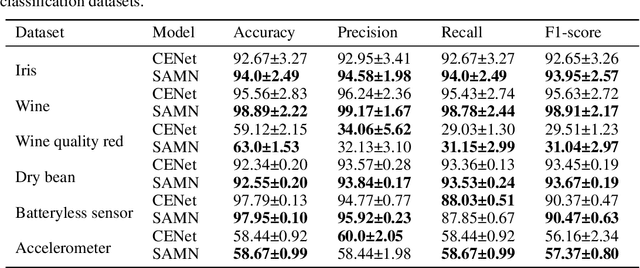
Support vector machine (SVM) and neural networks (NN) have strong complementarity. SVM focuses on the inner operation among samples while NN focuses on the operation among the features within samples. Thus, it is promising and attractive to combine SVM and NN, as it may provide a more powerful function than SVM or NN alone. However, current work on combining them lacks true integration. To address this, we propose a sample attention memory network (SAMN) that effectively combines SVM and NN by incorporating sample attention module, class prototypes, and memory block to NN. SVM can be viewed as a sample attention machine. It allows us to add a sample attention module to NN to implement the main function of SVM. Class prototypes are representatives of all classes, which can be viewed as alternatives to support vectors. The memory block is used for the storage and update of class prototypes. Class prototypes and memory block effectively reduce the computational cost of sample attention and make SAMN suitable for multi-classification tasks. Extensive experiments show that SAMN achieves better classification performance than single SVM or single NN with similar parameter sizes, as well as the previous best model for combining SVM and NN. The sample attention mechanism is a flexible module that can be easily deepened and incorporated into neural networks that require it.
Towards Safer Robot-Assisted Surgery: A Markerless Augmented Reality Framework
Sep 14, 2023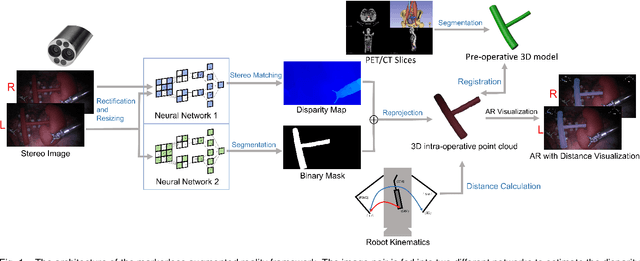

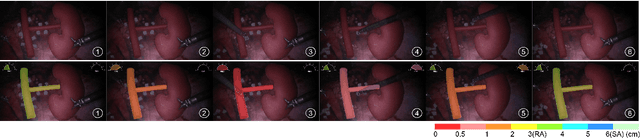

Robot-assisted surgery is rapidly developing in the medical field, and the integration of augmented reality shows the potential of improving the surgeons' operation performance by providing more visual information. In this paper, we proposed a markerless augmented reality framework to enhance safety by avoiding intra-operative bleeding which is a high risk caused by the collision between the surgical instruments and the blood vessel. Advanced stereo reconstruction and segmentation networks are compared to find out the best combination to reconstruct the intra-operative blood vessel in the 3D space for the registration of the pre-operative model, and the minimum distance detection between the instruments and the blood vessel is implemented. A robot-assisted lymphadenectomy is simulated on the da Vinci Research Kit in a dry lab, and ten human subjects performed this operation to explore the usability of the proposed framework. The result shows that the augmented reality framework can help the users to avoid the dangerous collision between the instruments and the blood vessel while not introducing an extra load. It provides a flexible framework that integrates augmented reality into the medical robot platform to enhance safety during the operation.