 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingwen Ye
Distilled Datamodel with Reverse Gradient Matching
Apr 22, 2024
The proliferation of large-scale AI models trained on extensive datasets has revolutionized machine learning. With these models taking on increasingly central roles in various applications, the need to understand their behavior and enhance interpretability has become paramount. To investigate the impact of changes in training data on a pre-trained model, a common approach is leave-one-out retraining. This entails systematically altering the training dataset by removing specific samples to observe resulting changes within the model. However, retraining the model for each altered dataset presents a significant computational challenge, given the need to perform this operation for every dataset variation. In this paper, we introduce an efficient framework for assessing data impact, comprising offline training and online evaluation stages. During the offline training phase, we approximate the influence of training data on the target model through a distilled synset, formulated as a reversed gradient matching problem. For online evaluation, we expedite the leave-one-out process using the synset, which is then utilized to compute the attribution matrix based on the evaluation objective. Experimental evaluations, including training data attribution and assessments of data quality, demonstrate that our proposed method achieves comparable model behavior evaluation while significantly speeding up the process compared to the direct retraining method.
Ungeneralizable Examples
Apr 22, 2024The training of contemporary deep learning models heavily relies on publicly available data, posing a risk of unauthorized access to online data and raising concerns about data privacy. Current approaches to creating unlearnable data involve incorporating small, specially designed noises, but these methods strictly limit data usability, overlooking its potential usage in authorized scenarios. In this paper, we extend the concept of unlearnable data to conditional data learnability and introduce \textbf{U}n\textbf{G}eneralizable \textbf{E}xamples (UGEs). UGEs exhibit learnability for authorized users while maintaining unlearnability for potential hackers. The protector defines the authorized network and optimizes UGEs to match the gradients of the original data and its ungeneralizable version, ensuring learnability. To prevent unauthorized learning, UGEs are trained by maximizing a designated distance loss in a common feature space. Additionally, to further safeguard the authorized side from potential attacks, we introduce additional undistillation optimization. Experimental results on multiple datasets and various networks demonstrate that the proposed UGEs framework preserves data usability while reducing training performance on hacker networks, even under different types of attacks.
Mutual-modality Adversarial Attack with Semantic Perturbation
Dec 20, 2023Adversarial attacks constitute a notable threat to machine learning systems, given their potential to induce erroneous predictions and classifications. However, within real-world contexts, the essential specifics of the deployed model are frequently treated as a black box, consequently mitigating the vulnerability to such attacks. Thus, enhancing the transferability of the adversarial samples has become a crucial area of research, which heavily relies on selecting appropriate surrogate models. To address this challenge, we propose a novel approach that generates adversarial attacks in a mutual-modality optimization scheme. Our approach is accomplished by leveraging the pre-trained CLIP model. Firstly, we conduct a visual attack on the clean image that causes semantic perturbations on the aligned embedding space with the other textual modality. Then, we apply the corresponding defense on the textual modality by updating the prompts, which forces the re-matching on the perturbed embedding space. Finally, to enhance the attack transferability, we utilize the iterative training strategy on the visual attack and the textual defense, where the two processes optimize from each other. We evaluate our approach on several benchmark datasets and demonstrate that our mutual-modal attack strategy can effectively produce high-transferable attacks, which are stable regardless of the target networks. Our approach outperforms state-of-the-art attack methods and can be readily deployed as a plug-and-play solution.
Improving Expressivity of GNNs with Subgraph-specific Factor Embedded Normalization
Jun 11, 2023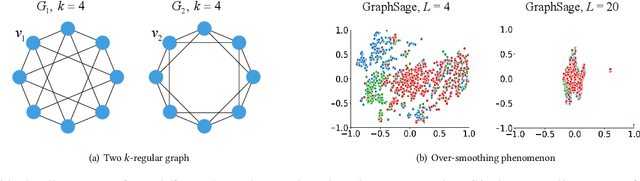

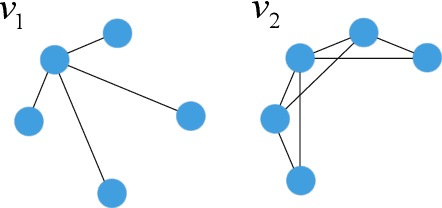
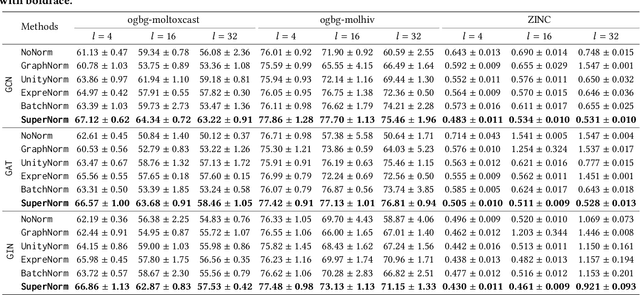
Graph Neural Networks (GNNs) have emerged as a powerful category of learning architecture for handling graph-structured data. However, existing GNNs typically ignore crucial structural characteristics in node-induced subgraphs, which thus limits their expressiveness for various downstream tasks. In this paper, we strive to strengthen the representative capabilities of GNNs by devising a dedicated plug-and-play normalization scheme, termed as SUbgraph-sPEcific FactoR Embedded Normalization (SuperNorm), that explicitly considers the intra-connection information within each node-induced subgraph. To this end, we embed the subgraph-specific factor at the beginning and the end of the standard BatchNorm, as well as incorporate graph instance-specific statistics for improved distinguishable capabilities. In the meantime, we provide theoretical analysis to support that, with the elaborated SuperNorm, an arbitrary GNN is at least as powerful as the 1-WL test in distinguishing non-isomorphism graphs. Furthermore, the proposed SuperNorm scheme is also demonstrated to alleviate the over-smoothing phenomenon. Experimental results related to predictions of graph, node, and link properties on the eight popular datasets demonstrate the effectiveness of the proposed method. The code is available at https://github.com/chenchkx/SuperNorm.
Any-to-Any Style Transfer: Making Picasso and Da Vinci Collaborate
Apr 20, 2023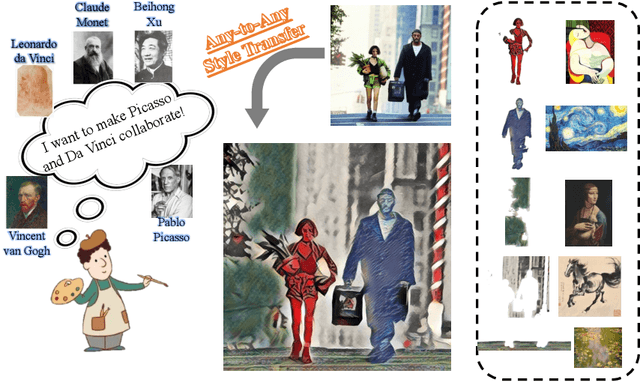


Style transfer aims to render the style of a given image for style reference to another given image for content reference, and has been widely adopted in artistic generation and image editing. Existing approaches either apply the holistic style of the style image in a global manner, or migrate local colors and textures of the style image to the content counterparts in a pre-defined way. In either case, only one result can be generated for a specific pair of content and style images, which therefore lacks flexibility and is hard to satisfy different users with different preferences. We propose here a novel strategy termed Any-to-Any Style Transfer to address this drawback, which enables users to interactively select styles of regions in the style image and apply them to the prescribed content regions. In this way, personalizable style transfer is achieved through human-computer interaction. At the heart of our approach lies in (1) a region segmentation module based on Segment Anything, which supports region selection with only some clicks or drawing on images and thus takes user inputs conveniently and flexibly; (2) and an attention fusion module, which converts inputs from users to controlling signals for the style transfer model. Experiments demonstrate the effectiveness for personalizable style transfer. Notably, our approach performs in a plug-and-play manner portable to any style transfer method and enhance the controllablity. Our code is available \href{https://github.com/Huage001/Transfer-Any-Style}{here}.
Partial Network Cloning
Mar 19, 2023
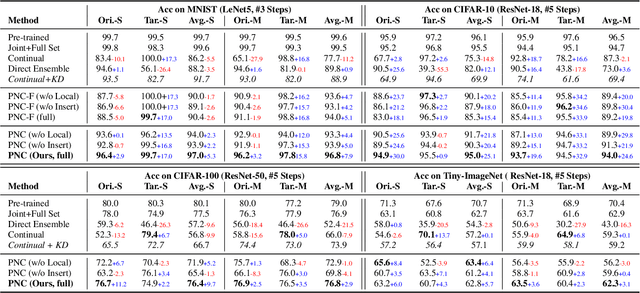
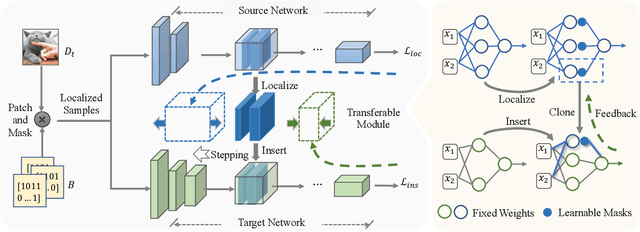
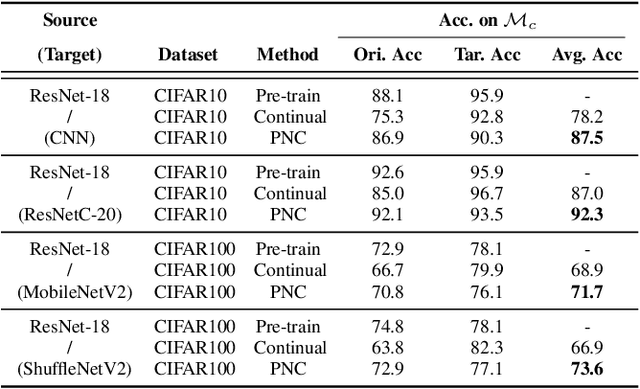
In this paper, we study a novel task that enables partial knowledge transfer from pre-trained models, which we term as Partial Network Cloning (PNC). Unlike prior methods that update all or at least part of the parameters in the target network throughout the knowledge transfer process, PNC conducts partial parametric "cloning" from a source network and then injects the cloned module to the target, without modifying its parameters. Thanks to the transferred module, the target network is expected to gain additional functionality, such as inference on new classes; whenever needed, the cloned module can be readily removed from the target, with its original parameters and competence kept intact. Specifically, we introduce an innovative learning scheme that allows us to identify simultaneously the component to be cloned from the source and the position to be inserted within the target network, so as to ensure the optimal performance. Experimental results on several datasets demonstrate that, our method yields a significant improvement of 5% in accuracy and 50% in locality when compared with parameter-tuning based methods. Our code is available at https://github.com/JngwenYe/PNCloning.
Deep Model Reassembly
Nov 02, 2022


In this paper, we explore a novel knowledge-transfer task, termed as Deep Model Reassembly (DeRy), for general-purpose model reuse. Given a collection of heterogeneous models pre-trained from distinct sources and with diverse architectures, the goal of DeRy, as its name implies, is to first dissect each model into distinctive building blocks, and then selectively reassemble the derived blocks to produce customized networks under both the hardware resource and performance constraints. Such ambitious nature of DeRy inevitably imposes significant challenges, including, in the first place, the feasibility of its solution. We strive to showcase that, through a dedicated paradigm proposed in this paper, DeRy can be made not only possibly but practically efficiently. Specifically, we conduct the partitions of all pre-trained networks jointly via a cover set optimization, and derive a number of equivalence set, within each of which the network blocks are treated as functionally equivalent and hence interchangeable. The equivalence sets learned in this way, in turn, enable picking and assembling blocks to customize networks subject to certain constraints, which is achieved via solving an integer program backed up with a training-free proxy to estimate the task performance. The reassembled models, give rise to gratifying performances with the user-specified constraints satisfied. We demonstrate that on ImageNet, the best reassemble model achieves 78.6% top-1 accuracy without fine-tuning, which could be further elevated to 83.2% with end-to-end training. Our code is available at https://github.com/Adamdad/DeRy
Dataset Distillation via Factorization
Oct 30, 2022
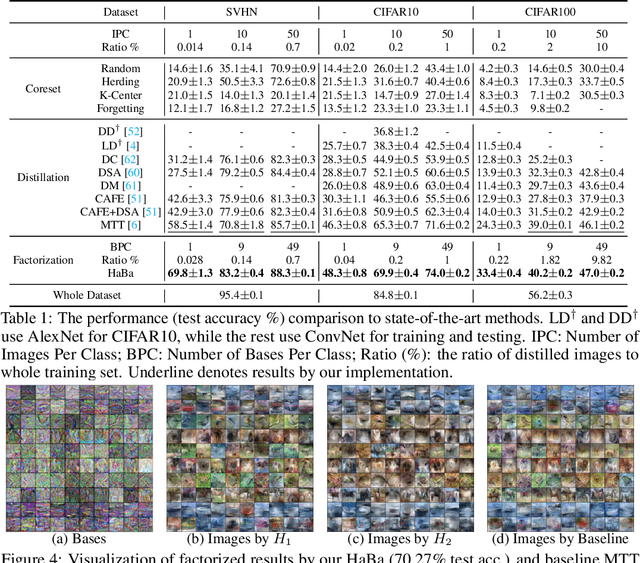
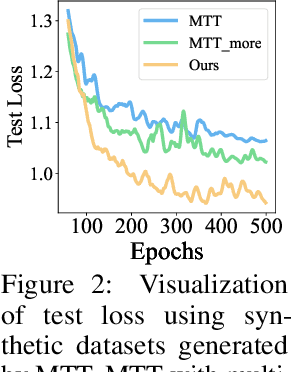
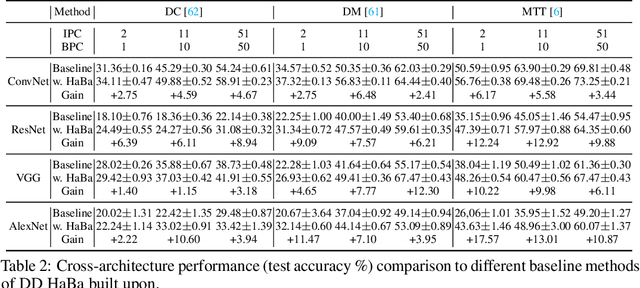
In this paper, we study \xw{dataset distillation (DD)}, from a novel perspective and introduce a \emph{dataset factorization} approach, termed \emph{HaBa}, which is a plug-and-play strategy portable to any existing DD baseline. Unlike conventional DD approaches that aim to produce distilled and representative samples, \emph{HaBa} explores decomposing a dataset into two components: data \emph{Ha}llucination networks and \emph{Ba}ses, where the latter is fed into the former to reconstruct image samples. The flexible combinations between bases and hallucination networks, therefore, equip the distilled data with exponential informativeness gain, which largely increase the representation capability of distilled datasets. To furthermore increase the data efficiency of compression results, we further introduce a pair of adversarial contrastive constraints on the resultant hallucination networks and bases, which increase the diversity of generated images and inject more discriminant information into the factorization. Extensive comparisons and experiments demonstrate that our method can yield significant improvement on downstream classification tasks compared with previous state of the arts, while reducing the total number of compressed parameters by up to 65\%. Moreover, distilled datasets by our approach also achieve \textasciitilde10\% higher accuracy than baseline methods in cross-architecture generalization. Our code is available \href{https://github.com/Huage001/DatasetFactorization}{here}.
A Survey of Neural Trees
Sep 07, 2022
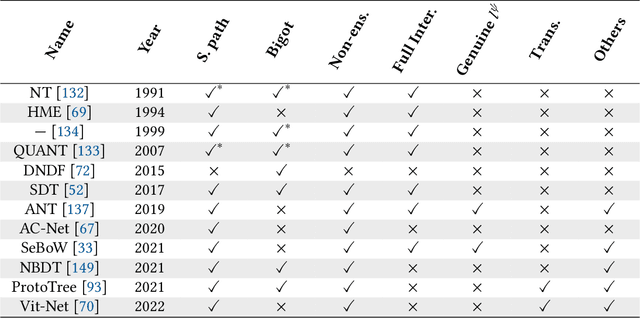
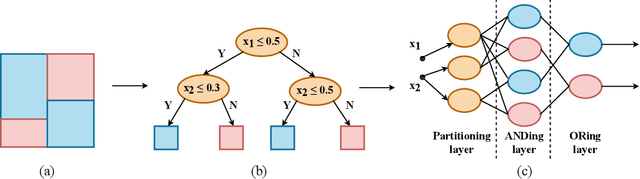

Neural networks (NNs) and decision trees (DTs) are both popular models of machine learning, yet coming with mutually exclusive advantages and limitations. To bring the best of the two worlds, a variety of approaches are proposed to integrate NNs and DTs explicitly or implicitly. In this survey, these approaches are organized in a school which we term as neural trees (NTs). This survey aims to present a comprehensive review of NTs and attempts to identify how they enhance the model interpretability. We first propose a thorough taxonomy of NTs that expresses the gradual integration and co-evolution of NNs and DTs. Afterward, we analyze NTs in terms of their interpretability and performance, and suggest possible solutions to the remaining challenges. Finally, this survey concludes with a discussion about other considerations like conditional computation and promising directions towards this field. A list of papers reviewed in this survey, along with their corresponding codes, is available at: https://github.com/zju-vipa/awesome-neural-trees
DynaST: Dynamic Sparse Transformer for Exemplar-Guided Image Generation
Jul 18, 2022
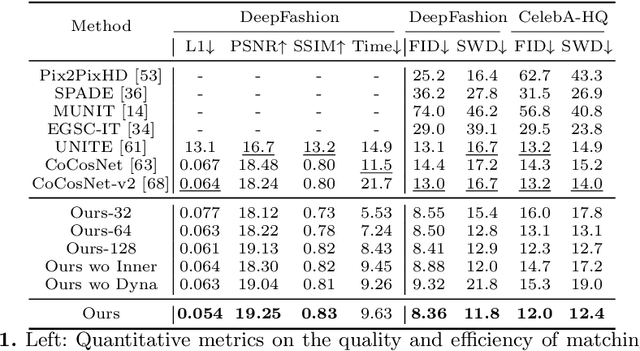
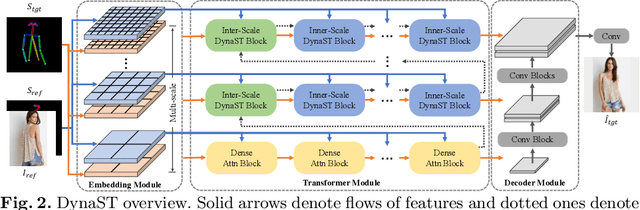

One key challenge of exemplar-guided image generation lies in establishing fine-grained correspondences between input and guided images. Prior approaches, despite the promising results, have relied on either estimating dense attention to compute per-point matching, which is limited to only coarse scales due to the quadratic memory cost, or fixing the number of correspondences to achieve linear complexity, which lacks flexibility. In this paper, we propose a dynamic sparse attention based Transformer model, termed Dynamic Sparse Transformer (DynaST), to achieve fine-level matching with favorable efficiency. The heart of our approach is a novel dynamic-attention unit, dedicated to covering the variation on the optimal number of tokens one position should focus on. Specifically, DynaST leverages the multi-layer nature of Transformer structure, and performs the dynamic attention scheme in a cascaded manner to refine matching results and synthesize visually-pleasing outputs. In addition, we introduce a unified training objective for DynaST, making it a versatile reference-based image translation framework for both supervised and unsupervised scenarios. Extensive experiments on three applications, pose-guided person image generation, edge-based face synthesis, and undistorted image style transfer, demonstrate that DynaST achieves superior performance in local details, outperforming the state of the art while reducing the computational cost significantly. Our code is available at https://github.com/Huage001/DynaST