 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYanfeng Wang
Ethical-Lens: Curbing Malicious Usages of Open-Source Text-to-Image Models
Apr 18, 2024
The burgeoning landscape of text-to-image models, exemplified by innovations such as Midjourney and DALLE 3, has revolutionized content creation across diverse sectors. However, these advancements bring forth critical ethical concerns, particularly with the misuse of open-source models to generate content that violates societal norms. Addressing this, we introduce Ethical-Lens, a framework designed to facilitate the value-aligned usage of text-to-image tools without necessitating internal model revision. Ethical-Lens ensures value alignment in text-to-image models across toxicity and bias dimensions by refining user commands and rectifying model outputs. Systematic evaluation metrics, combining GPT4-V, HEIM, and FairFace scores, assess alignment capability. Our experiments reveal that Ethical-Lens enhances alignment capabilities to levels comparable with or superior to commercial models like DALLE 3, ensuring user-generated content adheres to ethical standards while maintaining image quality. This study indicates the potential of Ethical-Lens to ensure the sustainable development of open-source text-to-image tools and their beneficial integration into society. Our code is available at https://github.com/yuzhu-cai/Ethical-Lens.
Knowledge-enhanced Visual-Language Pretraining for Computational Pathology
Apr 15, 2024In this paper, we consider the problem of visual representation learning for computational pathology, by exploiting large-scale image-text pairs gathered from public resources, along with the domain specific knowledge in pathology. Specifically, we make the following contributions: (i) We curate a pathology knowledge tree that consists of 50,470 informative attributes for 4,718 diseases requiring pathology diagnosis from 32 human tissues. To our knowledge, this is the first comprehensive structured pathology knowledge base; (ii) We develop a knowledge-enhanced visual-language pretraining approach, where we first project pathology-specific knowledge into latent embedding space via language model, and use it to guide the visual representation learning; (iii) We conduct thorough experiments to validate the effectiveness of our proposed components, demonstrating significant performance improvement on various downstream tasks, including cross-modal retrieval, zero-shot classification on pathology patches, and zero-shot tumor subtyping on whole slide images (WSIs). All codes, models and the pathology knowledge tree will be released to the research community
MING-MOE: Enhancing Medical Multi-Task Learning in Large Language Models with Sparse Mixture of Low-Rank Adapter Experts
Apr 13, 2024Large language models like ChatGPT have shown substantial progress in natural language understanding and generation, proving valuable across various disciplines, including the medical field. Despite advancements, challenges persist due to the complexity and diversity inherent in medical tasks which often require multi-task learning capabilities. Previous approaches, although beneficial, fall short in real-world applications because they necessitate task-specific annotations at inference time, limiting broader generalization. This paper introduces MING-MOE, a novel Mixture-of-Expert~(MOE)-based medical large language model designed to manage diverse and complex medical tasks without requiring task-specific annotations, thus enhancing its usability across extensive datasets. MING-MOE employs a Mixture of Low-Rank Adaptation (MoLoRA) technique, allowing for efficient parameter usage by maintaining base model parameters static while adapting through a minimal set of trainable parameters. We demonstrate that MING-MOE achieves state-of-the-art (SOTA) performance on over 20 medical tasks, illustrating a significant improvement over existing models. This approach not only extends the capabilities of medical language models but also improves inference efficiency.
Anomaly Detection in Electrocardiograms: Advancing Clinical Diagnosis Through Self-Supervised Learning
Apr 07, 2024The electrocardiogram (ECG) is an essential tool for diagnosing heart disease, with computer-aided systems improving diagnostic accuracy and reducing healthcare costs. Despite advancements, existing systems often miss rare cardiac anomalies that could be precursors to serious, life-threatening issues or alterations in the cardiac macro/microstructure. We address this gap by focusing on self-supervised anomaly detection (AD), training exclusively on normal ECGs to recognize deviations indicating anomalies. We introduce a novel self-supervised learning framework for ECG AD, utilizing a vast dataset of normal ECGs to autonomously detect and localize cardiac anomalies. It proposes a novel masking and restoration technique alongside a multi-scale cross-attention module, enhancing the model's ability to integrate global and local signal features. The framework emphasizes accurate localization of anomalies within ECG signals, ensuring the method's clinical relevance and reliability. To reduce the impact of individual variability, the approach further incorporates crucial patient-specific information from ECG reports, such as age and gender, thus enabling accurate identification of a broad spectrum of cardiac anomalies, including rare ones. Utilizing an extensive dataset of 478,803 ECG graphic reports from real-world clinical practice, our method has demonstrated exceptional effectiveness in AD across all tested conditions, regardless of their frequency of occurrence, significantly outperforming existing models. It achieved superior performance metrics, including an AUROC of 91.2%, an F1 score of 83.7%, a sensitivity rate of 84.2%, a specificity of 83.0%, and a precision of 75.6% with a fixed recall rate of 90%. It has also demonstrated robust localization capabilities, with an AUROC of 76.5% and a Dice coefficient of 65.3% for anomaly localization.
ReMamber: Referring Image Segmentation with Mamba Twister
Mar 26, 2024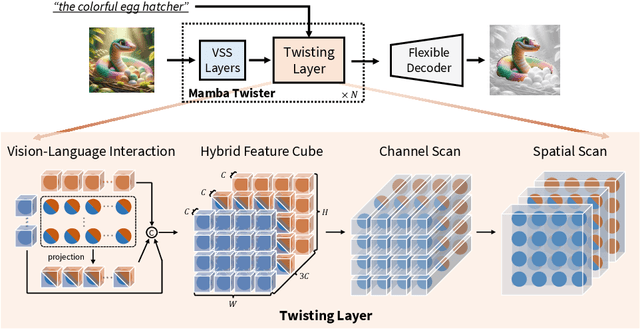
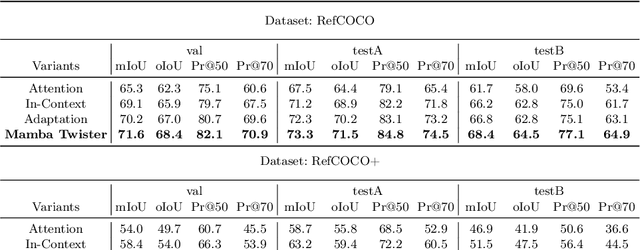
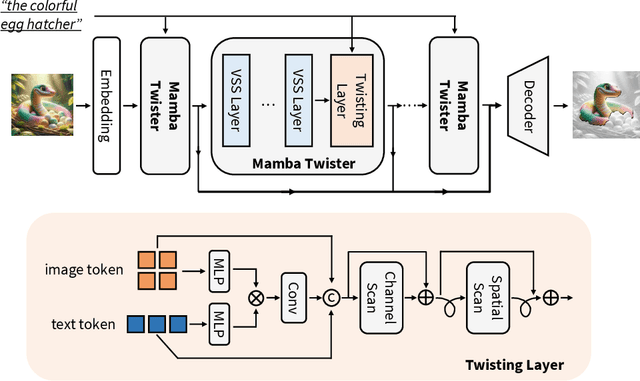
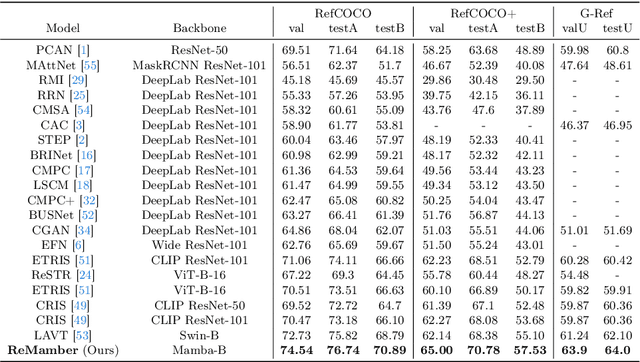
Referring Image Segmentation (RIS) leveraging transformers has achieved great success on the interpretation of complex visual-language tasks. However, the quadratic computation cost makes it resource-consuming in capturing long-range visual-language dependencies. Fortunately, Mamba addresses this with efficient linear complexity in processing. However, directly applying Mamba to multi-modal interactions presents challenges, primarily due to inadequate channel interactions for the effective fusion of multi-modal data. In this paper, we propose ReMamber, a novel RIS architecture that integrates the power of Mamba with a multi-modal Mamba Twister block. The Mamba Twister explicitly models image-text interaction, and fuses textual and visual features through its unique channel and spatial twisting mechanism. We achieve the state-of-the-art on three challenging benchmarks. Moreover, we conduct thorough analyses of ReMamber and discuss other fusion designs using Mamba. These provide valuable perspectives for future research.
M$^3$AV: A Multimodal, Multigenre, and Multipurpose Audio-Visual Academic Lecture Dataset
Mar 21, 2024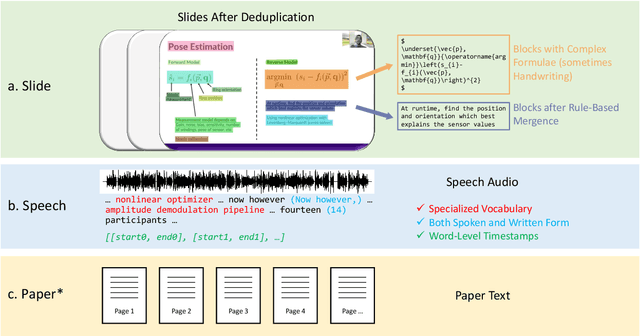
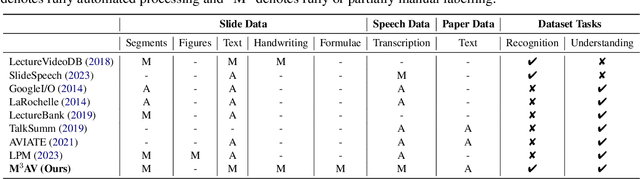
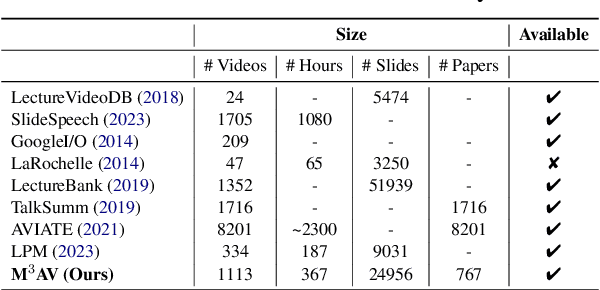
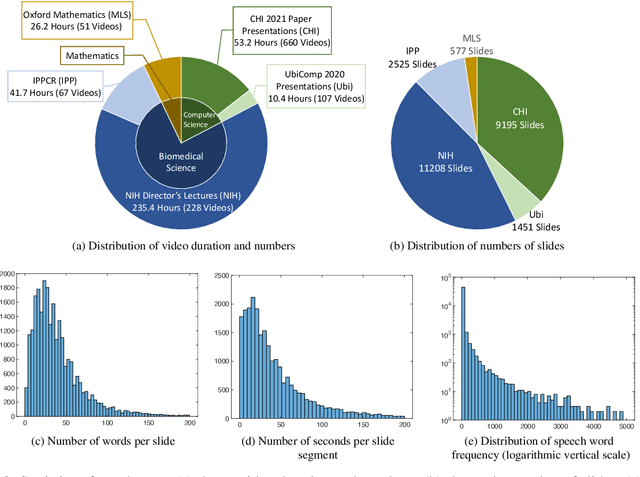
Publishing open-source academic video recordings is an emergent and prevalent approach to sharing knowledge online. Such videos carry rich multimodal information including speech, the facial and body movements of the speakers, as well as the texts and pictures in the slides and possibly even the papers. Although multiple academic video datasets have been constructed and released, few of them support both multimodal content recognition and understanding tasks, which is partially due to the lack of high-quality human annotations. In this paper, we propose a novel multimodal, multigenre, and multipurpose audio-visual academic lecture dataset (M$^3$AV), which has almost 367 hours of videos from five sources covering computer science, mathematics, and medical and biology topics. With high-quality human annotations of the spoken and written words, in particular high-valued name entities, the dataset can be used for multiple audio-visual recognition and understanding tasks. Evaluations performed on contextual speech recognition, speech synthesis, and slide and script generation tasks demonstrate that the diversity of M$^3$AV makes it a challenging dataset.
Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images
Mar 19, 2024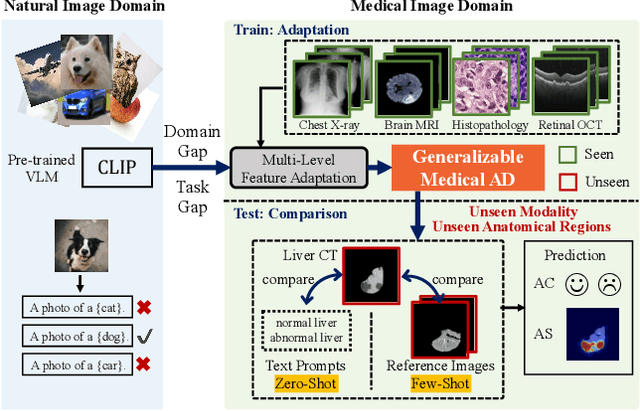
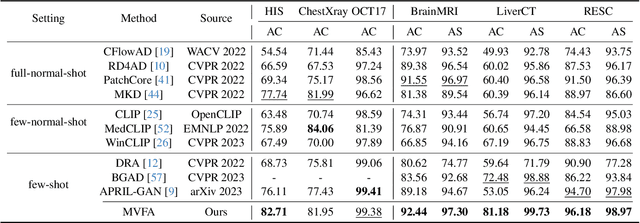
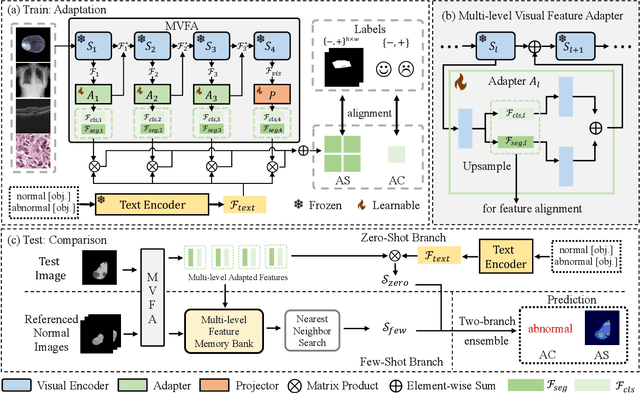
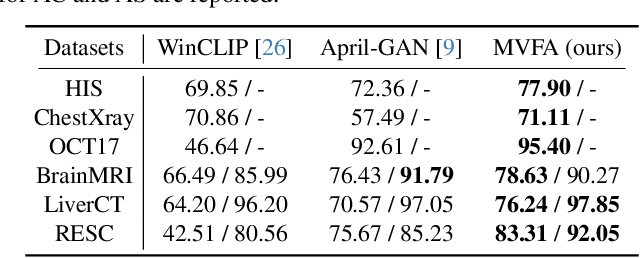
Recent advancements in large-scale visual-language pre-trained models have led to significant progress in zero-/few-shot anomaly detection within natural image domains. However, the substantial domain divergence between natural and medical images limits the effectiveness of these methodologies in medical anomaly detection. This paper introduces a novel lightweight multi-level adaptation and comparison framework to repurpose the CLIP model for medical anomaly detection. Our approach integrates multiple residual adapters into the pre-trained visual encoder, enabling a stepwise enhancement of visual features across different levels. This multi-level adaptation is guided by multi-level, pixel-wise visual-language feature alignment loss functions, which recalibrate the model's focus from object semantics in natural imagery to anomaly identification in medical images. The adapted features exhibit improved generalization across various medical data types, even in zero-shot scenarios where the model encounters unseen medical modalities and anatomical regions during training. Our experiments on medical anomaly detection benchmarks demonstrate that our method significantly surpasses current state-of-the-art models, with an average AUC improvement of 6.24% and 7.33% for anomaly classification, 2.03% and 2.37% for anomaly segmentation, under the zero-shot and few-shot settings, respectively. Source code is available at: https://github.com/MediaBrain-SJTU/MVFA-AD
Audio-Visual Segmentation via Unlabeled Frame Exploitation
Mar 17, 2024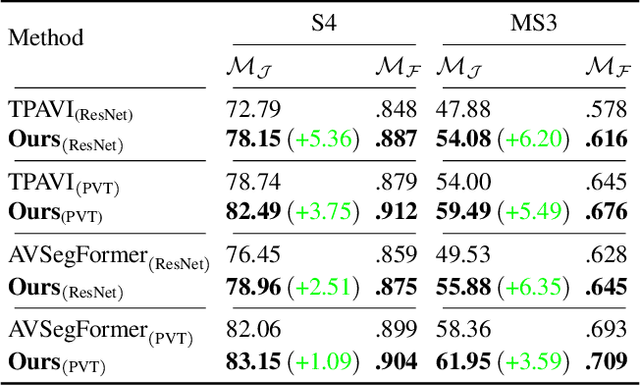
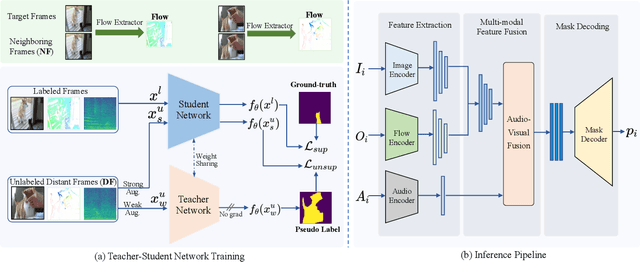
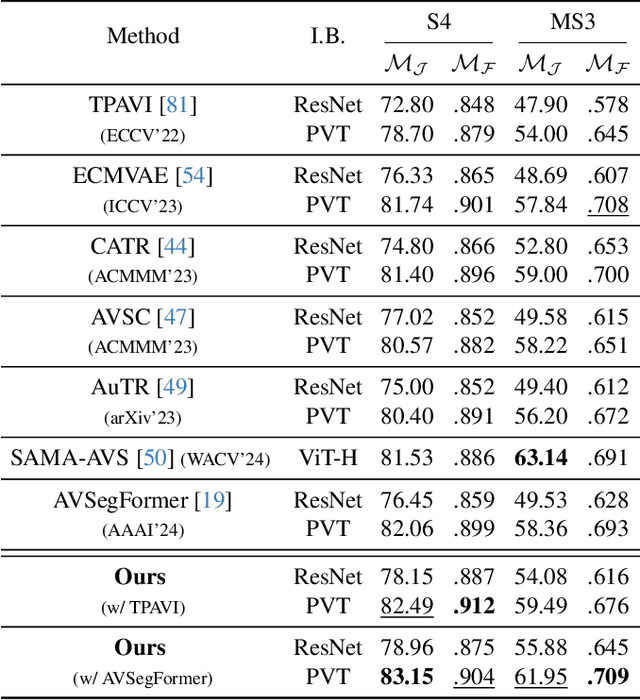
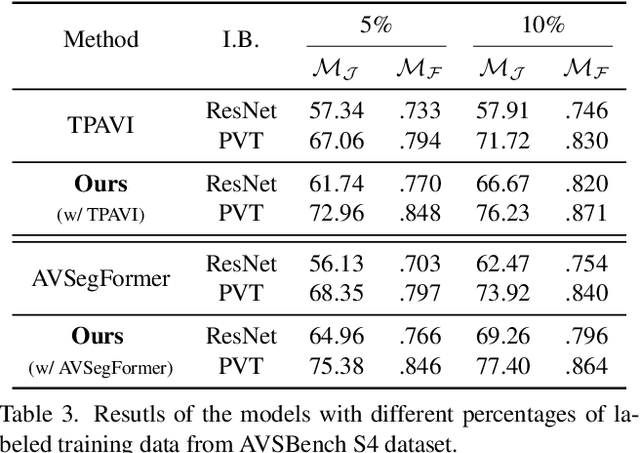
Audio-visual segmentation (AVS) aims to segment the sounding objects in video frames. Although great progress has been witnessed, we experimentally reveal that current methods reach marginal performance gain within the use of the unlabeled frames, leading to the underutilization issue. To fully explore the potential of the unlabeled frames for AVS, we explicitly divide them into two categories based on their temporal characteristics, i.e., neighboring frame (NF) and distant frame (DF). NFs, temporally adjacent to the labeled frame, often contain rich motion information that assists in the accurate localization of sounding objects. Contrary to NFs, DFs have long temporal distances from the labeled frame, which share semantic-similar objects with appearance variations. Considering their unique characteristics, we propose a versatile framework that effectively leverages them to tackle AVS. Specifically, for NFs, we exploit the motion cues as the dynamic guidance to improve the objectness localization. Besides, we exploit the semantic cues in DFs by treating them as valid augmentations to the labeled frames, which are then used to enrich data diversity in a self-training manner. Extensive experimental results demonstrate the versatility and superiority of our method, unleashing the power of the abundant unlabeled frames.
Automatic Interactive Evaluation for Large Language Models with State Aware Patient Simulator
Mar 14, 2024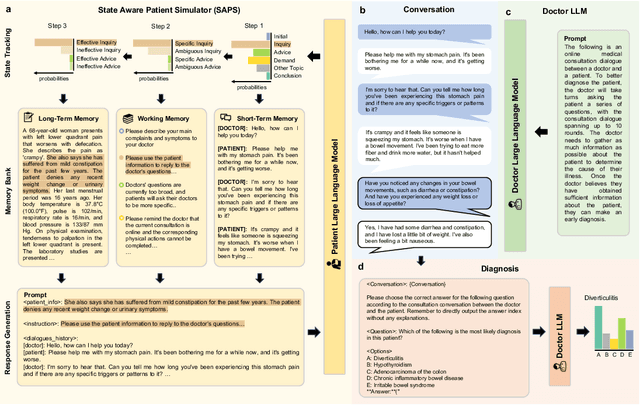
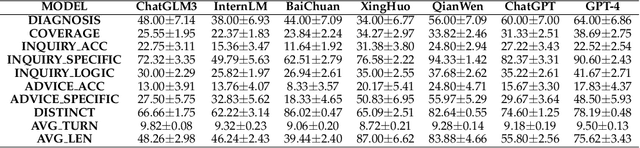
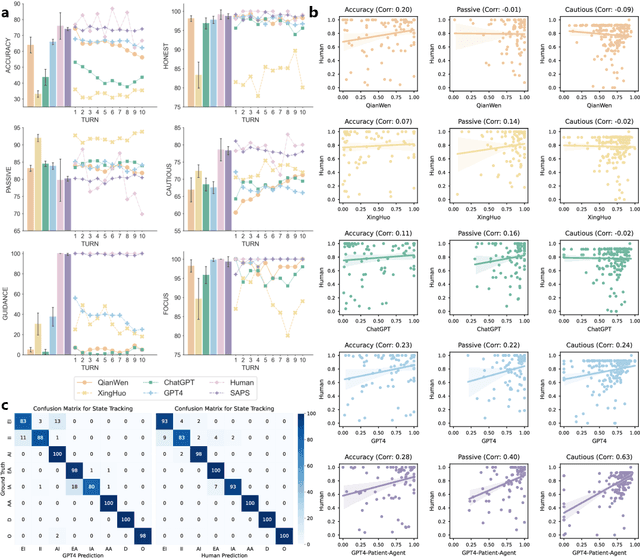

Large Language Models (LLMs) have demonstrated remarkable proficiency in human interactions, yet their application within the medical field remains insufficiently explored. Previous works mainly focus on the performance of medical knowledge with examinations, which is far from the realistic scenarios, falling short in assessing the abilities of LLMs on clinical tasks. In the quest to enhance the application of Large Language Models (LLMs) in healthcare, this paper introduces the Automated Interactive Evaluation (AIE) framework and the State-Aware Patient Simulator (SAPS), targeting the gap between traditional LLM evaluations and the nuanced demands of clinical practice. Unlike prior methods that rely on static medical knowledge assessments, AIE and SAPS provide a dynamic, realistic platform for assessing LLMs through multi-turn doctor-patient simulations. This approach offers a closer approximation to real clinical scenarios and allows for a detailed analysis of LLM behaviors in response to complex patient interactions. Our extensive experimental validation demonstrates the effectiveness of the AIE framework, with outcomes that align well with human evaluations, underscoring its potential to revolutionize medical LLM testing for improved healthcare delivery.
Decentralized and Lifelong-Adaptive Multi-Agent Collaborative Learning
Mar 11, 2024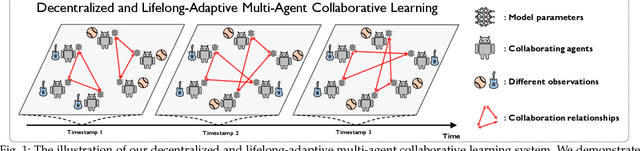
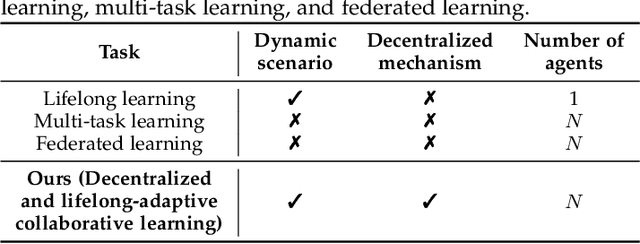
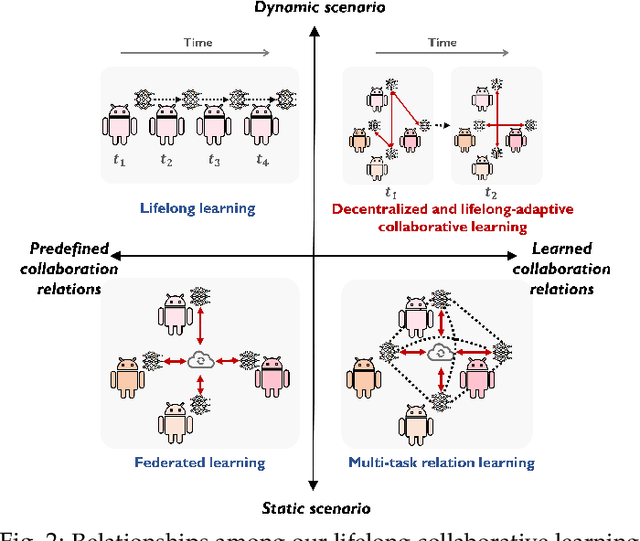
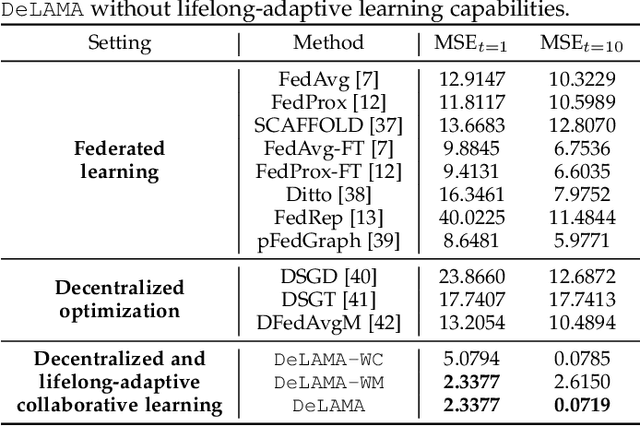
Decentralized and lifelong-adaptive multi-agent collaborative learning aims to enhance collaboration among multiple agents without a central server, with each agent solving varied tasks over time. To achieve efficient collaboration, agents should: i) autonomously identify beneficial collaborative relationships in a decentralized manner; and ii) adapt to dynamically changing task observations. In this paper, we propose DeLAMA, a decentralized multi-agent lifelong collaborative learning algorithm with dynamic collaboration graphs. To promote autonomous collaboration relationship learning, we propose a decentralized graph structure learning algorithm, eliminating the need for external priors. To facilitate adaptation to dynamic tasks, we design a memory unit to capture the agents' accumulated learning history and knowledge, while preserving finite storage consumption. To further augment the system's expressive capabilities and computational efficiency, we apply algorithm unrolling, leveraging the advantages of both mathematical optimization and neural networks. This allows the agents to `learn to collaborate' through the supervision of training tasks. Our theoretical analysis verifies that inter-agent collaboration is communication efficient under a small number of communication rounds. The experimental results verify its ability to facilitate the discovery of collaboration strategies and adaptation to dynamic learning scenarios, achieving a 98.80% reduction in MSE and a 188.87% improvement in classification accuracy. We expect our work can serve as a foundational technique to facilitate future works towards an intelligent, decentralized, and dynamic multi-agent system. Code is available at https://github.com/ShuoTang123/DeLAMA.