 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinchao Wang
Ungeneralizable Examples
Apr 22, 2024
The training of contemporary deep learning models heavily relies on publicly available data, posing a risk of unauthorized access to online data and raising concerns about data privacy. Current approaches to creating unlearnable data involve incorporating small, specially designed noises, but these methods strictly limit data usability, overlooking its potential usage in authorized scenarios. In this paper, we extend the concept of unlearnable data to conditional data learnability and introduce \textbf{U}n\textbf{G}eneralizable \textbf{E}xamples (UGEs). UGEs exhibit learnability for authorized users while maintaining unlearnability for potential hackers. The protector defines the authorized network and optimizes UGEs to match the gradients of the original data and its ungeneralizable version, ensuring learnability. To prevent unauthorized learning, UGEs are trained by maximizing a designated distance loss in a common feature space. Additionally, to further safeguard the authorized side from potential attacks, we introduce additional undistillation optimization. Experimental results on multiple datasets and various networks demonstrate that the proposed UGEs framework preserves data usability while reducing training performance on hacker networks, even under different types of attacks.
Distilled Datamodel with Reverse Gradient Matching
Apr 22, 2024The proliferation of large-scale AI models trained on extensive datasets has revolutionized machine learning. With these models taking on increasingly central roles in various applications, the need to understand their behavior and enhance interpretability has become paramount. To investigate the impact of changes in training data on a pre-trained model, a common approach is leave-one-out retraining. This entails systematically altering the training dataset by removing specific samples to observe resulting changes within the model. However, retraining the model for each altered dataset presents a significant computational challenge, given the need to perform this operation for every dataset variation. In this paper, we introduce an efficient framework for assessing data impact, comprising offline training and online evaluation stages. During the offline training phase, we approximate the influence of training data on the target model through a distilled synset, formulated as a reversed gradient matching problem. For online evaluation, we expedite the leave-one-out process using the synset, which is then utilized to compute the attribution matrix based on the evaluation objective. Experimental evaluations, including training data attribution and assessments of data quality, demonstrate that our proposed method achieves comparable model behavior evaluation while significantly speeding up the process compared to the direct retraining method.
MindBridge: A Cross-Subject Brain Decoding Framework
Apr 11, 2024Brain decoding, a pivotal field in neuroscience, aims to reconstruct stimuli from acquired brain signals, primarily utilizing functional magnetic resonance imaging (fMRI). Currently, brain decoding is confined to a per-subject-per-model paradigm, limiting its applicability to the same individual for whom the decoding model is trained. This constraint stems from three key challenges: 1) the inherent variability in input dimensions across subjects due to differences in brain size; 2) the unique intrinsic neural patterns, influencing how different individuals perceive and process sensory information; 3) limited data availability for new subjects in real-world scenarios hampers the performance of decoding models. In this paper, we present a novel approach, MindBridge, that achieves cross-subject brain decoding by employing only one model. Our proposed framework establishes a generic paradigm capable of addressing these challenges by introducing biological-inspired aggregation function and novel cyclic fMRI reconstruction mechanism for subject-invariant representation learning. Notably, by cycle reconstruction of fMRI, MindBridge can enable novel fMRI synthesis, which also can serve as pseudo data augmentation. Within the framework, we also devise a novel reset-tuning method for adapting a pretrained model to a new subject. Experimental results demonstrate MindBridge's ability to reconstruct images for multiple subjects, which is competitive with dedicated subject-specific models. Furthermore, with limited data for a new subject, we achieve a high level of decoding accuracy, surpassing that of subject-specific models. This advancement in cross-subject brain decoding suggests promising directions for wider applications in neuroscience and indicates potential for more efficient utilization of limited fMRI data in real-world scenarios. Project page: https://littlepure2333.github.io/MindBridge
Hash3D: Training-free Acceleration for 3D Generation
Apr 09, 2024The evolution of 3D generative modeling has been notably propelled by the adoption of 2D diffusion models. Despite this progress, the cumbersome optimization process per se presents a critical hurdle to efficiency. In this paper, we introduce Hash3D, a universal acceleration for 3D generation without model training. Central to Hash3D is the insight that feature-map redundancy is prevalent in images rendered from camera positions and diffusion time-steps in close proximity. By effectively hashing and reusing these feature maps across neighboring timesteps and camera angles, Hash3D substantially prevents redundant calculations, thus accelerating the diffusion model's inference in 3D generation tasks. We achieve this through an adaptive grid-based hashing. Surprisingly, this feature-sharing mechanism not only speed up the generation but also enhances the smoothness and view consistency of the synthesized 3D objects. Our experiments covering 5 text-to-3D and 3 image-to-3D models, demonstrate Hash3D's versatility to speed up optimization, enhancing efficiency by 1.3 to 4 times. Additionally, Hash3D's integration with 3D Gaussian splatting largely speeds up 3D model creation, reducing text-to-3D processing to about 10 minutes and image-to-3D conversion to roughly 30 seconds. The project page is at https://adamdad.github.io/hash3D/.
Unsegment Anything by Simulating Deformation
Apr 03, 2024Foundation segmentation models, while powerful, pose a significant risk: they enable users to effortlessly extract any objects from any digital content with a single click, potentially leading to copyright infringement or malicious misuse. To mitigate this risk, we introduce a new task "Anything Unsegmentable" to grant any image "the right to be unsegmented". The ambitious pursuit of the task is to achieve highly transferable adversarial attacks against all prompt-based segmentation models, regardless of model parameterizations and prompts. We highlight the non-transferable and heterogeneous nature of prompt-specific adversarial noises. Our approach focuses on disrupting image encoder features to achieve prompt-agnostic attacks. Intriguingly, targeted feature attacks exhibit better transferability compared to untargeted ones, suggesting the optimal update direction aligns with the image manifold. Based on the observations, we design a novel attack named Unsegment Anything by Simulating Deformation (UAD). Our attack optimizes a differentiable deformation function to create a target deformed image, which alters structural information while preserving achievable feature distance by adversarial example. Extensive experiments verify the effectiveness of our approach, compromising a variety of promptable segmentation models with different architectures and prompt interfaces. We release the code at https://github.com/jiahaolu97/anything-unsegmentable.
Gamba: Marry Gaussian Splatting with Mamba for single view 3D reconstruction
Mar 29, 2024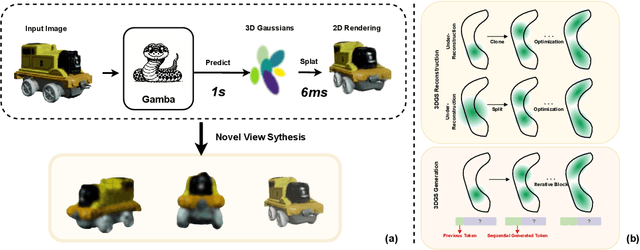

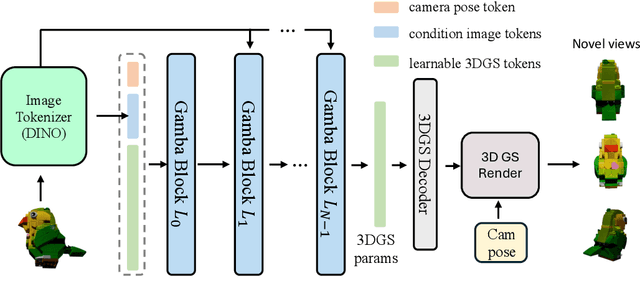

We tackle the challenge of efficiently reconstructing a 3D asset from a single image with growing demands for automated 3D content creation pipelines. Previous methods primarily rely on Score Distillation Sampling (SDS) and Neural Radiance Fields (NeRF). Despite their significant success, these approaches encounter practical limitations due to lengthy optimization and considerable memory usage. In this report, we introduce Gamba, an end-to-end amortized 3D reconstruction model from single-view images, emphasizing two main insights: (1) 3D representation: leveraging a large number of 3D Gaussians for an efficient 3D Gaussian splatting process; (2) Backbone design: introducing a Mamba-based sequential network that facilitates context-dependent reasoning and linear scalability with the sequence (token) length, accommodating a substantial number of Gaussians. Gamba incorporates significant advancements in data preprocessing, regularization design, and training methodologies. We assessed Gamba against existing optimization-based and feed-forward 3D generation approaches using the real-world scanned OmniObject3D dataset. Here, Gamba demonstrates competitive generation capabilities, both qualitatively and quantitatively, while achieving remarkable speed, approximately 0.6 second on a single NVIDIA A100 GPU.
Relation Rectification in Diffusion Model
Mar 29, 2024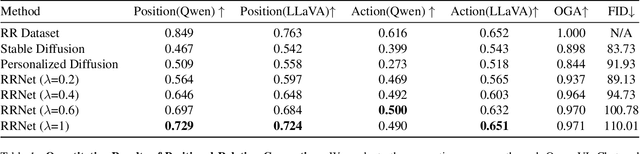
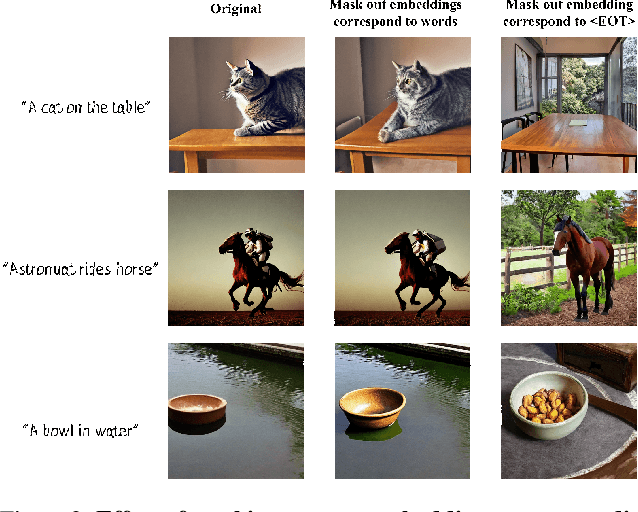

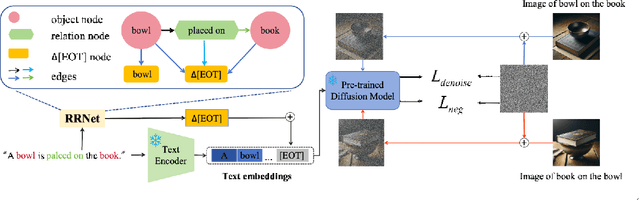
Despite their exceptional generative abilities, large text-to-image diffusion models, much like skilled but careless artists, often struggle with accurately depicting visual relationships between objects. This issue, as we uncover through careful analysis, arises from a misaligned text encoder that struggles to interpret specific relationships and differentiate the logical order of associated objects. To resolve this, we introduce a novel task termed Relation Rectification, aiming to refine the model to accurately represent a given relationship it initially fails to generate. To address this, we propose an innovative solution utilizing a Heterogeneous Graph Convolutional Network (HGCN). It models the directional relationships between relation terms and corresponding objects within the input prompts. Specifically, we optimize the HGCN on a pair of prompts with identical relational words but reversed object orders, supplemented by a few reference images. The lightweight HGCN adjusts the text embeddings generated by the text encoder, ensuring the accurate reflection of the textual relation in the embedding space. Crucially, our method retains the parameters of the text encoder and diffusion model, preserving the model's robust performance on unrelated descriptions. We validated our approach on a newly curated dataset of diverse relational data, demonstrating both quantitative and qualitative enhancements in generating images with precise visual relations. Project page: https://wuyinwei-hah.github.io/rrnet.github.io/.
Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images
Mar 19, 2024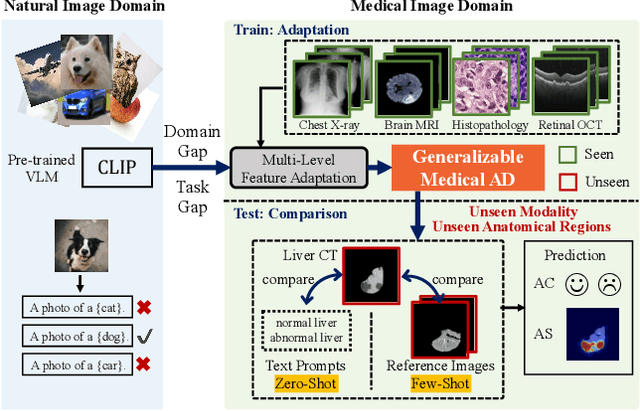
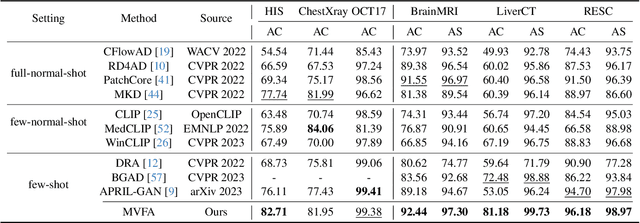
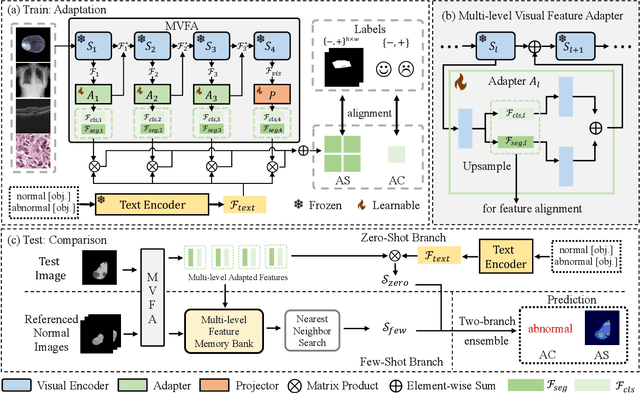
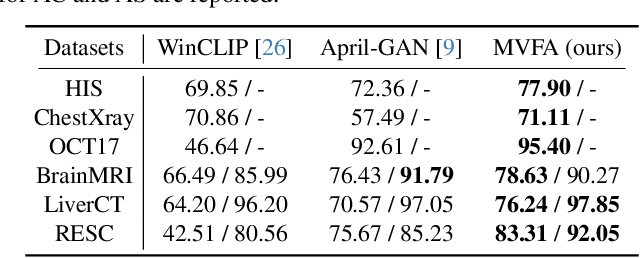
Recent advancements in large-scale visual-language pre-trained models have led to significant progress in zero-/few-shot anomaly detection within natural image domains. However, the substantial domain divergence between natural and medical images limits the effectiveness of these methodologies in medical anomaly detection. This paper introduces a novel lightweight multi-level adaptation and comparison framework to repurpose the CLIP model for medical anomaly detection. Our approach integrates multiple residual adapters into the pre-trained visual encoder, enabling a stepwise enhancement of visual features across different levels. This multi-level adaptation is guided by multi-level, pixel-wise visual-language feature alignment loss functions, which recalibrate the model's focus from object semantics in natural imagery to anomaly identification in medical images. The adapted features exhibit improved generalization across various medical data types, even in zero-shot scenarios where the model encounters unseen medical modalities and anatomical regions during training. Our experiments on medical anomaly detection benchmarks demonstrate that our method significantly surpasses current state-of-the-art models, with an average AUC improvement of 6.24% and 7.33% for anomaly classification, 2.03% and 2.37% for anomaly segmentation, under the zero-shot and few-shot settings, respectively. Source code is available at: https://github.com/MediaBrain-SJTU/MVFA-AD
Through the Dual-Prism: A Spectral Perspective on Graph Data Augmentation for Graph Classification
Jan 22, 2024Graph Neural Networks (GNNs) have become the preferred tool to process graph data, with their efficacy being boosted through graph data augmentation techniques. Despite the evolution of augmentation methods, issues like graph property distortions and restricted structural changes persist. This leads to the question: Is it possible to develop more property-conserving and structure-sensitive augmentation methods? Through a spectral lens, we investigate the interplay between graph properties, their augmentation, and their spectral behavior, and found that keeping the low-frequency eigenvalues unchanged can preserve the critical properties at a large scale when generating augmented graphs. These observations inform our introduction of the Dual-Prism (DP) augmentation method, comprising DP-Noise and DP-Mask, which adeptly retains essential graph properties while diversifying augmented graphs. Extensive experiments validate the efficiency of our approach, providing a new and promising direction for graph data augmentation.
Mutual-modality Adversarial Attack with Semantic Perturbation
Dec 20, 2023Adversarial attacks constitute a notable threat to machine learning systems, given their potential to induce erroneous predictions and classifications. However, within real-world contexts, the essential specifics of the deployed model are frequently treated as a black box, consequently mitigating the vulnerability to such attacks. Thus, enhancing the transferability of the adversarial samples has become a crucial area of research, which heavily relies on selecting appropriate surrogate models. To address this challenge, we propose a novel approach that generates adversarial attacks in a mutual-modality optimization scheme. Our approach is accomplished by leveraging the pre-trained CLIP model. Firstly, we conduct a visual attack on the clean image that causes semantic perturbations on the aligned embedding space with the other textual modality. Then, we apply the corresponding defense on the textual modality by updating the prompts, which forces the re-matching on the perturbed embedding space. Finally, to enhance the attack transferability, we utilize the iterative training strategy on the visual attack and the textual defense, where the two processes optimize from each other. We evaluate our approach on several benchmark datasets and demonstrate that our mutual-modal attack strategy can effectively produce high-transferable attacks, which are stable regardless of the target networks. Our approach outperforms state-of-the-art attack methods and can be readily deployed as a plug-and-play solution.