 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaize Dong
iDAT: inverse Distillation Adapter-Tuning
Mar 23, 2024
Adapter-Tuning (AT) method involves freezing a pre-trained model and introducing trainable adapter modules to acquire downstream knowledge, thereby calibrating the model for better adaptation to downstream tasks. This paper proposes a distillation framework for the AT method instead of crafting a carefully designed adapter module, which aims to improve fine-tuning performance. For the first time, we explore the possibility of combining the AT method with knowledge distillation. Via statistical analysis, we observe significant differences in the knowledge acquisition between adapter modules of different models. Leveraging these differences, we propose a simple yet effective framework called inverse Distillation Adapter-Tuning (iDAT). Specifically, we designate the smaller model as the teacher and the larger model as the student. The two are jointly trained, and online knowledge distillation is applied to inject knowledge of different perspective to student model, and significantly enhance the fine-tuning performance on downstream tasks. Extensive experiments on the VTAB-1K benchmark with 19 image classification tasks demonstrate the effectiveness of iDAT. The results show that using existing AT method within our iDAT framework can further yield a 2.66% performance gain, with only an additional 0.07M trainable parameters. Our approach compares favorably with state-of-the-arts without bells and whistles. Our code is available at https://github.com/JCruan519/iDAT.
A Graph is Worth $K$ Words: Euclideanizing Graph using Pure Transformer
Feb 04, 2024Can we model non-Euclidean graphs as pure language or even Euclidean vectors while retaining their inherent information? The non-Euclidean property have posed a long term challenge in graph modeling. Despite recent GNN and Graphformer efforts encoding graphs as Euclidean vectors, recovering original graph from the vectors remains a challenge. We introduce GraphsGPT, featuring a Graph2Seq encoder that transforms non-Euclidean graphs into learnable graph words in a Euclidean space, along with a GraphGPT decoder that reconstructs the original graph from graph words to ensure information equivalence. We pretrain GraphsGPT on 100M molecules and yield some interesting findings: (1) Pretrained Graph2Seq excels in graph representation learning, achieving state-of-the-art results on 8/9 graph classification and regression tasks. (2) Pretrained GraphGPT serves as a strong graph generator, demonstrated by its ability to perform both unconditional and conditional graph generation. (3) Graph2Seq+GraphGPT enables effective graph mixup in the Euclidean space, overcoming previously known non-Euclidean challenge. (4) Our proposed novel edge-centric GPT pretraining task is effective in graph fields, underscoring its success in both representation and generation.
Cherry Hypothesis: Identifying the Cherry on the Cake for Dynamic Networks
Nov 10, 2022

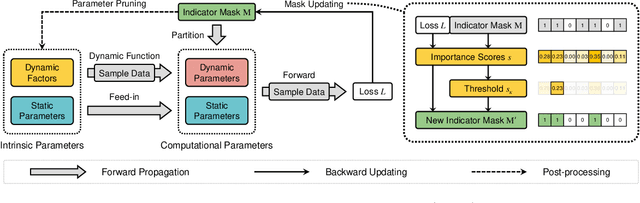
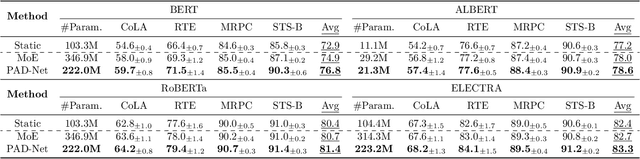
Dynamic networks have been extensively explored as they can considerably improve the model's representation power with acceptable computational cost. The common practice in implementing dynamic networks is to convert given static layers into fully dynamic ones where all parameters are dynamic and vary with the input. Recent studies empirically show the trend that the more dynamic layers contribute to ever-increasing performance. However, such a fully dynamic setting 1) may cause redundant parameters and high deployment costs, limiting the applicability of dynamic networks to a broader range of tasks and models, and more importantly, 2) contradicts the previous discovery in the human brain that \textit{when human brains process an attention-demanding task, only partial neurons in the task-specific areas are activated by the input, while the rest neurons leave in a baseline state.} Critically, there is no effort to understand and resolve the above contradictory finding, leaving the primal question -- to make the computational parameters fully dynamic or not? -- unanswered. The main contributions of our work are challenging the basic commonsense in dynamic networks, and, proposing and validating the \textsc{cherry hypothesis} -- \textit{A fully dynamic network contains a subset of dynamic parameters that when transforming other dynamic parameters into static ones, can maintain or even exceed the performance of the original network.} Technically, we propose a brain-inspired partially dynamic network, namely PAD-Net, to transform the redundant dynamic parameters into static ones. Also, we further design Iterative Mode Partition to partition the dynamic- and static-subnet, which alleviates the redundancy in traditional fully dynamic networks. Our hypothesis and method are comprehensively supported by large-scale experiments with typical advanced dynamic methods.
SparseAdapter: An Easy Approach for Improving the Parameter-Efficiency of Adapters
Oct 11, 2022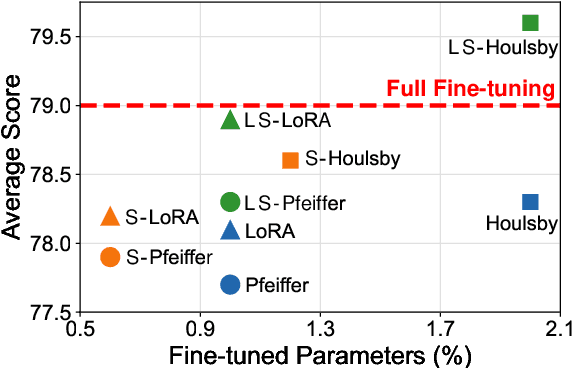
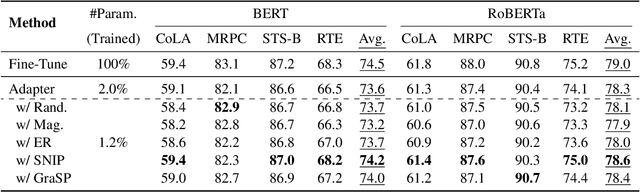
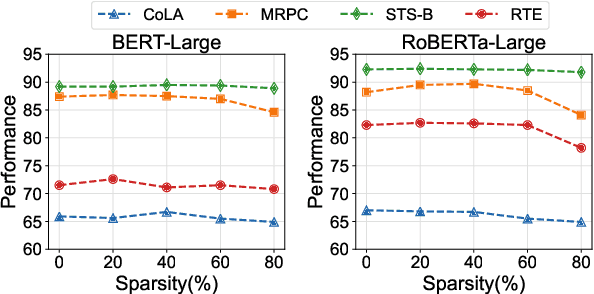
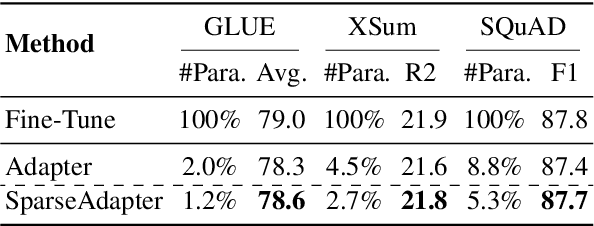
Adapter Tuning, which freezes the pretrained language models (PLMs) and only fine-tunes a few extra modules, becomes an appealing efficient alternative to the full model fine-tuning. Although computationally efficient, the recent Adapters often increase parameters (e.g. bottleneck dimension) for matching the performance of full model fine-tuning, which we argue goes against their original intention. In this work, we re-examine the parameter-efficiency of Adapters through the lens of network pruning (we name such plug-in concept as \texttt{SparseAdapter}) and find that SparseAdapter can achieve comparable or better performance than standard Adapters when the sparse ratio reaches up to 80\%. Based on our findings, we introduce an easy but effective setting ``\textit{Large-Sparse}'' to improve the model capacity of Adapters under the same parameter budget. Experiments on five competitive Adapters upon three advanced PLMs show that with proper sparse method (e.g. SNIP) and ratio (e.g. 40\%) SparseAdapter can consistently outperform their corresponding counterpart. Encouragingly, with the \textit{Large-Sparse} setting, we can obtain further appealing gains, even outperforming the full fine-tuning by a large margin. Our code will be released at: \url{https://github.com/Shwai-He/SparseAdapter}.