 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYibing Zhan
Open-Set Video-based Facial Expression Recognition with Human Expression-sensitive Prompting
Apr 26, 2024
In Video-based Facial Expression Recognition (V-FER), models are typically trained on closed-set datasets with a fixed number of known classes. However, these V-FER models cannot deal with unknown classes that are prevalent in real-world scenarios. In this paper, we introduce a challenging Open-set Video-based Facial Expression Recognition (OV-FER) task, aiming at identifying not only known classes but also new, unknown human facial expressions not encountered during training. While existing approaches address open-set recognition by leveraging large-scale vision-language models like CLIP to identify unseen classes, we argue that these methods may not adequately capture the nuanced and subtle human expression patterns required by the OV-FER task. To address this limitation, we propose a novel Human Expression-Sensitive Prompting (HESP) mechanism to significantly enhance CLIP's ability to model video-based facial expression details effectively, thereby presenting a new CLIP-based OV-FER approach. Our proposed HESP comprises three components: 1) a textual prompting module with learnable prompt representations to complement the original CLIP textual prompts and enhance the textual representations of both known and unknown emotions, 2) a visual prompting module that encodes temporal emotional information from video frames using expression-sensitive attention, equipping CLIP with a new visual modeling ability to extract emotion-rich information, 3) a delicately designed open-set multi-task learning scheme that facilitates prompt learning and encourages interactions between the textual and visual prompting modules. Extensive experiments conducted on four OV-FER task settings demonstrate that HESP can significantly boost CLIP's performance (a relative improvement of 17.93% on AUROC and 106.18% on OSCR) and outperform other state-of-the-art open-set video understanding methods by a large margin.
Where to Mask: Structure-Guided Masking for Graph Masked Autoencoders
Apr 24, 2024Graph masked autoencoders (GMAE) have emerged as a significant advancement in self-supervised pre-training for graph-structured data. Previous GMAE models primarily utilize a straightforward random masking strategy for nodes or edges during training. However, this strategy fails to consider the varying significance of different nodes within the graph structure. In this paper, we investigate the potential of leveraging the graph's structural composition as a fundamental and unique prior in the masked pre-training process. To this end, we introduce a novel structure-guided masking strategy (i.e., StructMAE), designed to refine the existing GMAE models. StructMAE involves two steps: 1) Structure-based Scoring: Each node is evaluated and assigned a score reflecting its structural significance. Two distinct types of scoring manners are proposed: predefined and learnable scoring. 2) Structure-guided Masking: With the obtained assessment scores, we develop an easy-to-hard masking strategy that gradually increases the structural awareness of the self-supervised reconstruction task. Specifically, the strategy begins with random masking and progresses to masking structure-informative nodes based on the assessment scores. This design gradually and effectively guides the model in learning graph structural information. Furthermore, extensive experiments consistently demonstrate that our StructMAE method outperforms existing state-of-the-art GMAE models in both unsupervised and transfer learning tasks. Codes are available at https://github.com/LiuChuang0059/StructMAE.
Gradformer: Graph Transformer with Exponential Decay
Apr 24, 2024Graph Transformers (GTs) have demonstrated their advantages across a wide range of tasks. However, the self-attention mechanism in GTs overlooks the graph's inductive biases, particularly biases related to structure, which are crucial for the graph tasks. Although some methods utilize positional encoding and attention bias to model inductive biases, their effectiveness is still suboptimal analytically. Therefore, this paper presents Gradformer, a method innovatively integrating GT with the intrinsic inductive bias by applying an exponential decay mask to the attention matrix. Specifically, the values in the decay mask matrix diminish exponentially, correlating with the decreasing node proximities within the graph structure. This design enables Gradformer to retain its ability to capture information from distant nodes while focusing on the graph's local details. Furthermore, Gradformer introduces a learnable constraint into the decay mask, allowing different attention heads to learn distinct decay masks. Such an design diversifies the attention heads, enabling a more effective assimilation of diverse structural information within the graph. Extensive experiments on various benchmarks demonstrate that Gradformer consistently outperforms the Graph Neural Network and GT baseline models in various graph classification and regression tasks. Additionally, Gradformer has proven to be an effective method for training deep GT models, maintaining or even enhancing accuracy compared to shallow models as the network deepens, in contrast to the significant accuracy drop observed in other GT models.Codes are available at \url{https://github.com/LiuChuang0059/Gradformer}.
Towards Training A Chinese Large Language Model for Anesthesiology
Mar 05, 2024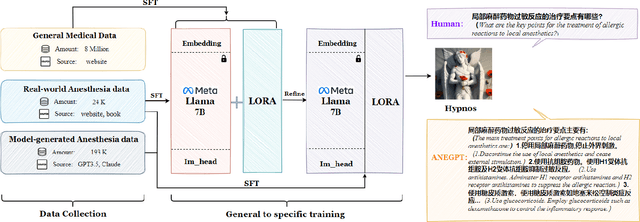
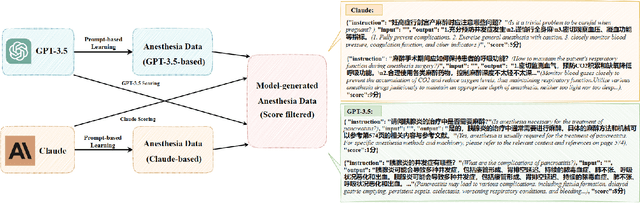
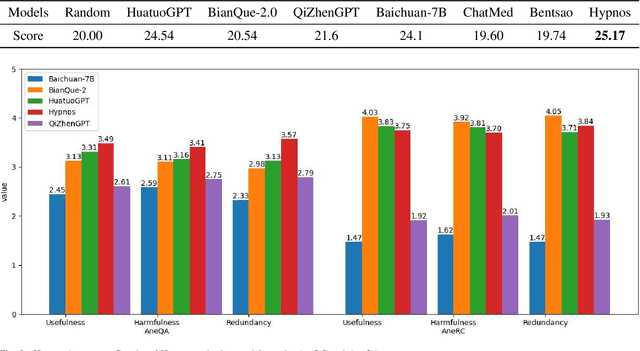
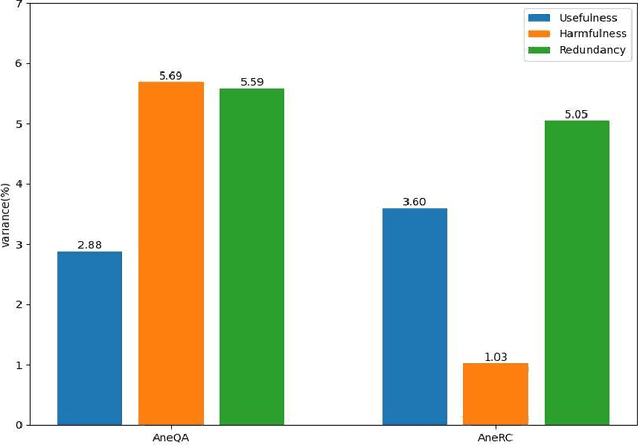
Medical large language models (LLMs) have gained popularity recently due to their significant practical utility. However, most existing research focuses on general medicine, and there is a need for in-depth study of LLMs in specific fields like anesthesiology. To fill the gap, we introduce Hypnos, a Chinese Anesthesia model built upon existing LLMs, e.g., Llama. Hypnos' contributions have three aspects: 1) The data, such as utilizing Self-Instruct, acquired from current LLMs likely includes inaccuracies. Hypnos implements a cross-filtering strategy to improve the data quality. This strategy involves using one LLM to assess the quality of the generated data from another LLM and filtering out the data with low quality. 2) Hypnos employs a general-to-specific training strategy that starts by fine-tuning LLMs using the general medicine data and subsequently improving the fine-tuned LLMs using data specifically from Anesthesiology. The general medical data supplement the medical expertise in Anesthesiology and enhance the effectiveness of Hypnos' generation. 3) We introduce a standardized benchmark for evaluating medical LLM in Anesthesiology. Our benchmark includes both publicly available instances from the Internet and privately obtained cases from the Hospital. Hypnos outperforms other medical LLMs in anesthesiology in metrics, GPT-4, and human evaluation on the benchmark dataset.
Healthcare Copilot: Eliciting the Power of General LLMs for Medical Consultation
Feb 20, 2024The copilot framework, which aims to enhance and tailor large language models (LLMs) for specific complex tasks without requiring fine-tuning, is gaining increasing attention from the community. In this paper, we introduce the construction of a Healthcare Copilot designed for medical consultation. The proposed Healthcare Copilot comprises three main components: 1) the Dialogue component, responsible for effective and safe patient interactions; 2) the Memory component, storing both current conversation data and historical patient information; and 3) the Processing component, summarizing the entire dialogue and generating reports. To evaluate the proposed Healthcare Copilot, we implement an auto-evaluation scheme using ChatGPT for two roles: as a virtual patient engaging in dialogue with the copilot, and as an evaluator to assess the quality of the dialogue. Extensive results demonstrate that the proposed Healthcare Copilot significantly enhances the capabilities of general LLMs for medical consultations in terms of inquiry capability, conversational fluency, response accuracy, and safety. Furthermore, we conduct ablation studies to highlight the contribution of each individual module in the Healthcare Copilot. Code will be made publicly available on GitHub.
Confronting Reward Overoptimization for Diffusion Models: A Perspective of Inductive and Primacy Biases
Feb 13, 2024Bridging the gap between diffusion models and human preferences is crucial for their integration into practical generative workflows. While optimizing downstream reward models has emerged as a promising alignment strategy, concerns arise regarding the risk of excessive optimization with learned reward models, which potentially compromises ground-truth performance. In this work, we confront the reward overoptimization problem in diffusion model alignment through the lenses of both inductive and primacy biases. We first identify the divergence of current methods from the temporal inductive bias inherent in the multi-step denoising process of diffusion models as a potential source of overoptimization. Then, we surprisingly discover that dormant neurons in our critic model act as a regularization against overoptimization, while active neurons reflect primacy bias in this setting. Motivated by these observations, we propose Temporal Diffusion Policy Optimization with critic active neuron Reset (TDPO-R), a policy gradient algorithm that exploits the temporal inductive bias of intermediate timesteps, along with a novel reset strategy that targets active neurons to counteract the primacy bias. Empirical results demonstrate the superior efficacy of our algorithms in mitigating reward overoptimization.
Large Language Models as an Indirect Reasoner: Contrapositive and Contradiction for Automated Reasoning
Feb 06, 2024Recently, increasing attention has been focused drawn on to improve the ability of Large Language Models (LLMs) to perform complex reasoning. However, previous methods, such as Chain-of-Thought and Self-Consistency, mainly follow Direct Reasoning (DR) frameworks, so they will meet difficulty in solving numerous real-world tasks which can hardly be solved via DR. Therefore, to strengthen the reasoning power of LLMs, this paper proposes a novel Indirect Reasoning (IR) method that employs the logic of contrapositives and contradictions to tackle IR tasks such as factual reasoning and mathematic proof. Specifically, our methodology comprises two steps. Firstly, we leverage the logical equivalence of contrapositive to augment the data and rules to enhance the comprehensibility of LLMs. Secondly, we design a set of prompt templates to trigger LLMs to conduct IR based on proof by contradiction that is logically equivalent to the original DR process. Our IR method is simple yet effective and can be straightforwardly integrated with existing DR methods to further boost the reasoning abilities of LLMs. The experimental results on popular LLMs, such as GPT-3.5-turbo and Gemini-pro, show that our IR method enhances the overall accuracy of factual reasoning by 27.33% and mathematical proof by 31.43%, when compared with traditional DR methods. Moreover, the methods combining IR and DR significantly outperform the methods solely using IR or DR, further demonstrating the effectiveness of our strategy.
TD^2-Net: Toward Denoising and Debiasing for Dynamic Scene Graph Generation
Jan 23, 2024Dynamic scene graph generation (SGG) focuses on detecting objects in a video and determining their pairwise relationships. Existing dynamic SGG methods usually suffer from several issues, including 1) Contextual noise, as some frames might contain occluded and blurred objects. 2) Label bias, primarily due to the high imbalance between a few positive relationship samples and numerous negative ones. Additionally, the distribution of relationships exhibits a long-tailed pattern. To address the above problems, in this paper, we introduce a network named TD$^2$-Net that aims at denoising and debiasing for dynamic SGG. Specifically, we first propose a denoising spatio-temporal transformer module that enhances object representation with robust contextual information. This is achieved by designing a differentiable Top-K object selector that utilizes the gumbel-softmax sampling strategy to select the relevant neighborhood for each object. Second, we introduce an asymmetrical reweighting loss to relieve the issue of label bias. This loss function integrates asymmetry focusing factors and the volume of samples to adjust the weights assigned to individual samples. Systematic experimental results demonstrate the superiority of our proposed TD$^2$-Net over existing state-of-the-art approaches on Action Genome databases. In more detail, TD$^2$-Net outperforms the second-best competitors by 12.7 \% on mean-Recall@10 for predicate classification.
Exploring Sparsity in Graph Transformers
Dec 09, 2023Graph Transformers (GTs) have achieved impressive results on various graph-related tasks. However, the huge computational cost of GTs hinders their deployment and application, especially in resource-constrained environments. Therefore, in this paper, we explore the feasibility of sparsifying GTs, a significant yet under-explored topic. We first discuss the redundancy of GTs based on the characteristics of existing GT models, and then propose a comprehensive \textbf{G}raph \textbf{T}ransformer \textbf{SP}arsification (GTSP) framework that helps to reduce the computational complexity of GTs from four dimensions: the input graph data, attention heads, model layers, and model weights. Specifically, GTSP designs differentiable masks for each individual compressible component, enabling effective end-to-end pruning. We examine our GTSP through extensive experiments on prominent GTs, including GraphTrans, Graphormer, and GraphGPS. The experimental results substantiate that GTSP effectively cuts computational costs, accompanied by only marginal decreases in accuracy or, in some cases, even improvements. For instance, GTSP yields a reduction of 30\% in Floating Point Operations while contributing to a 1.8\% increase in Area Under the Curve accuracy on OGBG-HIV dataset. Furthermore, we provide several insights on the characteristics of attention heads and the behavior of attention mechanisms, all of which have immense potential to inspire future research endeavors in this domain.
SpliceMix: A Cross-scale and Semantic Blending Augmentation Strategy for Multi-label Image Classification
Nov 26, 2023Recently, Mix-style data augmentation methods (e.g., Mixup and CutMix) have shown promising performance in various visual tasks. However, these methods are primarily designed for single-label images, ignoring the considerable discrepancies between single- and multi-label images, i.e., a multi-label image involves multiple co-occurred categories and fickle object scales. On the other hand, previous multi-label image classification (MLIC) methods tend to design elaborate models, bringing expensive computation. In this paper, we introduce a simple but effective augmentation strategy for multi-label image classification, namely SpliceMix. The "splice" in our method is two-fold: 1) Each mixed image is a splice of several downsampled images in the form of a grid, where the semantics of images attending to mixing are blended without object deficiencies for alleviating co-occurred bias; 2) We splice mixed images and the original mini-batch to form a new SpliceMixed mini-batch, which allows an image with different scales to contribute to training together. Furthermore, such splice in our SpliceMixed mini-batch enables interactions between mixed images and original regular images. We also offer a simple and non-parametric extension based on consistency learning (SpliceMix-CL) to show the flexible extensibility of our SpliceMix. Extensive experiments on various tasks demonstrate that only using SpliceMix with a baseline model (e.g., ResNet) achieves better performance than state-of-the-art methods. Moreover, the generalizability of our SpliceMix is further validated by the improvements in current MLIC methods when married with our SpliceMix. The code is available at https://github.com/zuiran/SpliceMix.