 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaixuan Chen
Advantage-Aware Policy Optimization for Offline Reinforcement Learning
Mar 12, 2024
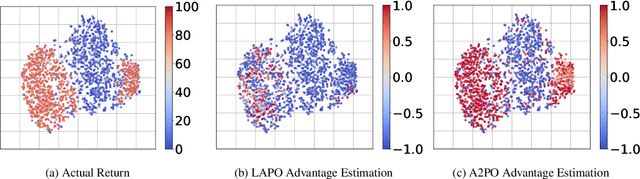
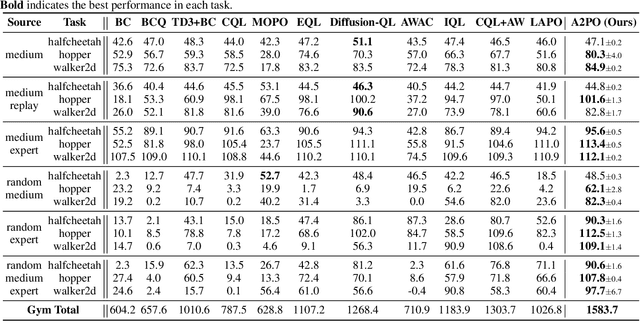
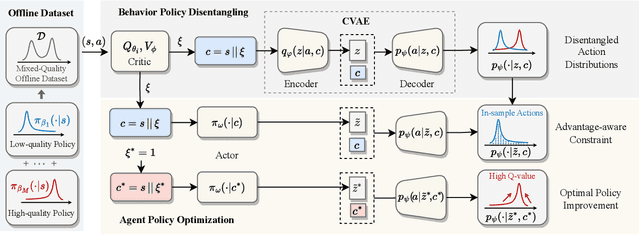
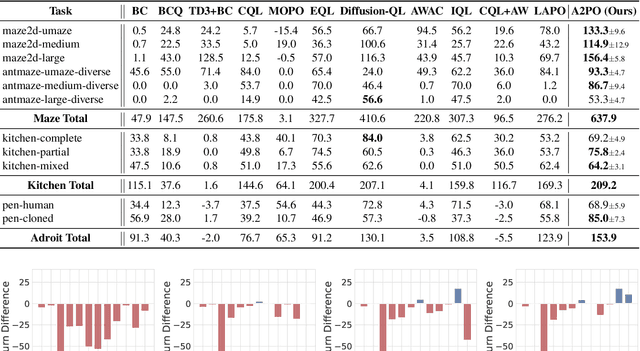
Offline Reinforcement Learning (RL) endeavors to leverage offline datasets to craft effective agent policy without online interaction, which imposes proper conservative constraints with the support of behavior policies to tackle the Out-Of-Distribution (OOD) problem. However, existing works often suffer from the constraint conflict issue when offline datasets are collected from multiple behavior policies, i.e., different behavior policies may exhibit inconsistent actions with distinct returns across the state space. To remedy this issue, recent Advantage-Weighted (AW) methods prioritize samples with high advantage values for agent training while inevitably leading to overfitting on these samples. In this paper, we introduce a novel Advantage-Aware Policy Optimization (A2PO) method to explicitly construct advantage-aware policy constraints for offline learning under mixed-quality datasets. Specifically, A2PO employs a Conditional Variational Auto-Encoder (CVAE) to disentangle the action distributions of intertwined behavior policies by modeling the advantage values of all training data as conditional variables. Then the agent can follow such disentangled action distribution constraints to optimize the advantage-aware policy towards high advantage values. Extensive experiments conducted on both the single-quality and mixed-quality datasets of the D4RL benchmark demonstrate that A2PO yields results superior to state-of-the-art counterparts. Our code will be made publicly available.
Powerformer: A Section-adaptive Transformer for Power Flow Adjustment
Jan 10, 2024In this paper, we present a novel transformer architecture tailored for learning robust power system state representations, which strives to optimize power dispatch for the power flow adjustment across different transmission sections. Specifically, our proposed approach, named Powerformer, develops a dedicated section-adaptive attention mechanism, separating itself from the self-attention used in conventional transformers. This mechanism effectively integrates power system states with transmission section information, which facilitates the development of robust state representations. Furthermore, by considering the graph topology of power system and the electrical attributes of bus nodes, we introduce two customized strategies to further enhance the expressiveness: graph neural network propagation and multi-factor attention mechanism. Extensive evaluations are conducted on three power system scenarios, including the IEEE 118-bus system, a realistic 300-bus system in China, and a large-scale European system with 9241 buses, where Powerformer demonstrates its superior performance over several baseline methods.
Agent-Aware Training for Agent-Agnostic Action Advising in Deep Reinforcement Learning
Nov 28, 2023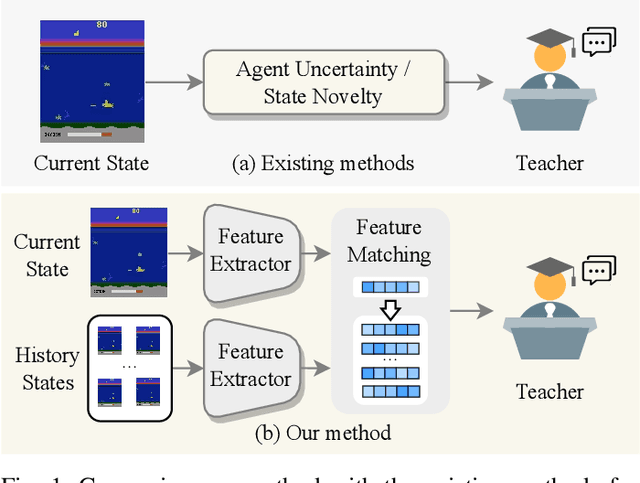
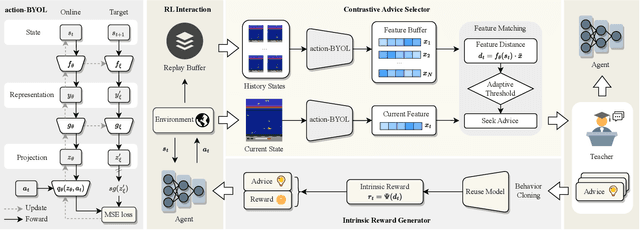
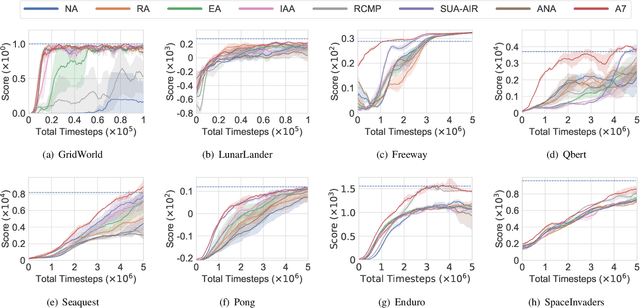
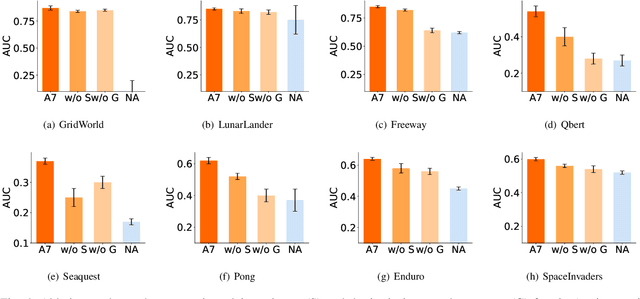
Action advising endeavors to leverage supplementary guidance from expert teachers to alleviate the issue of sampling inefficiency in Deep Reinforcement Learning (DRL). Previous agent-specific action advising methods are hindered by imperfections in the agent itself, while agent-agnostic approaches exhibit limited adaptability to the learning agent. In this study, we propose a novel framework called Agent-Aware trAining yet Agent-Agnostic Action Advising (A7) to strike a balance between the two. The underlying concept of A7 revolves around utilizing the similarity of state features as an indicator for soliciting advice. However, unlike prior methodologies, the measurement of state feature similarity is performed by neither the error-prone learning agent nor the agent-agnostic advisor. Instead, we employ a proxy model to extract state features that are both discriminative (adaptive to the agent) and generally applicable (robust to agent noise). Furthermore, we utilize behavior cloning to train a model for reusing advice and introduce an intrinsic reward for the advised samples to incentivize the utilization of expert guidance. Experiments are conducted on the GridWorld, LunarLander, and six prominent scenarios from Atari games. The results demonstrate that A7 significantly accelerates the learning process and surpasses existing methods (both agent-specific and agent-agnostic) by a substantial margin. Our code will be made publicly available.
Navigating Out-of-Distribution Electricity Load Forecasting during COVID-19: A Continual Learning Approach Leveraging Human Mobility
Sep 12, 2023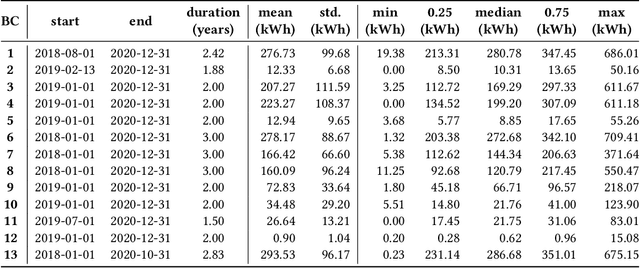
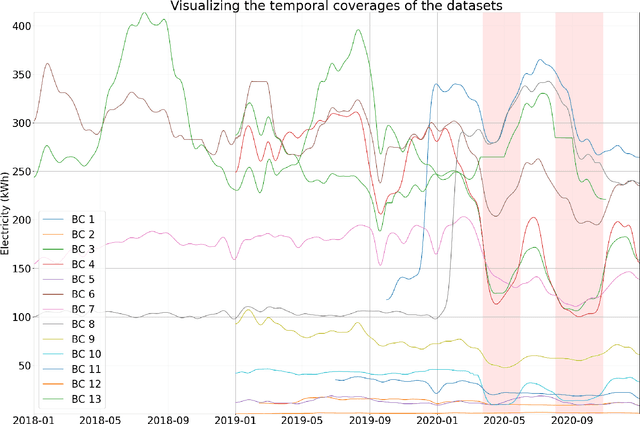
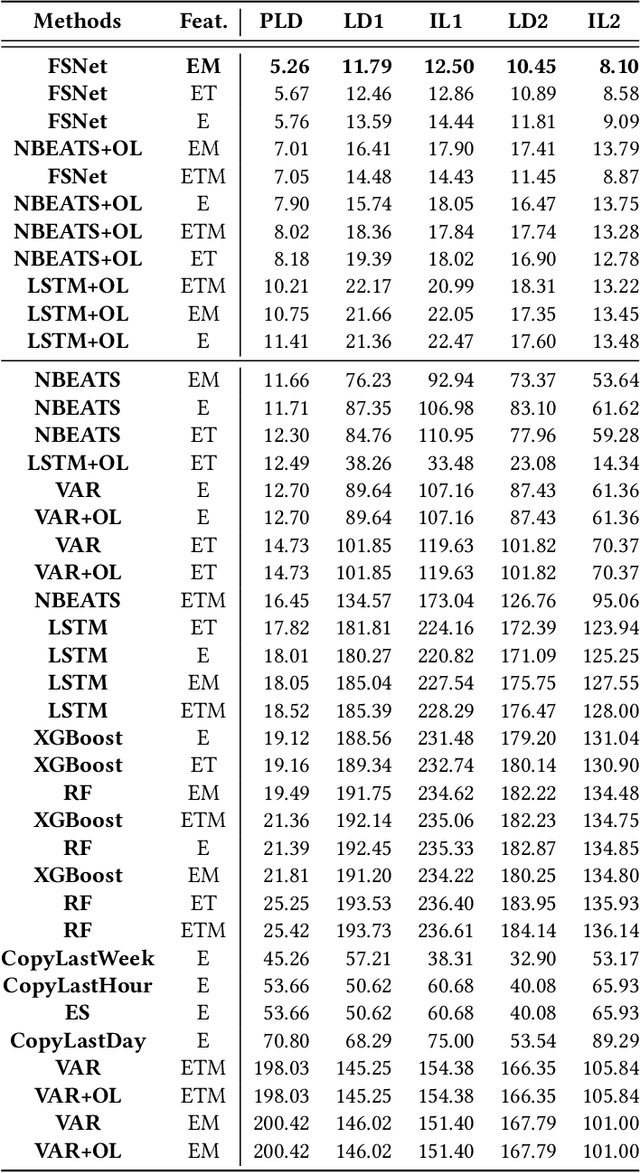
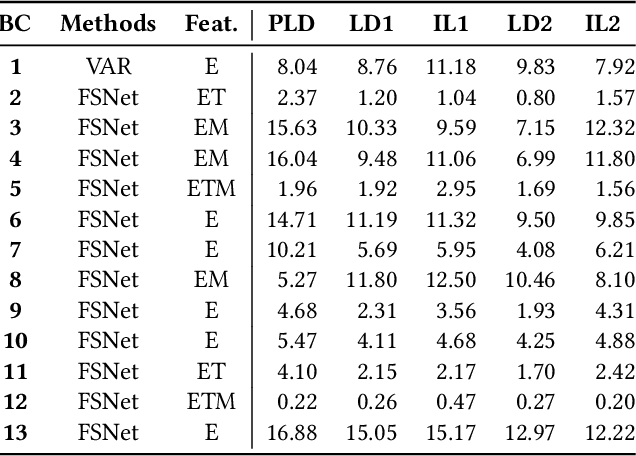
In traditional deep learning algorithms, one of the key assumptions is that the data distribution remains constant during both training and deployment. However, this assumption becomes problematic when faced with Out-of-Distribution periods, such as the COVID-19 lockdowns, where the data distribution significantly deviates from what the model has seen during training. This paper employs a two-fold strategy: utilizing continual learning techniques to update models with new data and harnessing human mobility data collected from privacy-preserving pedestrian counters located outside buildings. In contrast to online learning, which suffers from 'catastrophic forgetting' as newly acquired knowledge often erases prior information, continual learning offers a holistic approach by preserving past insights while integrating new data. This research applies FSNet, a powerful continual learning algorithm, to real-world data from 13 building complexes in Melbourne, Australia, a city which had the second longest total lockdown duration globally during the pandemic. Results underscore the crucial role of continual learning in accurate energy forecasting, particularly during Out-of-Distribution periods. Secondary data such as mobility and temperature provided ancillary support to the primary forecasting model. More importantly, while traditional methods struggled to adapt during lockdowns, models featuring at least online learning demonstrated resilience, with lockdown periods posing fewer challenges once armed with adaptive learning techniques. This study contributes valuable methodologies and insights to the ongoing effort to improve energy load forecasting during future Out-of-Distribution periods.
Adversarial Erasing with Pruned Elements: Towards Better Graph Lottery Ticket
Aug 10, 2023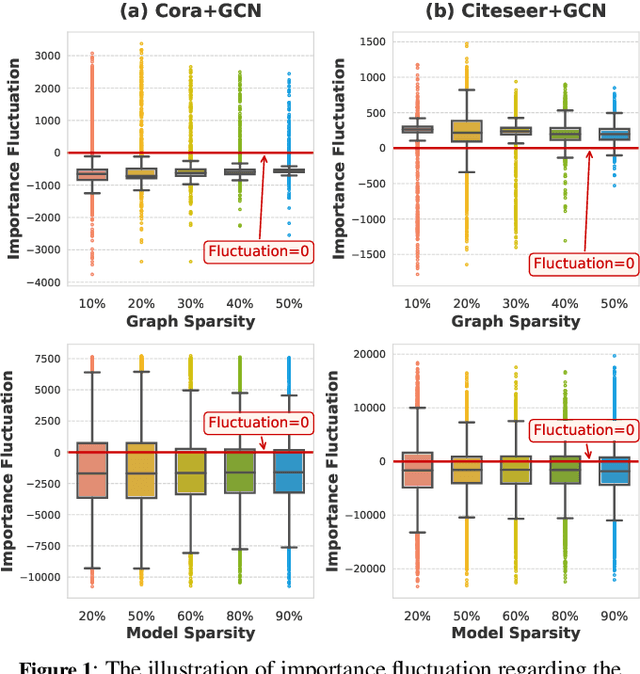
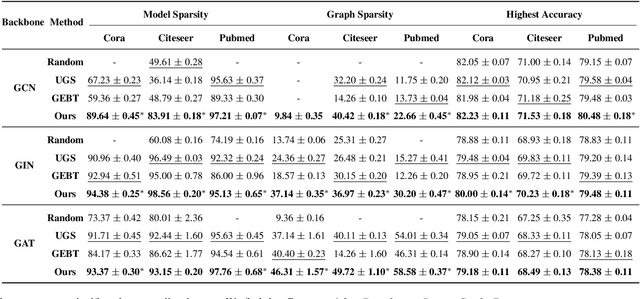
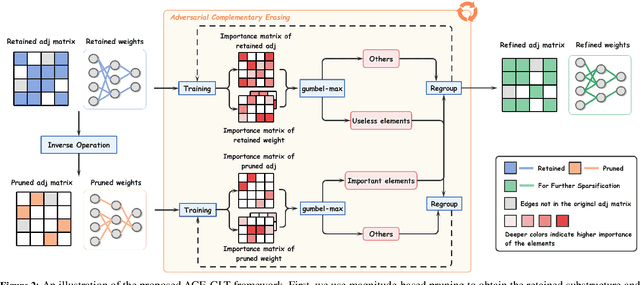
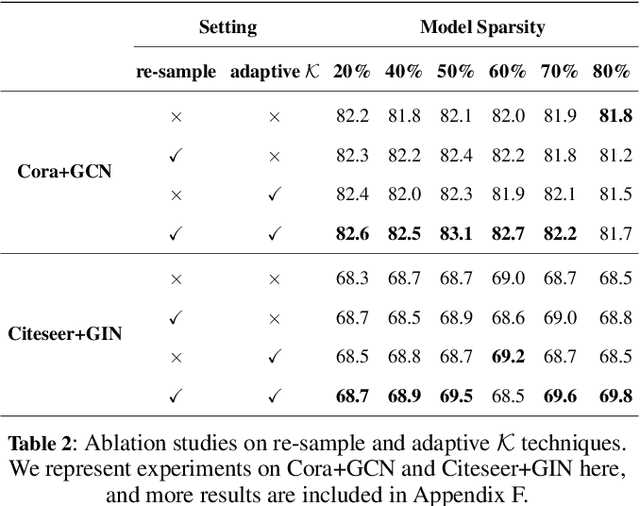
Graph Lottery Ticket (GLT), a combination of core subgraph and sparse subnetwork, has been proposed to mitigate the computational cost of deep Graph Neural Networks (GNNs) on large input graphs while preserving original performance. However, the winning GLTs in exisiting studies are obtained by applying iterative magnitude-based pruning (IMP) without re-evaluating and re-considering the pruned information, which disregards the dynamic changes in the significance of edges/weights during graph/model structure pruning, and thus limits the appeal of the winning tickets. In this paper, we formulate a conjecture, i.e., existing overlooked valuable information in the pruned graph connections and model parameters which can be re-grouped into GLT to enhance the final performance. Specifically, we propose an adversarial complementary erasing (ACE) framework to explore the valuable information from the pruned components, thereby developing a more powerful GLT, referred to as the ACE-GLT. The main idea is to mine valuable information from pruned edges/weights after each round of IMP, and employ the ACE technique to refine the GLT processing. Finally, experimental results demonstrate that our ACE-GLT outperforms existing methods for searching GLT in diverse tasks. Our code will be made publicly available.
Spatiotemporal-Augmented Graph Neural Networks for Human Mobility Simulation
Jun 19, 2023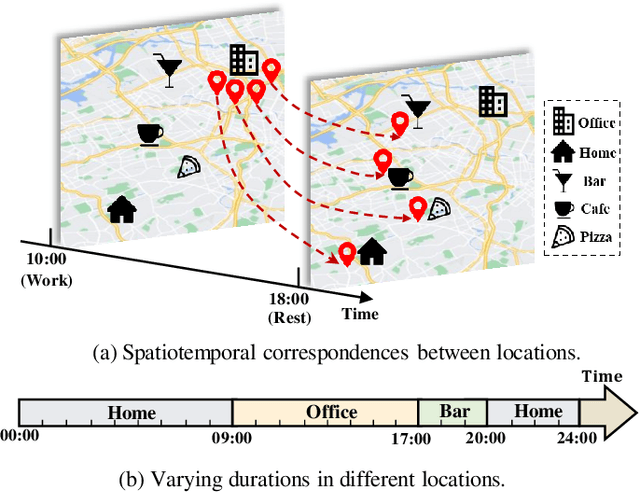


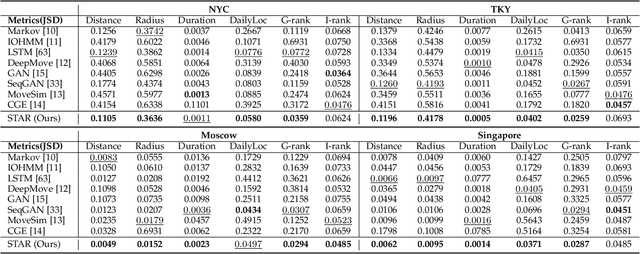
Human mobility patterns have shown significant applications in policy-decision scenarios and economic behavior researches. The human mobility simulation task aims to generate human mobility trajectories given a small set of trajectory data, which have aroused much concern due to the scarcity and sparsity of human mobility data. Existing methods mostly rely on the static relationships of locations, while largely neglect the dynamic spatiotemporal effects of locations. On the one hand, spatiotemporal correspondences of visit distributions reveal the spatial proximity and the functionality similarity of locations. On the other hand, the varying durations in different locations hinder the iterative generation process of the mobility trajectory. Therefore, we propose a novel framework to model the dynamic spatiotemporal effects of locations, namely SpatioTemporal-Augmented gRaph neural networks (STAR). The STAR framework designs various spatiotemporal graphs to capture the spatiotemporal correspondences and builds a novel dwell branch to simulate the varying durations in locations, which is finally optimized in an adversarial manner. The comprehensive experiments over four real datasets for the human mobility simulation have verified the superiority of STAR to state-of-the-art methods. Our code will be made publicly available.
Decentralized SGD and Average-direction SAM are Asymptotically Equivalent
Jun 12, 2023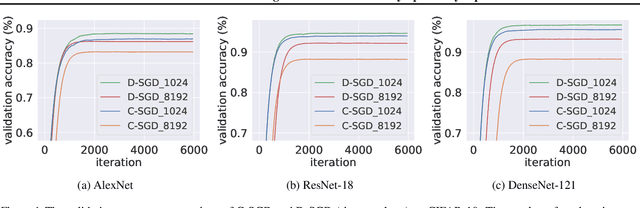
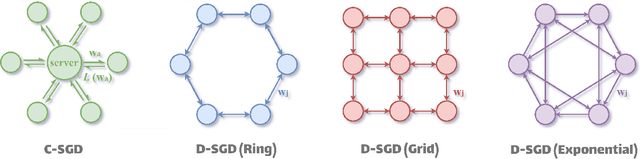
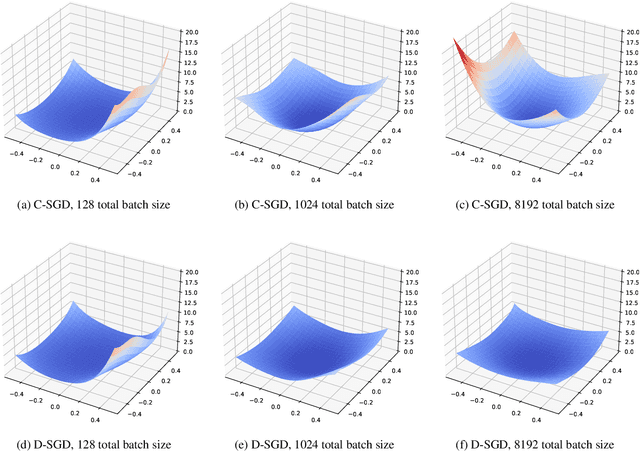
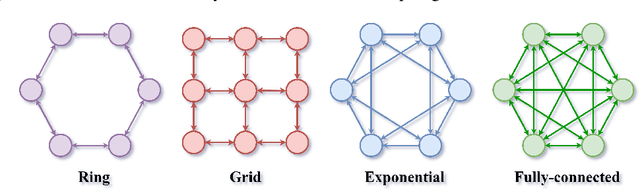
Decentralized stochastic gradient descent (D-SGD) allows collaborative learning on massive devices simultaneously without the control of a central server. However, existing theories claim that decentralization invariably undermines generalization. In this paper, we challenge the conventional belief and present a completely new perspective for understanding decentralized learning. We prove that D-SGD implicitly minimizes the loss function of an average-direction Sharpness-aware minimization (SAM) algorithm under general non-convex non-$\beta$-smooth settings. This surprising asymptotic equivalence reveals an intrinsic regularization-optimization trade-off and three advantages of decentralization: (1) there exists a free uncertainty evaluation mechanism in D-SGD to improve posterior estimation; (2) D-SGD exhibits a gradient smoothing effect; and (3) the sharpness regularization effect of D-SGD does not decrease as total batch size increases, which justifies the potential generalization benefit of D-SGD over centralized SGD (C-SGD) in large-batch scenarios.
Improving Expressivity of GNNs with Subgraph-specific Factor Embedded Normalization
Jun 11, 2023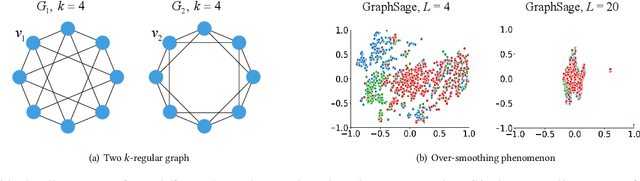

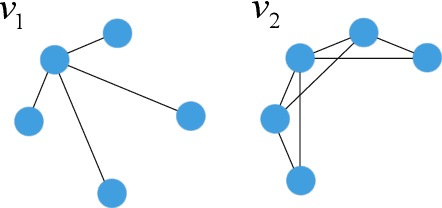
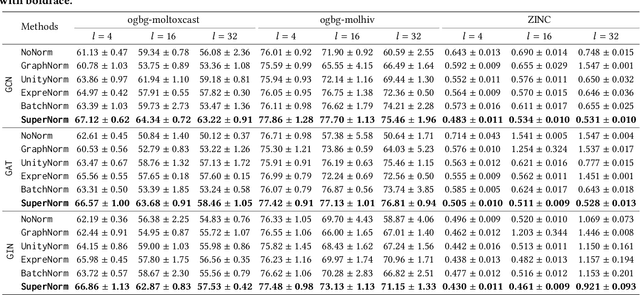
Graph Neural Networks (GNNs) have emerged as a powerful category of learning architecture for handling graph-structured data. However, existing GNNs typically ignore crucial structural characteristics in node-induced subgraphs, which thus limits their expressiveness for various downstream tasks. In this paper, we strive to strengthen the representative capabilities of GNNs by devising a dedicated plug-and-play normalization scheme, termed as SUbgraph-sPEcific FactoR Embedded Normalization (SuperNorm), that explicitly considers the intra-connection information within each node-induced subgraph. To this end, we embed the subgraph-specific factor at the beginning and the end of the standard BatchNorm, as well as incorporate graph instance-specific statistics for improved distinguishable capabilities. In the meantime, we provide theoretical analysis to support that, with the elaborated SuperNorm, an arbitrary GNN is at least as powerful as the 1-WL test in distinguishing non-isomorphism graphs. Furthermore, the proposed SuperNorm scheme is also demonstrated to alleviate the over-smoothing phenomenon. Experimental results related to predictions of graph, node, and link properties on the eight popular datasets demonstrate the effectiveness of the proposed method. The code is available at https://github.com/chenchkx/SuperNorm.
Continually learning out-of-distribution spatiotemporal data for robust energy forecasting
Jun 10, 2023
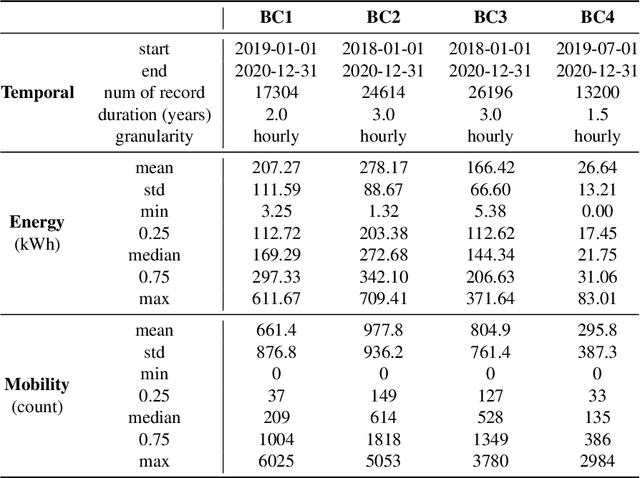
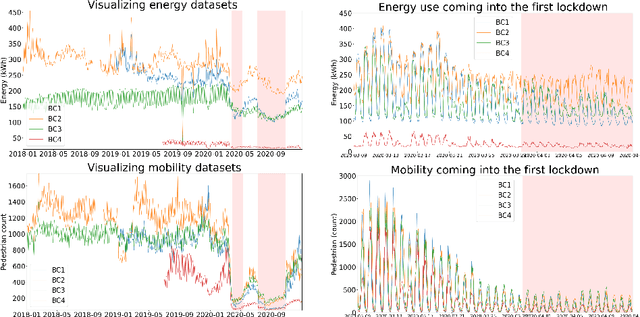
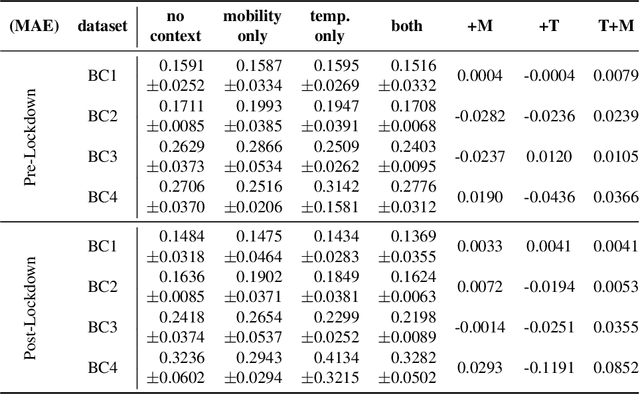
Forecasting building energy usage is essential for promoting sustainability and reducing waste, as it enables building managers to optimize energy consumption and reduce costs. This importance is magnified during anomalous periods, such as the COVID-19 pandemic, which have disrupted occupancy patterns and made accurate forecasting more challenging. Forecasting energy usage during anomalous periods is difficult due to changes in occupancy patterns and energy usage behavior. One of the primary reasons for this is the shift in distribution of occupancy patterns, with many people working or learning from home. This has created a need for new forecasting methods that can adapt to changing occupancy patterns. Online learning has emerged as a promising solution to this challenge, as it enables building managers to adapt to changes in occupancy patterns and adjust energy usage accordingly. With online learning, models can be updated incrementally with each new data point, allowing them to learn and adapt in real-time. Another solution is to use human mobility data as a proxy for occupancy, leveraging the prevalence of mobile devices to track movement patterns and infer occupancy levels. Human mobility data can be useful in this context as it provides a way to monitor occupancy patterns without relying on traditional sensors or manual data collection methods. We have conducted extensive experiments using data from six buildings to test the efficacy of these approaches. However, deploying these methods in the real world presents several challenges.
Message-passing selection: Towards interpretable GNNs for graph classification
Jun 08, 2023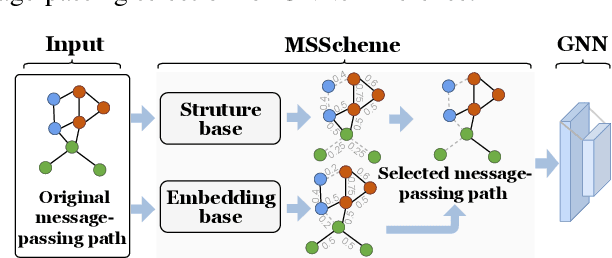

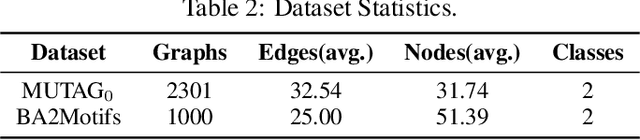

In this paper, we strive to develop an interpretable GNNs' inference paradigm, termed MSInterpreter, which can serve as a plug-and-play scheme readily applicable to various GNNs' baselines. Unlike the most existing explanation methods, MSInterpreter provides a Message-passing Selection scheme(MSScheme) to select the critical paths for GNNs' message aggregations, which aims at reaching the self-explaination instead of post-hoc explanations. In detail, the elaborate MSScheme is designed to calculate weight factors of message aggregation paths by considering the vanilla structure and node embedding components, where the structure base aims at weight factors among node-induced substructures; on the other hand, the node embedding base focuses on weight factors via node embeddings obtained by one-layer GNN.Finally, we demonstrate the effectiveness of our approach on graph classification benchmarks.